《PersFormer:3D Lane Detection via Perspective Transformer and the OpenLane Benchmark》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《PersFormer:3D Lane Detection via Perspective Transformer and the OpenLane Benchmark》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:PersFormer_3DLane
OpenLane数据地址:OpenLane
1. 概述
介绍:在2D场景下检测得到的车道线在下游任务中会将其转换到bev空间下,但车辆在行驶过程中yaw和pitch是会存在一定程度偏移的,也就导致了bev空间下的车道线会出现交汇和发散的情况。对于这样的问题一种方案是通过姿态估计算法解算更准确的位姿,另外一种便是将其直接在bev空间下完成检测任务,这篇文章的方法属于后者。在这篇文章中建立2D bev空间到前视图像特征的映射关系,并通过该关系构建bev特征,并在bev特征上完成车道线预测,从而避免了车道线空间转换带来的问题。此外,在bev检测的基础上引入2D空间下的传统车道线检测算法,实现多任务联合训练,并使用uncertain_loss对这些损失函数进行调和。最后,文章公开了一个大型3D车道线检测数据集OpenLane,数据量和数据覆盖范围还是很广的。
总结现有的bev车道线获取方案,将其归纳为如下三种:
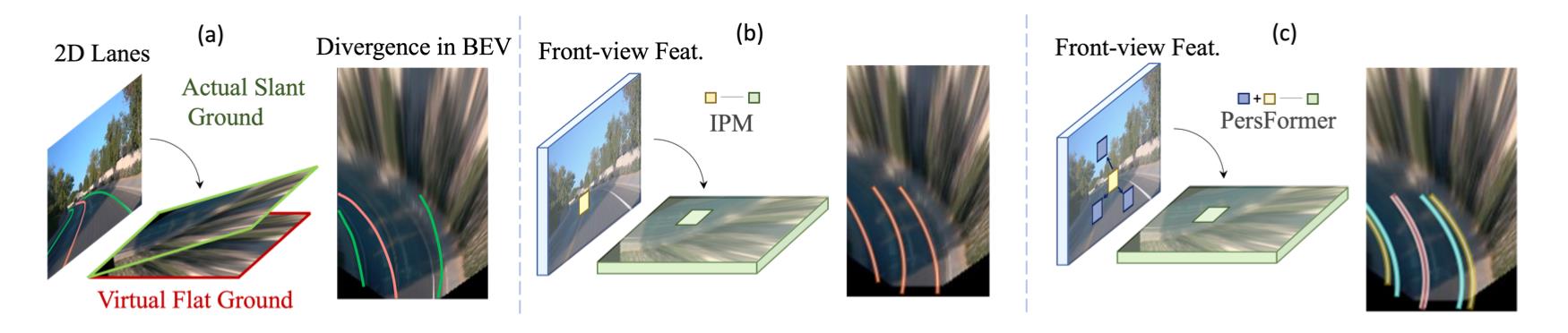
- 1)在2D图像上完成车道线检测,并通过平面投影实现bev车道线检测,但是会存在pitch和yaw影响。
- 2)根据相机内外参数将图像特征直接投影为bev特征,之后在bev特征上进行车道线预测,但是却有一个问题是投影的位置往往并不与实际位置相对应,因为还有depth未知,因而是次优的。
- 3)在通过IPM建立bev特征与图像特征之间的关系,并通过deformable attention增强感知能力,这就是这篇文章使用的方案。
2. 方法设计
2.1 pipeline
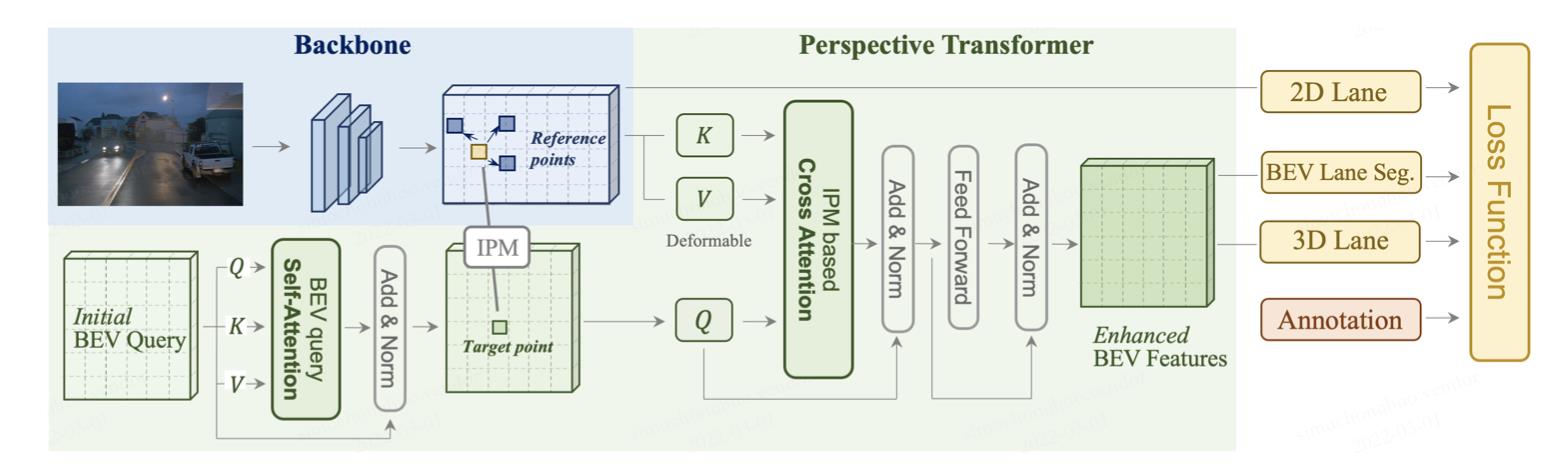
文章方法的pipeline见上图,可以将其分为3个主要部分:
- 1)由resnet构成的图像特征抽取网络,生成不同尺寸的特征图。
- 2)预定义不同尺寸的bev网格作为bev query,经过经过self-attention对query进行优化(这里也是deformable attention),之后在相机内外参数作为先验下建立bev grid与图像特征之间变换关系,从而得到bev特征。上述的操作会在不同stride的图像特征下进行,最后得到的bev特征会经过bev_head模块融合得到完整分辨率的bev特征。
- 3)在2D图像特征上使用传统车道线检测算法,在bev特征上使用3D车道线检测算法,组成多任务训练框架,并用uncertain_loss实现不同任务损失权重调整。
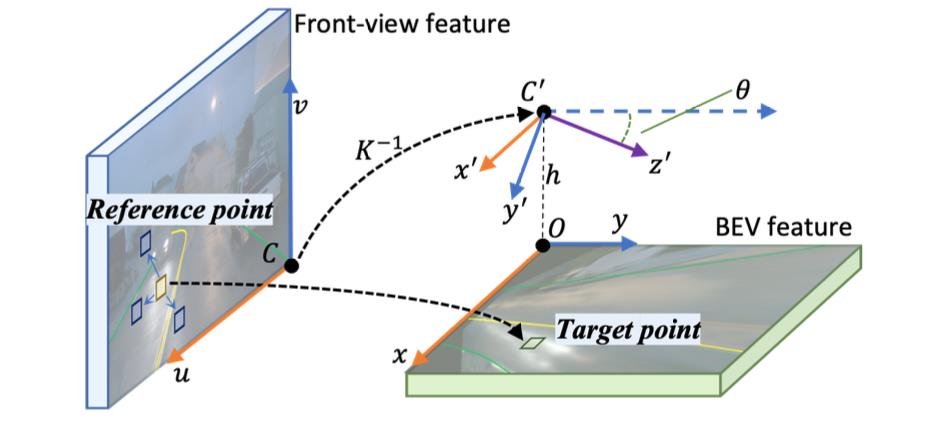
2.2 bev特征构建
这里bev特征的构建是在不同stride的图像特征下完成的,因而就会有多个bev query。这里bev query的运算过程包含了query自身的refine,以及在相机内外参数引导下的refine。这里相机内弯参数实现的是bev grid中target和图像特征中reference的关联,并使用deformable attention在reference的基础上添加offset实现提升感知能力,避免深度不符合先验导致特征抽取问题。下图展示了bev中target与图像特征reference之间的映射关系:
bev query的self-attention,以bev grid作为attention中心点:
# models/networks/Layers.py#L142
query = self.self_attn( query + bev_pos, # bev query添加bev pos位置信息
reference_points=ref_2d,
input_flatten=temp_value,
input_spatial_shapes=torch.tensor(
[[bev_h, bev_w]], device=query.device),
input_level_start_index=torch.tensor(
[0], device=query.device),
identity=identity)
以内外参数确定target和reference实现cross attention:
# models/networks/Layers.py#L155
# cross attention
query = self.cross_attn(query,
reference_points=ref_3d,
input_flatten=value,
input_spatial_shapes=spatial_shapes,
input_level_start_index=level_start_index)
上述的过程会在不同stride图像特征上重复多次,之后这些特征会送入bev_head优化得到完整分辨率bev特征:
# models/PersFormer.py#L76
# BEV feature extractor
self.bev_head = BEVHead(args, channels=args.feature_channels)
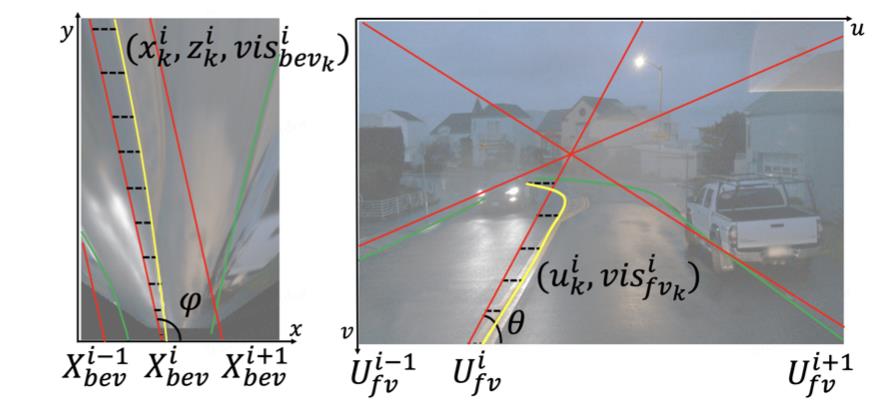
2.3 车道线预测
这里车道线预测是参考了LaneATT中anchor的方案,同时在图像特征上和bev特征上进行,区别是增加了是否可视类别属性预测
v
i
s
b
e
v
,
v
i
s
f
v
vis_bev,\\ vis_fv
visbev, visfv。
不同任务头使用可学习的uncertain_loss自动调配权重:
# uncertainty loss weight
self.uncertainty_loss = nn.Parameter(torch.tensor([args._3d_vis_loss_weight,
args._3d_prob_loss_weight,
args._3d_reg_loss_weight,
args._2d_vis_loss_weight,
args._2d_prob_loss_weight,
args._2d_reg_loss_weight,
args._seg_loss_weight]), requires_grad=True)
文章方法中一些变量对于性能的影响:
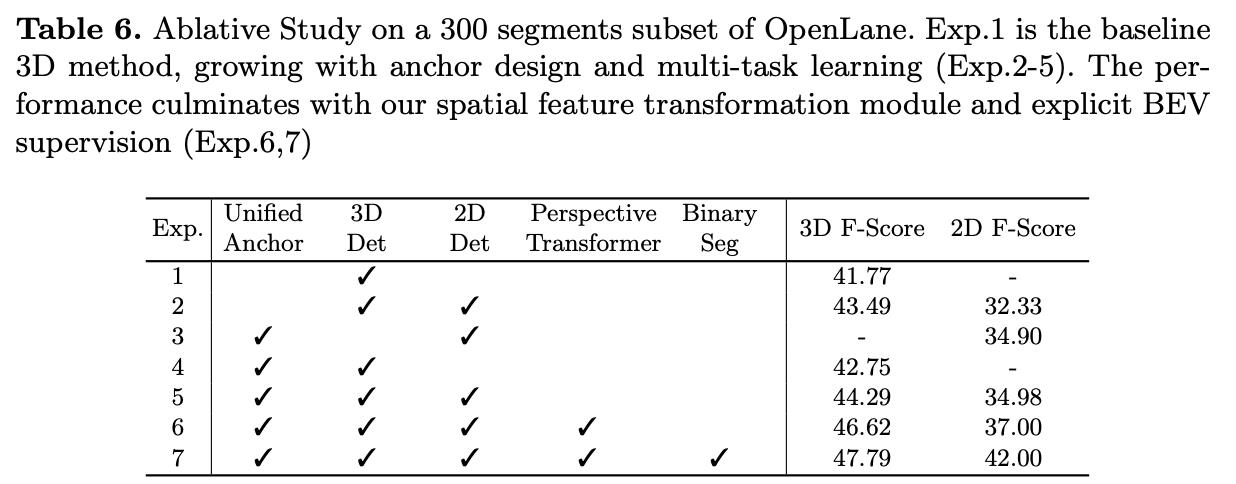
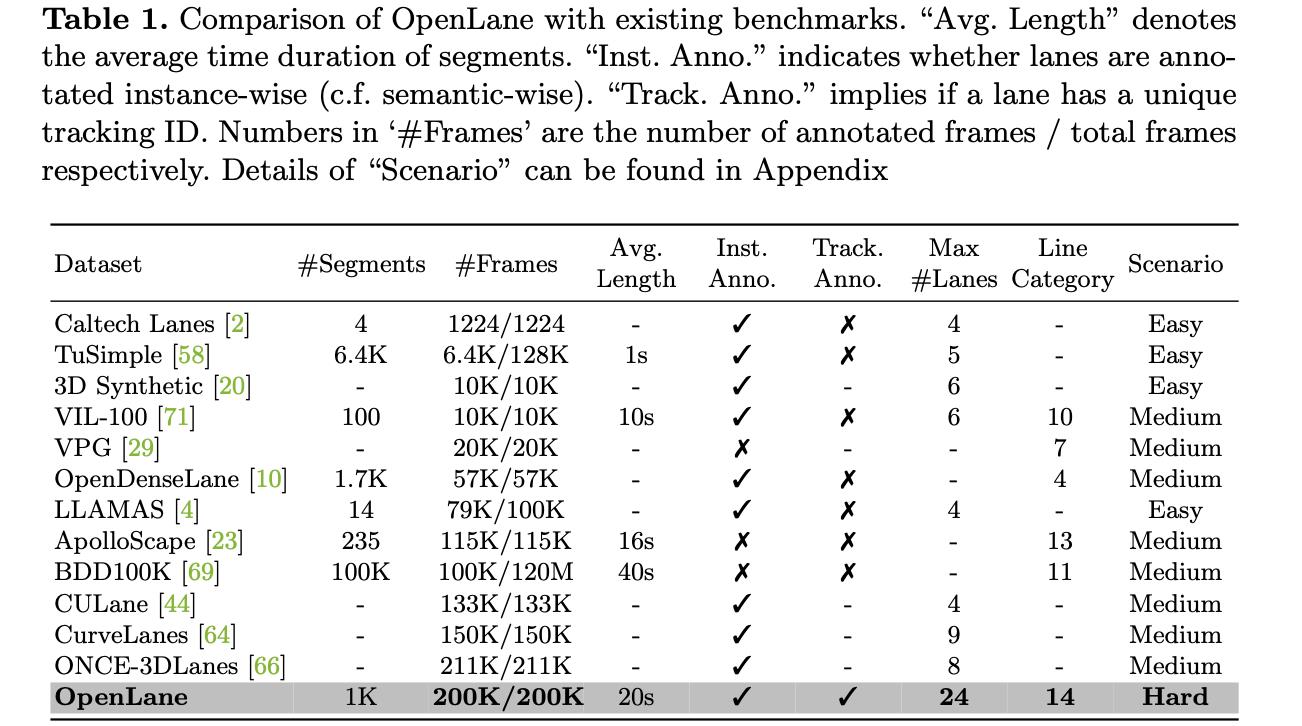
3. 实验结果
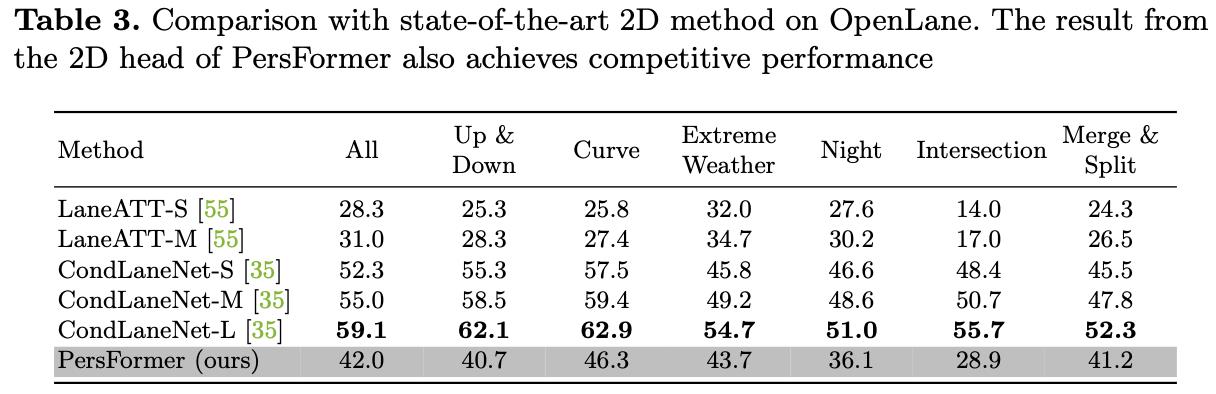
相比CondLaneNet这种更灵活的车道线建模方式,基于anchor的方案在2D下还是差距挺大
以上是关于《PersFormer:3D Lane Detection via Perspective Transformer and the OpenLane Benchmark》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章