:数据源池化技术实现
Posted 小傅哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:数据源池化技术实现相关的知识,希望对你有一定的参考价值。
作者:小傅哥
博客:https://bugstack.cn - 手写Mybatis系列文章
沉淀、分享、成长,让自己和他人都能有所收获!😄
一、前言
码农,只会做不会说?
你有发现吗,其实很大一部分码农,都只是会写代码,不会讲东西。一遇到述职、答辩、分享、汇报,就很难流畅且有高度、有深度,并融合一部分引入入胜的趣味性来让观众更好的接受和理解你要传递的信息。
那为什么已经做了还讲不出来呢?因为做只是在已确定目标和既定路线下的执行,但为什么确定这个目标、为什么制定这个路线、横向的参照对比、纵向的深度设计,都没有在一个执行者的头脑中形成过程的推演,更多的时候都只是执行。所以也就很难把一个事完整的表述出来。
所以,只有当你经历的足够多,阅历的足够丰富,才能有更好的表述能力和临场应变技巧,也就更能更清楚的传递出你要表达的信息。
二、目标
在上一章节我们解析了 XML 中数据源配置信息,并使用 Druid 创建数据源完成数据库的操作。但其实在 Mybatis 中是有自己的数据源实现的,包括无池化的 UnpooledDataSource 实现方式和有池化的 PooledDataSource 实现方式。
那么本章节我们就来实现一下关于池化数据源的处理,通过这些实现读者也能更好的理解在我们日常开发中一些关于数据源的配置属性到底意欲何为,包括:最大活跃连接数、空闲连接数、检测时长等,在连接池中所起到的作用。
三、设计
首先你可以把池化技术理解为享元模式的具体实现方案,通常我们对一些需要较高创建成本且高频使用的资源,需要进行缓存或者也称预热处理。并把这些资源存放到一个预热池子中,需要用的时候从池子中获取,使用完毕再进行使用。通过池化可以非常有效的控制资源的使用成本,包括;资源数量、空闲时长、获取方式等进行统一控制和管理。如图 6-1 所示
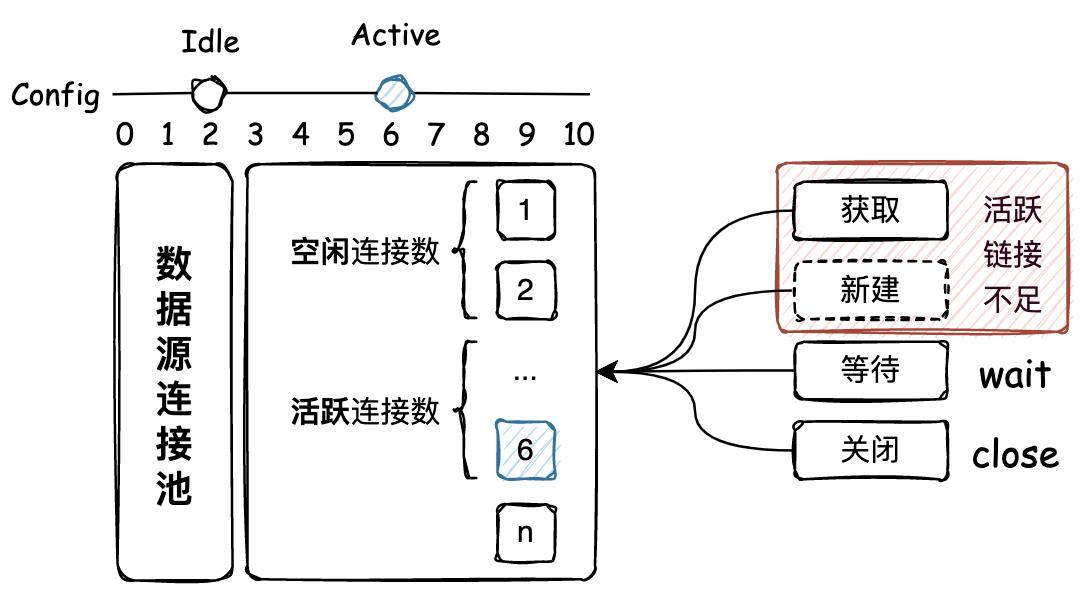
- 通过提供统一的连接池中心,存放数据源链接,并根据配置按照请求获取链接的操作,创建连接池的数据源链接数量。这里就包括了最大空闲链接和最大活跃链接,都随着创建过程被控制。
- 此外由于控制了连接池中连接的数量,所以当外部从连接池获取链接时,如果链接已满则会进行循环等待。这也是大家日常使用DB连接池,如果一个SQL操作引起了慢查询,则会导致整个服务进入瘫痪的阶段,各个和数据库相关的接口调用,都不能获得到链接,接口查询TP99陡然增高,系统开始大量报警。那连接池可以配置的很大吗,也不可以,因为连接池要和数据库所分配的连接池对应上,避免应用配置连接池超过数据库所提供的连接池数量,否则会出现夯住不能分配链接的问题,导致数据库拖垮从而引起连锁反应。
四、实现
1. 工程结构
mybatis-step-04
└── src
├── main
│ └── java
│ └── cn.bugstack.mybatis
│ ├── binding
│ ├── builder
│ ├── datasource
│ │ ├── druid
│ │ │ └── DruidDataSourceFactory.java
│ │ ├── pooled
│ │ │ ├── PooledConnection.java
│ │ │ ├── PooledDataSource.java
│ │ │ ├── PooledDataSourceFactory.java
│ │ │ └── PoolState.java
│ │ ├── unpooled
│ │ │ ├── UnpooledDataSource.java
│ │ │ └── UnpooledDataSourceFactory.java
│ │ └── DataSourceFactory.java
│ ├── io
│ ├── mapping
│ ├── session
│ │ ├── defaults
│ │ │ ├── DefaultSqlSession.java
│ │ │ └── DefaultSqlSessionFactory.java
│ │ ├── Configuration.java
│ │ ├── SqlSession.java
│ │ ├── SqlSessionFactory.java
│ │ ├── SqlSessionFactoryBuilder.java
│ │ └── TransactionIsolationLevel.java
│ ├── transaction
│ └── type
└── test
├── java
│ └── cn.bugstack.mybatis.test.dao
│ ├── dao
│ │ └── IUserDao.java
│ ├── po
│ │ └── User.java
│ └── ApiTest.java
└── resources
├── mapper
│ └──User_Mapper.xml
└── mybatis-config-datasource.xml
工程源码:https://t.zsxq.com/bmqNFQ7
池化数据源核心类关系,如图 6-2 所示
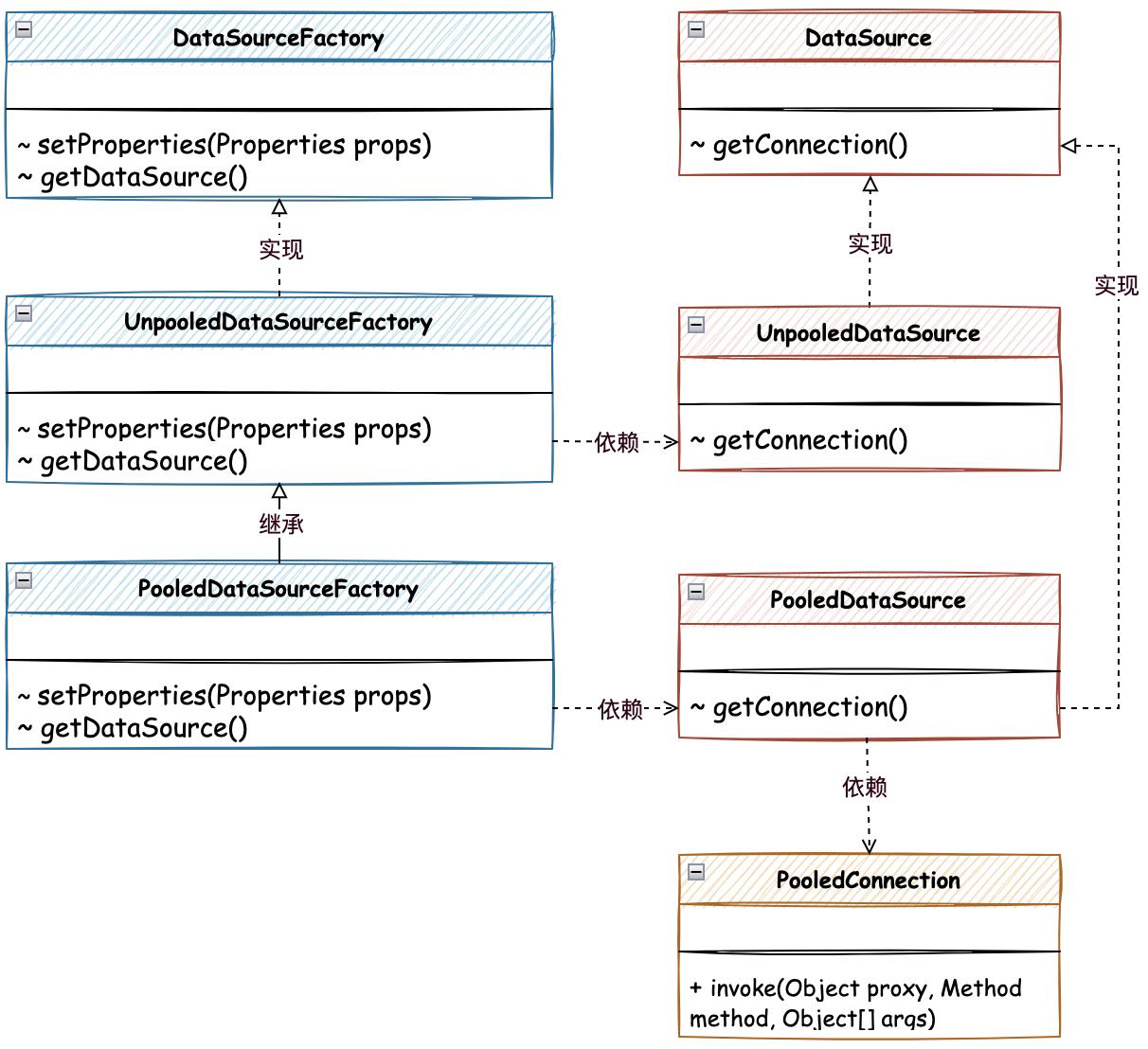
- 在 Mybatis 数据源的实现中,包括两部分分为无池化的 UnpooledDataSource 实现类和有池化的 PooledDataSource 实现类,池化的实现类 PooledDataSource 以对无池化的 UnpooledDataSource 进行扩展处理。把创建出来的链接保存到内存中,记录为空闲链接和活跃链接,在不同的阶段进行使用。
- PooledConnection 是对链接的代理操作,通过invoke方法的反射调用,对关闭的链接进行回收处理,并使用 notifyAll 通知正在等待链接的用户进行抢链接。
- 另外是对 DataSourceFactory 数据源工厂接口的实现,由无池化工厂实现后,有池化工厂继承的方式进行处理,这里没有太多的复杂操作,池化的处理主要集中在 PooledDataSource 类中进行处理。
2. 无池化链接实现
对于数据库连接池的实现,不一定非得提供池化技术,对于某些场景可以只使用无池化的连接池。那么在实现的过程中,可以把无池化的实现和池化实现拆分解耦,在需要的时候只需要配置对应的数据源即可。
public class UnpooledDataSource implements DataSource
private ClassLoader driverClassLoader;
// 驱动配置,也可以扩展属性信息 driver.encoding=UTF8
private Properties driverProperties;
// 驱动注册器
private static Map<String, Driver> registeredDrivers = new ConcurrentHashMap<>();
// 驱动
private String driver;
// DB 链接地址
private String url;
// 账号
private String username;
// 密码
private String password;
// 是否自动提交
private Boolean autoCommit;
// 事务级别
private Integer defaultTransactionIsolationLevel;
static
Enumeration<Driver> drivers = DriverManager.getDrivers();
while (drivers.hasMoreElements())
Driver driver = drivers.nextElement();
registeredDrivers.put(driver.getClass().getName(), driver);
private Connection doGetConnection(Properties properties) throws SQLException
initializerDriver();
Connection connection = DriverManager.getConnection(url, properties);
if (autoCommit != null && autoCommit != connection.getAutoCommit())
connection.setAutoCommit(autoCommit);
if (defaultTransactionIsolationLevel != null)
connection.setTransactionIsolation(defaultTransactionIsolationLevel);
return connection;
/**
* 初始化驱动
*/
private synchronized void initializerDriver() throws SQLException
if (!registeredDrivers.containsKey(driver))
try
Class<?> driverType = Class.forName(driver, true, driverClassLoader);
// https://www.kfu.com/~nsayer/Java/dyn-jdbc.html
Driver driverInstance = (Driver) driverType.newInstance();
DriverManager.registerDriver(new DriverProxy(driverInstance));
registeredDrivers.put(driver, driverInstance);
catch (Exception e)
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
- 无池化的数据源链接实现比较简单,核心在于 initializerDriver 初始化驱动中使用了 Class.forName 和 newInstance 的方式创建了数据源链接操作。
- 在创建完成连接以后,把链接存放到驱动注册器中,方便后续使用中可以直接获取链接,避免重复创建所带来的资源消耗。
3. 有池化链接实现
有池化的数据源链接,核心在于对无池化链接的包装,同时提供了相应的池化技术实现,包括:pushConnection、popConnection、forceCloseAll、pingConnection 的操作处理。
这样当用户想要获取链接的时候,则会从连接池中进行获取,同时判断是否有空闲链接、最大活跃链接多少,以及是否需要等待处理或是最终抛出异常。
3.1 池化连接的代理
由于我们需要对连接进行池化处理,所以当链接调用一些 CLOSE 方法的时候,也需要把链接从池中关闭和恢复可用,允许其他用户获取到链接。那么这里就需要对连接类进行代理包装,处理 CLOSE 方法。
源码详见:cn.bugstack.mybatis.datasource.pooled.PooledConnection
public class PooledConnection implements InvocationHandler
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable
String methodName = method.getName();
// 如果是调用 CLOSE 关闭链接方法,则将链接加入连接池中,并返回null
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName))
dataSource.pushConnection(this);
return null;
else
if (!Object.class.equals(method.getDeclaringClass()))
// 除了toString()方法,其他方法调用之前要检查connection是否还是合法的,不合法要抛出SQLException
checkConnection();
// 其他方法交给connection去调用
return method.invoke(realConnection, args);
- 通过 PooledConnection 实现 InvocationHandler#invoke 方法,包装代理链接,这样就可以对具体的调用方法进行控制了。
- 在 invoke 方法中处理对 CLOSE 方法控制以外,排除 toString 等Object 的方法后,则是其他真正需要被 DB 链接处理的方法了。
- 那么这里有一个对于 CLOSE 方法的数据源回收操作 dataSource.pushConnection(this); 有一个具体的实现方法,在池化实现类 PooledDataSource 中进行处理。
3.2 pushConnection 回收链接
源码详见:cn.bugstack.mybatis.datasource.pooled.PooledDataSource
protected void pushConnection(PooledConnection connection) throws SQLException
synchronized (state)
state.activeConnections.remove(connection);
// 判断链接是否有效
if (connection.isValid())
// 如果空闲链接小于设定数量,也就是太少时
if (state.idleConnections.size() < poolMaximumIdleConnections && connection.getConnectionTypeCode() == expectedConnectionTypeCode)
state.accumulatedCheckoutTime += connection.getCheckoutTime();
if (!connection.getRealConnection().getAutoCommit())
connection.getRealConnection().rollback();
// 实例化一个新的DB连接,加入到idle列表
PooledConnection newConnection = new PooledConnection(connection.getRealConnection(), this);
state.idleConnections.add(newConnection);
newConnection.setCreatedTimestamp(connection.getCreatedTimestamp());
newConnection.setLastUsedTimestamp(connection.getLastUsedTimestamp());
connection.invalidate();
logger.info("Returned connection " + newConnection.getRealHashCode() + " to pool.");
// 通知其他线程可以来抢DB连接了
state.notifyAll();
// 否则,空闲链接还比较充足
else
state.accumulatedCheckoutTime += connection.getCheckoutTime();
if (!connection.getRealConnection().getAutoCommit())
connection.getRealConnection().rollback();
// 将connection关闭
connection.getRealConnection().close();
logger.info("Closed connection " + connection.getRealHashCode() + ".");
connection.invalidate();
else
logger.info("A bad connection (" + connection.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
state.badConnectionCount++;
- 在 PooledDataSource#pushConnection 数据源回收的处理中,核心在于判断链接是否有效,以及进行相关的空闲链接校验,判断是否把连接回收到 idle 空闲链接列表中,并通知其他线程来抢占。
- 如果现在空闲链接充足,那么这个回收的链接则会进行回滚和关闭的处理中。connection.getRealConnection().close();
3.3 popConnection 获取链接
源码详见:cn.bugstack.mybatis.datasource.pooled.PooledDataSource
private PooledConnection popConnection(String username, String password) throws SQLException
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null)
synchronized (state)
// 如果有空闲链接:返回第一个
if (!state.idleConnections.isEmpty())
conn = state.idleConnections.remove(0);
logger.info("Checked out connection " + conn.getRealHashCode() + " from pool.");
// 如果无空闲链接:创建新的链接
else
// 活跃连接数不足
if (state.activeConnections.size() < poolMaximumActiveConnections)
conn = new PooledConnection(dataSource.getConnection(), this);
logger.info("Created connection " + conn.getRealHashCode() + ".");
// 活跃连接数已满
else
// 取得活跃链接列表的第一个,也就是最老的一个连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
// 如果checkout时间过长,则这个链接标记为过期
if (longestCheckoutTime > poolMaximumCheckoutTime)
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit())
oldestActiveConnection.getRealConnection().rollback();
// 删掉最老的链接,然后重新实例化一个新的链接
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
oldestActiveConnection.invalidate();
logger.info("Claimed overdue connection " + conn.getRealHashCode() + ".");
// 如果checkout超时时间不够长,则等待
else
try
if (!countedWait)
state.hadToWaitCount++;
countedWait = true;
logger.info("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
catch (InterruptedException e)
break;
// 获得到链接
if (conn != null)
if (conn.isValid())
if (!conn.getRealConnection().getAutoCommit())
conn.getRealConnection().rollback();
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
// 记录checkout时间
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
else
logger.info("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection
// 如果没拿到,统计信息:失败链接 +1
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
// 失败次数较多,抛异常
if (localBadConnectionCount > (poolMaximumIdleConnections + 3))
logger.debug("PooledDataSource: Could not get a good connection to the database.");
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
return conn;
- popConnection 获取链接是一个 while 死循环操作,只有获取到链接抛异常才会退出循环,如果仔细阅读这些异常代码,是不是也是你在做一些开发的时候所遇到的异常呢。
- 获取链接的过程会使用 synchronized 进行加锁,因为所有线程在资源竞争的情况下,都需要进行加锁处理。在加锁的代码块中通过判断是否还有空闲链接进行返回,如果没有则会判断活跃连接数是否充足,不充足则进行创建后返回。在这里也会遇到活跃链接已经进行循环等待的过程,最后再不能获取则抛出异常。
4. 数据源工厂
数据源工厂包括两部分,分别是无池化和有池化,有池化的工程继承无池化工厂,因为在 Mybatis 源码的实现类中,这样就可以减少对 Properties 统一包装的反射方式的属性处理。由于我们暂时没有对这块逻辑进行开发,只是简单的获取属性传参,所以还不能体现出这样的继承有多便捷,读者可以参考源码进行理解。源码类:UnpooledDataSourceFactory
4.1 无池化工厂
源码详见:cn.bugstack.mybatis.datasource.unpooled.UnpooledDataSourceFactory
public class UnpooledDataSourceFactory implements DataSourceFactory
protected Properties props;
@Override
public void setProperties(Properties props)
this.props = props;
@Override
public DataSource getDataSource()
UnpooledDataSource unpooledDataSource = new UnpooledDataSource();
unpooledDataSource.setDriver(props.getProperty("driver"));
unpooledDataSource.setUrl(props.getProperty("url"));
unpooledDataSource.setUsername(props.getProperty("username"));
unpooledDataSource.setPassword(props.getProperty("password"));
return unpooledDataSource;
- 简单包装 getDataSource 获取数据源处理,把必要的参数进行传递过去。在 Mybatis 源码中这部分则是进行了大量的反射字段处理的方式进行存放和获取的。
4.2 有池化工厂
源码详见:cn.bugstack.mybatis.datasource.pooled.PooledDataSourceFactory
public class PooledDataSourceFactory 以上是关于:数据源池化技术实现的主要内容,如果未能解决你的问题,请参考以下文章