逻辑回归算法
Posted 优化大师傅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归算法相关的知识,希望对你有一定的参考价值。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
class LogisticRegression:
def __init__(self):
self.coef_ = None
self.intercept_ = None
self._theta = None
def _sigmoid(self, t):
return 1 / (1 + np.exp(-t))
def fit(self, x_train, y_trian, n):
def J(theta, x_b, y):
y_hat = self._sigmoid(x_b.dot(theta))
return -np.sum(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat)) / len(y)
def dJ(theta, x_b, y):
return x_b.T.dot(self._sigmoid(x_b.dot(theta)) - y) / len(y)
def gradient_descent(x_b, y, initial_theta, alpha=0.01, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
iter = 0
while iter < n_iters:
gradient = dJ(theta, x_b, y)
last_theta = theta
theta = theta - alpha * gradient
if abs(J(last_theta, x_b, y) - J(theta, x_b, y)) < epsilon:
break
iter += 1
return last_theta
x_b = np.hstack([np.ones((len(x_train), 1)), x_train])
initail_theta = np.zeros(x_b.shape[1])
self._theta = gradient_descent(x_b, y_trian, initail_theta, n_iters=n)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
def predict_prob(self, x_test):
x_b = np.hstack([np.ones((len(x_test), 1)), x_test])
return self._sigmoid(x_b.dot(self._theta))
def predict(self, x_test):
prob = self.predict_prob(x_test)
return np.array(prob >= 0.5,dtype='int')
def score(self, x_test, y_test):
return np.sum(y_test == self.predict(x_test)) / len(y_test)
# 鸢尾花数据集测试手写逻辑回归算法
iris = load_iris()
x = iris.data
y = iris.target
# 由于逻辑回归只能处理2分类问题,截取分类为0,1,保留x2个特征方便可视化
X = x[y < 2, :2]
Y = y[y < 2]
plt.scatter(X[Y == 0, 0], X[Y == 0, 1])
plt.scatter(X[Y == 1, 0], X[Y == 1, 1], color='r')
plt.show()
x_train, x_test, y_train, y_test = train_test_split(X, Y)
logistic = LogisticRegression()
logistic.fit(x_train, y_train, n=1e6)
y_predict = logistic.predict(x_test)
score = logistic.score(x_test, y_test)
print(score)
print(y_predict)
print(y_test)
逻辑回归算法原理是啥?
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,测试验证这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)。回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。

Logistic回归模型的适用条件
1、因变量为二分类的分类变量或某事件的发生率,并且是数值型变量。但是需要注意,重复计数现象指标不适用于Logistic回归。
2、残差和因变量都要服从二项分布。二项分布对应的是分类变量,所以不是正态分布,进而不是用最小二乘法,而是最大似然法来解决方程估计和检验问题。
3、自变量和Logistic概率是线性关系。
以上内容参考:百度百科-logistic回归
参考技术A逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。
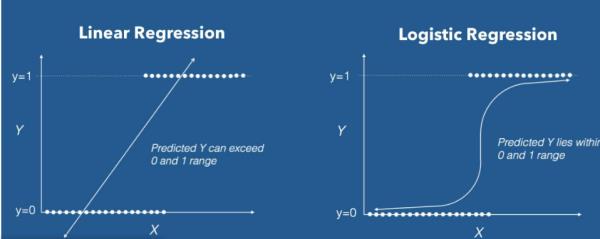
区别:
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。
正是因为如此,这两种回归可以归于同一个家族,即广义线性模型。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
参考技术B线性回归要求因变量必须是连续性数据变量;逻辑回归要求因变量必须是分类变量,二分类或者多分类的;
比如要分析性别、年龄、身高、饮食习惯对于体重的影响,如果这个体重是属于实际的重量,是连续性的数据变量,这个时候就用线性回归来做;如果将体重分类,分成了高、中、低这三种体重类型作为因变量,则采用logistic回归。
线性回归的特征:
回归分析中有多个自变量:这里有一个原则问题,这些自变量的重要性,究竟谁是最重要,谁是比较重要,谁是不重要。所以,spss线性回归有一个和逐步判别分析的等价的设置。
原理:是F检验。spss中的操作是“分析”~“回归”~“线性”主对话框方法框中需先选定“逐步”方法~“选项”子对话框。
以上是关于逻辑回归算法的主要内容,如果未能解决你的问题,请参考以下文章