在低容错业务场景下落地微服务的实践经验
Posted 阿里云云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在低容错业务场景下落地微服务的实践经验相关的知识,希望对你有一定的参考价值。
作者:禾连健康
“健康体检是一个低容错的场景,用户到医院体检,由于 IT 原因导致无法完成预约的项目,会对用户体验造成极大的影响。”*
——禾连健康 CTO 邓志豪
禾连健康成立于 2014 年,是一家从体检场景切入的健康管理服务公司。对于医院,禾连提供的是围绕体检检前、检中、检后的一套 SaaS 服务;对于企业,提供的是团体体检、健康管理,李锦记、普华永道都是禾连的客户;对于家庭,提供的则是健康管理 APP。目前,禾连已经覆盖全国 200 多个城市,2000 多家医院。
禾连健康经历了哪些技术发展阶段?
第一个阶段:宏应用。从 0 到 1,迭代速度很快,同时故障也很多,业务需要禾连快速迭代并验证,怎么快怎么来,当时还用过阿里云聚石塔提供的一个容器管理服务,也算是容器化的雏形。总结来看,关注速度,但是会出现技术债务、故障多、达不到业务的预期。
第二个阶段:微服务化。当禾连对接的医院越来越多后,故障也更多了,客户抱怨很大,那时候开发整天在“救火”。随后,禾连开始做模块化的解耦和服务拆分,引入了 Dubbo 和 Nacos,但当时对业务的理解还是不够深刻,服务拆的有问题,导致服务交叉调用非常多,出现几乎所有接口都会调用到的超级服务,对稳定性有害。总结来看,对业务理解不深刻的微服务拆分,治标不治本。
第三个阶段:微服务重构。以横向的订单、落单、数据同步为主,重新梳理了模块和服务,同时部署架构换成了 K8s,并把用于服务治理的一些中间件替换成阿里云微服务引擎 MSE 这类云服务 [ 1] ,这个时候,整个系统总体就比较稳定了。总结来看,围绕业务来构建微服务,结合云的优势,提升了开发运维效率和线上稳定性。
低容错的体检业务有哪些不一样的技术挑战?
低容错是禾连的业务特点。例如,用户到医院体检,由于 IT 原因导致无法完成预约的项目,会对用户体验造成极大的影响,不仅是体检,其实整个医疗行业都有着低容错的特点。另外,对于大多数人而言,体检的频率一年也就1-2次,是非常低频的场景,因此流量也非常低。而低流量带来的问题是,灰度发布几乎是无效的,甚至全量发布都可能无法发现 bug,有些 bug 会在代码发布一年以后才会被发现。
因此,禾连首先要解决复杂逻辑的问题,必须做模块化、做解耦。
但如果只做业务解耦,那么实现模块化就足够了。例如,如果使用的是 Java 语言,将 Java 模块分为 JAR 包,用 Maven 管理不同依赖即可。但是,早期很多技术架构是通过单一的包支撑不同业务,业务模块多、业务不隔离。没有做微服务拆分时,可能会出现企业业务代码有问题,导致医院容错较低的业务崩溃,这对业务来说,是难以接受的。
因此,禾连直接实现了服务化,将服务拆分开,有公共的基础服务可以调用,不同业务之间不会互相影响。服务化不仅实现了业务解耦,也实现了服务分层,保障履约的核心服务。例如,针对容错率非常低的业务,可以构建专门针对问题场景的保障服务。同时,可以对服务做独立质检,而如果打包在一起则无法做独立的质检。
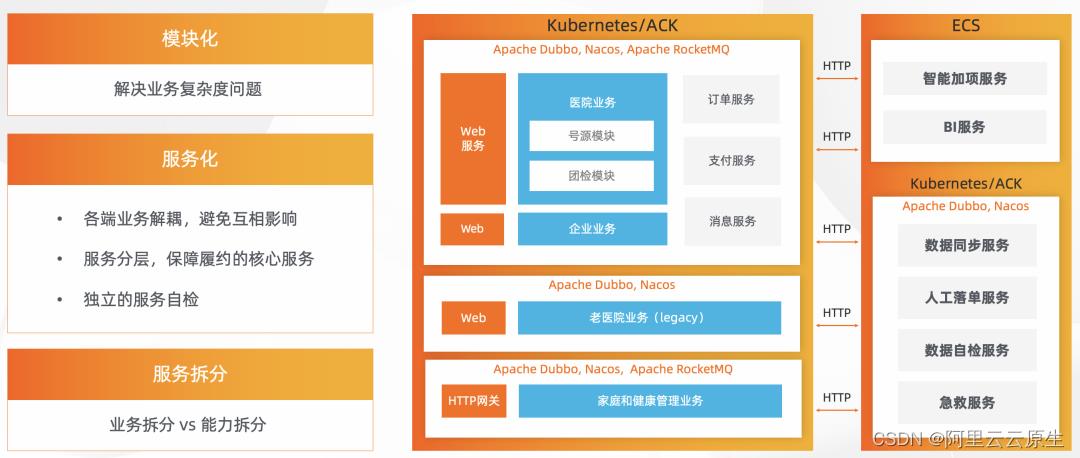
服务拆分主要有两种模式,一种为按照业务拆分,一种为按照能力拆分,不同业务可以互相调用。最终,禾连的架构如上图所示。以按照能力拆分为主,按照业务拆分为辅。比如最前端是 web 服务,蓝色块是业务核心迭代的业务服务,底层按照能力拆分订单、支付、消息三种服务。往下一层与业务较远的,比如医院数据同步服务、人工履约服务,是自建的独立服务。
业务迭代最频繁的服务与相对稳定的服务各自区分独立,两边通过 HTTP 打通,业务集群内使用 Dubbo 做 RPC,Nacos 做注册和配置中心,RocketMQ 做异步消息。
微服务演进过程中的实践经验
微服务上,禾连使用的是 Dubbo + Nacos 这套技术栈。

Dubbo 是一个 基于 Java Interface 的 RPC 框架,对于 Java 程序员而言,只需加简单的注解即可成为微服务,于是在团队中推行。同时,调用几乎不侵入代码,将 @Autowire 改为 @DubboReference 即可注入服务。Nacos 在 Dubbo 的集成非常完善,只需几行配置即可使用,控制面板简单易用,与 Dubbo 一样均为中文社区,对于程序员的门槛更低。
早期,禾连自行搭建社区版 Nacos 曾遇到较大性能瓶颈,当时的 Dubbo2 服务模型基于接口,一个接口、一个函数就会带来一个服务,流量非常大。阿里云的微服务引擎 MSE 帮助禾连扛住了 Dubbo 的压力,它具有良好的兼容性,后续禾连跟随社区升级至 Dubbo 3,解决了 Dubbo 2 服务模型的问题。另外,从内存视角看,MSE 具有出色的调优能力,使业务性能提升 4 倍,降低了资源成本。
禾连服务大量的医院,每个医院的需求不确定、也不尽相同,会存在大量的特性开关。此类开关的操作非常危险,一般由开发人员进行配置,而 MSE 很好地解决了痛点。MSE 的特性开关可以做动态配置,无需重启应用。同时可以一键与 KMS 阿里云密钥管理服务相结合,对数据进行加密存储,但是用户无感知。

HTTP 网关主要解决协议转换的问题。禾连的 App 前端业务逻辑重,无需做任何结果封装,只要暴露服务能力即可。因此,基于开源的 Apache ShenYu 做了改造,将 HTTP 协议转为 Dubbo ,同时支持 POST/GET,将鉴权和授权逻辑都放至网关。
DevOps 方面,K8s +镜像发布回滚使用了 ACK[2],持续集成 使用了云效 CI ,为禾连带来了极高的发布效率,一周最多时会发布 20-30 次,单次发布时间从原先的 2-3 小时降低至 8 分钟内。 另外,禾连基于 Dubbo 做了服务隔离,例如,同一个服务可以部署两个版本,代码和使用方式均一致,实例不同。两个服务均有独立内存,一个服务故障时,不会影响到另外一个相同的服务。但该能力目前依然较弱,控制面能力的增强是未来的发展方向。
微服务未来规划
未来,禾连希望能够实现 Service Mesh 的控制面。
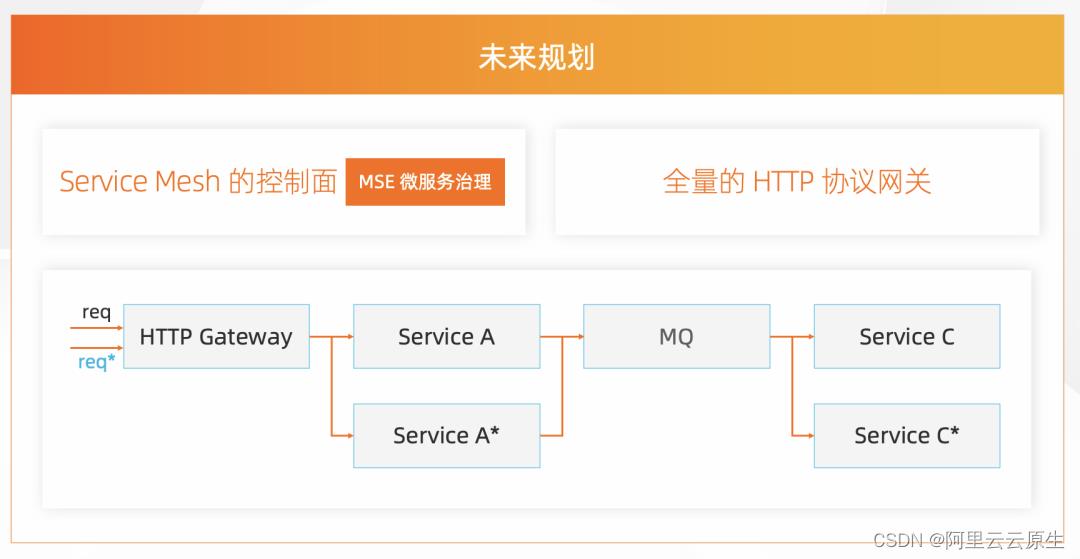
如上图所示,比如服务请求到达时,如果是 req*,则希望它路由至特殊版本 ServiceA* 。请求经过 MQ 之后发出的消息不能被 Service 消息接收,而是应被 Service* 接收,实现全链路的路由能力。目前阿里云的 ASM 提供的 Istio 托管具备以上能力,也提供了基本的 Dubbo 治理能力 [3 ] , 后续也将探索在 ASM 中如何进行融合演进。
实现 Service Mesh 的目的是降低测试环境成本。当前,禾连的大集群里有 7-8 套测试环境供各个业务小组使用,每个小组各用一套,互不干扰,但成本过高。如果能实现全链路的路由,每个开发小组只要做服务的测试环境发布,使用打标流量即可实现发布。
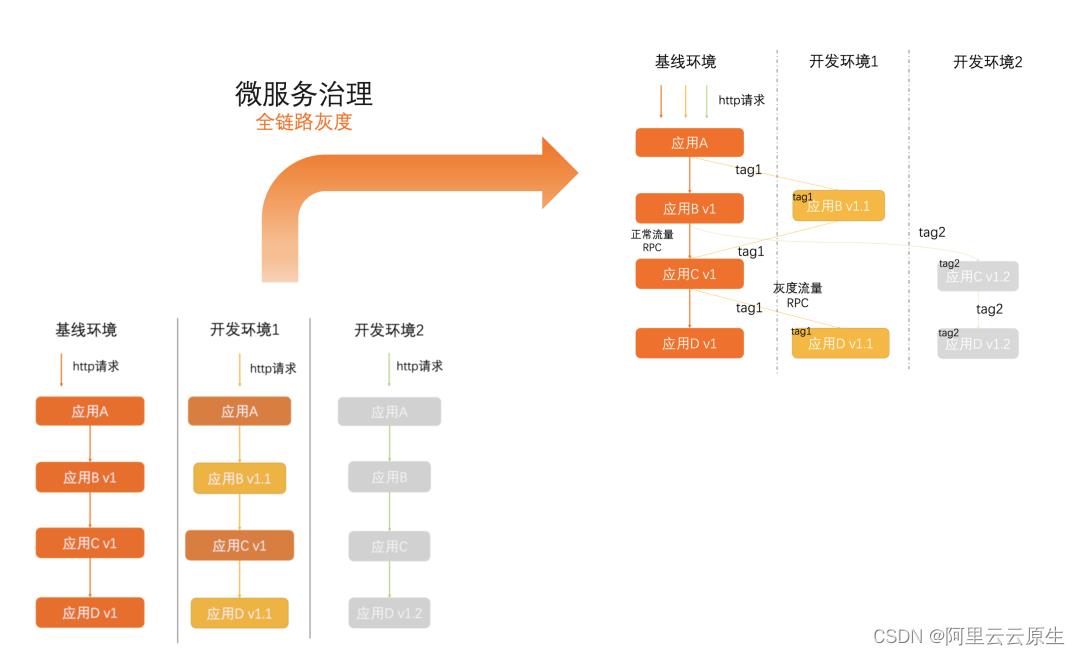
参考目前业界的实践,全链路的灰度路由,可以通过在网关层面识别流量并打标、每个测试环境都有单独的标签;每一跳服务调用传递流量标签,并在每一跳调用时,根据流量标签和对端机器标签做不同策略的匹配路由。最终,禾连可以做到每个环境,只需要部署当前环境修改后的服务,最大限度地重用基线环境的服务,降低了总体成本。
另外,禾连将实现全量 HTTP 网关。从未来趋势看,前端越来越重,无需后端做 web 层,将后端服务直接暴露给前端即可。因此,禾连考虑将所有 web 层替换成 BFF 网关,期待紧密跟进社区的步伐,联合云原生社区一起向前发展。
参考链接:
[1] https://www.aliyun.com/product/aliware/mse
[2] https://www.aliyun.com/product/kubernetes
[3] https://help.aliyun.com/document_detail/214749.html
点击此处 ,立即前往微服务引擎官网查看更多~
微服务架构实践之服务容错
引子
我们都知道软件开发的中,不仅仅要解决正常的业务逻辑,更重要的是对异常状态的处理,这关系到我们程序的稳定性和容错性,在引入我们的微服务后我们的错误处理机制又面临了新的挑战,如图所示,微服务中,多个服务之间可能存在着依赖关系,而底层的服务可能被多个服务所依赖,从而一个服务的失效可能导致多个服务不可用,从而进一步导致整个系统的不可用,面对这个问题,选择正确的服务容错处理方案就显得格外重要了,今天我们就来讨论服务容错的设计和响应的几种模式.
设计原则
我们再来思考一下,容错在我们设计上需要的功能,容错的处理并非一个通用的模式,所以在面对不同的场景的时候,我们就应该在设计上避免底层不可用带来的影响,让依赖的服务的故障不影响用户的正常体验,比如搜索功能故障,可以暂时禁用,并给予友好提示,而不应该因此造成整个系统的不可用.其次应该同时让系统能应对这个错误,并具有恢复能力,比如故障的服务可能在一段时间后会恢复正常后,对应的依赖服务应有所感知并进行恢复.
经典的容错模式
当然经过多年的实践,业界已经存在了一些优秀可靠的设计模式,下面简单介绍一下,我们可以根据我们的场景选择正确的模式
超时重试
超时 这个模式是我们比较常见的,比如在HTTP请求中我们就会设置一下超时时间,超过一定时间后我们就后断开连接,从而防止服务不可用导致请求一直阻塞,从而避免服务资源的长时间占用.
重试 这个模式一般和超时配合出现,一般使用在对下层服务强依赖的场景,否则不建议使用.利用重试来解决网络异常带来的请求失败的情况,超时次数不应该太多,超时时间的时间也比较关键,不能太长最好是 根据服务的正常响应时间来定,否则可能会导致长时间无响应,拖垮系统.
实现方式比较简单,通过设置请求时间和记录请求次数来判断是否需要重试即可,框架实现有Spring retry
限流
我们应用的异常情况不仅仅是内部原因引起的,每个应用的处理请求的能力是有限的,如果外部流量过大也会导致我们的服务不可用,这时候就需要限流了.常见的限流有控制并发数量和限制访问速率.
控制并发,属于常用的限流方式,比如有1000个请求,但是同时我们只允许100个请求进行处理,而其他的请求可以直接返回不进行处理,这样保证了我们的并发数和我们的设计的负载水平相一致.在实现中我们可以使用Java的信号量来控制进入的请求数量.
控制速率 控制访问的流量,效果上也是一样的,实现上有所区别,一般使用令牌桶算法实现,简单来说就是每秒会有N个令牌放入桶中,并且桶的大小是固定的也就是我们要限制流量的大小,多余的令牌会丢弃,每个请求会消耗对于请求的字节大小的令牌,如果令牌不足了请求就会被丢弃,从而实现访问控制.
舱壁隔离
这个模式借鉴造船行业的经验,在造船业人们往往利用舱壁将不同的船舱隔离起来,这样如果一个船舱破了进水,只损失一个船舱,其它船舱可以不受影响.
** 线程隔离** 就是了这个模式的思想,在开发过程中我们对每个不同的服务分配不同的线程池,比如serviceA分配了10个serviceB分配了20个,如果serviceA的线程用完了对serviceB也不会有影响,并不用占用另一个的资源,如果没有这种隔离,serviceA出现异常后就可能占用了其他服务的资源,从而影响整个系统.
熔断器
熔断器模式类似我们家里的电路保险丝,如果出现异常熔断器会打开,所有的请求都会直接返回,而不会等待或阻塞.在我们的项目当中,如果服务不可用会导致大量的请求等待,阻塞重要的系统资源CPU内存等,并进一步消耗资源使系统的其他服务也不可用,而熔断器会对异常状态直接返回,从而减少这种资源的浪费,同时如图所示,熔断器还可以有一种半开的状态,当熔断器打开后,会定时接受一部分请求来检测系统是否恢复,然后正常就会关闭熔断器,恢复正常使用了.
实际使用中我们经常使用熔断器模式来实现微服务的优雅降级,Netflix开源的组件[Hystrix](https://www.oschina.net/p/hystrix)就很好的实现了这一模式.回退
以上所有的模式都会出现异常,针对这些异常的处理方式也是一种模式 叫做回退模式, 回退的策略主要有
快速失败 直接抛出异常,适应于非数据类的服务和非强依赖的服务.
故障沉默 返回空数据或者默认值,适用于可降级的场景,比如推荐系统直接返回空也不影响业务
自定义处理 根据实践情况定义处理的策略,是返回缓存数据还是使用备用方案等,适用于系统的关键流程
总结
系统的容错性对于高可用的系统架构格外重要,在我们的实践业务中应用这些模式的可单独使用也可灵活组合,当然发现容错处理后及时发现系统异常的监控也格外重要.
出处:https://my.oschina.net/jayqqaa12/blog/918526?_t=t
以上是关于在低容错业务场景下落地微服务的实践经验的主要内容,如果未能解决你的问题,请参考以下文章