模型思维2-中心极限定理的应用
Posted LuckyZhouStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型思维2-中心极限定理的应用相关的知识,希望对你有一定的参考价值。
1、什么是中心极限定理
[]用样本来估计总体(任何一个样本的平均值,将会约等于其所在总体的平均值)
[]样本的平均值成正态分布
2、应用条件
[]事件相互独立
[]事件之间的值是有限的
3、样本来估计总体
用样本来估计总体。任何一个样本的平均值将会约等于其所在总体的平均值。
一个正确抽取的家庭样本应该能够反映中国所有家庭的情况,里面会包含收入高的公司高管,也会包括普通的员工,快递小哥、警察以及其他人,这些人出现的频率与他们在人口构成中的占比相关。因此,我们能够推测,这个包含1000个中国家庭代表性样本的家庭财富的平均值约等于总体的平均值。
4、样本平均值成正态分布
如果我们连续抽取100次包含1000个家庭的样本,并将它们的平均值的出现频率在坐标轴上标出,那么我们基本可以确定在总体平均值周围将会呈现正态分布。
取样次数越多,结果就越接近正态分布;而且样本大小越大,分布就越接近正态分布。
5、样本来估计总体标准差
现在我们已经可以用样本来估计出总体平均值。现在我想用样本来估计出总体的标准差,该怎么办呢?
我们已经知道,一个数据集的标准差是数值与平均值的偏离程度。
当你选择一个样本后,相比总体,你拥有数据的数量是变少了,因此,与总体中的数值偏离平均值的程度相比,样本中很有可能把较为极端的数值排除在外,这样使得数值更有可能以更紧密的方式聚集在均值周围。也就是说,样本的标准差要小于总体标准差。所以,为了更好的用样本估计总体的标准差,统计学家就将标准差的公式做了像下面图中公式中这样的改造。

即原来的标准差公式是除以n,为了用样本估计总体标准差,现在是除以n-1。这样就是的标准略大。一般用字幕s表示用样本估计出的总体标准差。
很多书上都会把除以n-1的标准差叫做样本标准,其实会给很多人造成误解。其实这个样本标准差的目的是用于估计总体标准差。
你可能会疑惑,那我什么时候标准差除以n还是n-1呢?
那就要看你使用标准差的目的是什么。
如果你只是想计算一个数据集的标准差,那么就除以n,例如你有100个毕业与清华人的收入,只是想了解这100个人构成的数据集的波动大小,那你就用除以n的标准差公式。
如果你想把这100个人当成一个样本,用这个样本来估计出总体(所有毕业与清华人的收入)的标准差,那么就除以n-1的标准差公式。
举个例子:
如果我从毕业于清华大学中抽取100个人作为样本1,然后我计算出标准差。那么这个标准差就是用来描述这100个人组成的数据集的波动大小。
我连续刚才重复抽取样本的动作,最后抽取出2个样本,每个样本都有100个人。对每个样本计算平均值,这样就有2个平均值。
这2个平均值其实组成了1个新的数据集,就是所有的“样本平均值”。然后对这2个平均值数据计算出标准差。就是标准误差。
6、样本平均值概率图
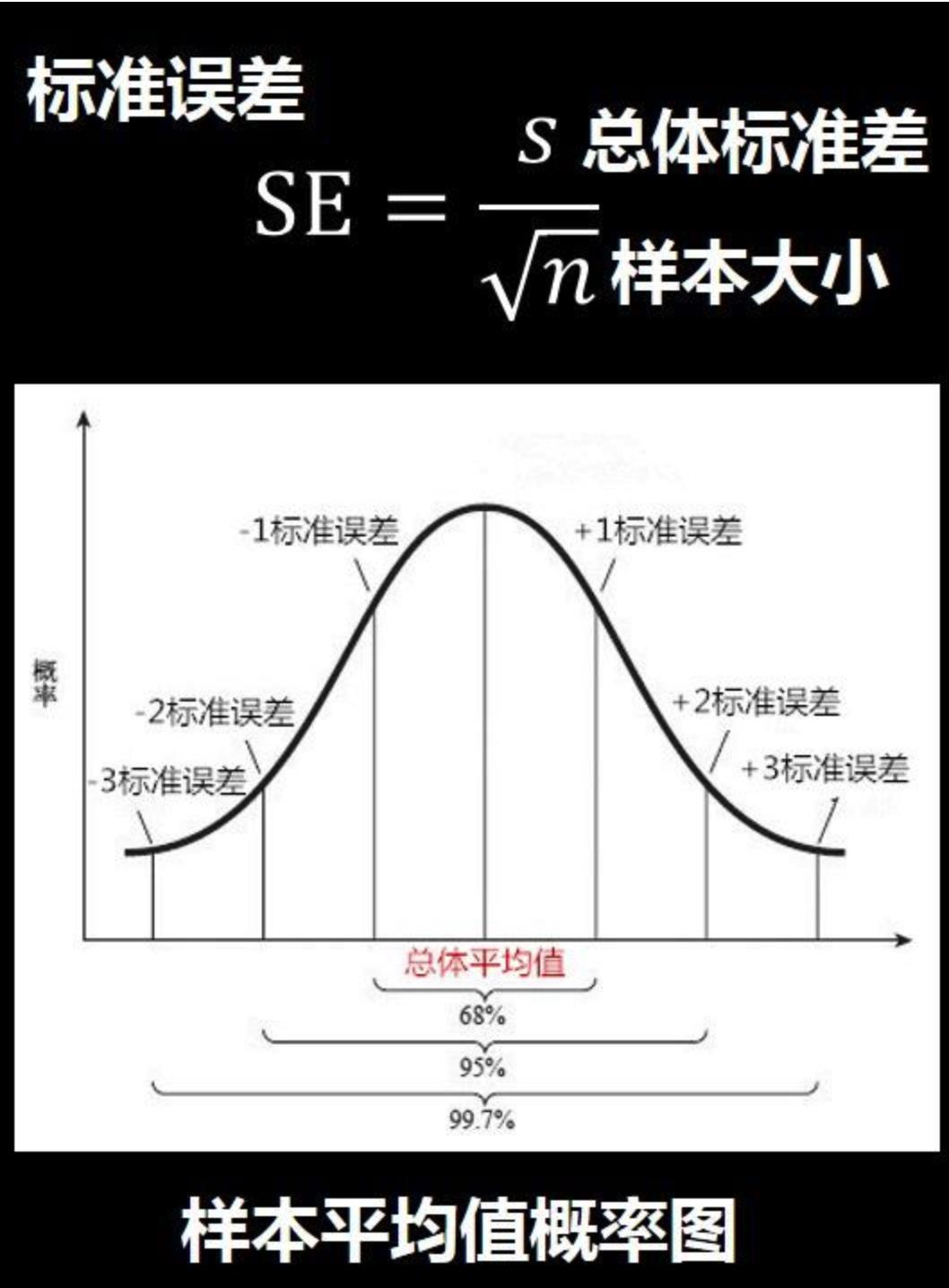
上图的含义是:
1)有68%的样本平均值会在总体平均值一个标准误差的范围之内
数值范围(总体平均值-1个标准误差,总体平均值+1个标准误差)
2)有95%的样本平均值会在总体平均值的两个标准误差的范围之内
(总体平均值-2个标准误差,总体平均值+2个标准误差)
3)有99.7%的样本平均值会在总体平均值3个标准误差的范围之内。
(总体平均值-3个标准误差,总体平均值+3个标准误差)
6、售出多少个飞机票合适呢?
例如我们飞机票的座位数目是380个,每个人来机场的概率是90%,那么我们卖出多少个座位合适呢? 比如我们卖出400个座位,由于该场景是二项分布,所以我们可以得出
平均值=360 标准差=6
那么根据上面的概率分布图,我们可以得出以下结果:
68%的概率,人数会在[354,366]之间
95%的概率,人数会在[342,372]之间
99.7%的概率,人数会在[342,378]之间
7、反推某个样本适合符合总体趋势
假如某个样本的平均值减去总体的平均值,大于3个标准误差。根据99.7%的样本平均值会处于总体平均值3个标准误差的范围内,因此我们可以得出该样本不属于总体。
文章参考自:https://www.zhihu.com/question/22913867/answer/250046834
以上是关于模型思维2-中心极限定理的应用的主要内容,如果未能解决你的问题,请参考以下文章