Kubernetes in Action 5 服务:让客户端发现pod并与之通信
Posted 沛沛老爹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes in Action 5 服务:让客户端发现pod并与之通信相关的知识,希望对你有一定的参考价值。

目录
(1)Kubernetes In Action 1:Kubernetes介绍
(2)Kubernetes In Action 2:开始使用Kubernetes和Docker
(3)Kubernetes in Action 3 pod:运行于Kubernetes中的容器(1)
(4)Kubernetes in Action 3 pod:运行于Kubernetes中的容器(2)
(5)Kubernetes in Action 4 副本机制和其他控制器:部署托管的pod
Kubernetes in Action 5 服务:让客户端发现pod并与之通信
本章内容说明
- 创建服务资源,利用单个地址访问—组pod
- 发现集群中的服务
- 将服务公开给外部客户端
- 从集群内部连接外部服务
- 控制pod是与服务关联
- 排除服务故障
现在已经学习过了pod,以及如何通过ReplicaSet和类似资源部署运行。尽管特定的pod可以独立地应对外部刺激,现在大多数应用都需要根据外部请求做出响应。例如,就微服务而言,pod通常需要对来自集群内部其他pod,以及来自集群外部的客户端的HTTP请求做出响应。
pod需要一种寻找其他pod的方法来使用其他pod提供的服务,不像在没有Kubernetes的世界,系统管理员要在用户端配置文件中明确指出服务的精确的IP地址或者主机名来配置每个客户端应用,但是同样的方式在Kubernetes中并不适用,因为pod是短暂的——它们随时会启动或者关闭,无论是为了给其他pod提供空间而从节点中被移除,或者是减少了pod的数量,又或者是因为集群中存在节点异常。
Kubernetes在pod启动前会给已经调度到节点上的pod分配IP地址——因此客户端不能提前知道提供服务的pod的IP地址。
水平伸缩意味着多个pod可能会提供相同的服务——每个pod都有自己的IP地址,客户端无须关心后端提供服务pod的数量,以及各自对应的IP地址。它们无须记录每个pod的IP地址。相反,所有的pod可以通过一个单一的IP地址进行访问。
为了解决上述问题,Kubernetes提供了一种资源类型——服务(service),在本章中将对其进行介绍。
5.1 介绍服务
Kubernetes服务是一种为一组功能相同的pod提供单一不变的接入点的资源。当服务存在时,它的IP地址和端口不会改变。客户端通过IP地址和端口号建立连接,这些连接会被路由到提供该服务的任意一个pod上。通过这种方式,客户端不需要知道每个单独的提供服务的pod的地址,这样这些pod就可以在集群中随时被创建或移除。
结合实例解释服务
回顾一下有前端web服务器和后端数据库服务器的例子。有很多pod提供前端服务,而只有一个pod提供后台数据库服务。需要解决两个问题才能使系统发挥作用。
外部客户端无须关心服务器数量而连接到前端pod上。
前端的pod需要连接后端的数据库。由于数据库运行在pod中,它可能会在集群中移来移去,导致IP地址变化。当后台数据库被移动时,无须对前端pod重新配置。
通过为前端pod创建服务,并且将其配置成可以在集群外部访问,可以暴露一个单一不变的IP地址让外部的客户端连接pod。同理,可以为后台数据库pod创建服务,并为其分配一个固定的IP地址。尽管pod的IP地址会改变,但是服务的IP地址固定不变。另外,通过创建服务,能够让前端的pod通过环境变量或DNS以及服务名来访问后端服务。系统中所有的元素都在图5.1中展示出来(两种服务、支持这些服务的两套pod,以及它们之间的相互依赖关系)。 图5.1 内部和外部客户端通常通过服务连接到pod
图5.1 内部和外部客户端通常通过服务连接到pod
到目前为止了解了服务背后的基本理念。那么现在,去深入研究如何创建它们。
5.1.1 创建服务
服务的后端可以有不止一个pod。服务的连接对所有的后端pod是负载均衡的。但是要如何准确地定义哪些pod属于服务哪些不属于呢?
或许还记得在ReplicationController和其他的pod控制器中使用标签选择器来指定哪些pod属于同一组。服务使用相同的机制,可以参考图5.2。
在前面的章节中,通过创建ReplicationController运行了三个包含Node.js应用的pod。再次创建ReplicationController并且确认pod启动运行,在这之后将会为这三个pod创建一个服务。
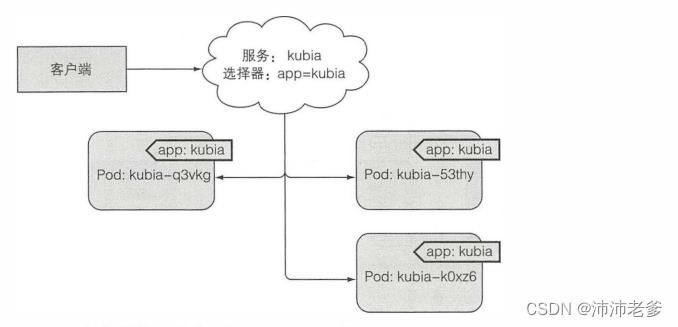
图5.2 标签选择器决定哪些pod属于服务
通过kubectl expose创建服务
创建服务的最简单的方法是通过kubectl expose,在第2章中曾使用这种方法来暴露创建的ReplicationController。像创建ReplicationController时使用的pod选择器那样,利用expose命令和pod选择器来创建服务资源,从而通过单个的IP和端口来访问所有的pod。
现在,除了使用expose命令,可以通过将配置的YAML文件传递到Kubernetes API服务器来手动创建服务。
通过YAML描述文件来创建服务
使用以下代码清单中的内容创建一个名为kubia-svc.yaml的文件。
代码清单5.1 服务的定义:kubia-svc.yaml

创建了一个名叫kubia的服务,它将在端口80接收请求并将连接路由到具有标签选择器是app=kubia的pod的8080端口上。
接下来通过使用kubectl create发布文件来创建服务。
检测新的服务
在发布完YAML文件后,可以在命名空间下列出来所有的服务资源,并可以发现新的服务已经被分配了一个内部集群IP。
$ kubectl get svc
列表显示分配给服务的IP地址是 10.111.249.153 。因为只是集群的IP地址,只能在集群内部可以被访问。服务的主要目标就是使集群内部的其他pod可以访问当前这组pod,但通常也希望对外暴露服务。如何实现将在之后讲解。现在,从集群内部使用创建好的服务并了解服务的功能。
从内部集群测试服务
可以通过以下几种方法向服务发送请求:
- 显而易见的方法是创建一个pod,它将请求发送到服务的集群IP并记录响应。可以通过查看pod日志检查服务的响应。
- 使用ssh远程登录到其中一个Kubernetes节点上,然后使用curl命令。
- 可以通过 kubectl exec 命令在一个已经存在的pod中执行curl命令。
我们来学习最后一种方法——如何在已有的pod中运行命令。
在运行的容器中远程执行命令
可以使用kubectl exec命令远程地在一个已经存在的pod容器上执行任何命令。这样就可以很方便地了解pod的内容、状态及环境。用 kubectl get pod 命令列出所有的pod,并且选择其中一个作为exec命令的执行目标(在下述例子中,选择kubia-7nog1 pod作为目标)。也可以获得服务的集群IP(比如使用 kubectl get svc 命令),当执行下述命令时,请确保替换对应pod的名称及服务IP地址。
$ kubectl exec kubia-7nogl -- curl -s http://10.111.249.153
You've hit kubia-4gkbs
如果之前使用过ssh命令登录到一个远程系统,会发现kubectl exec没有特别大的不同之处。
为什么是双横杠?
双横杠(–)代表着kubectl命令项的结束。在两个横杠之后的内容是指在pod内部需要执行的命令。如果需要执行的命令并没有以横杠开始的参数,横杠也不是必需的。如下情况,如果这里不使用横杠号,-s选项会被解析成 kubectl exec 选项,会导致结果异常和歧义错误。
$ kubectl exec kubia-7nogl curl -s http://10.111.249.153服务除拒绝连接外什么都不做。这是因为kubectl并不能连接到位于10.111.249.153的API服务器(-s选项用来告诉kubectl需要连接一个不同的API 服务器而不是默认的)。
回顾一下在运行命令时发生了什么。图5.3展示了事件发生的顺序。在一个pod容器上,利用Kubernetes去执行curl命令。curl命令向一个后端有三个pod服务的IP发送了HTTP请求,Kubernetes服务代理截取的该连接,在三个pod中任意选择了一个pod,然后将请求转发给它。Node.js在pod中运行处理请求,并返回带有pod名称的HTTP响应。接着,curl命令向标准输出打印返回值,该返回值被kubectl截取并打印到宕主机的标准输出。
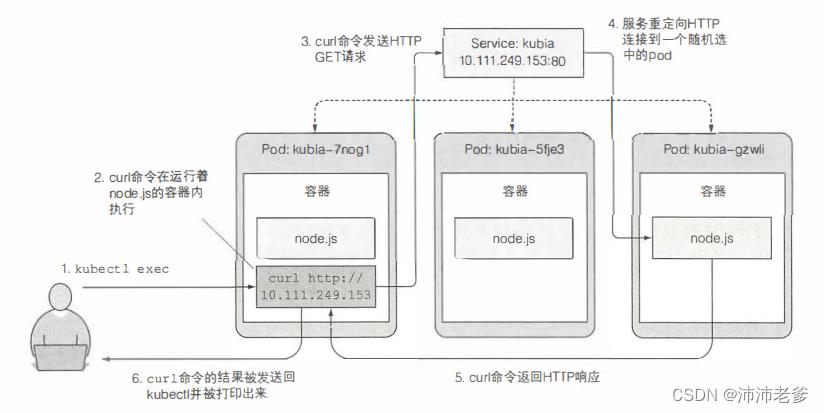
图5.3 使用kubectl exec通过在一个pod中运行curl命令来测试服务是否连通
在之前的例子中,在pod主容器中以独立进程的方式执行了curl命令。这与容器真正的主进程和服务通信并没有什么区别。
配置服务上的会话亲和性
如果多次执行同样的命令,每次调用执行应该在不同的pod上。因为服务代理通常将每个连接随机指向选中的后端pod中的一个,即使连接来自于同一个客户端。
另一方面,如果希望特定客户端产生的所有请求每次都指向同一个pod,可以设置服务的sessionAffinity属性为ClientIP(而不是None,None是默认值),如下面的代码清单所示。
代码清单5.2 会话亲和性被设置成ClientIP的服务的例子
apiVersion: v1
kind: Service
spec:
sessionAffinity: ClientIP
......
这种方式将会使服务代理将来自同一个client IP的所有请求转发至同一个pod上。作为练习,创建额外的服务并将会话亲和性设置为ClientIP,并尝试向其发送请求。
Kubernetes仅仅支持两种形式的会话亲和性服务:None和ClientIP。你或许惊讶竟然不支持基于cookie的会话亲和性的选项,但是你要了解Kubernetes 服务不是在HTTP层面上工作。服务处理TCP和UDP包,并不关心其中的载荷内容。因为cookie是HTTP协议中的一部分,服务并不知道它们,这就解释了为什么会话亲和性不能基于cookie。
同一个服务暴露多个端口
创建的服务可以暴露一个端口,也可以暴露多个端口。比如,你的pod监听两个端口,比如HTTP监听8080端口、HTTPS监听8443端口,可以使用一个服务从端口80和443转发至pod端口8080和8443。在这种情况下,无须创建两个不同的服务。通过一个集群IP,使用一个服务就可以将多个端口全部暴露出来。
注意 在创建一个有多个端口的服务的时候,必须给每个端口指定名字。
以下代码清单中展示了多端口服务的规格。
代码清单5.3 在服务定义中指定多端口

注意 标签选择器应用于整个服务,不能对每个端口做单独的配置。如果不同的pod有不同的端口映射关系,需要创建两个服务。
之前创建的kubia pod不在多个端口上侦听,因此可以练习创建一个多端口服务和一个多端口pod。
使用命名的端口 在这些例子中,通过数字来指定端口,但是在服务spec中也可以给不同的端口号命名,通过名称来指定。这样对于一些不是众所周知的端口号,使得服务spec更加清晰。
举个例子,假设你的pod端口定义命名如下面的代码清单所示。
代码清单5.4 在pod的定义中指定port名称

可以在服务spec中按名称引用这些端口,如下面的代码清单所示。
代码清单5.5 在服务中引用命名pod

为什么要采用命名端口的方式?最大的好处就是即使更换端口号也无须更改服务spec。你的pod现在对http服务用的是8080,但是假设过段时间你决定将端口更换为80呢?
如果你采用了命名的端口,仅仅需要做的就是改变spec pod 中的端口号(当然你的端口号的名称没有改变)。在你的pod向新端口更新时,根据pod收到的连接(8080端口在旧的pod上、80端口在新的pod上),用户连接将会转发到对应的端口号上。
5.1.2 服务发现
通过创建服务,现在就可以通过一个单一稳定的IP地址访问到pod。在服务整个生命周期内这个地址保持不变。在服务后面的pod可能删除重建,它们的IP地址可能改变,数量也会增减,但是始终可以通过服务的单一不变的IP地址访问到这些pod。
但客户端pod如何知道服务的IP和端口?是否需要先创建服务,然后手动查找其IP地址并将IP传递给客户端pod的配置选项?当然不是。Kubernetes还为客户端提供了发现服务的IP和端口的方式。
通过环境变量发现服务
在pod开始运行的时候,Kubernetes会初始化一系列的环境变量指向现在存在的服务。如果你创建的服务早于客户端pod的创建,pod上的进程可以根据环境变量获得服务的IP地址和端口号。
在一个运行pod上检查环境,去了解这些环境变量。现在已经了解了通过kubectl exec命令在pod上运行一个命令,但是由于服务的创建晚于pod的创建,那么关于这个服务的环境变量并没有设置,这个问题也需要解决。
在查看服务的环境变量之前,首先需要删除所有的pod使得ReplicationController创建全新的pod。在无须知道pod的名字的情况下就能删除所有的pod,就像这样:
$ kubectl delete po --all
现在列出所有新的pod,然后选择一个作为kubectl exec命令的执行目标。一旦选择了目标pod,通过在容器中运行env来列出所有的环境变量,如下面的代码清单所示。
代码清单5.6 容器中和服务相关的环境变量

在集群中定义了两个服务:kubernetes和kubia(之前在用kubectl get svc命令的时候应该见过);所以,列表中显示了和这两个服务相关的环境变量。在本章开始部分,创建了kubia服务,在和其有关的环境变量中有 KUBIA_SERVICE_HOST 和 KUBIA_SERVICE_PORT ,分别代表了kubia服务的IP地址和端口号。
回顾本章开始部分的前后端的例子,当前端pod需要后端数据库服务pod时,可以通过名为 backend-database 的服务将后端pod暴露出来,然后前端pod通过环境变量 BACKEND_DATABASE_SERVICE_HOST 和 BACKEND_DATABASE_SERVICE_PORT 去获得IP地址和端口信息。
注意 服务名称中的横杠被转换为下画线,并且当服务名称用作环境变量名称中的前缀时,所有的字母都是大写的。
环境变量是获得服务IP地址和端口号的一种方式,为什么不用DNS域名?为什么Kubernetes中没有DNS服务器,并且允许通过DNS来获得所有服务的IP地址?事实证明,它的确如此!
通过DNS发现服务
还记得第3章中在kube-system命名空间下列出的所有pod的名称吗?其中一个pod被称作kube-dns,当前的kube-system的命名空间中也包含了一个具有相同名字的响应服务。
就像名字的暗示,这个pod运行DNS服务,在集群中的其他pod都被配置成使用其作为dns(Kubernetes通过修改每个容器的/etc/resolv.conf文件实现)。运行在pod上的进程DNS查询都会被Kubernetes自身的DNS 服务器响应,该服务器知道系统中运行的所有服务。
注意 pod是否使用内部的DNS服务器是根据pod中spec的dnsPolicy属性来决定的。
每个服务从内部DNS 服务器中获得一个DNS条目,客户端的pod在知道服务名称的情况下可以通过全限定域名(FQDN)来访问,而不是诉诸于环境变量。
通过FQDN连接服务
再次回顾前端-后端的例子,前端pod可以通过打开以下FQDN的连接来访问后端数据库服务:
backend-database.default.svc.cluster.local
backend-database对应于服务名称,default表示服务在其中定义的名称空间,而svc.cluster.local是在所有集群本地服务名称中使用的可配置集群域后缀。
注意 客户端仍然必须知道服务的端口号。如果服务使用标准端口号(例如,HTTP的80端口或Postgres的5432端口),这样是没问题的。如果并不是标准端口,客户端可以从环境变量中获取端口号。
连接一个服务可能比这更简单。如果前端pod和数据库pod在同一个命名空间下,可以省略 svc.cluster.local 后缀,甚至命名空间。因此可以使用 backend-database 来指代服务。这简单到不可思议,不是吗?
尝试一下。尝试使用FQDN来代替IP去访问kubia服务。另外,必须在一个存在的pod上才能这样做。已经知道如何通过 kubectl exec 在一个pod的容器上去执行一个简单的命令,但是这一次不是直接运行curl命令,而是运行bash shell,这样可以在容器上运行多条命令。在第2章中,当想进入容器启动Docker时,调用 docker exec-it bash 命令,这与此很相似。
在pod容器中运行shell
可以通过kubectl exec命令在一个pod容器上运行bash(或者其他形式的shell)。通过这种方式,可以随意浏览容器,而无须为每个要运行的命令执行kubectl exec。
注意 shell的二进制可执行文件必须在容器镜像中可用才能使用。
为了正常地使用shell,kubectl exec 命令需要添加–it选项:
$ kubectl exec -it kubia-3inly -- bash
如果不在命令前加 – Kubernetes会给出如下提示 kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] – [COMMAND] instead. 因此,后续在Pod容器中执行的命令都要加上 –
现在进入容器内部,根据下述的任何一种方式使用curl命令来访问kubia服务:
$ curl http://kubia.default.svc.cluster.local
You've hit kubia-5sfhc
$ curl http://kubia.default
You've hit kubia-5sfhc
$ curl http://kubia
You've hit kubia-5sfhc
在请求的URL中,可以将服务的名称作为主机名来访问服务。因为根据每个pod容器DNS解析器配置的方式,可以将命名空间和svc.cluster.local后缀省略掉。查看一下容器中的/etc/resilv.conf文件就明白了。
$ cat /etc/resolv.conf
nameserver 10.96.0.10
search test.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
无法ping通服务IP的原因
在继续之前还有最后一问题。了解了如何创建服务,很快地去自己创建一个。但是,不知道什么原因,无法访问创建的服务。
大家可能会尝试通过进入现有的pod,并尝试像上一个示例那样访问该服务来找出问题所在。然后,如果仍然无法使用简单的curl命令访问服务,也许会尝试ping 服务 IP以查看服务是否已启动。现在来尝试一下:
$ ping kubia
PING kubia.test.svc.cluster.local (10.99.93.78): 56 data bytes
^C--- kubia.test.svc.cluster.local ping statistics ---
91 packets transmitted, 0 packets received, 100% packet loss
嗯,curl这个服务是工作的,但是却ping不通。这是因为服务的集群IP是一个虚拟IP,并且只有在与服务端口结合时才有意义。将在第11章中解释这意味着什么,以及服务是如何工作的。在这里提到这个问题,因为这是用户在尝试调试异常服务时会做的第一件事(ping服务的IP),而服务的IP无法ping通会让大多数人措手不及。
5.2 连接集群外部的服务
到现在为止,我们已经讨论了后端是集群中运行的一个或多个pod的服务。但也存在希望通过Kubernetes服务特性暴露外部服务的情况。不要让服务将连接重定向到集群中的pod,而是让它重定向到外部IP和端口。
这样做可以让你充分利用服务负载平衡和服务发现。在集群中运行的客户端pod可以像连接到内部服务一样连接到外部服务。
5.2.1 介绍服务endpoint
在进入如何做到这一点之前,先阐述一下服务。服务并不是和pod直接相连的。相反,有一种资源介于两者之间——它就是Endpoint资源。如果之前在服务上运行过kubectl describe,可能已经注意到了endpoint,如下面的代码清单所示。
代码清单5.7 用kubectl describe展示服务的全部细节

Endpoint资源就是暴露一个服务的IP地址和端口的列表,Endpoint资源和其他Kubernetes资源一样,所以可以使用 kubectl info 来获取它的基本信息。
$ kubectl get endpoints kubia
尽管在 spec服务中定义了pod选择器,但在重定向传入连接时不会直接使用它。相反,选择器用于构建IP和端口列表,然后存储在Endpoint资源中。当客户端连接到服务时,服务代理选择这些IP和端口对中的一个,并将传入连接重定向到在该位置监听的服务器。
5.2.2 手动配置服务的endpoint
或许已经意识到这一点,服务的 endpoint与服务解耦后,可以分别手动配置和更新它们。
如果创建了不包含pod选择器的服务,Kubernetes将不会创建Endpoint资源(毕竟,缺少选择器,将不会知道服务中包含哪些pod)。这样就需要创建Endpoint资源来指定该服务的endpoint列表。
要使用手动配置endpoint的方式创建服务,需要创建服务和Endpoint资源。
创建没有选择器的服务
首先为服务创建一个YAML文件,如下面的代码清单所示。
代码清单5.8 不含pod选择器的服务:external-service.yaml

定义一个名为external-service的服务,它将接收端口80上的传入连接。并没有为服务定义一个pod选择器。
为没有选择器的服务创建Endpoint资源
Endpoint是一个单独的资源并不是服务的一个属性。由于创建的资源中并不包含选择器,相关的Endpoints资源并没有自动创建,所以必须手动创建。如下所示的代码清单中列出了YAML manifest。
代码清单5.9 手动创建Endpoint资源:external-service-endpoints.yaml

Endpoint对象需要与服务具有相同的名称,并包含该服务的目标IP地址和端口列表。服务和Endpoint资源都发布到服务器后,这样服务就可以像具有pod选择器那样的服务正常使用。在服务创建后创建的容器将包含服务的环境变量,并且与其IP:port对的所有连接都将在服务端点之间进行负载均衡。
图5.4显示了三个pod连接到具有外部endpoint的服务。
如果稍后决定将外部服务迁移到Kubernetes中运行的pod,可以为服务添加选择器,从而对Endpoint进行自动管理。反过来也是一样的——将选择器从服务中移除,Kubernetes将停止更新Endpoints。这意味着服务的IP地址可以保持不变,同时服务的实际实现却发生了改变。

图5.4 pod关联到具有两个外部endpoint的服务上
5.2.3 为外部服务创建别名
除了手动配置服务的Endpoint来代替公开外部服务方法,有一种更简单的方法,就是通过其完全限定域名(FQDN)访问外部服务
创建ExternalName类型的服务
要创建一个具有别名的外部服务的服务时,要将创建服务资源的一个type字段设置为ExternalName。例如,设想一下在http://api.somecompany.com上有公共可用的API,可以定义一个指向它的服务,如下面的代码清单所示。
代码清单5.10 ExternalName类型的服务:external-service-externalname.yaml

服务创建完成后,pod可以通过 external-service.default.svc.cluster.local 域名(甚至是 external-service )连接到外部服务,而不是使用服务的实际FQDN。这隐藏了实际的服务名称及其使用该服务的pod的位置,允许修改服务定义,并且在以后如果将其指向不同的服务,只需简单地修改externalName属性,或者将类型重新变回ClusterIP并为服务创建Endpoint——无论是手动创建,还是对服务上指定标签选择器使其自动创建。
ExternalName 服务仅在DNS级别实施——为服务创建了简单的CNAME DNS记录。因此,连接到服务的客户端将直接连接到外部服务,完全绕过服务代理。
出于这个原因,这些类型的服务甚至不会获得集群IP。
注意 CNAME记录指向完全限定的域名而不是数字IP地址。
5.3 将服务暴露给外部客户端
到目前为止,只讨论了集群内服务如何被pod使用;但是,还需要向外部公开某些服务。例如前端web服务器,以便外部客户端可以访问它们,就像图5.5描述的那样。

图5.5 将服务暴露给外部客户端
有几种方式可以在外部访问服务:
-
将服务的类型设置成 NodePort——每个集群节点都会在节点上打开一个端口,对于NodePort服务,每个集群节点在节点本身(因此得名叫NodePort)上打开一个端口,并将在该端口上接收到的流量重定向到基础服务。该服务仅在内部集群IP和端口上才可访问,但也可通过所有节点上的专用端口访问。
-
将服务的类型设置成 LoadBalance,NodePort类型的一种扩展——这使得服务可以通过一个专用的负载均衡器来访问,这是由Kubernetes中正在运行的云基础设施提供的。负载均衡器将流量重定向到跨所有节点的NodePort。客户端通过负载均衡器的IP连接到服务。
-
创建一个Ingress资源,这是一个完全不同的机制,通过一个IP地址公开多个服务——它运行在HTTP层(网络协议第7层)上,因此可以提供比工作在第4层的服务更多的功能。我们将在5.4节介绍Ingress资源。
5.3.1 使用NodePort类型的服务
将一组pod公开给外部客户端的第一种方法是创建一个服务并将其类型设置为NodePort。通过创建NodePort服务,可以让Kubernetes在其所有节点上保留一个端口(所有节点上都使用相同的端口号),并将传入的连接转发给作为服务部分的pod。
这与常规服务类似(它们的实际类型是ClusterIP),但是不仅可以通过服务的内部集群IP访问NodePort 服务,还可以通过任何节点的IP和预留端口访问 NodePort Service。
当尝试与NodePort服务交互时,意义更加重大。
创建NodePort类型的服务
现在将创建一个NodePort服务,以查看如何使用它。下面的代码清单显示了服务的YAML。
代码清单5.11 NodePort服务定义:kubia-svc-nodeport.yaml

将类型设置为 NodePort 并指定该服务应该绑定到的所有集群节点的 NodePort Service。指定端口不是强制性的。如果忽略它,Kubernetes将选择一个随机端口。
注意 当在GKE中创建服务时,kubectl打印出一个关于必须配置防火墙规则的警告。接下来的章节将讲述如何处理。
查看NodePort类型的服务
查看该服务的基础信息:
$ kubectl get svc kubia-nodeport
看看EXTERNAL-IP列。它显示nodes,表明服务可通过任何集群节点的IP地址访问。PORT(S)列显示集群 IP(80)的内部端口和 NodePort(30123),可以通过以下地址访问该服务:
- 10.11.254.223:80
- <节点1的IP>:30123
- <节点2的IP>:30123,等等
图5.6显示了服务暴露在两个集群节点的端口30123上(这适用于在GKE上运行的情况;Minikube只有一个节点,但原理相同)。到达任何一个端口的传入连接将被重定向到一个随机选择的pod,该pod是否位于接收到连接的节点上是不确定的。

图5.6 外部客户端通过节点1或者节点2连接到NodePort服务
在第一个节点的端口30123收到的连接,可以被重定向到第一节点个上运行的pod,也可能是第二个节点上运行的pod。
更改防火墙规则,让外部客户端访问我们的NodePort服务
如前所述,在通过 NodePort 访问 Service 之前,需要配置谷歌云平台的防火墙,以允许外部连接到该端口上的节点,如下所示。
$ gcloud compute firewall-rules creates kubia-svc-rule --allow=tcp:30123
Created [https://www.googleapis.com/compute/vl/projects/kubiaNAME
12 95 /global/ f irewalls/kubia-svc-rule] .
NETWORK SRC RANGES RULES
kubia-svc-rule default 0.0.0.0/0 tcp:30123
可以通过其中一个节点的IP的端口30123访问服务,但是需要首先找出节点的IP。请参阅补充内容了解如何做到这一点。
使用JSONPath获取所有节点的IP
可以在节点的JSON或YAML描述符中找到IP。但并不是在很大的JSON中筛选,而是可以利用kubectl只打印出节点IP而不是整个服务的定义。$ kubectl get nodes -o jsonpath='.items[*].status.addresses[?(@.type=="ExternalIP*)].address'通过指定kubectl的JSONPath,使得其只输出需要的信息。你可能已经熟悉XPath,并且知道如何使用XML,JSONPath基本上是JSON的XPath。上例中的JSONPath指示kubectl执行以下操作:
- 浏览item属性中的所有元素。
- 对于每个元素,输入status属性。
- 过滤address属性的元素,仅包含那些具有将type属性设置为ExternalIP的元素。
- 最后,打印过滤元素的address属性。
要了解有关kubectl使用JSONPath的更多信息,请参阅http://kubernetes.io/docs/user-guide/jsonpath上的文档。
一旦知道了节点的IP,就可以尝试通过以下方式访问服务:
$ curl http://130.211.97.55:30123
You've hit kubia-ym8or
$ curl http://130.211.99.206:30123
You've hit kubia-xueql
提示 使用Minikube时,可以运行 minikube sevrvice [-n] 命令,通过浏览器轻松访问NodePort服务。
正如所看到的,现在整个互联网可以通过任何节点上的30123端口访问到你的pod。客户端发送请求的节点并不重要。但是,如果只将客户端指向第一个节点,那么当该节点发生故障时,客户端无法再访问该服务。这就是为什么将负载均衡器放在节点前面以确保发送的请求传播到所有健康节点,并且从不将它们发送到当时处于脱机状态的节点的原因。
如果Kubernetes集群支持它(当Kubernetes部署在云基础设施上时,大多数情况都是如此),那么可以通过创建一个Load Badancer而不是NodePort服务自动生成负载均衡器。接下来介绍此部分。
5.3.2 通过负载均衡器将服务暴露出来
在云提供商上运行的Kubernetes集群通常支持从云基础架构自动提供负载平衡器。所有需要做的就是设置服务的类型为Load Badancer而不是NodePort。负载均衡器拥有自己独一无二的可公开访问的IP地址,并将所有连接重定向到服务。可以通过负载均衡器的IP地址访问服务。
如果Kubernetes在不支持Load Badancer服务的环境中运行,则不会调配负载平衡器,但该服务仍将表现得像一个NodePort服务。这是因为Load Badancer服务是NodePort服务的扩展。可以在支持Load Badancer服务的Google Kubernetes Engine上运行此示例。Minikube没有,至少在写作本书的时候。
创建LoadBalance服务
要使用服务前面的负载均衡器,请按照以下YAML manifest创建服务,代码清单如下所示。
代码清单5.12 Load Badancer类型的服务:kubia-svc-loadbalancer.yaml

服务类型设置为LoadBalancer而不是NodePort。如果没有指定特定的 NodePort Service,Kubernetes将会选择一个端口。
通过负载均衡器连接服务
创建服务后,云基础架构需要一段时间才能创建负载均衡器并将其IP地址写入服务对象。一旦这样做了,IP地址将被列为服务的外部IP地址:
$ kubectl get svc kubia-loadbalancer
在这种情况下,负载均衡器的IP地址为130.211.53.173,因此现在可以通过该IP地址访问该服务:
$ curl http://130.211.53.173
成功了!可能像你已经注意到的那样,这次不需要像以前使用NodePort服务那样来关闭防火墙。
会话亲和性和Web浏览器
由于服务现在已暴露在外,因此可以尝试使用网络浏览器访问它。但是会看到一些可能觉得奇怪的东西——每次浏览器都会碰到同一个pod。此时服务的会话亲和性是否发生变化?使用kubectl explain,可以再次检查服务的会话亲缘性是否仍然设置为None,那么为什么不同的浏览器请求不会碰到不同的pod,就像使用curl时那样?
现在阐述为什么会这样。浏览器使用keep-alive连接,并通过单个连接发送所有请求,而curl每次都会打开一个新连接。服务在连接级别工作,所以当首次打开与服务的连接时,会选择一个随机集群,然后将属于该连接的所有网络数据包全部发送到单个集群。即使会话亲和性设置为None,用户也会始终使用相同的pod(直到连接关闭)。
请参阅图5.7,了解HTTP请求如何传递到该pod。外部客户端(可以使用curl)连接到负载均衡器的80端口,并路由到其中一个节点上的隐式分配节点端口。之后该连接被转发到一个pod实例。
如前所述,LoadBalancer类型的服务是一个具有额外的基础设施提供的负载平衡器NodePort服务。如果使用kubectl describe来显示有关该服务的其他信息,则会看到为该服务选择了一个 NodePort。如果要为此端口打开防火墙,就像在上一节中对NodePort服务所做的那样,也可以通过节点IP访问服务。
提示 如果使用的是Minikube,尽管负载平衡器不会被分配,仍然可以通过 NodePort(位于Minikube VM的IP地址)访问该服务。

图 5.7 外部客户端连接一个LoadBalancer服务
5.3.3 了解外部连接的特性
你必须了解与服务的外部发起的连接有关的几件事情。
了解并防止不必要的网络跳数
当外部客户端通过 NodePort 连接到服务时(这也包括先通过负载均衡器时的情况),随机选择的pod并不一定在接收连接的同一节点上运行。可能需要额外的网络跳转才能到达pod,但这种行为并不符合期望。
可以通过将服务配置为仅将外部通信重定向到接收连接的节点上运行的pod来阻止此额外跳数。这是通过在服务的spec部分中设置 externalTrafficPolicy 字段来完成的:
spec:
externalTrafficPolicy: Local
...
如果服务定义包含此设置,并且通过服务的 NodePort 打开外部连接,则服务代理将选择本地运行的pod。如果没有本地pod存在,则连接将挂起(它不会像不使用注解那样,将其转发到随机的全局pod)。因此,需要确保负载平衡器将连接转发给至少具有一个pod的节点。
使用这个注解还有其他缺点。通常情况下,连接均匀分布在所有的pod上,但使用此注解时,情况就不再一样了。
想象一下两个节点有三个pod。假设节点A运行一个pod,节点B运行另外两个pod。如果负载平衡器在两个节点间均匀分布连接,则节点A上的pod将接收所有连接的50%,但节点B上的两个pod每个只能接收25%,如图5.8所示。

图5.8 使用local外部流量策略的服务可能会导致跨pod的负载分布不均衡
记住客户端IP是不记录的
通常,当集群内的客户端连接到服务时,支持服务的pod可以获取客户端的IP地址。但是,当通过 NodePort接收到连接时,由于对数据包执行了源网络地址转换(SNAT),因此数据包的源IP将发生更改。
后端的pod无法看到实际的客户端IP,这对于某些需要了解客户端IP的应用程序来说可能是个问题。例如,对于Web服务器,这意味着访问日志无法显示浏览器的IP。
上一节中描述的local外部流量策略会影响客户端IP的保留,因为在接收连接的节点和托管目标pod的节点之间没有额外的跳跃(不执行SNAT)。
5.4 通过Ingress暴露服务
现在已经介绍了向集群外部的客户端公开服务的两种方法,还有另一种方法——创建Ingress资源。
定义 Ingress(名词)——进入或进入的行为;进入的权利;进入的手段或地点;入口。
接下来解释为什么需要另一种方式从外部访问Kubernetes服务。
为什么需要Ingress
一个重要的原因是每个LoadBalancer 服务都需要自己的负载均衡器,以及独有的公有IP地址,而Ingress只需要一个公网IP就能为许多服务提供访问。当客户端向Ingress发送HTTP请求时,Ingress会根据请求的主机名和路径决定请求转发到的服务,如图5.9所示。
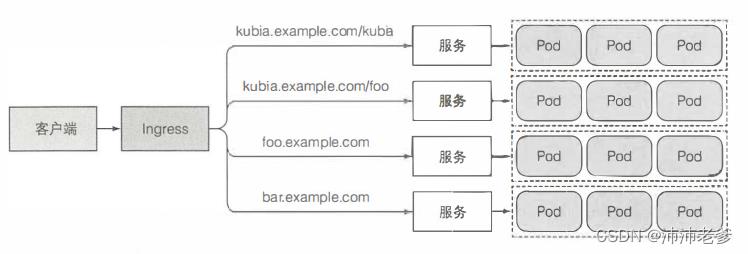
图5.9 通过一个Ingress暴露多个服务
Ingress在网络栈(HTTP)的应用层操作,并且可以提供一些服务不能实现的功能,诸如基于cookie的会话亲和性(session affinity)等功能。
Ingress控制器是必不可少的
在介绍Ingress对象提供的功能之前,必须强调只有Ingress控制器在集群中运行,Ingress资源才能正常工作。不同的Kubernetes环境使用不同的控制器实现,但有些并不提供默认控制器。
例如,Google Kubernetes Engine使用Google Cloud Platform带有的HTTP负载平衡模块来提供Ingress功能。最初,Minikube没有提供可以立即使用的控制器,但它现在包含一个可以启用的附加组件,可以试用Ingress功能。请根据下面的补充信息里的说明确保Ingress功能已启用。
在minikube上启动Ingress的扩展功能
如果使用Minikube运行本书中的示例,则需要确保已启用Ingress附加组件。可以通过列出所有附件来检查Ingress是否已启动:
$ minikube addons list |-----------------------------|----------|--------------|-------------------------------- | ADDON NAME | PROFILE | STATUS | MAINTAINER |-----------------------------|----------|--------------|--------------------------------| | ambassador | minikube | disabled | third-party (ambassador) | | auto-pause | minikube | disabled | google | | csi-hostpath-driver | minikube | disabled | kubernetes | | dashboard | minikube | enabled ✅ | kubernetes | | default-storageclass | minikube | enabled ✅ | kubernetes | | efk | minikube | disabled | third-party (elastic) | | freshpod | minikube | disabled | google | | gcp-auth | minikube | disabled | google | | gvisor | minikube | disabled | google | | helm-tiller | minikube | disabled | third-party (helm) | | ingress | minikube | disabled | unknown (third-party) | ...通过本书可以了解这些附加组件,但应该对dashboard和kube-dns附件的用途十分清楚。启用Ingress附加组件,并查看正在运行的Ingress:
$ minikube addons enable ingress这应该会在另一个pod上运行一个Ingress控制器。控制器pod很可能位于kube-system命名空间中,但也不一定是这样,所以使用 --all-namespaces 选项列出所有命名空间中正在运行的pod:
$ kubectl get po --all-namespace在输出的底部,会看到Ingress控制器pod。该名称暗示nginx(一种开源HTTP服务器并可以做反向代理)用于提供Ingress功能。
提示 当不知道pod(或其他类型的资源)所在的命名空间,或者是否希望跨所有命名空间列出资源时,利用补充说明中提到的 --all-namespaces 选项非常方便。
5.4.1 创建Ingress资源
已经确认集群中正在运行Ingress控制器,因此现在可以创建一个Ingress资源。下面的代码清单显示了Ingress的示例YAML:
代码清单5.13 Ingress资源的定义:kubia-ingress.yaml
apiVersion: entensions/v1 kind: Ingress metadata: name: kubia spec: rules: - host: kubia.example.com http: paths: - path: / backend: serviceName: kubia-nodeport servicePort:80
定义了一个单一规则的Ingress,确保Ingress控制器收到的所有请求主机http://kubia.example.com的HTTP请求,将被发送到端口80上的kubia-nodeport服务。
*
注意 云供应商的Ingress控制器(例如GKE)要求Ingress指向一个NodePort服务。但Kubernetes并没有这样的要求。*
5.4.2 通过Ingress访问服务
要通过 http://kubia.example.com 访问服务,需要确保域名解析为Ingress控制器的IP。
获取Ingress的IP地址
要查找IP,需要列出Ingress:
$ kubectl get ingresses
***
注意 在云提供商的环境上运行时,地址可能需要一段时间才能显示,因为Ingress控制器在幕后调配负载均衡器。
IP在ADDRESS列中显示出来。
**确保在Ingress中配置的Host指向Ingress的IP地址**
一旦知道IP地址,通过配置DNS服务器将 kubia.example.com 解析为此IP地址,或者在 /ect/hosts 文件(Windows系统为 C:\\windows\\system32\\drivers\\etc\\hosts )中添加下面一行内容:
```bash
192.168.99.100 kubia.example.com
通过Ingress访问pod
环境都已经建立完毕,可以通过 http://kubia.example.com 地址访问服务(使用浏览器或者curl命令):
$ curl http://kubia.example.com
现在已经通过Ingress成功访问了该服务,接下来对其展开深层次的研究。
了解Ingress的工作原理
图5.10显示了客户端如何通过Ingress控制器连接到其中一个pod。客户端首先对 kubia.example.com 执行DNS查找,DNS服务器(或本地操作系统)返回了Ingress控制器的IP。客户端然后向Ingress控制器发送HTTP请求,并在Host头中指定 kubia.example.com。控制器从该头部确定客户端尝试访问哪个服务,通过与该服务关联的Endpoint对象查看pod IP,并将客户端的请求转发给其中一个pod。
如你所见,Ingress控制器不会将请求转发给该服务,只用它来选择一个pod。大多数(即使不是全部)控制器都是这样工作的。

图5.10 通过Ingress访问pod
5.4.3 通过相同的Ingress暴露多个服务
如果仔细查看Ingress规范,则会看到rules和paths都是数组,因此它们可以包含多个条目。一个Ingress可以将多个主机和路径映射到多个服务,我们先来看看paths字段。
将不同的服务映射到相同主机的不同路径
将不同的服务映射到相同主机的不同paths,以下面的代码清单为例。
代码清单5.14 在同一个主机、不同的路径上,Ingress暴露出多个服务

在这种情况下,根据请求的URL中的路径,请求将发送到两个不同的服务。因此,客户端可以通过一个IP地址(Ingress控制器的IP地址)访问两种不同的服务。
将不同的服务映射到不同的主机上
同样,可以使用Ingress根据HTTP请求中的主机而不是(仅)路径映射到不同的服务,如下面的代码清单所示。
代码清单5.15 Ingress根据不同的主机(host)暴露出多种服务

根据请求中的Host头(虚拟主机在网络服务器中处理的方式),控制器收到的请求将被转发到foo服务或bar服务。DNS需要将 foo.example.com 和 bar.example.com 域名都指向Ingress控制器的IP地址。
5.4.4 配置Ingress处理TLS传输
我们已经知道Ingress如何转发HTTP流量。但是HTTPS呢?接下来了解一下如何配置Ingress以支持TLS。
**为Ingress创建TLS认证
当客户端创建到Ingress控制器的TLS连接时,控制器将终止TLS连接。客户端和控制器之间的通信是加密的,而控制器和后端pod之间的通信则不是。运行在pod上的应用程序不需要支持TLS。例如,如果pod运行web服务器,则它只能接收HTTP通信,并让Ingress控制器负责处理与TLS相关的所有内容。要使控制器能够这样做,需要将证书和私钥附加到Ingress。这两个必需资源存储在称为Secret的Kubernetes资源中,然后在Ingress manifest中引用它。我们将在第7章中详细介绍Secret。现在,只需创建Secret,而不必太在意。
首先,需要创建私钥和证书:
$ openssl genrsa -out tls.key 2048
$ openssl req -new -x509 -key tls.key -out tls.cert -days 360 -subj CN=kubia.example.com
像下述两个文件一样创建Secret:
$ kubectl create secret tls-secret --cert=tls.cert --key=tls.key
通过CertificateSigningRequest资源签署证书
可以不通过自己签署证书,而是通过创建CertificateSigningRequest(CSR)资源来签署。用户或他们的应用程序可以创建一个常规证书请求,将其放入CSR中,然后由人工操作员或自动化程序批准请求,像这样:$ kubectl certificate approve <name of the CSR>然后可以从CSR的status.certificate字段中检索签名的证书。
请注意,证书签署者组件必须在集群中运行,否则创建CertificateSigningRequest以及批准或拒绝将不起作用。
私钥和证书现在存储在名为tls-secret的Secret中。现在,可以更新Ingress对象,以便它也接收 kubia.example.com 的HTTPS请求。Ingress现在看起来应该像下面的代码清单。
代码清单5.16 Ingress处理TLS传输:kubia-ingress-tls.yaml

提示 可以调用 kubectl apply -f kubia-ingress-tls.yaml 使用文件中指定的内容来更新Ingress资源,而不是通过删除并从新文件重新创建的方式。
现在可以使用HTTPS通过Ingress访问服务:
$ curl -k -v https://kubia.example.com/kubia
* About to connect() to kubia example com port 443 (#0)
...
* Server certificate:
subject: CN=kub . example.com
...
> GET /kubia HTTP .1
>...
You ' ve hit kubia-xueql
该命令的输出显示应用程序的响应,以及配置的Ingress的证书服务器的响应。
注意 对Ingress功能的支持因不同的Ingress控制器实现而异,因此请检查特定实现的文档以确定支持的内容。
Ingress是一个相对较新的Kubernetes功能,因此可以预期将来会看到许多改进和新功能。虽然目前仅支持L7(网络第7层)(HTTP /HTTPS)负载平衡,但也计划支持L4(网络第4层)负载平衡。
5.5 pod就绪后发出信号
还有一件关于Service和Ingress的事情需要考虑。已经了解到,如果pod的标签与服务的pod选择器相匹配,那么pod就将作为服务的后端。只要创建了具有适当标签的新pod,它就成为服务的一部分,并且请求开始被重定向到pod。但是,如果pod没有准备好,如何处理服务请求呢?
该pod可能需要时间来加载配置或数据,或者可能需要执行预热过程以防止第一个用户请求时间太长影响了用户体验。在这种情况下,不希望该pod立即开始接收请求,尤其是在运行的实例可以正确快速地处理请求的情况下。不要将请求转发到正在启动的pod中,直到完全准备就绪。
5.5.1 介绍就绪探针
在之前的章节中,了解了存活探针,以及它们如何通过确保异常容器自动重启来保持应用程序的正常运行。与存活探针类似,Kubernetes还允许
以上是关于Kubernetes in Action 5 服务:让客户端发现pod并与之通信的主要内容,如果未能解决你的问题,请参考以下文章