论文笔记图像分割和图像配准联合学习模型——DeepAtlas
Posted 棉花糖灬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记图像分割和图像配准联合学习模型——DeepAtlas相关的知识,希望对你有一定的参考价值。
本文是论文《DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation》的阅读笔记。
文章第一个提出了一个图像配准和图像分割联合学习的网络模型 DeepAtlas,该模型实现了弱监督的图像配准和半监督的图像分割。在图像配准时使用图像的分割标签作为监督数据,如果没有分割标签,则通过分割网络产生;而经过配准后的图像增加了在图像分割时可利用的训练数据的量,相当于是一种数据增强。该模型不仅在分割和配准的精度上有所提升,并且还可以在训练数据有限的情况下实现较好的效果。
一、记号
- I m I_m Im:浮动图像(moving image)
- I t I_t It:目标图像(target image)
- F R \\mathcalF_R FR:配准网络
- θ r \\theta_r θr:配准网络的参数
- F S \\mathcalF_S FS:分割网络
- θ s \\theta_s θs:分割网络的参数
- u = F R ( I m , I t ; θ r ) u=\\mathcalF_R(I_m,I_t;\\theta_r) u=FR(Im,It;θr):形变场
- ϕ − 1 = u + i d \\phi^-1=u+id ϕ−1=u+id:形变图,其中 i d id id 是恒等变换
- I m w = I m ∘ ϕ − 1 I_m^w=I_m\\circ\\phi^-1 Imw=Im∘ϕ−1:配准后的图像
- S t S_t St:目标图像分割标签
- S m w = S m ∘ ϕ − 1 S_m^w=S_m\\circ\\phi^-1 Smw=Sm∘ϕ−1:配准后图像分割标签
二、网络结构
DeepAtlas 的目的是当数据集中只有少量的分割标签可用时,通过联合训练来让分割和配准实现较高的精度。
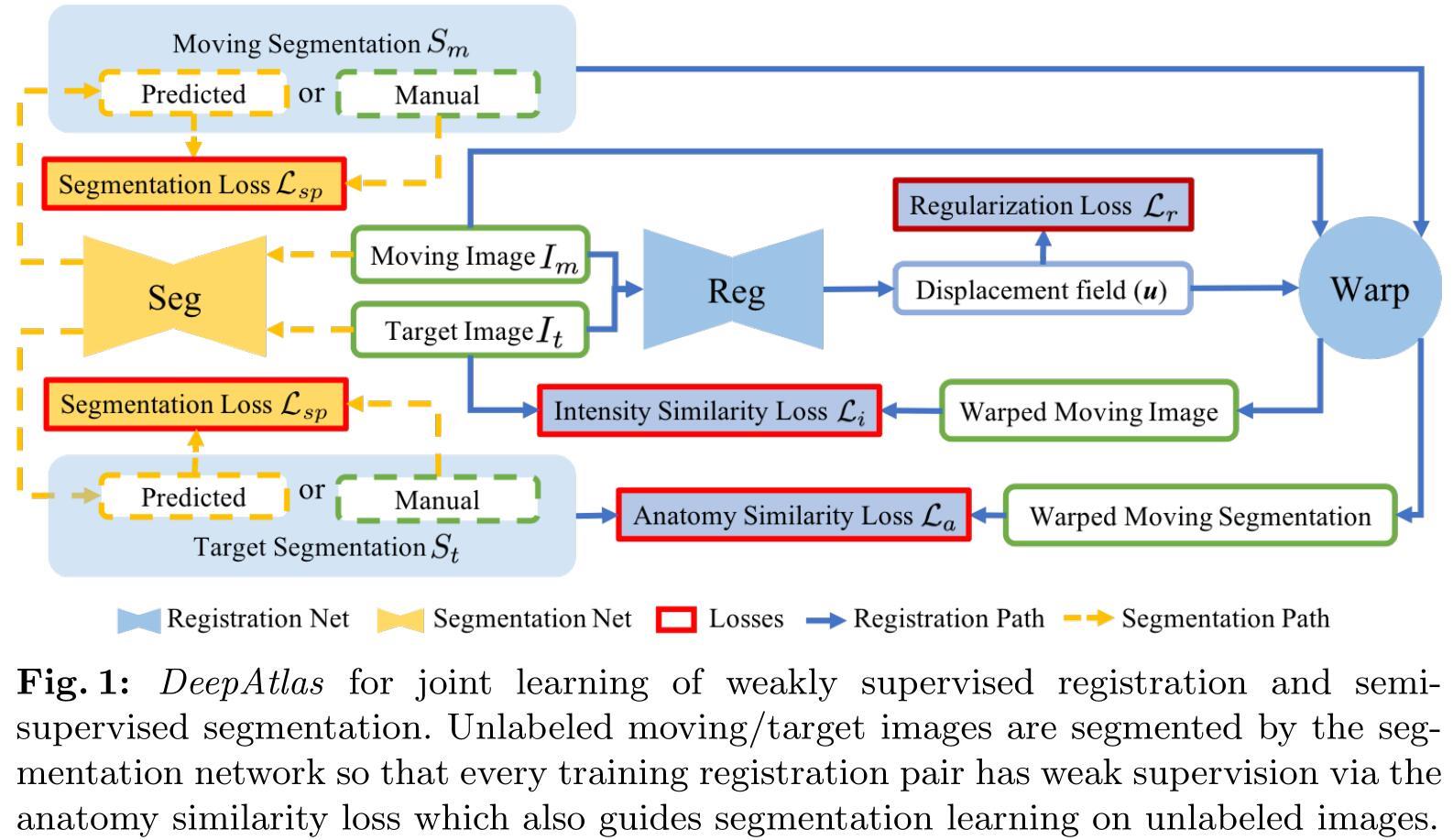
网络的结构如上图所示,蓝色的实线表示弱监督的配准,黄色虚线表示半监督的分割。
文章在附件中给出了分割网络和配准网络的具体结构,如下图左右两图所示:
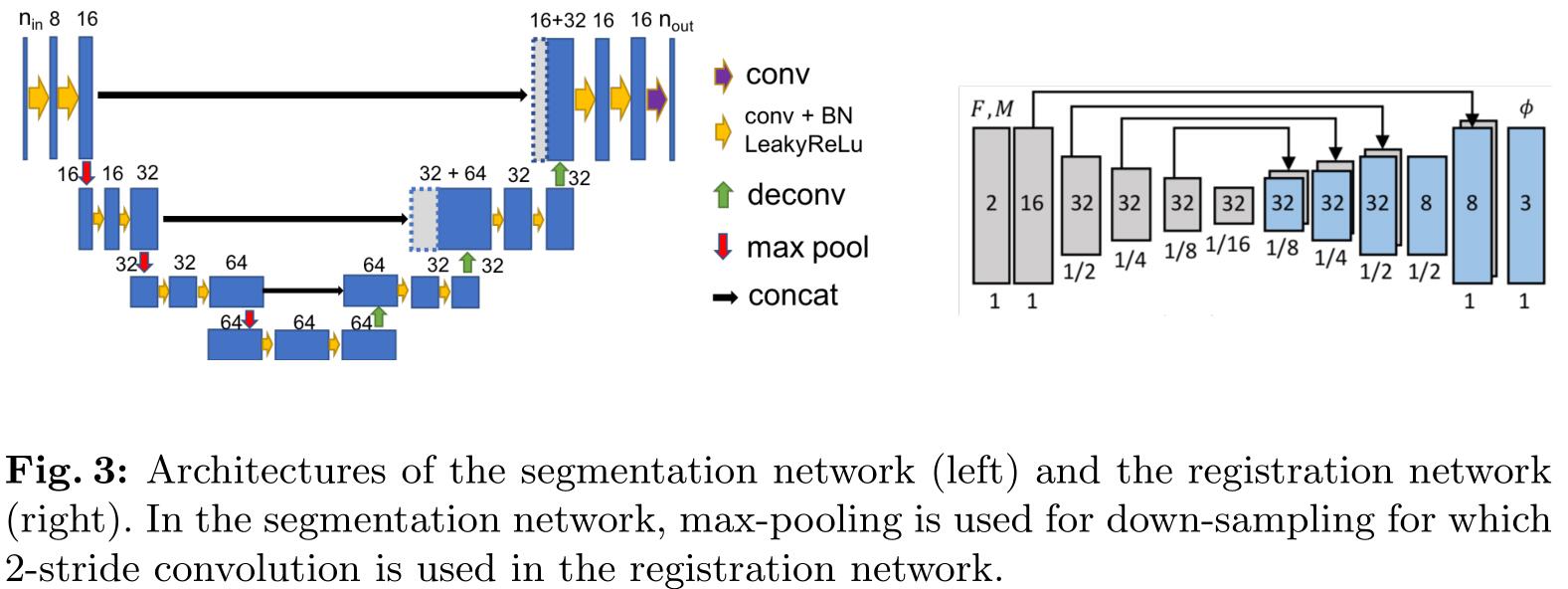
1. 配准网络
配准网络的损失主要有三个损失函数组成:配准正则损失 L r \\mathcalL_r Lr,图像相似度损失 L i \\mathcalL_i Li 和解剖损失(分割相似度损失) L a \\mathcalL_a La。配准正则损失 L r \\mathcalL_r Lr 可以让形变场 ϕ \\phi ϕ 变得光滑,图像相似度损失 L i \\mathcalL_i Li 用来评价浮动图像 I m I_m Im 和配准后图像 I m w I_m^w Imw 之间的相似度,解剖损失(分割相似度损失) L a \\mathcalL_a La 是目标图像分割标签 S t S_t St 和配准后图像分割标签 S m w S_m^w Smw 之间的相似度损失。
如此一来,配准学习的过程可以由下式表示:
θ
r
⋆
=
argmin
θ
r
L
i
(
I
m
∘
Φ
−
1
,
I
t
)
+
λ
r
L
r
(
Φ
−
1
)
+
λ
a
L
a
(
S
m
∘
Φ
−
1
,
S
t
)
\\theta_r^\\star=\\underset\\theta_r\\operatornameargmin\\left\\\\mathcalL_i\\left(I_m \\circ \\Phi^-1, I_t\\right)+\\lambda_r \\mathcalL_r\\left(\\Phi^-1\\right)+\\lambda_a \\mathcalL_a\\left(S_m \\circ \\Phi^-1, S_t\\right)\\right\\
θr⋆=θrargminLi(Im∘Φ−1,It)+λrLr(Φ−1)+λaLa(Sm∘Φ−1,St)
其中
λ
r
,
λ
a
≥
0
\\lambda_r,\\lambda_a\\geq0
λr,λa≥0。
2. 分割网络
分割网络的输入是一张图像
I
I
I,输出相应的分割结果
S
^
=
F
S
(
I
;
θ
s
)
\\hatS=\\mathcalF_S(I;\\theta_s)
S^=FS(I;θs),分割网络的损失主要有两个损失函数组成:解剖损失
L
a
\\mathcalL_a
La 和有监督分割损失
L
s
p
\\mathcalL_sp
Lsp。解剖损失和配准网络中的相同,有监督的分割损失
L
s
p
(
S
^
,
S
)
\\mathcalL_sp(\\hatS,S)
Lsp(S^,S) 是分割网络的分割结果
S
^
\\hatS
S^ 和人工分割结果
S
S
S 之间的相似度损失。但是浮动图像
I
m
I_m
Im 和目标图像
I
t
I_t
It 的分割标签的存在情况有多种可能,所以相应的损失函数也存在以下四种情况: 以上是关于论文笔记图像分割和图像配准联合学习模型——DeepAtlas的主要内容,如果未能解决你的问题,请参考以下文章
L
a
=
L
a
(
S
m
∘
Φ
−
1
,
F
S
(
I
t
)
)
and
L
s
p
=
L
s
p
(
F
S
(
I
m
)
,
S
m
)
,
if
I
t
is unlabeled;
L
a
=
L
a
(
F
S
(
I
m
)
∘
Φ
−
1
,
S
t
)