ELK专栏之ES内部机制-03
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK专栏之ES内部机制-03相关的知识,希望对你有一定的参考价值。
ELK专栏之ES内部机制-03
ES内部机制
ES分布式基础
ES对复杂分布式机制的透明隐藏特性
● 分布式机制:分布式数据存储和共享。
● 分片机制:数据存储到那个分片、副本数据写入。
● 集群发现机制:新启动ES实例,自动加入到集群中。
● shard负载均衡:大量数据写入和查询,ES会将数据平均分配。
● shard副本:新增副本数,分片重分配。
ES的垂直扩容和水平扩容
● 垂直扩容:使用更加强大的服务器替换老服务器,但是单机存储和运算能力有上限,且成本直线上升,比如IT服务器要1万,但是单个10T的服务器可能要20万。
● 水平扩容:采购更多的服务器,加入集群。
增加和减少节点,数据重新分配
● 新增或减少ES实例的时候,ES集群会将数据重新分配。
master节点
● 功能:
● 管理ES集群的元数据:创建删除索引,维护索引的元数据,节点的增加和减少。
● 默认情况下,ES会自动选择一台机器作为master。
节点对等的分布式架构
● 节点对等,每个节点都能接受所有的请求。
● 自动请求路由。
● 响应收集。
分片shard、副本replica机制
● 每个index包含一个或多个shard。
● 每个shard都是一个最小的工作单元,承载部分数据,Lucene实例,完整的简历索引和处理请求的能力。
● 增减节点的时候,shard会自动在节点中负载均衡。
● primary shard(主分片)和replica shard(副本分片),每个文档肯定只存在于一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard。
● replica shard是primary shard的副本,负责容错,以及承担读请求负载。
● primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改。
● primary shard的默认数量是1,replica 默认是1,即默认共有2个shard(1个是primary shard,另一个是replica shard)。注意:ES7之前的primary shard的默认数量是5,replica 默认是1,即默认共有10个shard(5个primary shard,5个replica shard)
● primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和replica shard都丢失,起不到容错的作用),但是可以和其他的primary shard的replica shard放在同一个节点上。
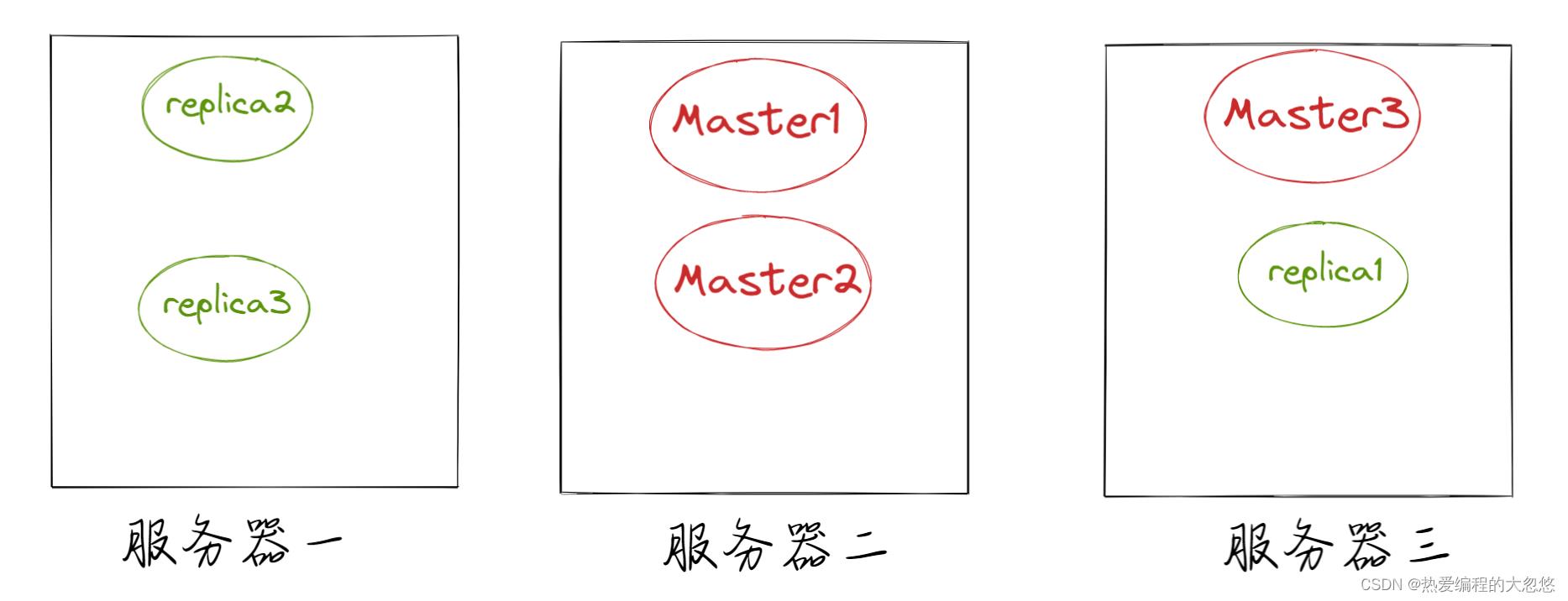
这里master和relica的关系就是redis中的主从关系,主节点当然不能和从节点放在一台服务器上呀,不然主节点服务器挂了,从节点也无法代替主节点对外提供服务了呀!
单Node(节点)环境下创建index
● 单Node环境下,创建一个index,有3个primary shard,3个replica shard。
PUT /test_index1
"settings" :
"number_of_shards" : 3,
"number_of_replicas" : 1
会发现集群的status是yellow。因为这个时候3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的。集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,并且集群出现不可用状态,无法承接任何请求。
两个Node(节点)环境下replica shard是如何分配的
● replica shard分配:一个节点上强制分配3个primary shard,另一个节点强制分配3个replica shard。
● 写请求的时候,发送到primary shard,ES会自动同步到replica shard。
● 读请求的时候,无论primary shard和replica shard都可以,因为数据是一致的。
主从服务器设计思路都是类似的,主服务器可以读写,从服务器只能读
横向扩容
● 分片自动负载均衡,分片向空闲机器转移。
● 每个节点存储更少的分片,系统资源给予每个分片的资源更多,整体集群性能提高。
● 扩容极限:节点数大于整体分片数,则必有空间机器。
● 超出扩容极限,可以增加副本数,如主分片为3,设置副本数为2,总共3*3=9个分片。9台机器同时运行,存储和搜索性能更强,容错性更好。
● 容错性:只要一个索引的所有主分片都在,集群就可以正常运行。
ES容错机制:master选举,replica容错,数据恢复
以3个分片,2副本数,3个节点为例。
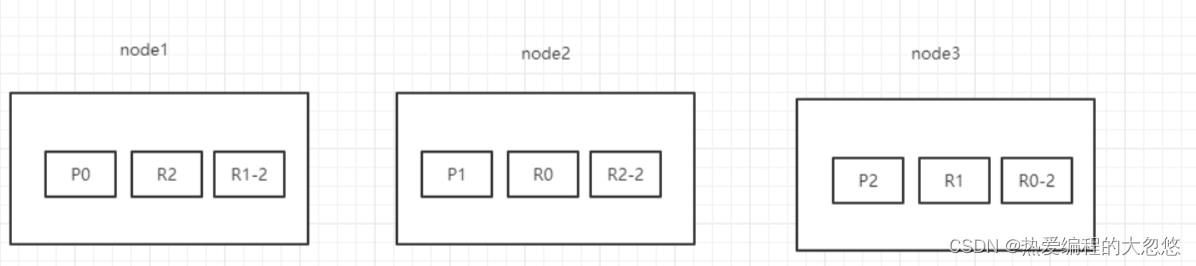
情景设计:
● ①背景:集群初始化的时候,node1是master节点。突然,node1宕机了,那么P0分片没有了,所有主分片不是active,集群状态是red。
● ②容错:
○ 重新选举master节点,拾起承担master的相关功能,假设此时node2选举为master节点。
○ 新的master节点,即node2,选择将丢失的主分片P0的某个副本(假设为R0)提升为主分片,那么此时R0我们可以看成是一个新的P0分片。此时集群状态为yellow,因为缺少了副本分片。
○ 重启故障的节点,即node1,新的master(node2)会感知到新节点加入,将缺失的副本分片复制到新机器上(增量的复制),并将P0降级为R0,P2这期间的增量数据复制到R2,P1这段期间的数据复制到R1-2上,集群状态变为green。
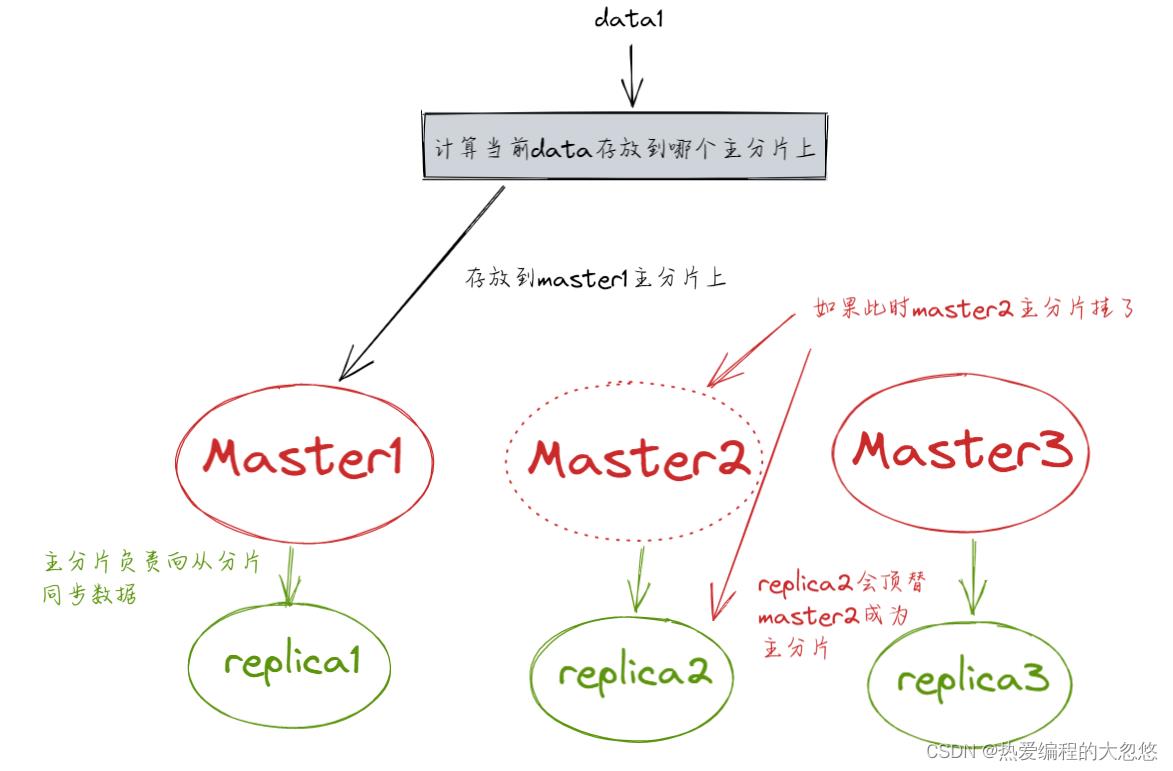
主服务器掉线势必是需要从从服务器列表中挑选出一个来顶替挂掉的主服务器的,对应上面从分片上位的过程。
而当前主服务器恢复后,通过做法是成为当前顶替他成为主服务器的从服务器的从服务器的。
文档存储机制
数据路由
什么是数据路由:
● 前置知识:
○ 一个索引数据量太大,分片会存储在多个ES的node中。
○ 一个文档,只会存储在一个主分片和其副本分片中。
● 一个文档,最终会落在主分片的一个分片上,到底应该在哪一个分片上?这就是数据路由。
这其实和redis集群模式的键槽存储思想十分类似,只能说成熟框架采用的实现思想都是类似的。
路由算法
● 路由算法公式:
shard = hash(routing) % number_of_parimary_shards
哈希值对主分片数取模
举例:
● 对一个文档的CRUD的时候,都会带一个routing number。默认为文档_id(可能是手动指定,也可能是自动生成的)。
● 存储1号文档,经过哈希计算,哈希值为2,此时有3个主分片(假设分别为p0、p1和p2),那么计算2%3=2,就算出此文档在p2分片上。
● 决定一个文档到底在哪个分片上,最重要的一个值就是routing number,默认是_id,可以手动指定,也可以自动生成,相同的routing number,每次进行hash函数求值,产出的hash值一定是相同的。
● 无论hash值是什么数字,对number_of_parimary_shards求余数,结果一定是在0和number_of_parimary_shards-1之间的这个范围内。
类比redis的集群模式就非常的清晰了
手动指定routing
PUT /test_index/_doc/15?routing=tom
"username":"tom"
● 场景:在程序中,架构师可以手动指定已有数据的一个属性为路由值。好处是可以定制一类文档数据存储到一个分片中。缺点是设计不好,会造成数据的倾斜。
● 所以,不同文档尽量放到不同的索引中,剩下的事情就交给ES集群自己处理。
主分片数量不可变
● 涉及到以往数据的查询时,一旦建立索引,主分片数不可变(参考路由算法)。
文档增删改内部机制
增删改可以看做是Update,都是对数据的修改。一个修改请求发送到ES集群,会经历以下的步骤:
● 客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)。
● coordinating node,对document进行路由计算,将请求转发给对应的node(有primary shard)。
● 实际的node上的primary shard处理请求,然后将数据同步到replica shard。
● coordinating node如果发现primary shard和所有的replica shard都搞定之后,就返回响应结果给客户端。
文档查询内部机制
一个查询请求发送的ES集群,会经历以下的步骤:
● 客户端发送请求到任意一个node,该node就是coordinating node(协调节点)。
● coordinating node(协调节点)对document进行路由计算,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有的replica shard中随机选择一个,让读请求负载均衡。
● 接收请求的node返回document给coordinating node(协调节点)。
● coordinating node(协调节点)返回document给客户端。
● 特殊情况:document如果还在建立索引过程中,可能只有primary shard上有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了。
bulk API奇特的JSON格式
- 目前bulk的REST API格式如下:
POST /_bulk
"action":"metadata"
"data"
- 为什么不是下面的这种格式?
POST /_bulk
[
"action":
"method":"create"
,
"data":
"id":1,
"field1":"java",
"field1":"spring",
,
"action":
"method":"create"
,
"data":
"id":2,
"field1":"java",
"field1":"spring",
]
● bulk中的每个操作都可能要转发到不同的node上的shard去执行。
● 如果采用比较良好的JSON格式:允许任意的换行,整个可读性非常棒,ES拿到这种标准格式的JSON以后,需要按照以下的流程进行处理。
○ ①将JSON数组解析成JSONArray对象,这个数据就会在内存中出现一模一样的复制,一份数据是json文本,一份数据是JSONArray对象。
○ ②解析JSON数组里的每个JSON,对每个请求中的document进行路由。
○ ③为路由到同一个shard上的多个请求,创建一个请求数组。比如100个请求中有10个是转发到P1。
○ ④将这个请求数组序列化。
○ ⑤将序列后的请求数组发送到对应的节点上去。
● 耗费更多的内存,更多的JVM GC开销。
○ ①bulk一般建议在几千条左右,大小在10MB左右。如果现在100个bulk请求发送到了一个节点上去,每个请求是10MB,100个请求就是1000MB = 1GB,然后每个请求的JOSN都会复制一份为JSONArray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成JSONArray之后,可能还会搞一些其他的数据结构,会造成2GB+的内存占用。
○ ②占用更多的请求可能就会积压其他请求的内存使用量,比如说最重要的搜素请求、分析请求等,此时就可能导致其他请求的性能急速下降。
○ ③占用内存越多,就会导致Java虚拟机的垃圾回收次数更多,更频繁,每次要回收的垃圾对象更多,耗时也更长,导致ES的Java虚拟机停止工作线程的时间更多。
● 现在的奇特格式:
POST /_bulk
"delete": "_index": "test_index", "_id": "5" \\n
"create": "_index": "test_index", "_id": "14" \\n
"test_field": "test14" \\n
"update": "_index": "test_index", "_id": "2" \\n
"doc" : "test_field" : "bulk test" \\n
○ ①不用将其装换为JSON对象,不会在内存中出现相同的数据复制,直接按照换行符切割JSON。
○ ②对每两个一组的JSON,读取meta,进行document路由。
○ ③直接将对应的JSON发送到node上去。
● 最大的优势在于,不需要将JSON数组解析为一个JSONArray对象,形成一个大数据的拷贝,浪费内存空间,尽可能的保证性能。
Mapping映射入门
什么是Mapping映射?
● 概念:自动或手动为index中的_doc建立的一种数据结构和相关配置,称为Mapping映射。
● 示例:插入几条数据,让ES自动为我们建立一条索引
PUT /website/_doc/1
"post_date": "2019-01-01",
"title": "my first article",
"content": "this is my first article in this website",
"author_id": 11400
PUT /website/_doc/2
"post_date": "2019-01-02",
"title": "my second article",
"content": "this is my second article in this website",
"author_id": 11400
PUT /website/_doc/3
"post_date": "2019-01-03",
"title": "my third article",
"content": "this is my third article in this website",
"author_id": 11400
- 相当于数据库建表语句:
create table website(
post_date date,
title varchar(50),
content varchar(100),
author_id int(11)
);
- 动态映射(dynamic mapping):自动为我们建立index,以及对应的mapping,mapping中包含了每个field对应的数据类型以及如何分词等设置。
- 当然,我们也可以手动在创建数据之前,先建立index,以及对应的Mapping。
- 查看动态映射语法
GET /index/_mapping
- 示例:查看ES自动会我们创建的动态映射
GET /website/_mapping
结果:
"website" :
"mappings" :
"properties" :
"author_id" :
"type" : "long"
,
"content" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"post_date" :
"type" : "date"
,
"title" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
● 搜索语法:
①搜索所有的字段:
GET /index/_search?q=xxx
②搜索指定的字段:
GET /index/_search?q=field:xxx
示例:查询2019
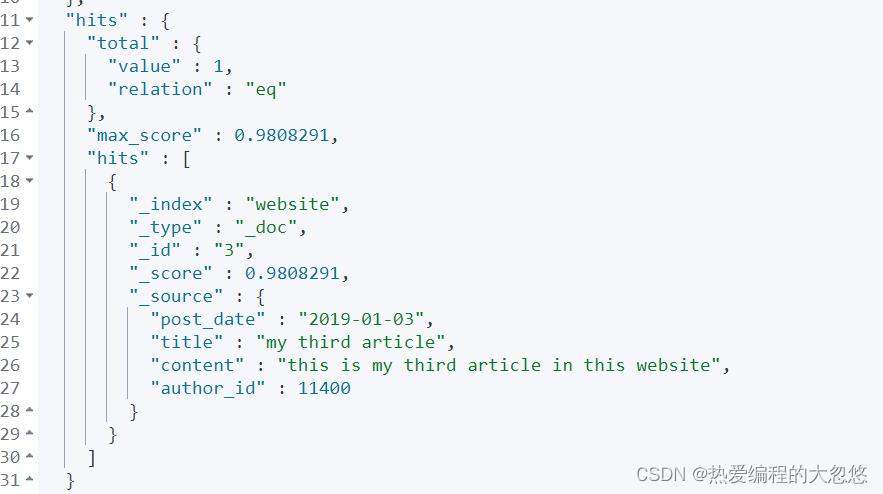
GET /website/_search?q=2019
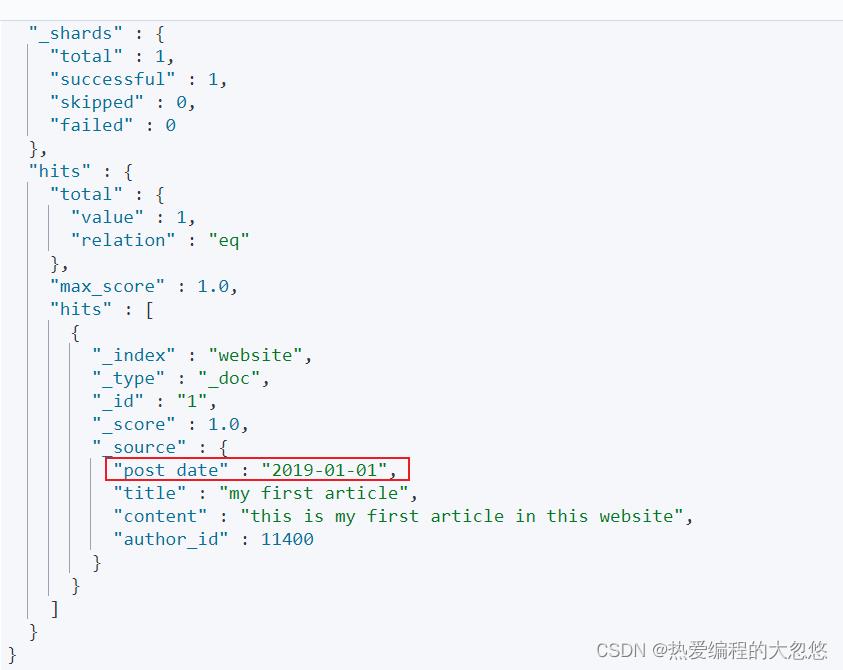
示例:查询content
GET /website/_search?q=content:third
精确匹配和全文检索的对比分析
精确匹配(exact value)
搜索的时候,必须输入准确的值,才能返回结果,类似于select * from book where publish_date = ‘2019-01-01’。
全文检索(full text)
搜索的时候,只要输入关键词,就能返回结果。
全文检索不是单纯的只是匹配完整的一个值,而是可以对值进行拆分词语后(分词)进行匹配,也可以通过缩写、时态、大小写、同义词等进行匹配。
全文检索下倒排索引核心原理
准备工作
doc1:
I really liked my small dogs, and I think my mom also liked them.
doc2:
He never liked any dogs, so I hope that my mom will not expect me to liked him.
应用示例
● 示例:演示倒排索引最简单的一个建立过程
● ①分词,初步的倒排索引建立:
| term | doc1 | doc2 |
|---|---|---|
| I | * | * |
| really | * | |
| liked | * | * |
| my | * | * |
| small | * | |
| dogs | * | |
| and | * | |
| think | * | |
| mom | * | * |
| also | * | |
| them | * | |
| He | * | |
| never | * | |
| any | * | |
| so | * | |
| hope | * | |
| that | * | |
| will | * | |
| not | * | |
| expect | * | |
| me | * | |
| to | * | |
| him | * |
● ②如果搜索:mother like little dog,是不会有结果的。因为会将这一句拆分为mother 、like 、little 、dog四个词,但是,在倒排索引中是没有这些词的,这不是我们想要的结果,因为mom和mother在我们看来是一样的,需要进行标准化操作。
● ③重建倒排索引:normalization(标准化),建立倒排索引的时候,会执行一个操作,对拆分处的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率。
○ 时态的转换:liked–>like。
○ 单复数的转换:dogs–>dog。
○ 同义词的转换:mom–>mother、small–>little。
○ 大小写的转换。
| word | doc1 | doc2 |
|---|---|---|
| I | * | * |
| really | * | |
| like | * | * |
| my | * | * |
| little | * | |
| dog | * | |
| and | * | |
| think | * | |
| mother | * | * |
| also | * | |
| them | * | |
| He | * | |
| never | * | |
| any | * | |
| so | * | |
| hope | * | |
| that | * | |
| will | * | |
| not | * | |
| expect | * | |
| me | * | |
| to | * | |
| him | * |
此时,使用mother liked little dog进行搜索,就可以搜索出doc1和doc2文档了,因为mother 、liked 、little 、dog等都会进行标准化分词。
分词器analyzer
什么是分词器?
● 分词器的作用:切分词语,进行标准化(normalization),提高召回率(recall)。换言之,给ES一段文本,然后将这段文本拆分成一个一个的单词,同时对每个单词进行标准化(normalization,如时态转换、单复数转换等),以便提高召回率(recall,搜索的时候,增加能够搜索到结果的数量)。
● 分词器的步骤:
○ ①character filter:在一段文本进行分词之前,先进行预处理,比如:过滤html标签等。
○ ②tokenizer:分词,比如:hello you and me --> hello、you、and、me。
○ ③token filter:lowercase、stop word(停用词:了、的、呢)、synonymom、dogs–>dog、liked–>like、Tom–>tom、a/the/an–>去掉、mom–>mother、small–>little。
● 分词器很重要,将一段文本进行各种处理之后,才能拿去建立倒排索引。
内置分词器
● 例句:Set the shape to semi-transparent by calling set_trans(5)。
● 标准分词器(standard analyzer,默认):set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)。
● 简单分词器(simple analyzer):set, the, shape, to, semi, transparent, by, calling, set, trans。
● 空格分词器(whitespace analyzer):Set, the, shape, to, semi-transparent, by, calling, set_trans(5)。
● 特定的语言的分词器(language analyzer,比如英语分词器):set, shape, semi, transpar, call, set_tran, 5。
query string根据字段分词策略
query string分词
query string必须以和index建立相同的analyzer进行分词。
测试分词器
- 语法:
GET /_analyze
"analyzer": "standard",
"text": "xxxx"
- 示例:
GET /_analyze
"analyzer": "standard",
"text": "Text to analyze 80"
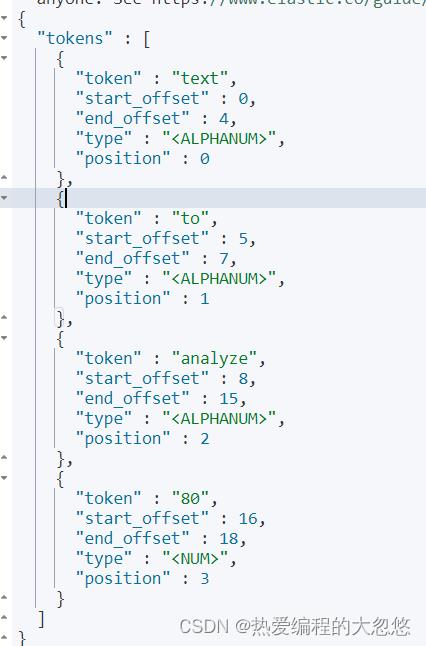
- token:实际存储的term关键词。
- position:此词条在原文本中的位置。
- start_offset/end_offset:字符在原始字符中的位置。
mapping的核心数据类型以及dynamic mapping
数据类型
dynamic mapping推测规则
● true/false --> boolean。
● 123 --> long。
● 123.45 --> double。
● 2019-11-11 --> date。
● “hello world” --> text/keyword。
查看mapping
语法:
GET /index/_mapping
示例:查看ES自动会我们创建的动态映射
GET /website/_mapping

手动管理mapping
映射,只能新增,不能修改。删除映射,是通过删除索引来间接达到的。
文本类型
● 创建索引后,应该立即手动创建mapping映射。
put /book
PUT /book/_mapping
"properties":
"name":
"type": "text"
,
"description":
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
,
"pic":
"type": "text",
"index": false
,
"studymodel":
"type": "text"
当type的值为text,即文本类型。
- analyzer:指定在索引和搜索的时候使用的分词器。如果单独想定义搜索的时候使用分词器,可以使用search_analyzer属性。
- index:指定是否索引,默认为true。只有为true的时候,才能被索引库搜索到。有一些内容不需要索引,比如商品图片的地址,不需要进行搜索,这时可以设置为false。
- store:是否在source之外存储,每个文档索引后会在ES中保存一份原始文档,存放在"source"中,一般情况下,不需要设置设置此属性为true,因为在source中已经有一份原始文档了。
- 测试:插入文档
PUT /book/_doc/1
"name":"Bootstrap开发框架",
"description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel":"201002"
- 测试查询:
# 支持全文检索
GET /book/_search?q=name:Bootstrap
# 支持全文检索
GET /book/_search?q=description:开发
# 不支持全文检索
GET /book/_search?q=pic:group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg
# 支持全文检索
GET /book/_search?q=studymodel:201002
关键字类型
- 创建索引后,应该立即手动创建mapping映射。
put /book
PUT /book/_mapping
"properties":
"name":
"type": "text"
,
"description":
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
,
"pic":
"type": "keyword"
,
"studymodel":
"type": "text"
当type的值是keyword,即关键字类型。关键字类型是按照整体搜索的,不需要进行分词,比如:邮政编码、手机号码、身份证号码等。关键字字段通常用于过滤、排序和聚合等。
GET /book/_search?q=pic:dhy 或者 GET /book/_search?q=dhy 都可以搜索到
但是 GET /book/_search?q=d 或者 GET /book/_search?q=pic:d 搜索不到
日期类型
● 创建索引后,应该立即手动创建mapping映射。
put /book
PUT /book/_mapping
"properties":
"name":
"type": "text"
,
"description":
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
,
"pic":
"type": "keyword"
,
"studymodel":
"type": "text"
,
"timestamp":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
当type的值是date,即日期类型。
● 日期类型不用设置分词器。
● 通常日期类型的字段用于排序。
● 可以通过format设置日期格式。
测试:插入文档
PUT /book/_doc/3
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic": "group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"timestamp": "2018-07-04 18:28:58"
数值类型
● 创建索引后,应该立即手动创建mapping映射。
put /book
PUT /book/_mapping
"properties":
"name":
"type": "text"
,
"description":
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
,
"pic":
"type": "keyword"
,
"studymodel":
"type": "text"
,
"timestamp":
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
,
"price":
"type": "scaled_float",
"scaling_factor": 100
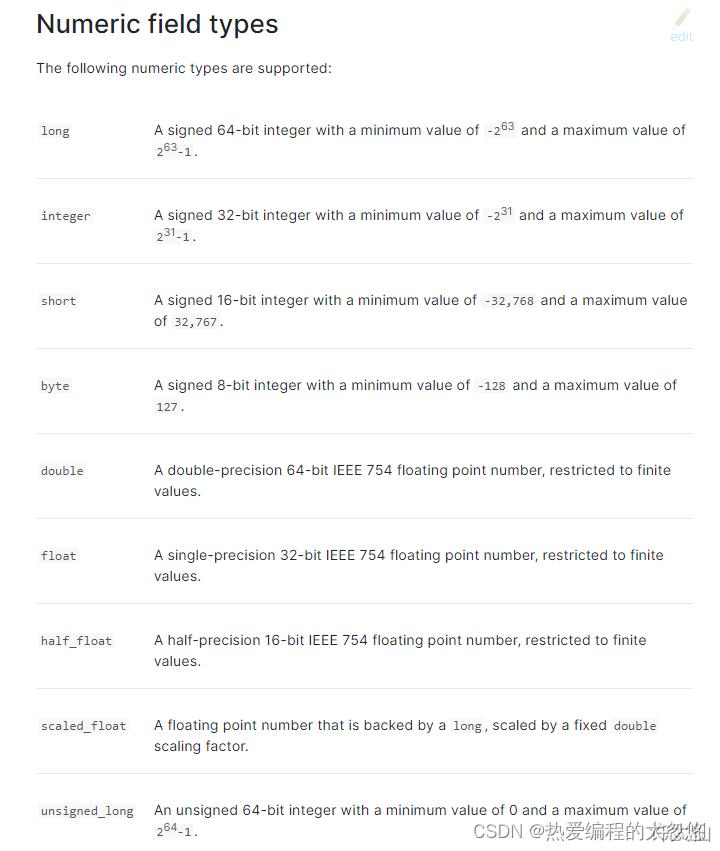
当type的值,是上图中的类型的时候,即为数值类型。