FPGA知识点汇总(verilog数字电路时序分析跨时钟域亚稳态)
Posted m0_47757655
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FPGA知识点汇总(verilog数字电路时序分析跨时钟域亚稳态)相关的知识,希望对你有一定的参考价值。
FPGA十分擅长同时做简单且重复的工作(并行计算)人工智能就有许多重复性、需要并行计算的工作如模式识别、图像处理,在通信领域,FPGA的低延时、可编程、低功耗的特点
开发流程:RTL设计,仿真验证,逻辑综合,布局布线,时序收敛(面积约束),硬件测试。
基本结构:可编程输入/输出单元,基本可编程逻辑单元(由查找表和寄存器构成),嵌入式块RAM(Block RAM),丰富的布线资源(片内互联线),底层嵌入功能单元(模块,如PLL、DSP),内嵌专用硬核(通用性较弱的才有),
可扩展资源:存储器资源(块RAM),数字时钟管理单元(分频、数字延迟、时钟锁定),算数运算单元(高速硬件乘法器、乘加器),高速串行IO接口,特殊功能模块(PCLE或者DDR),微处理器。
FP与ASIC区别:1.前者设计人员只需要根据需求选择相应的器件,然后设计逻辑电路,并下载到FPGA器件中去,实现需求的电路功能,随时可以修改电路功能。2.后者设计人员根据特定的电路需求,设计专用的逻辑电路,在设计完成后生成设计网表,交给芯片制造厂家流片。在流片之后,内部逻辑电路就固定了,芯片的功能也就固定的。
用途
FPGA主要用于要求快速迭代或者小批量产品,或者作为ASIC的算法验证加速。
ASIC用于设计规模大,复杂度比较高的芯片,或者是成熟度高,产量比较大的产品
成本
小批量需求时,单片FPGA成本低于ASIC,随着产品量的增加,单片ASIC成本逐步降低
功耗
在相同工艺条件下,FPGA要大于ASIC。FPGA,尤其是基于占用大量硅面积的、每个单元六个晶体管的静态存储器(SRAM)的查寻表(LUT)和配置元件技术的FPGA,其功耗要比对等的ASIC大得多
速度
FPGA内部是基于通用的结构,根据RTL设计选择内部布局布线,当然通用必然导致冗余。
ASIC是根据设计需求,最优化cell逻辑资源,并且做到最优布局走线,降低走线延迟和CELL延时。
面积
定制化的电路设计和工艺使用ASIC面积小于FPGA。
2.28
Cache:高速缓冲存储器。由于 CPU 的信息处理速度常常超过其它部件的信息传递速度,所以使用一般的 DRAM 来作为信息存储器常常使 CPU 处于等待状态,造成资源的浪费。 Cache 就是为了 解决 这个问题而诞生的。在操作 系统 启动以后,CPU 就把 DRAM 中经常被调用的一些系统信息暂时储存在 Cache 里面,以后当 CPU 需要调用这些信息时,首先到 Cache 里去找,如果找到了,就直接从 Cache 里读取,这样利用 Cache 的高速性能就可以节省很多时间。
SRAM:异步静态随机存储器,不用刷新,速度快,价格贵,主要用于制造Cache
DRAM:动态随机存储器,
SDRAM:同步动态随机存储器。
对比:SDRAM使用电容的电荷存储特性存储数据,SRAM使用CMOS晶体管存储数据。
一位存储芯片的功耗:SDRAM << SRAM 整体功耗: DRAM >> SRAM
容量:SDRAM >> SRAM
小梅哥DDR
上拉电阻可以让输入信号为高电平。
输入到查找表,查找表到触发器(时序逻辑)或直接到输出(组合逻辑)
可编程原理
PLD:可编程逻辑器件,修改具有固定内联电路的逻辑功能来进行编程
FPGA:修改一或多根内连线的布线,更适合实现多级的逻辑功能
查找表单元内部结构,采用了多路选择器,若有四个输入ABCD,则有16种路径。
多路选择器的原理及编程方法(HDLbits)
3.1
FPGA内数据传输模型
时序分析:时序分析的目的就是通过分析FPGA设计中各个寄存器之间的数据和时钟传输路径,来分析数据延迟和时钟延迟的关系。一个设计好的系统,必然能够保证整个系统中所有的寄存器都能够正确的寄存数据。
数据和时钟传输路径是由EDA软件,通过针对特定器件布局布线得到的。
时钟设计要点:3.8号
物理约束:IO接口约束,如引脚分配、布局约束以及配置约束。
时序约束:涉及FPGA内部的各种逻辑或走线的延时,反映系统的频率和速度的约束。
时序约束两个作用:
告知EDA软件,该设计需要到达怎样的时序指标,然后EDA软件会根据时序约束的各个参数,尽力优化布局布线,已达到该约束的指标。
协助EA软件进行分析设计的时序路径,以产生相应的时序报告。
重点
Tsu:建立时间,目的寄存器自身特性决定,在时钟信号上升沿到达其他时钟接口时,其数据输入端(D)的数据必须提前Nns稳定下来,否则就无法确保数据正确存储。
Tco:时钟上升沿到达D触发器 到 数据输出到Q端(输出端)的延迟。
目的寄存器能够正确的接收源寄存器发射过来的数据,分析数据传输路径,建立时间余量基本公式:Tclk1 + Tco +Tdata (时钟、数据到达时间)<= Tclk + Tclk2-Tsu(数据需求时间);左边往右边移得:
令Slack = Tclk + Tskew – Tsu – Tco – Tdata >=0
3.2
尽量走全局时钟树(而不是分频出来的信号),但是不能保证进入每个寄存器的时间都一样。
skew时钟偏斜:全局时钟到目的寄存器和源寄存器时间的差值。Tskew= Tclk2-Tclk1
3.3
地址线和数据线
如1个16k X 8位的存储器,地址线:16k=1k*16=1024 x 16=214,需要14根地址线,数据线为8
SDRAM(Synchronous Dynamic Random-access Memory,同步动态随机存取内存),是有同步接口(Synchronous)的DRAM,系统读写能够同步;RAM为易失性存储器。
多bit数据跨时钟域:1.方把数据写到异步fifo,接收方从异步fifo里读出;(最好的
2.连续变化的信号,发送方转为格雷码发送,接收方收到后再转为二进制;
3.方给出数据,发送方给出握手请求,接收方收到后回复,发送方撤销数据。
4.DMUX 5.打三拍?
单it数据跨时钟域(慢到快、同频不同相):1.用快时钟打两拍,直接采一拍大概率也是没问题的,两拍的主要目的是消除亚稳态(不能完全消除);2. 边沿检测
单it数据跨时钟域(快到慢):握手(脉冲展宽)、异步FIFO、异步双口RAM,脉冲同步法;快时钟域的信号脉宽较窄,慢时钟域不一定能采到,可以通过握手机制让窄脉冲展宽,慢时钟域采集到信号后再“告诉”快时钟域已经采集到信号,确保能采集到;
3.4
同步FIFO深度计算:
FIFO_Depth >= Burst_length -Burst_length* (rd_clk/ wr_clk)*(rd_rate)
流水线问题:
(1)插入寄存器(触发器Flip-Flop,FF)去分割延迟比较大的组合逻辑,消耗了更多的触发器,组合逻辑资源不变(理论上);
(2)由于增加了寄存器,每增加一级寄存器就会对数据寄存一个时钟周期,所以输入到输出的延时增加;
(3)对于整体来讲,数据同时处理,速度提升,最大工作频率提高,是典型的面积换速度的思想。
面积优化:资源共享、寄存器配平、串行化
速度优化:流水线设计、寄存器配平、关键路径法、乒乓操作法、树形结构法
DFT简介
(可测性设计)
在芯片设计过程中,加入各种可测性逻辑,使芯片变得容易测试,找到存在制造缺陷的芯片,主要是为了找出在生产制作中引入的制造缺陷(短路、断路等)。
比如,在设计中加入一些MUX选择器逻辑,用于测试;
综合(Synthesis):完成HDL语言到硬件电路的转化,并生成综合网表;
比如,将异或逻辑使用底层的LUT实现,将D触发器映射为底层的FDRE(同步使能,同步复位的触发器Flip-Flop) 等;
实现(Implementation):主要是布局布线(Place & Route),布局是将综合后的器件约束到 FPGA 对应位置,布线是使用布线资源连接这些器件。
3.5
复习一个礼拜所学知识点;
组合逻辑电路出现的是竞争冒险问题。在一个组合电路当中,当某一个变量经过两条以上的路径到达输出端的时候,由于每条路径上的延迟时间的不同,到达终点的时间就会有先有后,这一现象称作竞争。格雷码 滤波电容 冗余项;
时序逻辑电路出现的是亚稳态问题。
3.6
SOPC可编程片上系统,SOPC的应用是一个软硬件协同设计的过程。对于硬件设计,需根据需求剖析算法用硬件描述语言实现相关算法并映射到FPGA上。软件设计则是做系统移植,编写驱动程序等。
STA静态时序分析,是芯片设计中的一个后端流程,通常对设计的电路的时序路径进行分析,区别与动态逻辑分析。
通用验证方法学(Universal Verification Methodology, UVM)是一个以SystemVerilog类库为主体的验证平台开发框架,验证工程师可以利用其可重用组件构建具有标准化层次结构和接口的功能验证环境。
建立时间:触发器时钟上升沿到来之前,数据输入端数据必须保持不变的时间;
保持时间:触发器时钟上升沿到来之后,数据输入端数据必须保持不变的时间;
亚稳态:触发器无法在某个规定的时间段内到达一个可以确认的状态。
对于时钟和异步复位信号,分析recovery恢复时间和removal移除时间
recovery恢复时间:在有效的时钟沿来临前,异步复位信号保持稳定的最短时间;
removal移除时间:在有效的时钟沿来临后,异步复位信号保持稳定的最短时间;
3.17二刷
3.7
Buffer缓冲寄存器
它分输入缓冲器和输出缓冲器两种。前者的作用是将外设送来的数据暂时存放,以便处理器将它取走;后者的作用是用来暂时存放处理器送往外设的数据。有了数控缓冲器,就可以使高速工作的CPU与慢速工作的外设起协调和缓冲作用,实现数据传送的同步。由于缓冲器接在数据总线上,故必须具有三态输出(逻辑“0”,逻辑“1”和高阻态。高阻态主要用来将逻辑门同系统的其他部分加以隔离)功能。
关键路径通常是指同步逻辑电路中,组合逻辑时延最大的路径(这里我认为还需要加上布线的延迟),也就是说关键路径是对设计性能起决定性影响的时序路径。
对关键路径进行时序优化,可以直接提高设计性能。对同步逻辑来说,常用的时序优化方法包括Pipeline、Retiming、逻辑复制、加法/乘法树、关键信号后移、消除优先级等解决。
静态时序分析能够找出逻辑电路的关键路径。通过查看静态时序分析报告,可以确定关键路径。(具体方法见探索者公众号)
3.8
时钟设计要点:
避免使用门控时钟或系统内部逻辑产生的时钟,多用使能时钟去替代。
对于需要分频、倍频的时钟,用器件内部的专用时钟管理单元去生成(PLL\\DLL)。
尽量对输入的异步信号用时钟进行锁存。
避免使用异步信号进行复位或置位控制。
提升系统性能的代码风格:
减少关键路径的逻辑等级(时序设计无法收敛)
综合后的RTL视图看,某关键路径的逻辑门延时过长,存在三级,若要优化,必须减少此路径的逻辑等级。
逻辑复制与资源共享
消除组合逻辑上的毛刺,可以引入寄存器,打一拍,但同样可能存在时序逻辑的问题。
3.9
存储器地址译码方法
其地址译码被分为片选控制译码和片内地址译码两部分。
用高位地址进行译码后产生存储芯片的片选信号;用低位地址译码实现片内存储单元寻址。
时序电路的状态转换表中,状态数N=3,则状态变量数最少为3
因为独热码编码,只有一位是1.二进制和格雷码都是4.
3.10
集成电路低功耗设计:
降频(工作频率); 降压;多电压(内部能用低电压就用);多阈值(Multi-TV,高速运算部分采用低阈值,运算快,普通部分采用高阈值,运算慢一点但节省功耗);门控时钟;
对于非关键路径,对延时不敏感,可以使用高VT(高阈值)的器件,则可以在满足时序的前提下,减小静态功耗。
3.11
门控时钟:
有效降低动态功耗,最低功耗设计方法之一,主要应用于低功耗设计领域。门控时钟在ASIC中使用较多,在FPGA使用较少,使用门控时钟会影响时序分析。
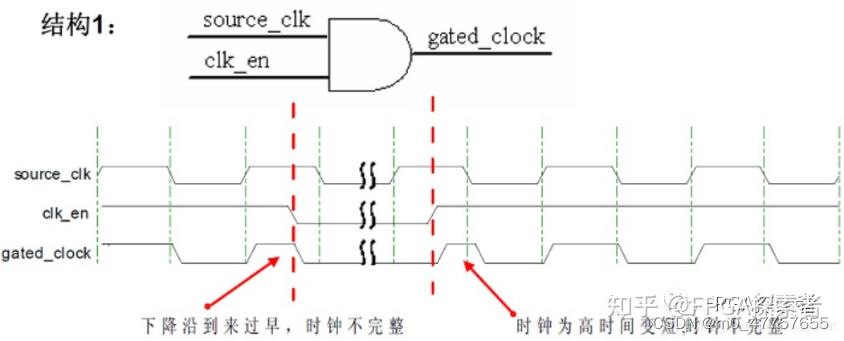
对上升沿有效地clk,使用与门进行门控,ena使能信号跳变只能发射在时钟的低电平区,或门反之,但使能信号要在输入位上取反。
为了解决上述情况,使用了一种特殊的时钟门控单元(进入与门前,将ena与clk放入D寄存器),它将EN与时钟边缘同步。这些被称为集成时钟门控单元或ICG。


3.12
以门级网表(Netlist)生成为分界线,之前称为前端,之后称为后端。
布局布线之前可以认为是前端,布局布线到流片是后端。
前端:逻辑设计(RTL到网表)
后端:物理设计(门级网表到物理版图)
Synthesis:综合,主要任务是将 RTL 代码 转成 门级网表;
典型的网表文件由单元(Cell)、引脚(Pin)、端口(Port)、网络(Net)组成。
Synthesis 输入:RTL 代码,工艺库,约束
Synthesis 输出:Netlist 门级网表(用于布局布线),标准延迟文件(用于时序仿真);综合后的报告;
功能仿真:
验证 RTL 代码设计的功能正确性,没有加入延时信息,又叫前仿真,工具有 Mentor 的 Modelsim,Synopsys 的 VCS,Candence 的 NC-Verilog。
在综合、布局布线以后,有加入延时的后仿真(时序仿真)。
Synthesis 综合:
逻辑综合的结果(目的)是把 HDL 代码翻译成门级网表 netlist,工具有 Synopsys 的 Design Compiler(简称 DC),门级网表拿去布局布线。
形式验证:
形式验证,属于验证范畴,从 功能上 对综合后的网表进行验证,常用的是等价性检验,以功能验证后的 HDL 设计为参考,对比综合后的网表功能,检验是否在功能上存在等价性,保证综合后没有改变原先 HDL 描述的功能。
形式验证工具有 Synopsys 的 Formality。
STA 静态时序分析
STA 静态时序分析(Static Timing Analyse),属于验证范畴,从时序上对综合后的网表进行验证,检查电路是否存在建立时间、保持时间等违例。
注意 STA 和 形式验证的不同,STA 从时序上验证,形式验证从功能上验证。
STA 工具有 Synosys 的 Prime Time。
3.13
二进制数转换为格雷码:1 0 1 1 0
0 1 0 1 1(右移一位,最高位补0)
1 1 1 0 1(上下取异或)
Verilog代码实现就一句:
assign gray_code = (bin_code>>1) ^ bin_code;
同步FIFO的编写:(请看上亿变,直到熟练掌握)
读写地址的处理,如:读数据操作必须满足第一没空,第二有读使能信号;写数据同理。
定义实际写入的数据量,即读数据的次数与写数据的次数,但是有两种情况,一种是只写了最大深度以内,另一种是写数据操作完成了一个最大深度,前者的地址最高为0,后者为1。
空与满状态的数据量判定。当数据量是0的时候为空,为最大深度的时候为满。
设计FIFO的时候一般需要考虑的有两点:
1. FIFO的大小 FIFO的大小指就是双端口ram的大小,这个可以根据设计需要来设置。
2. FIFO空满状态的判断 FIFO空满状态的判断通常有两种方法。采用第二种:
a、FIFO中的ram一般是双端口ram,所以有独立的读写地址。因此可以一种是设置读,写指针,写指针指向下一个要写入数据的地址,读指针指向下一个要读的地址,最后通过比较读指针和写指针的大小来确定空满状态。
b、设置一个计数器,当写使能有效的时候计数器加一;当读使能有效的时候,计数器减一,将计数器与ram的size进行比较来判断fifo的空满状态。这种方法设计比较简单,但是需要的额外的计数器,就会产生额外的资源,而且当fifo比较大时,会降低fifo最终可以达到的速度。
用一个fifo_cnt来指示实际写入的数据量。
地址指针waddr和raddr比实际地址多一位,最高位用来指示套圈情况。当waddr和raddr的最高位相同时,fifo_cnt = waddr-raddr;当waddr和raddr的最高位相反时,fifo_cnt = DEPTH - raddr[ADDR_WIDTH-1:0] + waddr[ADDR_WIDTH-1:0] 。
3.14
一个八位二进制减法计数器,初始状态为00000000,问经过268个输入脉冲后,此计数器的状态为()【计数器】【减法计数器】【二进制减法】
Intel(Altera)的FPGA:-6/-7/-8,-6最快,-8最慢;
Xilinx的FPGA:-1/-2/-3,-1最慢,-3最快。
现在还有-1/-L1/-2/-L2/-3,L是低功耗Low power。
在Verilog中,只有0、1、X、Z四种逻辑,其中X不定态,Z高阻态(X、Z不区分大小写)。
在VHDL中,H是弱逻辑1,X是不定态。


3.16
A:Xilinx 的 7 系列 FPGA 内部有 CLB 可编程配置块(Configuration Logic Block),每个 CLB 里有 2 个 Slice。Slice 有 2种,一种是 SliceL(Logic逻辑),一种是 SliceM(Memory存储),SliceM 相比 SliceL 多出的功能在于可以配置成 Distribute RAM(分布式RAM)。
B:分布式 RAM 不可以配置成真双端口RAM;
C:在前面提到,Slice 是 FPGA 内部的可编程资源;
D:DSP 主要是用于乘法、除法和快速加法
3.17
低通滤波器滤除高频,这时候再使用采样频率为Fs的采样时钟进行降采样,该滤波器的功能是抗混叠滤波,这个滤波器也叫抗混叠滤波器。因为 ADC 采样、量化后的信号是离散的数字信号,【时域离散化对应频域周期化】,即在频域会出现多个频率分量,其中只有低频部分是我们实际需要的。
此时,若直接进行降采样,那么针对每个频率分量,将会再次进行一次周期化,D倍抽取序列的频谱为抽取前后原始序列之频谱经频移和D倍展宽后的D个频谱的叠加和,因此可能存在混叠。
OD:漏极开路门(Open-Drain),直接线与;
OC:集电极开路门(Open-Collector),必须接电源和上拉电阻,而不是下拉电阻;
OC门是使用三极管搭建,工作时必须外接电源和上拉电阻。
OD 使用 MOS 管,与 OC 的集电极开路相似,将三极管换成场效应管,集电极变成漏极,原理分析一样。
先看 setup 的公式(不考虑时钟抖动和歪斜):
Tsetup ≤ Tclk - Tco(max) - Tcomb(max)
其中,Tclk 是时钟周期,Tco 是寄存器输出的响应时间,Tclk 沿到来后数据发送变化并文档输出的时间(由器件本身决定),Tcomb 是寄存器之间的组合逻辑延时。
由上面的式子,setup 出现违例,要增大 setup,可以
(1)增大时钟周期,即降低时钟频率,则很容易满足 setup 时序约束的公式,解决
(2)减小 Tco,即更换更快的器件,使用更先进的器件库,使得 Tco 更小
(3)减小 Tcomb,即减小组合逻辑延时,主要是关键路径的处理,包括插入寄存器使其流水、重定时等,降低这部分的路径延迟,所以将部分组合逻辑电路搬移到前级path上对
(4)如果考虑时钟的话,可以改善时钟质量,降低抖动,如果时钟歪斜 Tskew 为正,对setup是有利的,对hold是有害;
DFT FFT
3.29
False path非关键路径,异步不需要

[从零开始学习FPGA编程-37]:进阶篇 - 基本时序电路-有限状态机实现(Verilog)
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:
目录
以上是关于FPGA知识点汇总(verilog数字电路时序分析跨时钟域亚稳态)的主要内容,如果未能解决你的问题,请参考以下文章
[从零开始学习FPGA编程-32]:进阶篇 - 基本时序电路-D触发器(Verilog语言)
[从零开始学习FPGA编程-30]:进阶篇 - 基本时序电路-锁存器(Verilog语言)