真1分钟搞懂缓存穿透缓存击穿缓存雪崩
Posted 緑水長流*z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了真1分钟搞懂缓存穿透缓存击穿缓存雪崩相关的知识,希望对你有一定的参考价值。
💗推荐阅读文章💗
- 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》
- 🌺MySQL系列🌺👉2️⃣《MySQL系列教程》
- 🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》
- 🌻SSM框架系列🌻👉4️⃣《SSM框架系列教程》
文章目录
四、缓存解决方案
4.1 缓存穿透
4.1.1 现象:
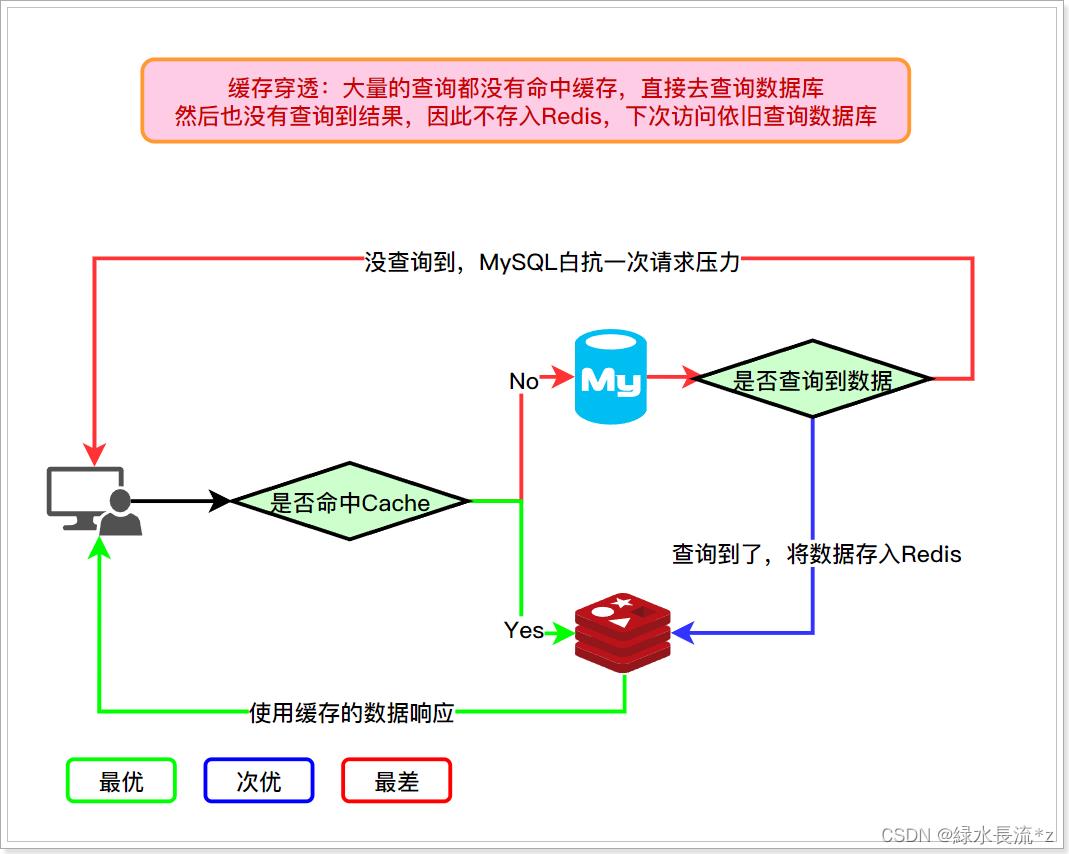
指大量请求来到数据库查询都没有查询到结果,因此不存储在redis中,redis命中率非常低,当redis没有命中,则大量的请求来到了数据库,数据库一直处于被大流量访问状态,很容易压力过载(一般属于恶意攻击)。
4.1.2 方案:
1、在微服务网关或拦截器中设置逻辑监控,必要时采取封ip操作
2、每次将请求的数据都存入redis中并设置过期时间,设置key-null数据(过期时间设置短点,如1分钟),如果大量请求中存在有重复的数据,那么第二次以后的操作都会查询到redis,减少mysql压力
3、在网关中增加逻辑校验,筛选掉不规则数据,如id<0的数据
4、bitmap白名单策略,将所有数据id存放在bitmaps中,id作为偏移量,存储0/1表示是否存在,存在则放行,不存在则拦截。(这种策略需要提前将所有的id缓存在bitmap中,效率偏低)
4.2 缓存击穿
4.2.1 现象:
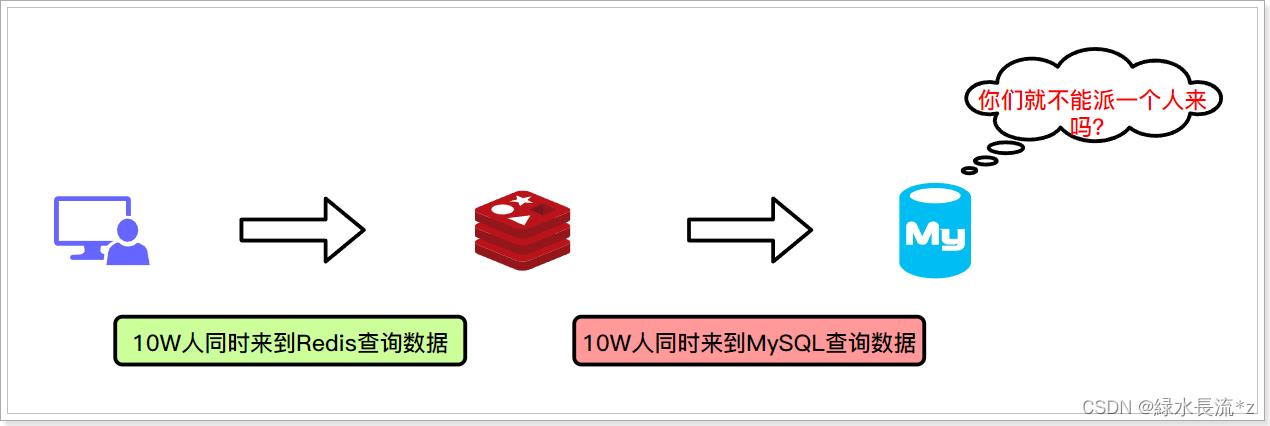
指查询某个key(热点数据)在缓存中没有,但数据库有(一般是缓存时间到期),由于这个key是热点数据,在同一时间有大量用户访问这个key,并发量极高,请求发现redis没有,则全部来到数据查询,造成数据库压力瞬间飙升。
4.2.2 方案:
1、如果是整个网站中长期处于热点数据的,可以考虑将数据设置为永不过期
2、如果是需要发布某项活动,造成原本不是热点的key,突然变成热点,可以在活动之前将key的过期时间延长至活动结束。(缓存预热)
3、我们知道缓存击穿的原理实在就是大量并发同时来到cache,同时发现cache中没有数据,全部都去数据库获取了,那么我们可以考虑添加互斥锁,如果已经有请求进来获取数据,发现为空,那么就从数据库去获取数据(这段时间是上锁的)。
代码参考:
public String getData(String key) throws InterruptedException
// 首先从缓存读取数据
String val = getDataFromRedis(key);
// 如果缓存不存在则去数据库获取
if (val == null)
// 获取锁
if (lock.tryLock())
// 从数据库获取数据
val = getDataFromDB(key);
if (val != null)
setCache(key, val);
// 释放锁
lock.unlock();
else
// 其他线程获取锁失败,睡眠100毫秒后尝试重新获取
Thread.sleep(100);
val = getData(key);
return val;
4.3 缓存雪崩
4.3.1 现象:
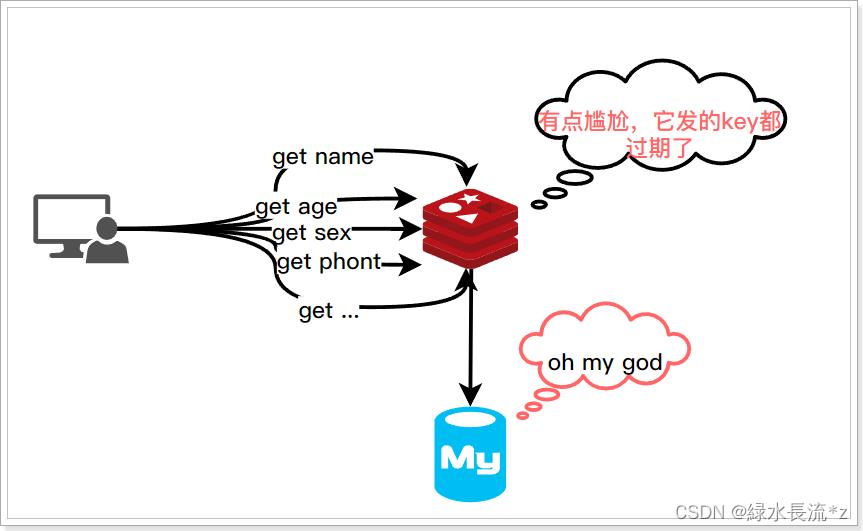
指某一时间大量缓存过期,请求直接来到数据库,造成数据库压力过载。与缓存击穿不同的是缓存击穿通常是大的并发量访问某一条数据,而某一条数据正好失效。而缓存雪崩是大量的数据同时失效,多个key累加起来的请求流量压力过大。很多数据都查询不到,从而到数据库查询,数据库压力飙升。
4.3.2 方案:
1、将较为重要的数据设置永不过期
2、将缓存数据过期时间设置为随机,防止同一时间大量缓存失效
「干货满满!」三句话搞懂 Redis 缓存穿透击穿雪崩
关注上方“Linux 研习社”回复“速查表”
免费领取Linux命令速查表一份!
前言
如何有效的理解并且区分 Reids 穿透、击穿和雪崩之间的区别,一直以来都挺困扰我的。特别是穿透和击穿,过一段时间就稀里糊涂的分不清了。
为了有效的帮助笔者自己,以及拥有同样烦恼的朋友们区分这三种场景。笔者总结了一些关键词,希望大家可以和我一样通过联想的方式来区分并理解这三种场景的区别!
缓存穿透:
关键词:穿过 Redis 和 数据库
当 Redis 和数据库中都没有我们想要的数据时,就需要考虑缓存穿透的问题了
下面这段逻辑大家用的会比较多:先去 Redis 中查找某资源,Redis 中查不到就去 DB 中查,DB 中查到后回写一份数据到 Redis 中。
这段逻辑正常情况下问题并不大,但是如果用户恶意重复请求资源 X,该资源在 Redis 和 DB 中都不存在。那么每次请求都会直接打到 DB 上,甚至导致物理 DB 宕机。
解决方案:
1、缓存空结果
如果系统发现 Redis 及 DB 中都不存在该资源,就缓存空结果一段时间。需要注意哈,这次的失效时间不能设置的太长,否则数据的实效性会产生很大的问题。
2、用户合法性校验
对用户的请求合法性进行校验,拦截恶意重复请求
3、布隆过滤器
看到这个名词不要慌。简单来说布隆过滤器的用途就是帮助你判断某个值是否存在。
举个例子来看下:假设我们现在有一个长度为 9 的 bit 数组,该数组的每个位置上只能保存 1 或者 0,1 标识该位置被占用,0 标识该位置未被使用。
对于 key1,我们借助三个 Hash 函数分别对其哈希运算
再将得到的这三个哈希值对 9 求模。
最后将这三个模值落入到 bit 数组上。
key2、key3 按照同样的方式再处理一遍。
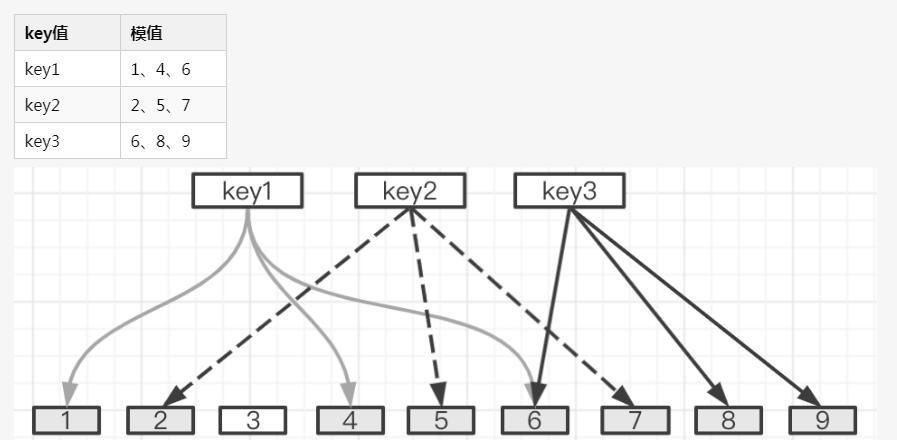
最后,我们会发现这个 bit 数组里只有位置 3 还是空着的。如果此时来了一个新的 key4 通过三个Hash算法求出的哈希值为 1、2、3,我们则可以断定 key4 一定不存在。
布隆过滤器的原理还是比较简单的。这里我们需要注意,布隆过滤器可能存在一定误判的可能性,但它依然可以帮助你拦截掉大部分一定不存在的数据。
缓存击穿
关键词:定点打击
试想如果所有请求对着一个 key 照死里搞,这是不是就是一种定点打击呢?
怎么理解呢?举个极端的例子:比如某某明星爆出一个惊天狠料,海量吃瓜群众同时访问微博去查看该八卦新闻,而微博 Redis 集群中数据在此刻正好过期了,那么无数的请求则直接打到了微博系统的物理 DB 上,DB 瞬间挂了。
解决方案:
1、热点数据永远不过期
比如我们可以将某个 key 的缓存时间设置为 25 小时,然后后台有个 JOB 每隔 24 小时就去批量刷新一下热点数据。就可以解决这个问题了
2、使用互斥锁
容易影响吞吐量,大部分项目设置热点 key 永不过期就妥妥的了
缓存雪崩
关键词:Redis 崩了,没有数据了
这里的 Redis 崩了指的并不是 Redis 集群宕机了。而是说在某个时刻 Redis 集群中的热点 key 都失效了。
如果集群中的热点 key 在某一时刻同时失效了的话,试想海量的请求都将直接打到 DB 上,DB 可能在瞬间就被打爆了。
解决方案
1、Redis 失效时间加上随机数
Redis 失效时间加上随机数,是一种比较取巧的解决方案。在一定程度上减轻了 DB 的瞬时压力,但是这种方案也在一定程度上增加了维护的成本。
2、Redis 永不过期
实现方案在上文中简单提过了
总结
最后我们再回归到主题!
如何轻松的通过联想的方式来区分 Redis 缓存穿透、击穿、雪崩的区别
缓存穿透---穿过(绕过) Redis 和 DB 来搞你
缓存击穿---定点打击来搞你
缓存雪崩---热点 key 在某一个时刻同时失效
https://www.toutiao.com/i6864767234737177091
end
往期推荐
号外号外:Linux 交流群已成立
无论你是科班出生、还是培训班出生、亦或是刚入门的小白,从你入行这一刻起,就得保持终生学习的心态。船神创建了一个「Linux 交流群」,希望更好的与大家一起学习交流,我们自己的职业生涯掌握在自己手中。
一定要备注:城市+昵称+技术方向,根据格式备注,可更快被通过且邀请进群哟
以上是关于真1分钟搞懂缓存穿透缓存击穿缓存雪崩的主要内容,如果未能解决你的问题,请参考以下文章