性能透明提升 50%!SMC + ERDMA 云上超大规模高性能网络协议栈
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能透明提升 50%!SMC + ERDMA 云上超大规模高性能网络协议栈相关的知识,希望对你有一定的参考价值。
编者按:当前内核网络协议栈有什么问题?新的协议栈是不是重新发明轮子?一个协议栈能否解决所有问题?适配所有场景?本文整理自 2022 年阿里巴巴开源开放周技术演讲,这里我们将自己的思考分享出来,和大家一起交流。
本文主要分为三部分:第一部分是我们为什么需要一个新的内核网络协议栈,我们是不是在重复发明轮子?第二部分是 SMC + ERDMA 的原理、优劣等等,快速为大家了解 SMC 技术。第三部分是 SMC-R 在网易 Curve 分布式系统的实践。
一、我们为什么需要一个新的内核网络协议栈?
当前内核网络协议栈有什么问题?新的协议栈是不是重新发明轮子?一个协议栈能否解决所有问题?适配所有场景?这里我们将自己的思考分享出来,和大家一起交流。

首先我想要抛出一个观点,没有一个网络栈是万能的,之于此没有银弹。要谈现状,离不开背景:
- 第一是 100G/400G 网络的普及,此时 CPU 是瓶颈。
- 第二是云、规模,当前越来越多的业务迁移到云上,云上支持传统 RDMA 网卡成本很高。
- 第三是 DPU,硬件卸载,承接第一点,CPU 成为瓶颈后,是否可以让网络栈将越来越多的逻辑卸载到网卡和 DPU 上,让 CPU 做更多更重要的事情。
我们如何平衡吞吐和时延?或者说如何用最少的 CPU 达到相同的吞吐,如何尽可能地降低时延。首先 Linux 内核的网络栈倾向于吞吐,而不是时延。提升吞吐很重的一点是,降低拷贝的开销。在大包吞吐的场景,我们很容易看到拷贝占据了 CPU 的绝大部分时间。而且内核网络栈的 context switch 开销,拷贝开销也会增加额外的时延。
那么这个问题变成了选择在内核态还是用户态实现一个网络栈?我想很多应用,或者说云上 99% 以上的应用使用的是 socket 接口,如果侵入性改造,对于用户态方案最大的壁垒。比如 DPDK 等,此时不仅仅是改造成本,也包括了运维成本、部署成本等等。当然用户态也可以劫持 socket 实现用户态协议栈,但此时 zero copy 等优势不在。并且同样需要改造,此处的改造是运维改造,调度改造和环境改造,这也是额外的成本。此时用户态的优势也不再显著。
软件 vs 硬件卸载?一开始 Linux 网络栈,例如 TCP 协议是从纯软件实现到越来越多的将功能卸载到网卡,甚至 TOE 完全卸载到网卡。如果提到卸载到网卡,是不是可以用一种更加成熟的硬件卸载方案?也就是 RDMA,也就是传统以太网卡 vs RDMA 网卡,部分卸载到成熟的完全卸载。RDMA 网络本身有规模的限制,我们可以在小规模把 RDMA 网络玩得很好。那是否有一种大规模 RDMA 的能力。我们现在看到的是阿里云发布的 ERDMA 网络,一种普惠、高性能、完全兼容 RDMA 的生态。我们借助 SMC + ERDMA 可以实现硬件卸载 RDMA 、大规模部署,二者相辅相成。
开箱即用 vs 应用改造?上面已经提到一部分,云上 99% 的应用使用的是 socket 接口编程,TCP 进行通信。绝大部分应用不可能投入大量成本改造适配新的网络栈,其中包括开发成本,测试成本(新的协议栈可能会有各种问题),部署和运维成本(例如 DPDK 环境,额外软件包的维护)等。此时还会让应用牢牢绑定在某个网络栈之上,后续迁移,或者遇到环境不支持的情况下,成本更高。所以我们分析后,得出的结论是,当前需要一个兼容 socket 接口,可以透明替换传统 TCP 应用的,硬件卸载的网络栈。利用云上大规模部署、DPU 硬件卸载、达成 100G/400G 网络的全新网络栈。
二、共享内存通信 SMC
有一点很重要,前面我们没有讨论,也就是所谓的数据通信模型。IPC 进程间通信,TCP 也是进程间通信的一种。我们按照第一性原理,拆分成不同的不可拆分的数据通信模型。对比这几种模型最佳实践下可能的性能数据。
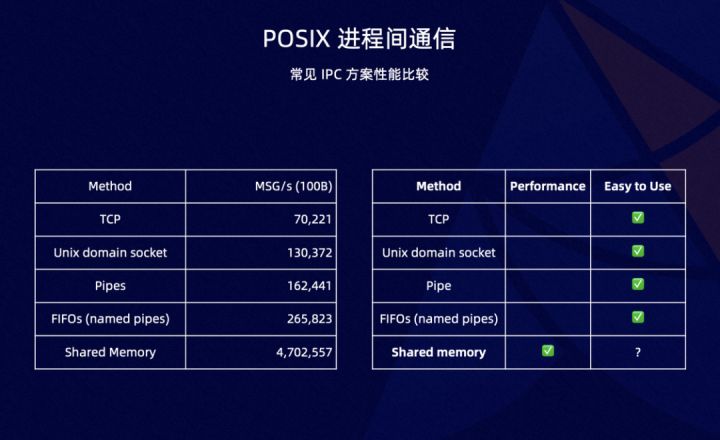
常见的是基于包的通信模型,例如最典型的 TCP,TCP loopback 性能不是特别理想,但是易用性毋庸置疑。我们之前有提到,绝大多数应用使用的是 socket 编程,其次是共享内存,这个在本机维度的 IPC 通信中,也是一种非常常见的方式。共享内存实现千差万别,但是总体来看,性能远远超过上面几种方式,但是易用性堪忧,第一是提到的实现方式不同、库不同、接口不同,和语言和运行时绑定,导致大部分共享内存的实现不具备跨越应用的普适性。我们快速回顾一下共享内存通信的模型:
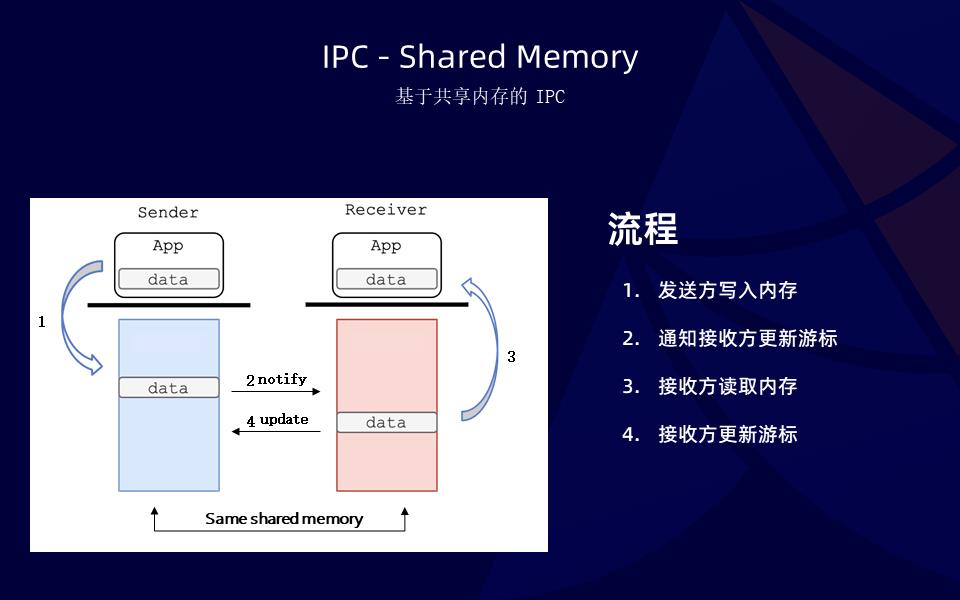
左边的图中,下面不同颜色的方块代表不同的内存,分别分成 sender 和 reciver 角色。首先发送方写入数据到这一块共享内存,之后通过某种方式,通知接收方数据写到了哪里、偏移量是多少,其次接收方按照游标位置读取或者拷贝走这一块内存上的数据,之后通知发送方,本地已经读取完成,下次写数据可以从某某位置开始。这样一次简单的数据通信就完成,同时是 zero copy,这里是单向,如果是双向,只需要维护两个内存区域即可。那么是否有一种技术可以帮助我们搬运内存,让下面两个方框的内存保持同步,从单机共享内存到远端共享内存?答案也就是之前提到的 RDMA,RDMA 本身就是远端直接内存方案的缩写。
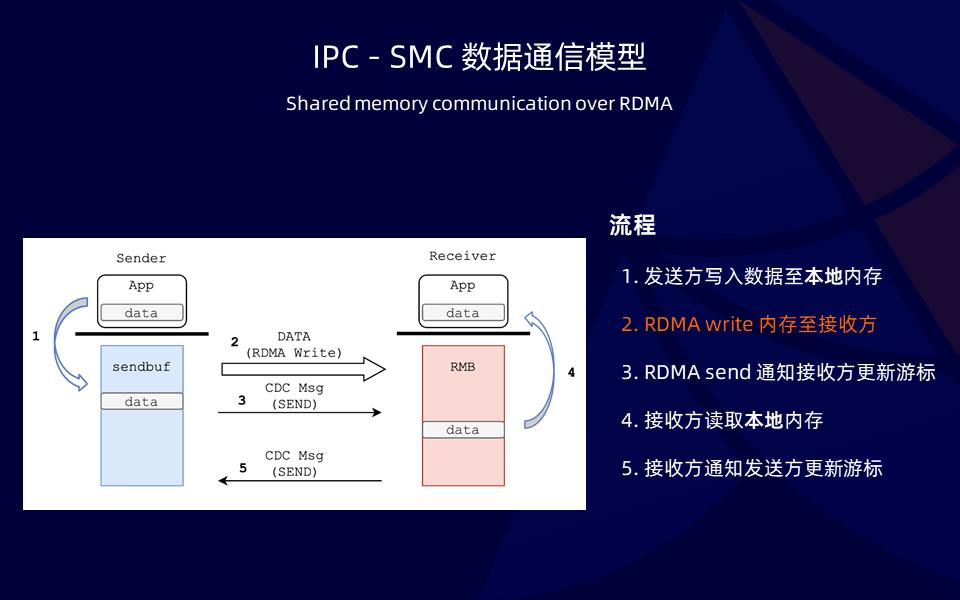
前面 4 步我们可以完成本地的共享内存通信,基于 RDMA,我们的数据模型只需要一个比较小的改动,也就是在第二步,通过 RDMA write 实现内存从本地同步到远端。这样本地和远端维护内存上的数据可以保持一致,同时通过 RDMA send 作为消息通知机制、通知游标更新。同时也可以实现 zero copy 硬件卸载。基于上面的分析,我们是不是可以基于共享内存同时兼容 socket,基于RDMA 硬件卸载实现这样一个可能高性能的网络栈呢?答案是肯定的,通过 SMC + ERDMA 构建云上高性能网络栈,为什么说 SMC + ERDMA 可以满足上面我们的结论呢?首先,我们快速了解一下 SMC
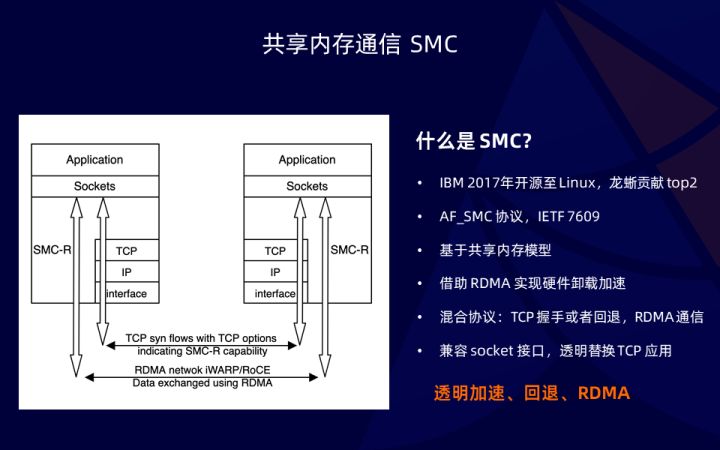
SMC 是 IBM 开源到 Linux 代码中,同时 IBM 也一同提出了 IETF RFC 7609,作为描述 SMC-R 协议是如何实现的。首先在上游社区中,龙蜥社区为上游贡献的补丁数排第二,其次,SMC 本身也是一种协议,Linux 下为 AF_SMC,可以直接在 socket 中制定使用,没有其他特殊的 hack 或者 tricky 的实现,和 TCP 等价。模型采用了共享内存技术,结合 RDMA 可以实现一次拷贝,硬件卸载的性能。同时最为重要的是,SMC 本身是一种混合协议,SMC 协议本身,需要借助某种更通用的协议建立 RDMA 链接,同时还需要提供一种 fallback 回退机制,如果没有 RDMA 支持,可以透明回退到 TCP。最后,SMC 兼容 socket,可以透明替换所有的 TCP 应用,应用无需改造,也无需配置,即可享受 SMC 带来的性能加速。通过上述特性,最大化兼顾性能和生态。SMC 可以在云上高性能和大规模部署,也离不开阿里云的 ERDMA。ERDMA 完全兼容 RDMA 生态,兼容 verbs 接口,verbs 应用可以无需改造。同时云上的 ERDMA 具备超大规模部署的能力,解决了传统 RDMA 网络的部署难题。

SMC 使用 verbs 接口,可以在云上直接使用 ERDMA,从而实现硬件卸载,高性能的网络栈 SMC 是如何使用 RDMA 的?
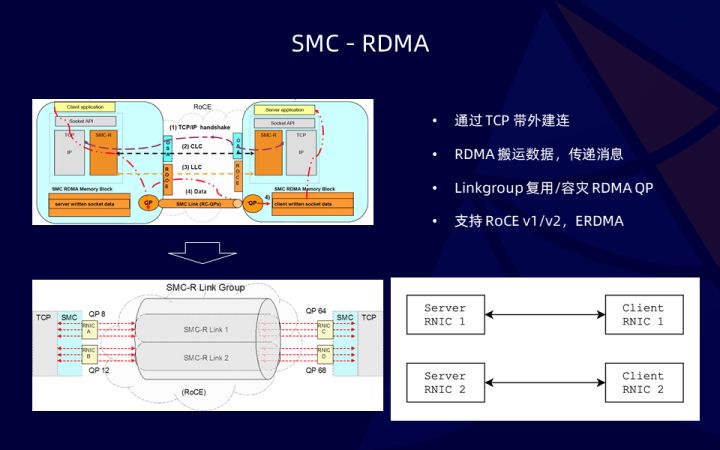
SMC 首先使用 TCP 带完建连,使整个 RDMA 链路可用,此时 TCP 链接可以用于回退,任何 RDMA 的问题都可以顺利回退到 TCP,确保 SMC 链接的可用。其次 RDMA 负责整个数据的通信,在内核态是 zero copy。SMC 有一次用户态-内核态拷贝。RDMA 技术的另一个问题是链接的规模,特别是 RC 模式下,链接的规模不是很大。SMC 通过 linkgroup,将 N 个链接映射到 1 个或多个 RDMA QP 之上,充分复用 QP 资源,也加快了控制路径创建 QP 慢的问题,最重要也具备了 linkgroup 多 QP 的容灾高可用的能力。最后 SMC 支持 RoCE v1/v2,龙蜥版本还支持 ERDMA,确保 SMC 既可以使用在云上,也可以使用在数据中心内部。我们多次提到了 SMC 基于 TCP 链接建连,那么 SMC 是怎么做的?
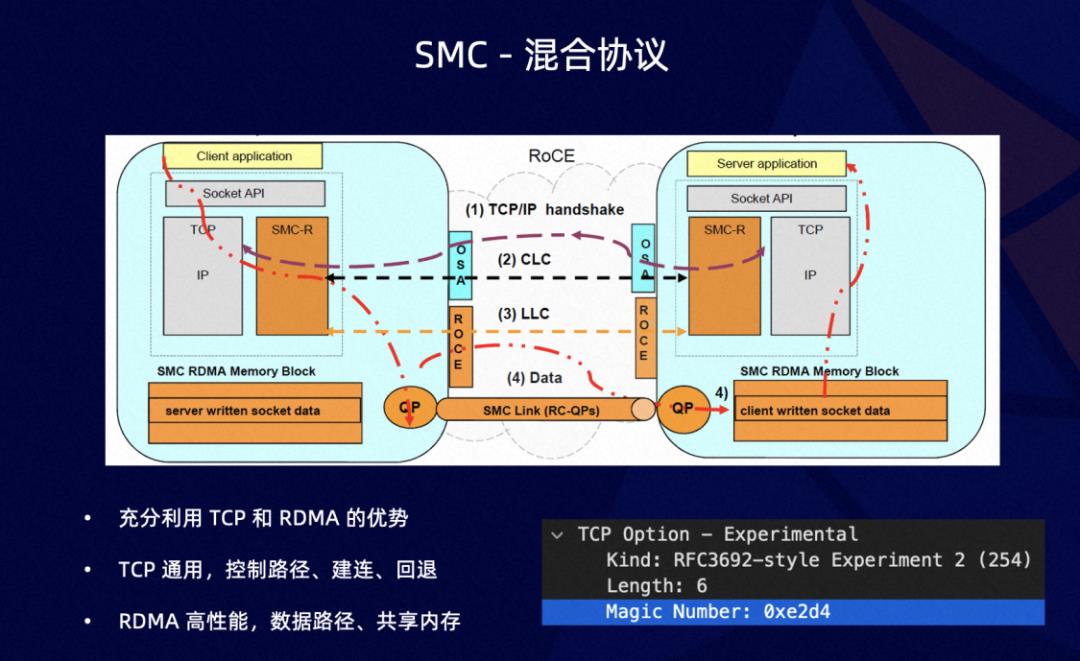
首先 SMC 本身是一种混合协议,协议底层包括 TCP 和 RDMA,充分运用 TCP 通用、兼容、可达率高、RDMA 高性能的优势。同时这一条 TCP 链接也可以帮助 RDMA 不可用或者建连错误后,快速回退到 TCP 模式,对于应用完全透明。SMC 通过 TCP SYN 包中的特定的 TCP options 标注是否支持 SMC 能力。如果支持会接下来交换 RDMA 建连所需的信息,SMC 兼容 socket 之后,是如何透明替换 TCP?
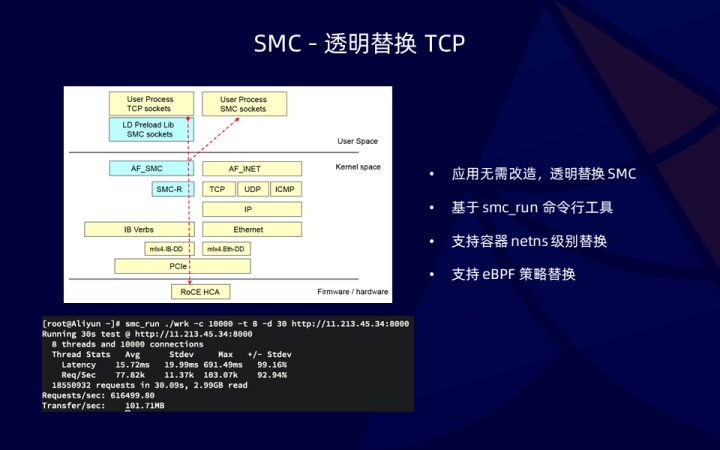
首先 AF_SMC 和 AF_INET 是在同一层级。对外暴露的接口和性能完全一致,应用可以在创建 socket 的时候直接使用 AF_SMC,与使用 TCP 时完全一致。应用不仅可以显示的制定 AF_SMC,也可以使用 smc_run 命令,快速将 TCP 替换成 SMC,如左图所示,任何应用都可以透明改造,无需任何适配,SMC 模块也会自动载入到内核。其次支持 netns 维度的替换,支持容器场景下的加速。也支持 eBPF 的策略替换,通过 eBPF 编写规则匹配所需的应用特征,选择性的替换成 SMC。对于一些不重要,不想要占用 SMC 资源,或者不适合 SMC 的场景,可以使用这种方式。SMC 回退机制,也是 SMC 为什么能够替换 TCP 重要的一个特性。
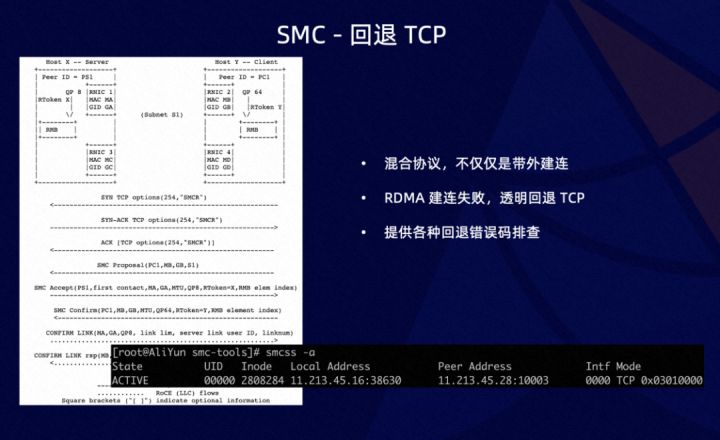
上图左边可以看到,SMC 首先创建 TCP 链接,经过 TCP 的握手后,才会进行 SMC 握手。如之前所提到的是,SMC 是混合协议,在 RDMA 建连失败后,可以快速透明的切回到 TCP。同时也提供了各种错误码,帮助应用排查问题,例如 RDMA 网卡问题,还是资源问题等。谈了这么多 SMC 自身的特性,那么 SMC 的性能如何?下面的测试是在阿里云上 ERDMA 网卡和 SMC 对比 TCP 的性能。
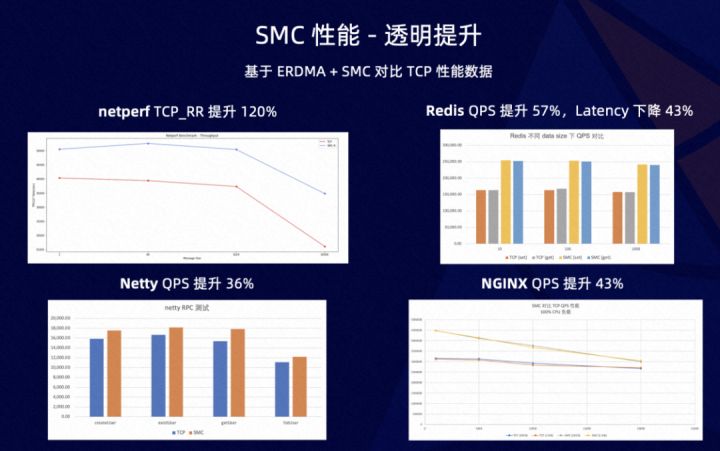
例如常见的 netperf microbenchmark 有一倍以上的性能提升。Redis 和 Netty 这种常见的基础组件有 30% 到 50% 的 QPS 提升,时延也显著下降。nginx 也有 40% 左右的性能提升。这些性能提升,都是在应用无需任何改造,透明替换成 SMC 下进行的测试。接下来我们聊一下我们龙蜥社区在 SMC 上所做的工作。

2021 年 11 月开始在社区密切参与开发和稳定性工作,当前贡献共计 70 多个补丁,排在 IBM 之后为第二。首先我们从头到尾优化了 SMC 的性能,包括短链接性能,包括吞吐和一些 syscall,CQ 中断打散等优化,最终 microbenchmark 综合性能提升了 357%,这里是对比的 SMC 之前的版本,对比 TCP 可以参考刚才的数据。其次是更多的场景支持,包括云原生、ERDMA、容器网络等等,拓宽了上游社区 SMC 的使用场景。最重要的是,极大地提升了稳定性,我们一直在持续看护上有社区,解决了数十个 panic 问题,彻底解决了遗留的 link 和 linkgroup 问题,同时也在持续看护 SMC。龙蜥社区我们有 CI/CD 持续不断的测试,能够成为一个产品级别的协议栈。大家可以访问我们的仓库(地址见文末),使用 HPN 中我们不断优化的 SMC 版本。
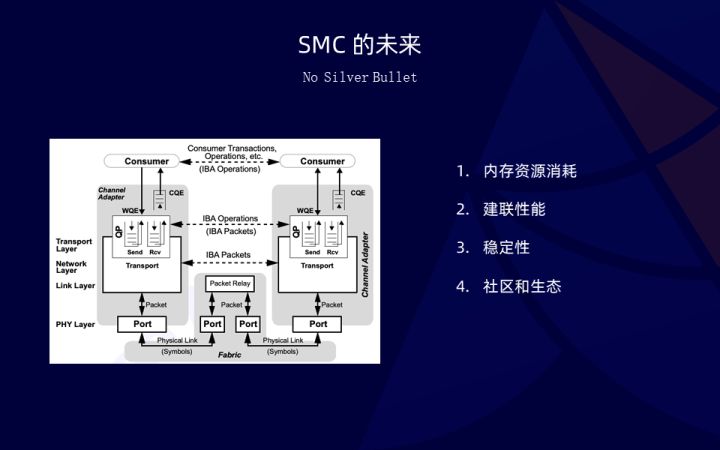
接下来我们谈一谈 SMC 的未来。回到分享的开始,SMC 同样也不是银弹。SMC 基于 RDMA 技术,本身也有 RDMA 引入的各种各样的问题。第一是内存消耗,SMC 本身需要一致维护一块比较大的连续内存区域,用来实现共享内存通信,内存消耗显著大于 TCP。其次是 SMC 的建连性能,还是会受制于 RDMA RC 模式的建连性能,这一块我们会持续不断的优化,相关优化我们会陆续推送到社区。其次是稳定性,SMC 不同于 TCP 在业界广泛使用多年。有很多问题没有被发现,我们当前也在借助 SMC CI/CD 帮助我们发现问题。
三、SMC-R 在网易 Curve 存储系统的实践
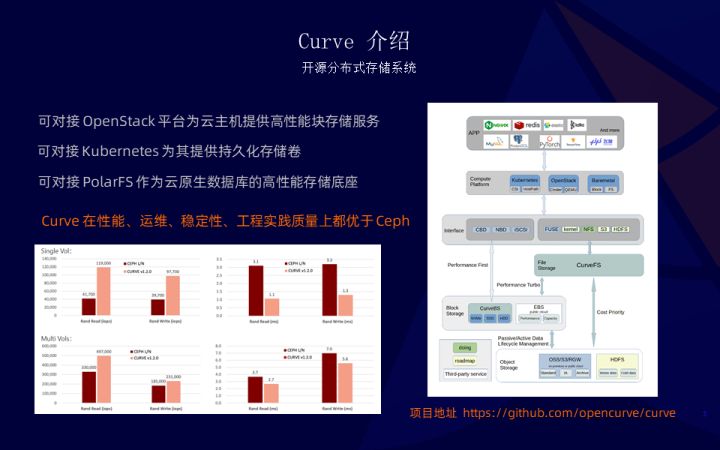
首先介绍一下 Curve。Curve 是一个开源分布式存储系统,可对接 OpenStack 平台为云主机提供高性能块存储服务,可对接 Kubernetes 为其提供持久化存储卷,可对接 PolarFS 作为云原生数据库的高性能存储底座。Curve 在性能、运维、稳定性、工程实践质量上都优于 Ceph。下面介绍 Curve 的网络通信:
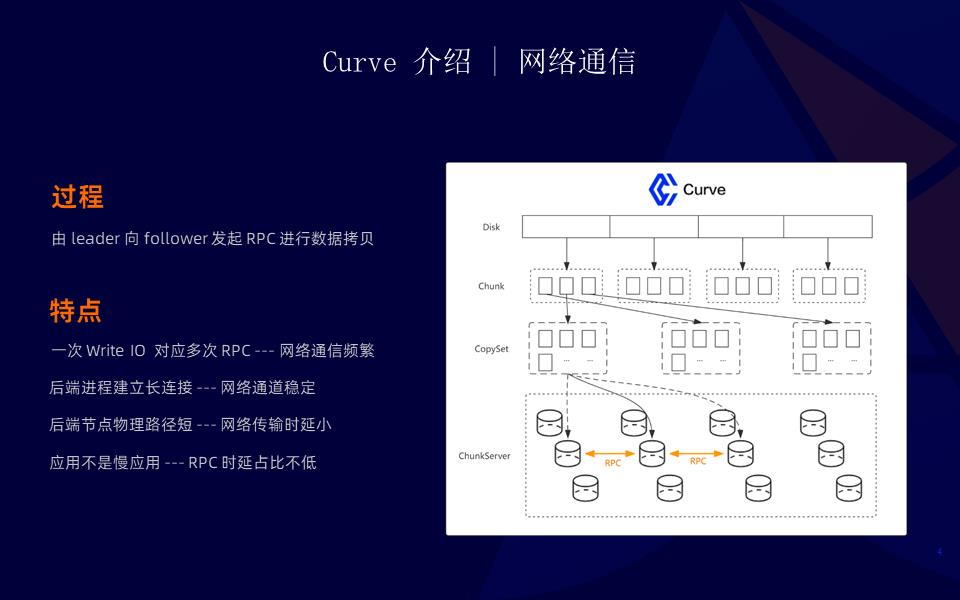
通信过程为由 leader 向 follower 发起 RPC 进行数据拷贝。特点是:网络通信频繁、网络通道稳定、网络传输时延小、RPC 时延占比不低。因此我们调研了几种网络加速选型:其中 SMC-R 可以实现透明替换,无侵入,并且提供较好的性能。
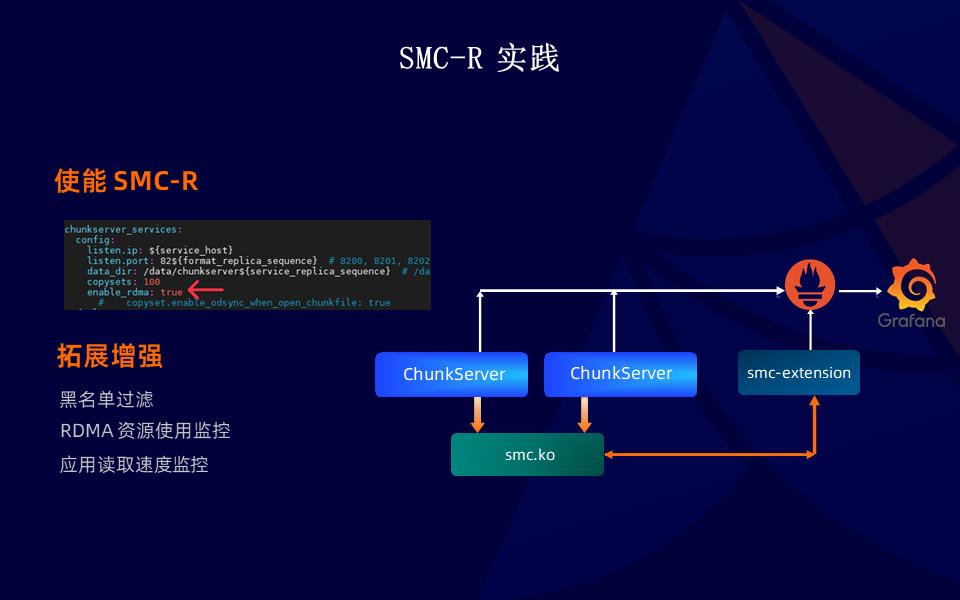
我们使用 SMC-R 改造了 Curve 并使能。同时扩展了黑名单、资源监控和读取速度监控等能力。

我们使用 Curve E2E 测试,在 3 Volume 256 depth randwrite case 下,对比 TCP 提升了 18.5% 的性能。最后,以上为大家介绍了我们为什么需要 SMC,SMC 的原理和性能以及 SMC 在网易 Curve 的最佳实践。对于 SMC 而言最重要的是社区和生态,在此欢迎大家使用并参与龙蜥社区和 SMC 社区,一同打造 SMC 高性能网络协议栈。
相关链接地址:
高性能网络 SIG 地址: https://openanolis.cn/sig/high-perf-networkSMC
代码仓库链接: https://gitee.com/anolis/hpn-cloud-kerne
本文为阿里云原创内容,未经允许不得转载
以上是关于性能透明提升 50%!SMC + ERDMA 云上超大规模高性能网络协议栈的主要内容,如果未能解决你的问题,请参考以下文章
系列解读 SMC-R :融合 TCP 与 RDMA 的 SMC-R 通信 | 龙蜥技术
转帖AMD Zen 3处理器IPC性能提升17% 浮点性能大涨50%
128核云原生新力作:Ampere® Altra® Max性能参数公布,提升50%!
性能提升60%↑ 成本降低50%↓ 个推分享Spark性能调优实战经验