Golang开发面经B站(两轮技术面)
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Golang开发面经B站(两轮技术面)相关的知识,希望对你有一定的参考价值。
文章目录
写在前面
面试下来我感觉我都讲出来了,算法题也写出来了,但是二面完一查结果就直接淘汰了。这个B是不是不招人啊。。
笔试
略
一面
Go的GMP模型
G:表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
P:表示逻辑processor,P 的数量决定了系统内最大可并行的 G 的数量(前提:系统的物理cpu核数 >= P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
M:M 代表着真正的执行计算资源,物理 Processor。
G 如果想运行起来必须依赖 P,因为 P 是它的
逻辑处理单元,但是 P 要想真正的运行,他也需要与 M 绑定,这样才能真正的运行起来,P 和 M 的这种关系就相当于 Linux 系统中的用户层面的线程和内核的线程是一样的。

GO的GC
Go是采用三色标记法来进行垃圾回收的,是传统 Mark-Sweep 的一个改进,它是一个并发的 GC 算法。on-the-fly
原理如下
- 整个进程空间里申请每个对象占据的内存可以视为一个图, 初始状态下每个内存对象都是白色标记。
- 先
stop the world,将扫描任务作为多个并发的goroutine立即入队给调度器,进而被CPU处理,第一轮先扫描所有可达的内存对象,标记为灰色放入队列 - 第二轮可以恢复start the world,将第一步队列中的对象引用的对象置为灰色加入队列,一个对象引用的所有对象都置灰并加入队列后,这个对象才能置为黑色并从队列之中取出。循环往复,最后队列为空时,整个图剩下的白色内存空间即不可到达的对象,即没有被引用的对象;
- 第三轮再次
stop the world,将第二轮过程中新增对象申请的内存进行标记(灰色),这里使用了writebarrier(写屏障)去记录这些内存的身份;
这个算法可以实现 on-the-fly,也就是在程序执行的同时进行收集,并不需要暂停整个程序。
简化步骤如下:
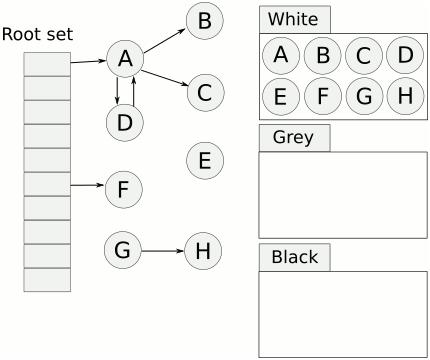
1、首先创建三个集合:白、灰、黑。
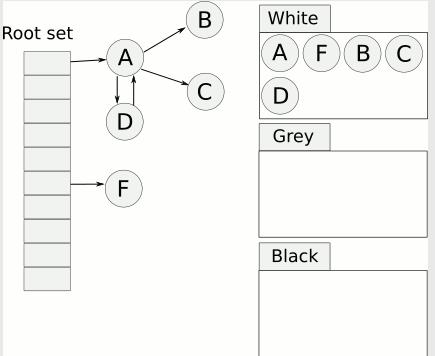
2、将所有对象放入白色集合中。

3、然后从根节点开始遍历所有对象(注意这里并不递归遍历),把遍历到的对象从白色集合放入灰色集合。
因为root set 指向了A、F,所以从根结点开始遍历的是A、F,所以是把A、F放到灰色集合中。
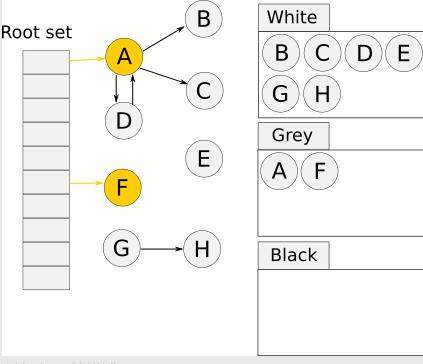
4、之后遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,之后将此灰色对象放入黑色集合
我们可以发现这个A指向了B,C,D所以也就是把BCD放到灰色中,把A放到黑色中,而F没有指任何的对象,所以直接放到黑色中。
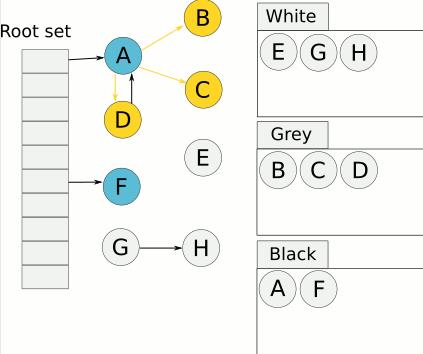
5、重复 4 直到灰色中无任何对象
因为D指向了A所以D也放到了黑色中,而B和C能放到黑色集合中的道理和F一样,已经没有了可指向的对象了。
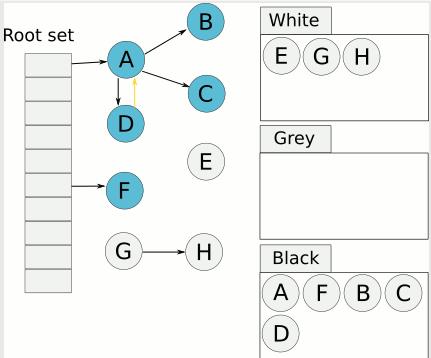
6、通过write-barrier检测对象有无变化,重复以上操作
由于这个EGH并没有和RootSet有直接或是间接的关系,所以就会被清除。
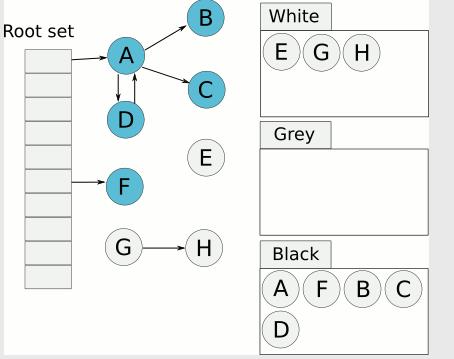
7、收集所有白色对象(垃圾)
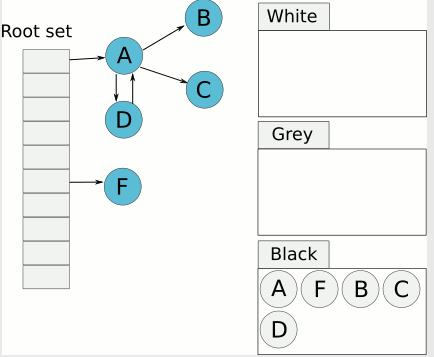
所以我们可以看出这里的情况,只要是和root set根集合直接相关的对象或是间接相关的对象都不会被清楚。只有不相关的才会被回收。
Go的map底层是怎么实现的?
map 的底层是一个结构体
// Go map 的底层结构体表示
type hmap struct
count int // map中键值对的个数,使用len()可以获取
flags uint8
B uint8 // 哈希桶的数量的log2,比如有8个桶,那么B=3
noverflow uint16 // 溢出桶的数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向哈希桶数组的指针,数量为 2^B
oldbuckets unsafe.Pointer // 扩容时指向旧桶的指针,当扩容时不为nil
nevacuate uintptr
extra *mapextra // 可选字段
const (
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits // 桶数量 1 << 3 = 8
)
// Go map 的一个哈希桶,一个桶最多存放8个键值对
type bmap struct
// tophash存放了哈希值的最高字节
tophash [bucketCnt]uint8
// 在这里有几个其它的字段没有显示出来,因为k-v的数量类型是不确定的,编译的时候才会确定
// keys: 是一个数组,大小为bucketCnt=8,存放Key
// elems: 是一个数组,大小为bucketCnt=8,存放Value
// 你可能会想到为什么不用空接口,空接口可以保存任意类型。但是空接口底层也是个结构体,中间隔了一层。因此在这里没有使用空接口。
// 注意:之所以将所有key存放在一个数组,将value存放在一个数组,而不是键值对的形式,是为了消除例如map[int64]所需的填充整数8(内存对齐)
// overflow: 是一个指针,指向溢出桶,当该桶不够用时,就会使用溢出桶
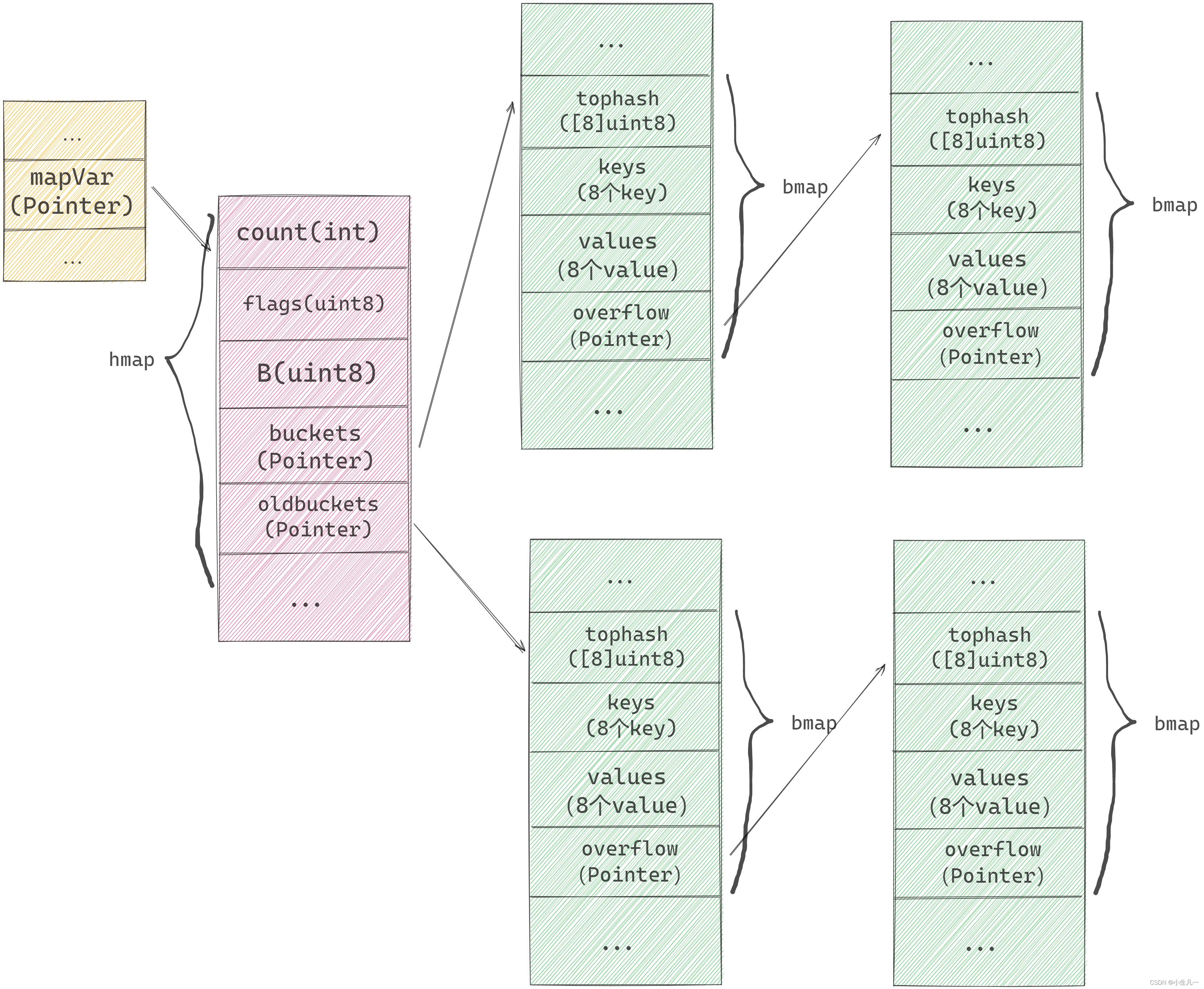
当向 map 中存储一个 kv 时,通过 k 的 hash 值与 buckets 长度取余,定位到 key 在哪一个bucket中,hash 值的高8位存储在 bucket 的 tophash[i] 中,用来快速判断 key是否存在。当一个 bucket 满时,通过 overflow 指针链接到下一个 bucket。
遍历map是有序的吗?为什么?
不是有序的,使用 range 多次遍历 map 时输出的 key 和 value 的顺序可能不同,map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的 cell 开始遍历。map 遍历时,是按序遍历 bucket,同时按需遍历 bucket 和其 overflow bucket 中 的 cell。
但是 map 在扩容后,会发生 key 的搬迁,这造成原来落在一个 bucket 中的 key,搬迁后,有可能会落到其他 bucket 中了,从这个角度看,遍历 map 的结果就不可能是按照原来的顺序了。
map作为函数是什么传递?
map 传的是地址值
在函数里面修改map会影响原来的吗?
会的,因为传递的map的地址,会对原来的map进行修改。
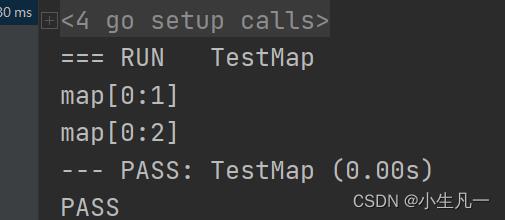
func TestMap(t *testing.T)
a := make(map[int]int)
a[0] = 1
fmt.Println(a)
changeMap(a)
fmt.Println(a)
func changeMap(b map[int]int)
b[0] = 2
结果如下
那数组呢?
数组不会,数组不是引用类型,传的值传递,并不是应用传递。
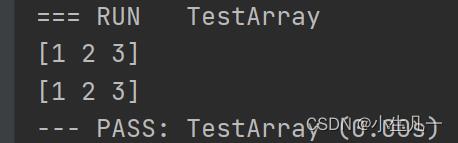
func TestArray(t *testing.T)
a := [3]int1, 2, 3
fmt.Println(a)
changeArray(a)
fmt.Println(a)
func changeArray(a [3]int)
a[0] = 1
切片呢?
会,和 map 一样,都是引用类型。传递的是地址。
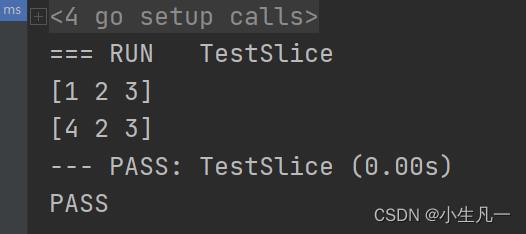
func TestSlice(t *testing.T)
a := make([]int, 3, 3)
a[0] = 1
a[1] = 2
a[2] = 3
fmt.Println(a)
changeSlice(a)
fmt.Println(a)
func changeSlice(a []int)
a[0] = 4
linux有用过是吧?如何查看一个服务是否在运行?
- 如果我们知道服务名,我们可以使用 ps 命令:
ps -ef | grep 服务名 或 ps aux |grep 服务名 - 如果知道端口号,我们可以使用 lsof 命令:
lsof -i:端口号 - 或者也可以用这个:
systemctl status 服务名 或 service 服务名 status - 如果是基于 tcp 的连接,还可以使用
netstat查看端口和进程等相关内容。netstat -tnlp
我只知道这个文件名,能找到这个文件在哪里吗?
可以使用 find 命令
find / -name "main.go"
用过mysql是吧?mysql 索引说一下?
mysql 的索引包括** 基于InnoDB的聚集索引、基于MyISAM的非聚集索引、primary key 主键索引、secondary key 次要索引**
-
基于InnoDB的聚集索引:主键索引(聚集索引)的
叶子结点会存储数据行,也就是说数据和索引在一起,辅助索引只会存储主键值 -
基于MyISAM的非聚集索引:B+树叶子结点只会存储数据行(数据文件)的指针,简单来说就是
数据和索引不在一起,非聚集索引包含 主键索引 和 辅助索引 到会存储指针的值。 -
primary key 主键索引:InnoDB要求表必须有主键(
MyISAM可以没有),如果没有,MySQL系统会自动选择一个唯一标识数据记录的列作为主键。 -
secondary key 次要索引:结构和主键搜索引没有任何区别,
同样用 B+Tree,data域存储相应记录主键的值而不是地址。
死锁是怎么产生的
产生死锁就有四个必要条件:互斥条件、请求和保持条件、不剥夺条件、环路等待条件。
了解分布式锁吗?讲讲红锁?
只磕磕绊绊讲了一些分布式锁,红锁就不太记得了(
可以看看这篇博客 基于Go语言的分布式红锁
算法:反转链表。这写不出来的话,就说不过去了。
二面
TCP和UDP区别?
TCP 是可靠传输,面向连接,基于流,占用资源多,效率低。
UDP是尽最大努力交付,基于无连接,基于报文,UDP 占用系统资源较少,效率高。
TCP是可靠传输,为什么还有丢包的情况?
丢包是网络问题,TCP的可靠是可靠在如果发生丢包,那么会立即重传报文段。
UDP能实现可靠传输吗?怎么实现?
可以的,我们只需要仿照TCP的可靠传输机制就可以了,比如说设置ACK确认机制,一旦没有收到,或是收到三次上一个报文的ACK,我们就立即重传丢失的报文。再比如说设置滑动窗口来保证数据传输的安全性等等…
TCP和IP的区别是什么?
TCP 是传输控制协议(Transmission Control Protocal),是基于IP的传输层协议,是传输层的,IP 是因特网协议(Internet Protocol)在网络层的。
四次挥手的细节?
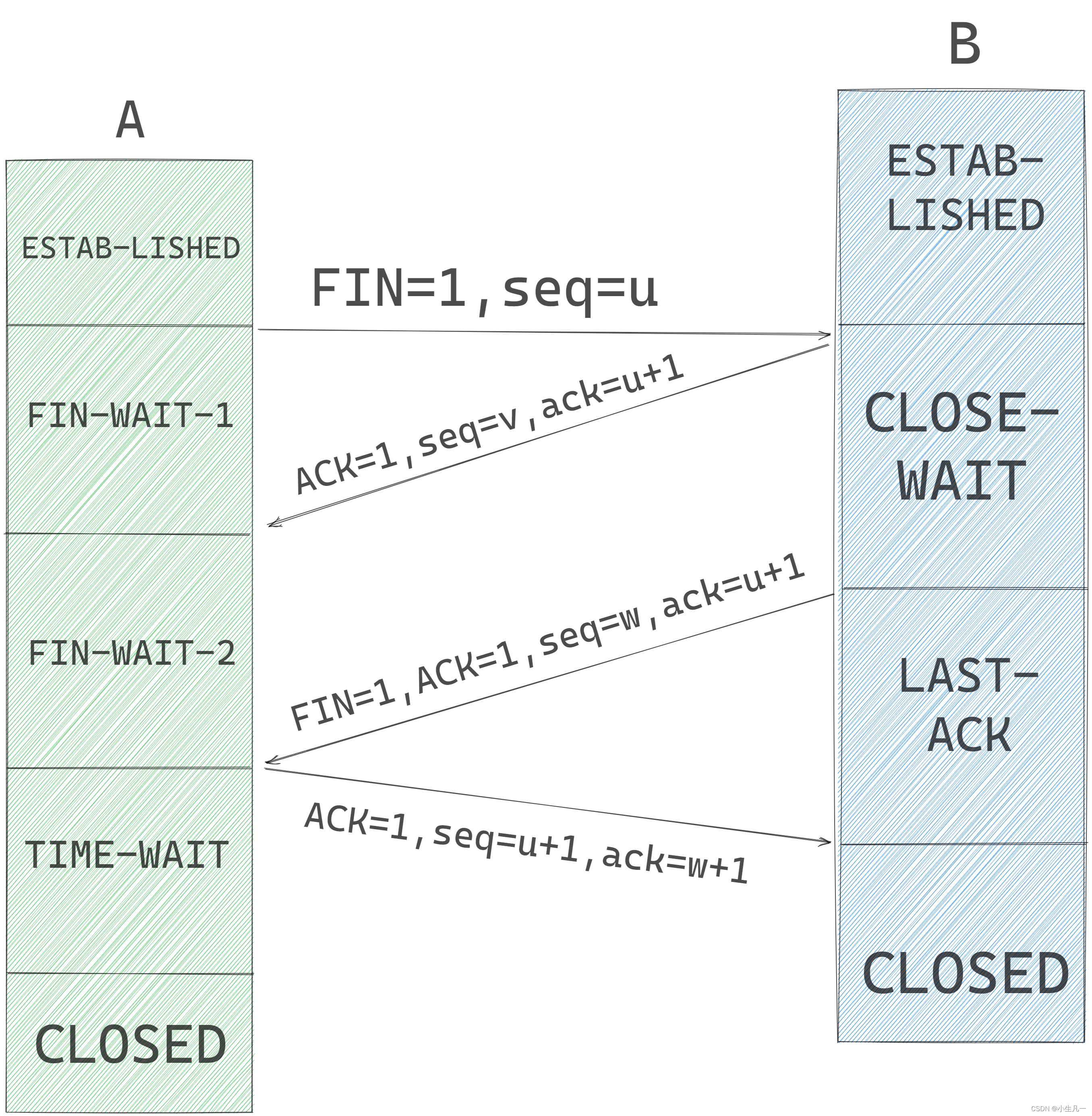
数据传输完毕之后,通信的双方都可释放连接。现在A和B都处于ESTABLISHED状态。
- A的应用进程先向TCP发出连接释放报文段,并停止再发送数据,主动关闭TCP连接。A把链接释放报文段首部的终止控制位
FIN置为1,其序号为seq=u,它等于前面以传送过的数据的最后一个字节的序号加1.这时候A进入了FIN-WAIT-1(终止等待1)状态,等待B的确认。
注意:TCP规定,FIN报文段即使不携带数据,他也消耗掉一个序号!!
- B 收到链接释放报文段后即发出确认,确认号是
ack = u + 1,而这个报文段自己的序号是v,等于B前面已传送过的数据的最后一个字节的序号加1.然后B就进入CLOSE-WAIT(关闭等待)状态。TCP服务器进程这时应通知高层应用进程,因而从A到B这个方向的链接就释放了,这时的TCP链接处于半关闭状态,即A已经没有数据要发送了,但B若发送数据,A仍要接收,也就是说,从B到A这个方向的连接并未关闭。这个状态可能要维持一段时间。 - A收到来自B的确认后,就进入了
FIN-WAIT-2(终止等待2)状态满等待B发出的连接释放报文段。若B已经没有要向A发送的数据,其应用进程就通知TCP释放连接,这时B发出的连接释放报文段必须使FIN = 1,现假定B的序号为w(在半关闭状态B可能又发送了一些数据)。B还必须重复上次已发送过的确认号ack = u + 1.这时B就进入LAST-ACK(最后确认)状态,等待A的确认。 - A在收到了B的链接释放报文段后,必须对此发出确认。在确认报文段中把
ACK置1,确认号ack=w+1,而自己的序号是seq=u+1(根据TCP标准,前面发送过的FIN报文段要消耗一个序号)。然后进入到TIME-WAIT(时间等待)状态。注意: 现在TCP连接还没有还没有释放掉。必须经过时间等待计时器设置的时间2MSL后,A才能进入CLOSED状态。
时间MSL叫做最长报文段寿命,RFC793建议设在两分钟。但是在现在工程来看两分钟太长了,所以TCP允许不同的实现可以根据具体情况使用更小的MSL值。
为什么 time_wait 是2MLS?
- 为了保证A发送的最后一个ACK报文段能够到达B。 这个ACK报文段有可能丢失,因而使处于在 LAST-ASK 状态的B收不到对己发送的 FIN-ACK 报文段的确认。
B会超时重传这个FIN+ACK报文段,而A就能在 2MSL 时间内收到这个重传的FIN+ACK报文段。而A就能在2MSL时间内收到这个重传的FIN+ACK报文段。接着A重传一次确认,重新启动2MSL计时器。最后的A和B都正常进入CLOSED状态。如果A在TIME-WAIT状态不等待一段时间,而实发送完ACK报文段后立即释放连接,那么就无法收到B重传的FIN+ACK报文段,因而也不会再发送一次确认报文段。 - 防止了“已失效的连接请求报文段”。 A在发送完最后一个ACK报文段后,在经过时间2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,这样就可以使下一个连接中不会出现这种旧的连接请求报文段。
B只要收到了A发出的确认,就进入CLOSED状态。同样,B在撤销相应的传输控制块TCB后,就结束了这次的TCP连接。
大量处于 close wait 的是什么场景? 如何解决?
通常出现大量的CLOSE_WAIT,说明Server端没有发起close()操作,这基本上是用户server 端程序的问题了;
通常情况下,Server都是等待Client访问,如果Client退出请求关闭连接,server端自觉close()对应的连接。
一般是程序 Bug,或者关闭 socket 不及时。服务端接口耗时较长,客户端主动断开了连接,此时,服务端就会出现 close_wait。
这个我们就只能检查自己代码了,用netstat或是其他工具,检测代码为啥耗时长。
cookie和session有什么区别?
cookie和session的共同之处在于:cookie和session都是用来跟踪浏览器用户身份的会话方式。cookie数据保存在客户端,session数据保存在服务器端。
你是用go的是吧?chan用过吧?那说说对一个关闭的chan做读写会发生什么操作?为什么?
- 读已经关闭的 chan 能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
如果有元素,就继续读剩下的元素,如果没有就是这个chan类型的零值,比如整型是 int,字符串是 ""。 - 写已经关闭的 chan 会 panic。因为源码上面就是这样写的,可以看
src/runtime/chan.go
map 的底层说一下?
看上面
如果你这个项目,我突然有一个时间段,多了很多流量,要怎么处理?
- 我们要延长一些 token,cookie的设置时间,或是设置这些过期时间不一样,防止缓存雪崩的情况。
- 设置布隆过滤器,防止缓冲击穿情况。
- 使用 nginx 进行 http/https 的流量分发。使用轮询,随机,哈希,一致性哈希等等进行负载均衡等等…
- 提高服务自身性能,比如sql的索引,语法层面的调参等等…
- 引入CDN进行加速。
- 提高服务器配置。
- …
算法:连续子序列的最大和
参考资料
[1] https://blog.csdn.net/Peerless__/article/details/125458742
以上是关于Golang开发面经B站(两轮技术面)的主要内容,如果未能解决你的问题,请参考以下文章