PCIE基于Riffa架构的PCIE项目
Posted Ethan_WC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PCIE基于Riffa架构的PCIE项目相关的知识,希望对你有一定的参考价值。
基于Riffa架构的PCIE项目
-
Pcie分为四层:
① 物理层:完成信号的转换以及编码
包含 PMA 和 PCS
PMA: Physical Media Attachment 物理媒介层,完成并转串或者串转并的操作
PCS: Physical Coding Sublayer物理的code,其实就是8b转10b的编码,使用 8b/10b 编码这个编码技术是用于高速接口中使得数据链路中的数据 1 和数据 0 更均衡
② 链路层:完成一些编码的操作
③ 事务层:ipcore 是控制事务处来实现应用层
④ 应用层为什么要经过8b转10b呢?
因为8b/10b提供了一些沿的信息,它会锁定沿的信息,它知道里边通信的速率是多少,它就能通过通信速率计算出一个基本的周期。再根据沿的偏移量,这样就能算出采集的数据最稳定的地方。它是动态锁定的,并不是锁定一次就不变了。==============
-
PICE的常用通信框架包括:Riffa框架 和 xilinx的XDMA框架。
Riffa 可以最多可以支持到8 lane。但是Riffa虚拟出来多个通道,Riffa 最多可以支持 12 个用户的 channel。

就跟DDR一样,物理上只能读或者只能写,但是我们虚拟出来几个通道可以同时读写。==============
-
这里 RX 和 TX 是使用 xilinx 芯片内部的 GTP 接口实现, (本项目中是 Aritx7 的 GTP接口,将来可以使用 kintex 7 的 GTX 以及高级器件中的 GTH GTY 等高速接口资源)。
==============
-
Riffa框架和xilinx的XDMA框架已经把PCIE的解包和封包做好了,它提供了一个更加简单的接口来给用户使用,使得开发更加高效。如果不使用这种框架的方式,必须自行写解包和封包,这还要涉及到和驱动工程师的配合。
物理层和链路层由IP自动生成,无需用户关心;用户只需要关心传输层,即TLP包。这部分有框架Riffa和XDMA,可以直接套。
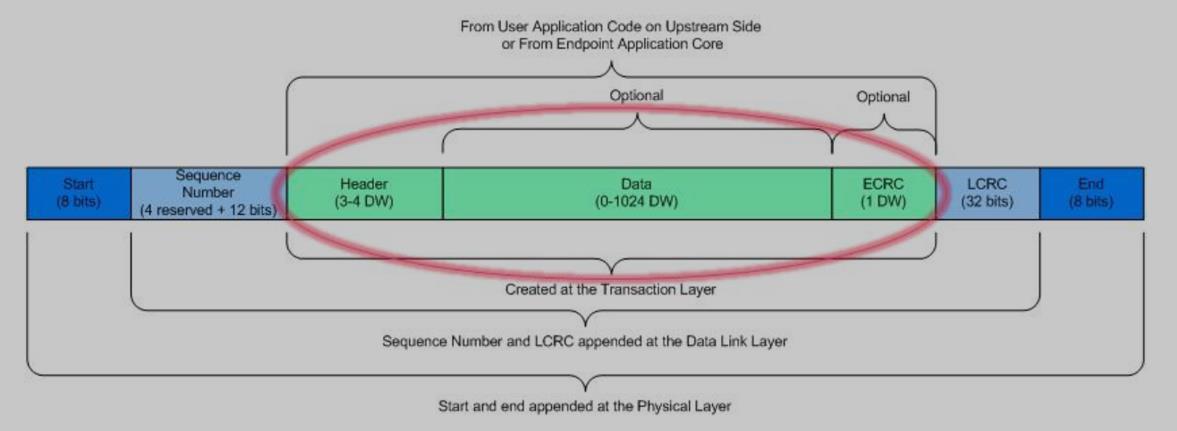
Riffa是通过AXI stream和更底层的pcie core连接。

==============
-
Riffa提供的简化接口.
1)Rx
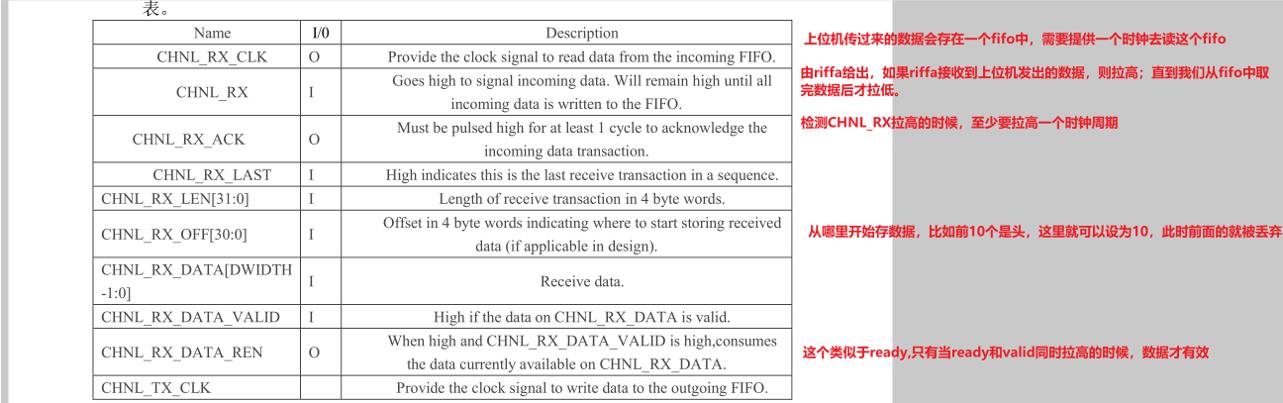

从第二张图可以看出,在接受完数据后CHNL_RX的反应会稍微晚一点,所以代码中需要做一个处理,即我们读fifo数据的时候整一个计数器,计数到lenth后保持,直到CHNL_RX拉低后,才退出这一次数据的所有接收。退出之后,再去检测CHNL_RX拉高。2)Tx


注意LEN的长度为DW长度。

==============
6. 以上位机发送1920x1080为例。
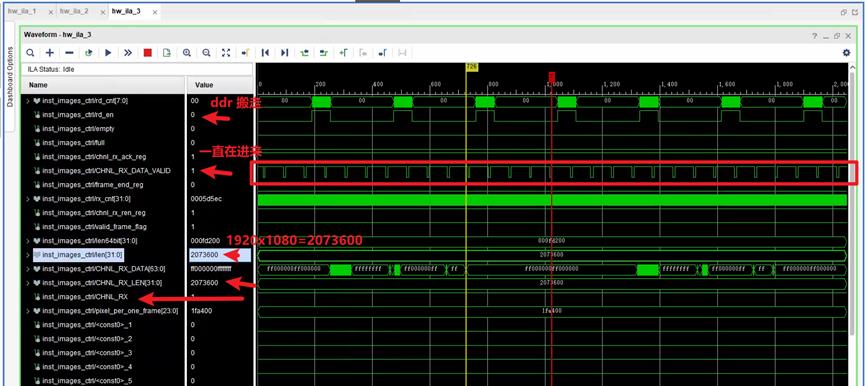
一帧开始的时候:隔了一段时间,数据才出来。
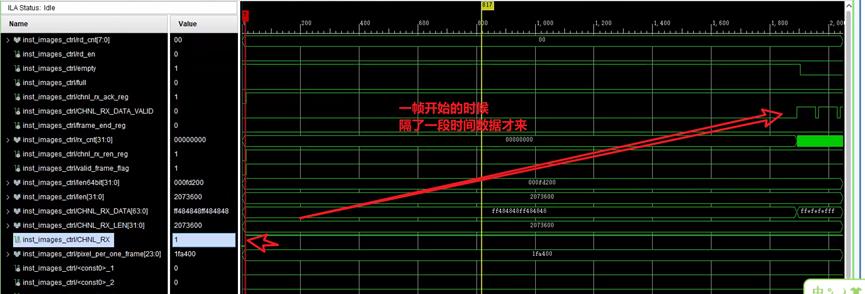
一帧结束:
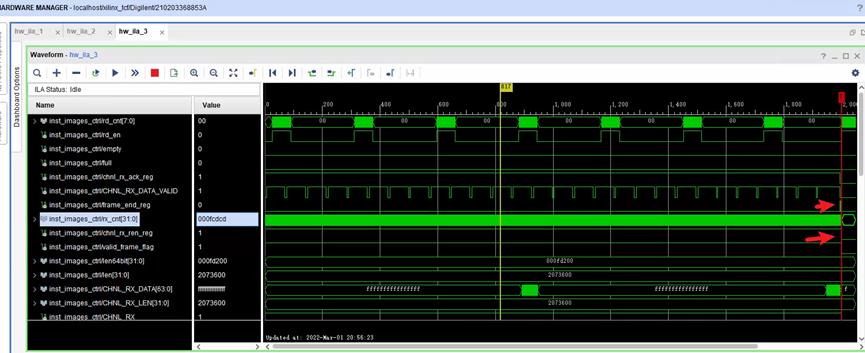
ila保存为modelsim的波形为.wlf文件 ,用modelsim直接打开即可。
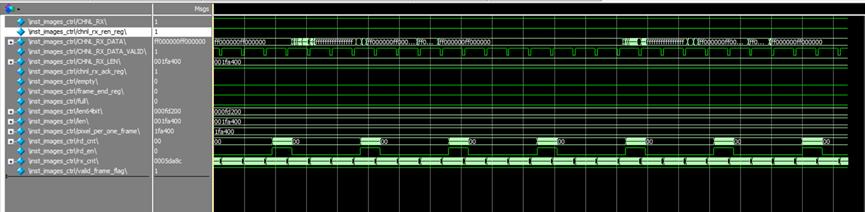
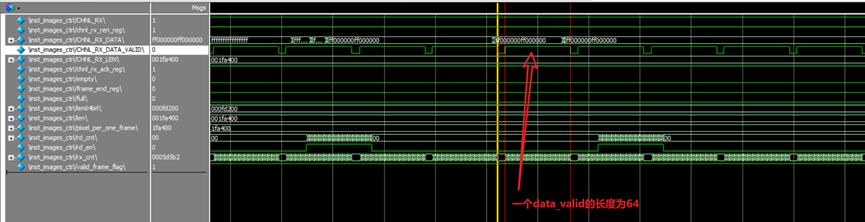
==============
7.riffa框架的用户接口最大只能支持到128位宽,只能到PCIE2.0;而XDMA可以支持到pcie3.0,用户接口最大可以支持到256位。但是XDMA的效率不如riffa的效率高,而且XDMA的AXI-stream的效率很难提高,所以建议只用AXI的接口去开发,不建议使用AXI-stream接口。
这个DMA其实是DMA到主机的内存,并不是我们板卡的内存。并且XDMA ip只能作为endpoint的设备,不能作为root.==============
8 . 接收上游发过来的数据的时候,一定要确保对所有数据的处理都是之前双方约定好的包头,所以数据一进来就要产生一个有效帧标志,把其他(异己)帧丢弃。==============
9 . Xilinx 的fifo的机制:先进来的数据要存在fifo的写的高位。==============
10 . Riffa出来的数据,DW1DW0, DW3DW2, ……… 数据0在低位,数据1在高位。
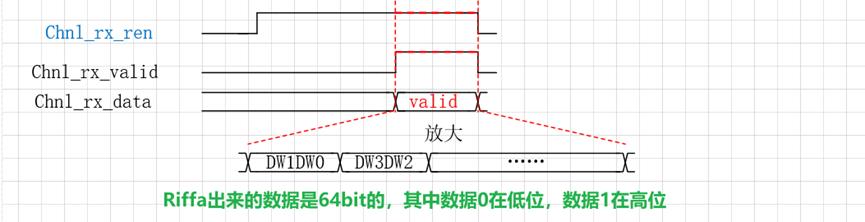
==============
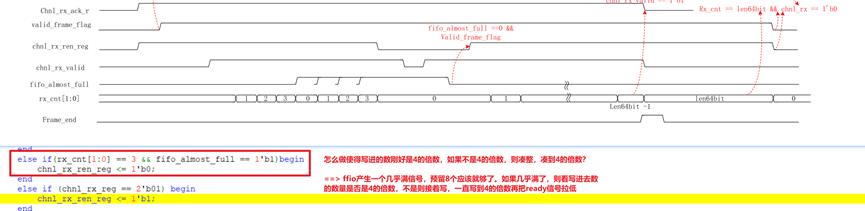
11 . 在写fifo的时候,如何控制写进去的数的个数刚好是4的倍数??
fifo产生一个几乎满信号,预留好空间;在几乎满的时候,看写进去的数量计数器是否是4的倍数,不是则等写到4的倍数后再把ready信号拉高,最多多些3个计数器。
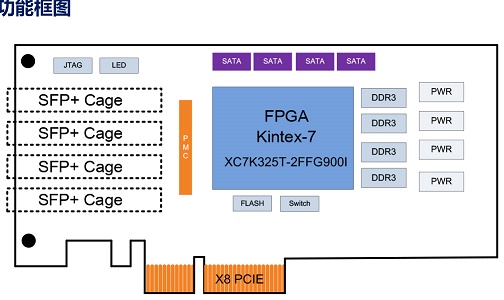
基于XC7K325T光纤传输PCIE光纤卡4路光纤卡
PCIE730是北京青翼科技一款基于PCI Express总线架构的4路10G光纤通道适配器,板卡具有4通道SFP+万兆光纤接口,x8 PCIE主机接口,具有1组64位DDR3 SDRAM作为高速缓存,可以实现4通道光纤网络数据的高速采集、实时记录和宽带回放。
该板卡还具有4个SATA接口,可以实现光纤数据的高速存储,支持SATA3.0标准,最大存储带宽可以达到1.6GByte/s。
该板卡为标准全高半长PCIE尺寸,适合于目前主流的服务器或工作站,可广泛应用于数据中心、服务器加速运算等场景,也可用于半实物仿真系统中。
主要功能
1.标准PCI Express半长卡;
2.符合PCI Express Gen2.0规范,可选x1、x4或x8模式,带宽40Gbps;
3.光纤传输性能:支持4路SFP+万兆光纤,10Gbps/lane线速率;
4.光纤传输协议:支持Aurora、RapidIO等多种高速协议;
5.动态存储性能:1组64位2GByte DDR3 SDRAM,理论带宽12.8Gbyte/s,效率高达90%;
6.SATA存储性能:支持x4 SATA3.0;
7. PCIE DMA性能:上行与下行带宽可以达到3GByte
8.板卡具有4路光耦隔离输入、4路光耦隔离输出数字离散IO;
9. 板载1个PMC IO接口,用于GPIO扩展;
10.板载1片128Mbyte BPI Nor Flash,用于FPGA的加载;
接口特征
1. 前面板支持4路SFP+ Cage(最大支持10Gbps/lane);
2.板上4路SATA接口;
3.板上1路PMC IO接口;
软件支持
1.可选集成板级软件开发包(BSP):
2.FPGA的DDR3接口测试程序;
3.4路10G光纤接口程序,支持Aurora或Serial RapidIO协议;
4.光纤PCIe链路演示DEMO;
5.提供驱动程序以及应用程序接口(API):
6.支持Windows 7 32位/64位操作系统;
7.支持Win Server2008/2012;
应用场景
1.图像采集系统
2.模拟数据光纤采集传输系统
3.雷达系统半实物仿真
4.网络硬件加速
技术支持;
直接由板卡开发团队提供技术支持,可以根据用户需要修改原理图和PCB,并升级为图像采集卡,数据播出卡等开发平台。团队也可支持应用程序开发。 项目、产品价格将根据需求定位、售后服务、技术支持及购买数量等方面具体情况而定,请与客服联系 北京青翼科技有限公司 在线客服:QQ:3329469943 销售电话:15811214467 公司网址:www.tsingetech.com 商务支持与服务邮箱:164772232@QQ.COM
以上是关于PCIE基于Riffa架构的PCIE项目的主要内容,如果未能解决你的问题,请参考以下文章