推荐算法面试集锦--架构工程
Posted fengkuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法面试集锦--架构工程相关的知识,希望对你有一定的参考价值。
-
假如算力允许,召回和排序是否可以合并?
推荐系统核心阶段是召回和排序,召回解决的是从海量候选者中初步筛选出用户可能感兴趣的物品,然后再根据更细力度的特征进行排序精选出最可能产生正反馈的物品。那么,如果算力足够,是不是就不需要拆成两个阶段了呢?
从算法模型的理想情况来看,如果可以使用单个模型对所有用户均可做个性化打分的话,似乎是可以合并两个阶段。
问题在于除了计算能力限制外,实际问题的建模也不是这么理想,目前基于的AI算法模型的本质是基于对大数据样本的标签预测,如若真有一个端到端的模型可以学习到所有样本的个性化,通常在离线建模评估阶段,我们认定为这种是过拟合,通常不具备较好的泛化能力,是因为本身离线模型的样本集就是一个抽样集合,不太可能涵盖了各种类型的用户样本。那么我们就需要对问题域重新进行理解,会发现现实情况是,算法工程师在做的是从完美个性化推荐排序的问题域里,尽可能抽取覆盖大多数用户的兴趣及决策规律的样本子集,然后选择合适的算法模型去拟合这个样本集合。业务上的问题是尽可能让所有到访用户发生有效的正反馈,模型的问题是合理抽样问题域中的样本,尽可能去拟合样本集。很明显这并不是同一个问题,推荐个性化的问题中,算法建模无法脱离业务独立存在,那么就不可能存在这样一个单一的端到端的算法模型,足以将召回和排序的两阶段式合并。我们可以看出召回本质是在做什么?不仅仅是因为算力有限,无法从大规模物品候选集中选出最感兴趣的集合,也是因为召回的多样性,针对每个用户可以做到更全面的个性化(满足业务上尽可能让每个到访用户发生正反馈的目的),来弥补端到端建模中无法真正做到完全个性化的不足,而这恰恰是机器学习算法建模天生的缺陷。因而我们不得不采取一些业务上的算法策略,丰富召回的多样性与个性化。
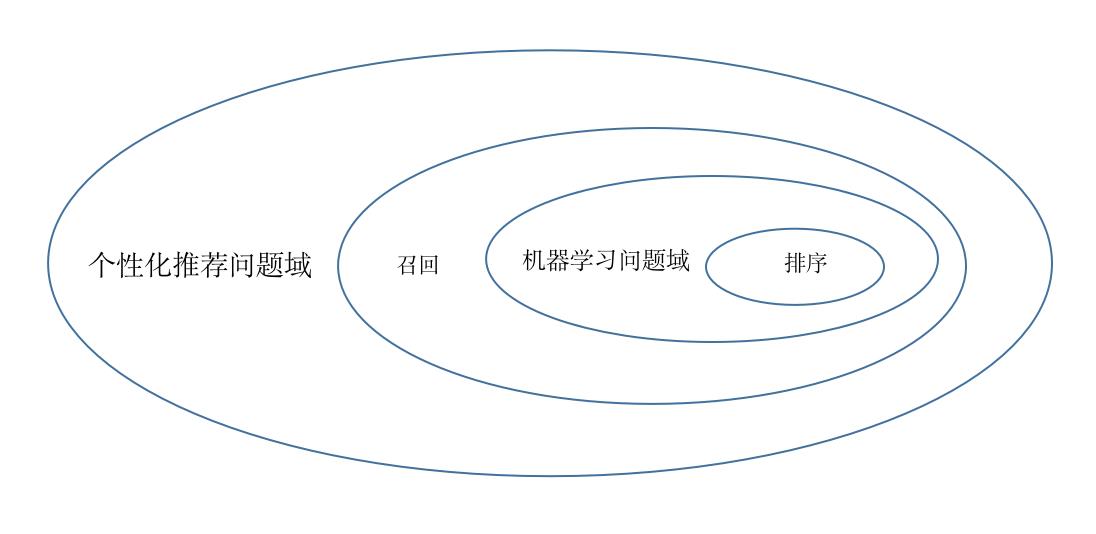
由上图的问题域范围图,我们可以再做更详细的探讨:- 个性化推荐问题域:无论是产品内的信息流还是其他资源位的曝光展示,我们都希望能够让用户能够产生正反馈(浏览、点击、点赞、收藏、购买等),这才是推荐系统的目标。那么机器学习算法在其中扮演的是什么角色呢?是在对子问题进行建模,这个建模的过程需要从真实的业务场景中提炼出用户产生正反馈决策的影响因子(对应模型中的特征),确定模型的优化目标,然后对真实的个性化推荐问题域进行采样构造数据集,我们会发现这个采样既有特征集采样,也有数据标签的采样。这种采样决定了什么?决定了以模型算法为代表的的机器学习问题域永远是个性化推荐问题的子问题,只不过这个子问题可能是目前看来最核心的、优化迭代ROI最大的子问题域。
- 召回问题域:为啥召回包含了机器学习问题域(对应召回阶段模型算法)?这里可以从业务、机器学习、数学的角度来理解,先构造样本集,然后通过机器学习模型算法来拟合逼近真实业务问题的特点决定了这个机器学习建模是后验的(执果寻因)。这里很容易看出机器学习解决真实业务问题的巨大死角:样本永远来自于已经曝光的User-Item,未曝光过的并不一定是不喜欢的。而曝光来自于什么?必然不能只通过单一算法模型(无论是召回算法还是排序算法还是合并两阶段的单一模型),因为这会导致信息茧房,为了解决这一问题(有时我们也称这个问题是EE问题),需要出圈,出圈来自于什么?来自于业务策略,运营策略等非单一模型外的模型策略,这种差异化推动着推荐系统朝着探索的方向发展,给了模型完善迭代的可能。
-
推荐系统的目标
从业务角度来看,推荐系统的核心目标是为了利用算法做用户和平台上Item的精准匹配,承担着推动业务发展的任务。但是对于一个具体的产品来说这不是唯一的目标,很多时候可能还要考虑产品定位和调性的问题,这也体现出了策略产品经理的作用,人工干预是离不开的。
基于对推荐中召回、排序两阶段是否可以合并的问题1的讨论我们可以看出,由于机器学习建模解决问题的后验性,意味着完美的精准匹配是不存在的,推荐系统永远在Exploitation和Experience的平衡中尽可能精准匹配,所以推荐系统在不同阶段侧重点其实不同。早期item较少,用户较少,重点在策略而非机器学习模型,这点显而易见,没有充足的样本喂给机器学习。中期User x Item矩阵变大,此时人工策略可能捉襟见肘,埋点数据丰富,样本量增加,变成机器学习算法的主场。配套的数据挖掘(用户分群,item分群,群匹配,样本集构造等)能力此时应该跟上,为模型提供更高的上限。一方面加强模型更新的频率,由离线到近实时、实时在线模型;一方面随着用户画像丰富完善,做更细致的分群等数据挖掘。 -
如何做 线上线性一致性对齐?
- 特征维度:上线前特征一致性校验;搭建线上特征监控体系;检查强偏置特征建模方式是否正确,比如pos bias,线下和线上不同;
- 模型维度:训练集与测试集是否存在重叠部分;是否出现穿越;训练集是否出现了过拟合
- 线上评估:线上指标统计时间窗口;实验平台分桶是否足够随机;inference调用是否正常
-
当发现核心指标发生异动时,应该如何定位问题并解决?
-
推荐系统中ES是如何作为召回组件的?
目前推荐系统中,可以实现两种召回方式,分别为实时召回和离线召回。实时召回主要采用了 Elasticsearch/MongoDB/Redis作为内容的存储。ES相对MongoDB和redis来说在搜索匹配上更具优势,支持相对复杂的实时相关性检索。
使用ES进行召回的优点:- ES支持过滤筛选,可基于不同业务场景设计对应的全局条件,可保证召回源头处数据合法性,提升召回数据的可利用率
- ES支持从多维度(如id、author、标签、时间等)进行相对复杂的查询匹配,还可自定义查询相关性算分方法,增加了召回的匹配上的拓展性和灵活性
-
ES的相关面试题
倒排索引:所谓的正排索引是从索引文档到关键词到内容,倒排索引则是相反从关键词到词频,位置,目录等信息,现在通常用于搜索的。由于互联网上的数据量无限大,不可能存储足够多的文档,所以正排索引用处不大。倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。lucene从4+版本后开始大量使用的数据结构是FST。
FST有两个优点:
1. 空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2. 查询速度快。O(len(str))的查询时间复杂度。索引文档的过程:
-
Flink相关面试题:https://zhuanlan.zhihu.com/p/138101642
-
重排序阶段打散算法有哪些?
- 桶打散:基于某个维度进行均匀打散,简单直接,破坏原先分数排序,末尾容易堆积
- 权重打散:对不同维度出现次数进行加权统计权重,调整得分
- 滑动窗口打散:局部滑动窗口内进行打散
- MMR:Maximal Marginal Relevance (a.k.a MMR) 算法目的是减少排序结果的冗余,同时保证结果的相关性。最早应用于文本摘要提取和信息检索等领域。在推荐场景下体现在,给用户推荐相关商品的同时,保证推荐结果的多样性,即排序结果存在着相关性与多样性的权衡。
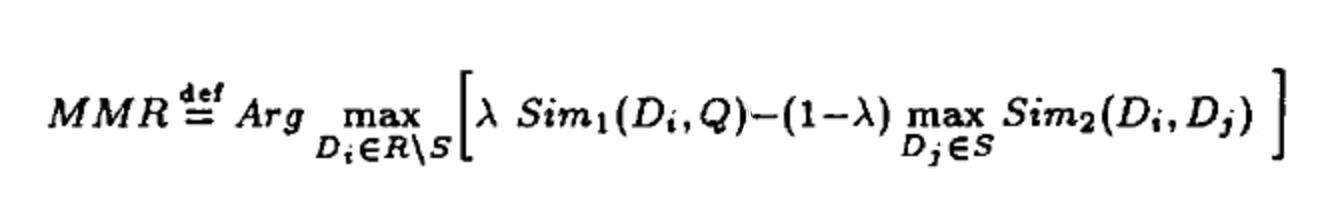
-
什么是ZAB协议?
ZAB 协议是为分布式协调服务ZooKeeper专门设计的一种支持崩溃恢复的一致性协议。基于该协议,ZooKeeper 实现了一种主从模式的系统架构来保持集群中各个副本之间的数据一致性。ZAB协议运行过程中,所有的客户端更新都发往Leader,Leader写入本地日志后再复制到所有的Follower节点。
一旦Leader节点故障无法工作,ZAB协议能够自动从Follower节点中重新选择出一个合适的替代者,这个过程被称为选主,选主也是ZAB协议中最为重要和复杂的过程。
深度学习/机器视觉/数字IC/FPGA/算法手撕代码目录总汇
目录
FPGA/数字IC手撕代码总汇
更新中
常用算法手撕代码总汇
更新中
FPGA工程师经典面试题
FPGA面试题79问
网上常见的FPGA面试题整理,总共58题(全部加了问题答案)
数字IC经典面试题
深度学习/人工智能/机器学习面试题
计算机视觉+人工智能面试笔试总结——深度学习基础题21~40
计算机视觉+人工智能面试笔试总结——深度学习基础题41~51
计算机视觉+人工智能面试笔试总结——目标检测/图像处理基础题
数字图像/计算机视觉面试题
计算机视觉图像处理面试笔试题整理——光线追踪&光线投射&路径追踪
以上是关于推荐算法面试集锦--架构工程的主要内容,如果未能解决你的问题,请参考以下文章