Open ML
Posted 叹感
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Open ML相关的知识,希望对你有一定的参考价值。
目录
简介
传统的机器学习的前提假设是封闭环境场景,即学习过程中的重要因素保持不变,如:标签、样本空间(特征)、数据分布、模型评价指标等,基于此的很多理论发展相对成熟。然而,在机器学习的实际应用中,面对像水流一样的随着时间累积的数据(数据流),上述假设将不总是成立,OpenML的研究相继而生。
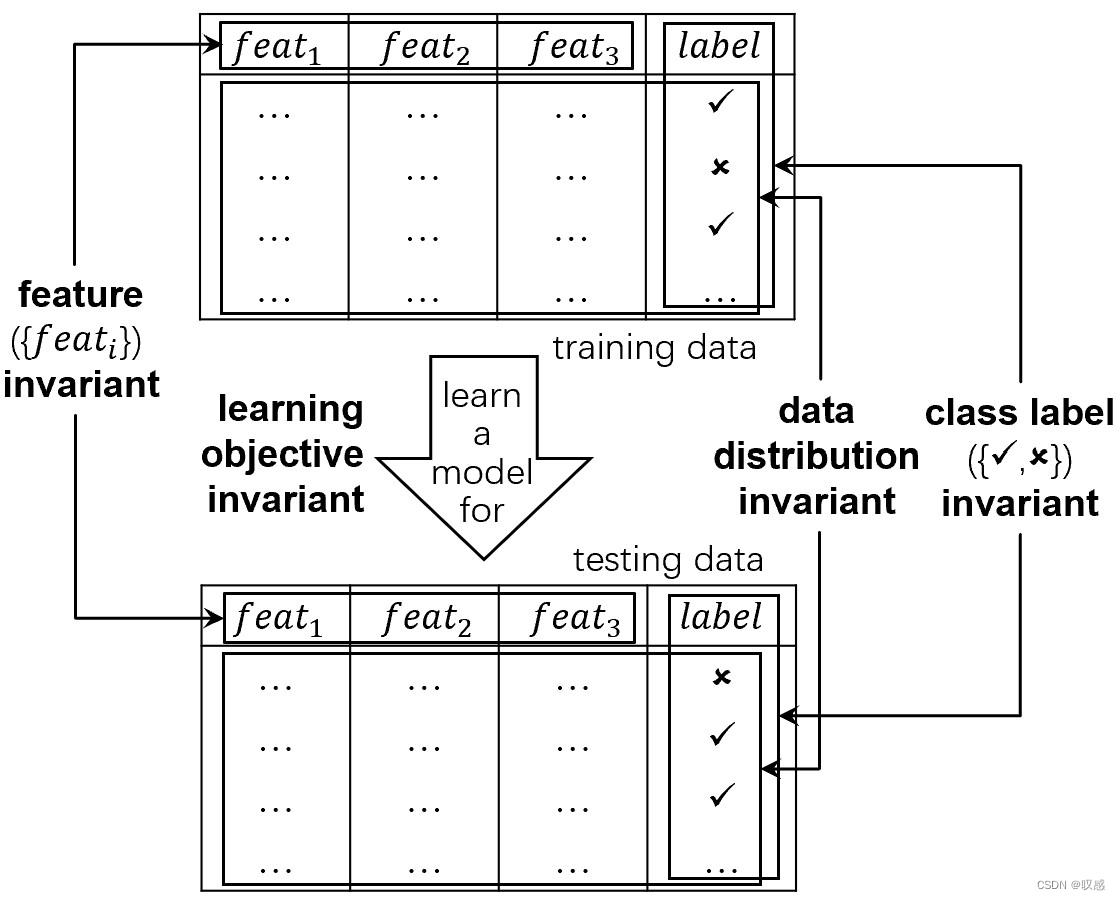
OpenML的核心关注点在于四个方面:新兴类别、递少/递增特征、变化的数据分布、不同的学习目标。
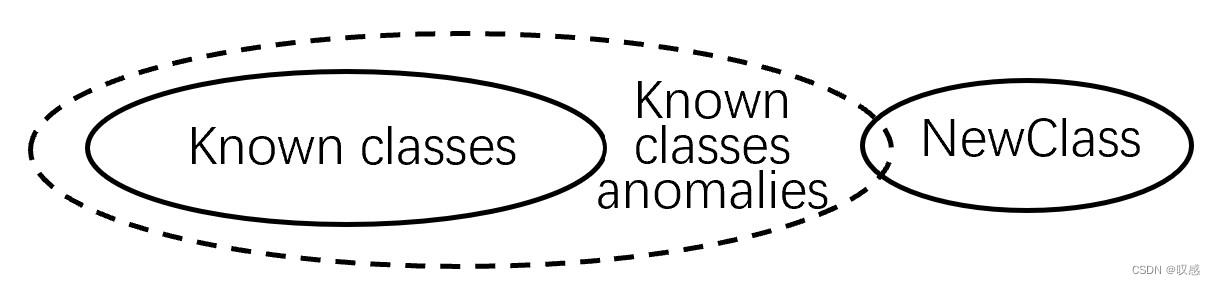
新兴类别:
传统有监督机器学习,对于任意实例 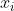 总会有
总会有 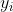 一直对应,而且 为已知的样本标签 。然而,随着时间累积的数据可能出现未知类别,例如:对于森林病虫害问题,一方面,我们无法将所有害虫进行标记;另一方面,害虫有可能是某时刻以物种入侵的方式出现的,对于新型物种,原传统机器学习模型已无法进行准确的预报。这就需要OpenML了。
一直对应,而且 为已知的样本标签 。然而,随着时间累积的数据可能出现未知类别,例如:对于森林病虫害问题,一方面,我们无法将所有害虫进行标记;另一方面,害虫有可能是某时刻以物种入侵的方式出现的,对于新型物种,原传统机器学习模型已无法进行准确的预报。这就需要OpenML了。
严格上,如果所有数据在手,我们可以通过两种方式得到新类,1、寻找已有类的分界线,未落在已知类的数据即为新类;2、得到所有已知类的分布,新类即为新分布。但对于数据流来说,上述方式不太适用。
用初始数据训练模型,理论上对于已有类别将有较好的预测精度,那么对于新兴类别实例,该模型即可预报出现了新类,并在“人”的参与下创建新标签。显然,这里描述了一个无监督/监督混合的人类在循环任务。
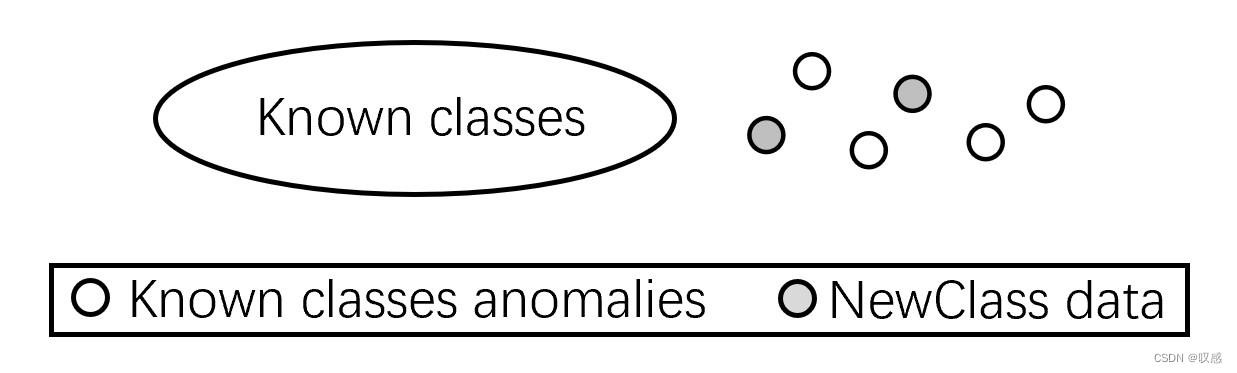
新兴类别的学习实质上与类别型增量学习有关,在这方面的研究较少,而且往往假设新增的类别是已知的。有新兴类别的学习的一种解决方式是:第一步找到新类并标识,第二步更新模型。
对于第一步,实质上是新类别实例与异常数据的区分,二者有两种存在关系,混淆或分离,对于混淆的情形,可通过核映射的方式转换。
对于第二步,更新模型适应新类的前提是不降低已知类别的预测性能,同时应避免灾难性的运算和高成本的数据储存。我们想要的情况是只为新类局部更新,一种方式是利用树模型,更新枝叶。另一种方式为基于全局和局部的草图方法。
值得注意的是,发现新类的时刻和更新模型的时刻可能存在一个间隔,为减小这个间隔,一个相关的讨论是检查哪些已知类与新类密切相关,并且开发了一种关于从新类映射到已知类映射的评估方法。
当然,还有其他需要注意的情况,如由于特征空间较小,新兴类别可能被误认为是已知类别。
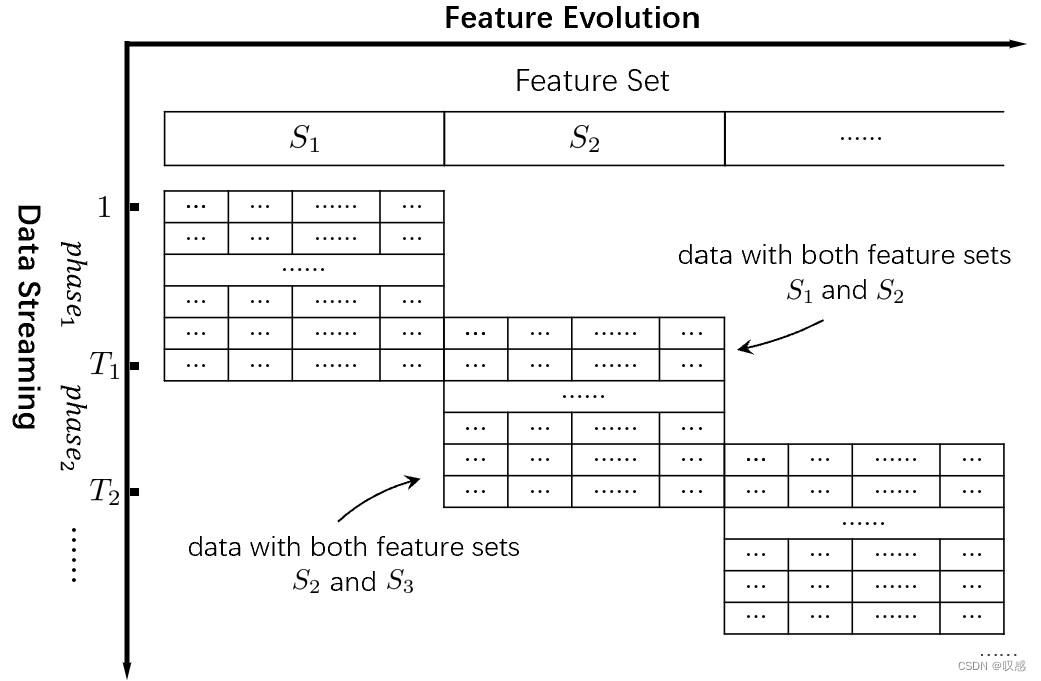
递减、递增特征:
一个很有意思的说明:检测森林疾病的传感器电量有限,旧一批服役的与新一批使用的传感器服役时采集的特征交集存在三种关系:不相交、相交、重合(那就没意思了)。
对于特征交集不为空的两批数据可通过下式进行新样本的预测。什么意思呢?在第一阶段采集的数据,我用全部特征进行模型的训练与预测(模型1),同时再训练一个模型(仅使用共有特征)进行预测(模型2),并且要满足二者的损失和二者预测结果的偏差之和最小,相当于是将第一时期才记得样本特征空间压缩到了共存的特征空间中。当然,这里也进行了正则化,防止w过分增大。这样能够保证预测第二个时期的实例时,可以结合用共有特征已经得到的模型2和用新数据训练的模型3一起预测,使模型1不浪费。
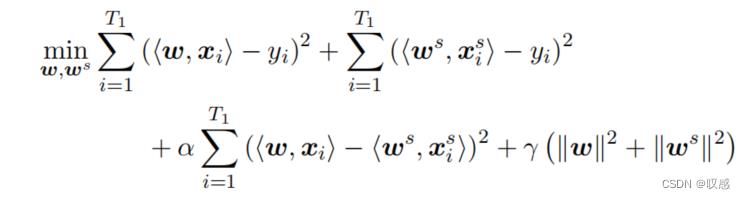
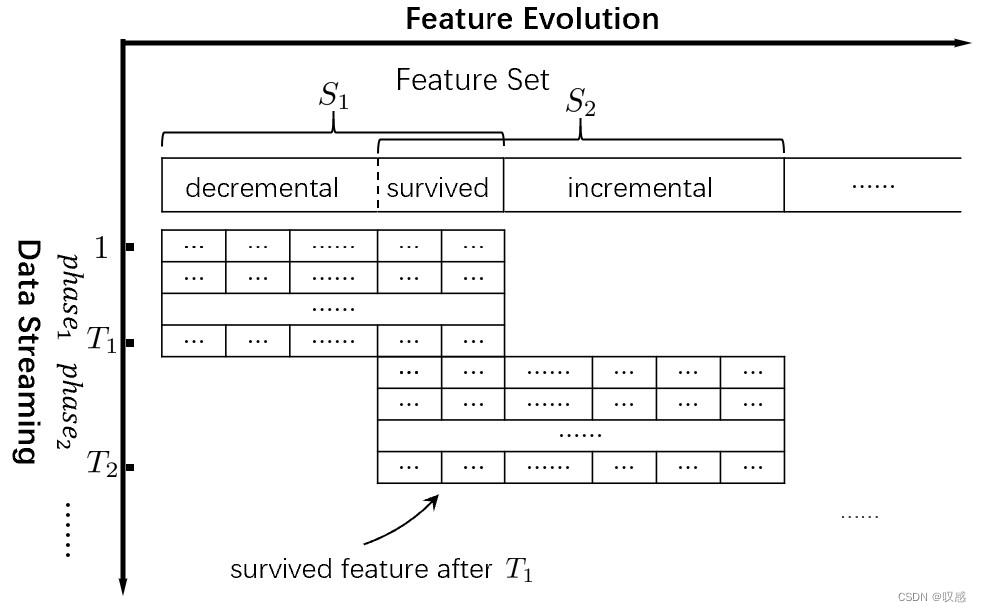
对于交集为空的情况,需要分两种情况讨论:
如果服役时间无交集,那之前的模型就算是废了,新模型必须使用新数据重新训练。
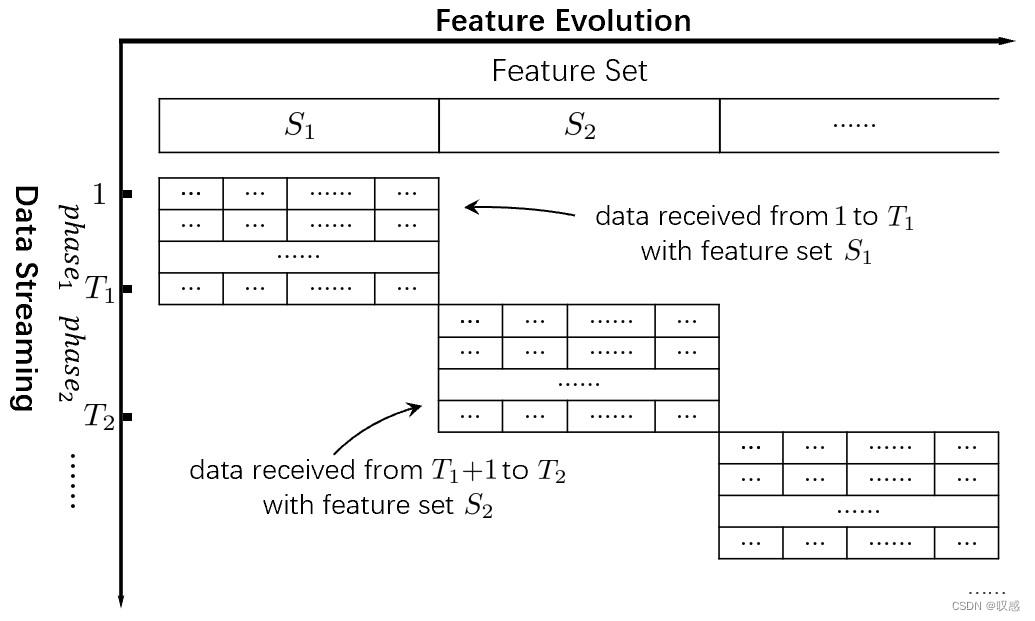
如果服役时间有交集,我们可以寻找某种映射,将第二个阶段的样本空间映射到第一个阶段,这样对于新的样本来说,可以利用原模型和新模型集成的进行相关预测。
变化的数据分布:
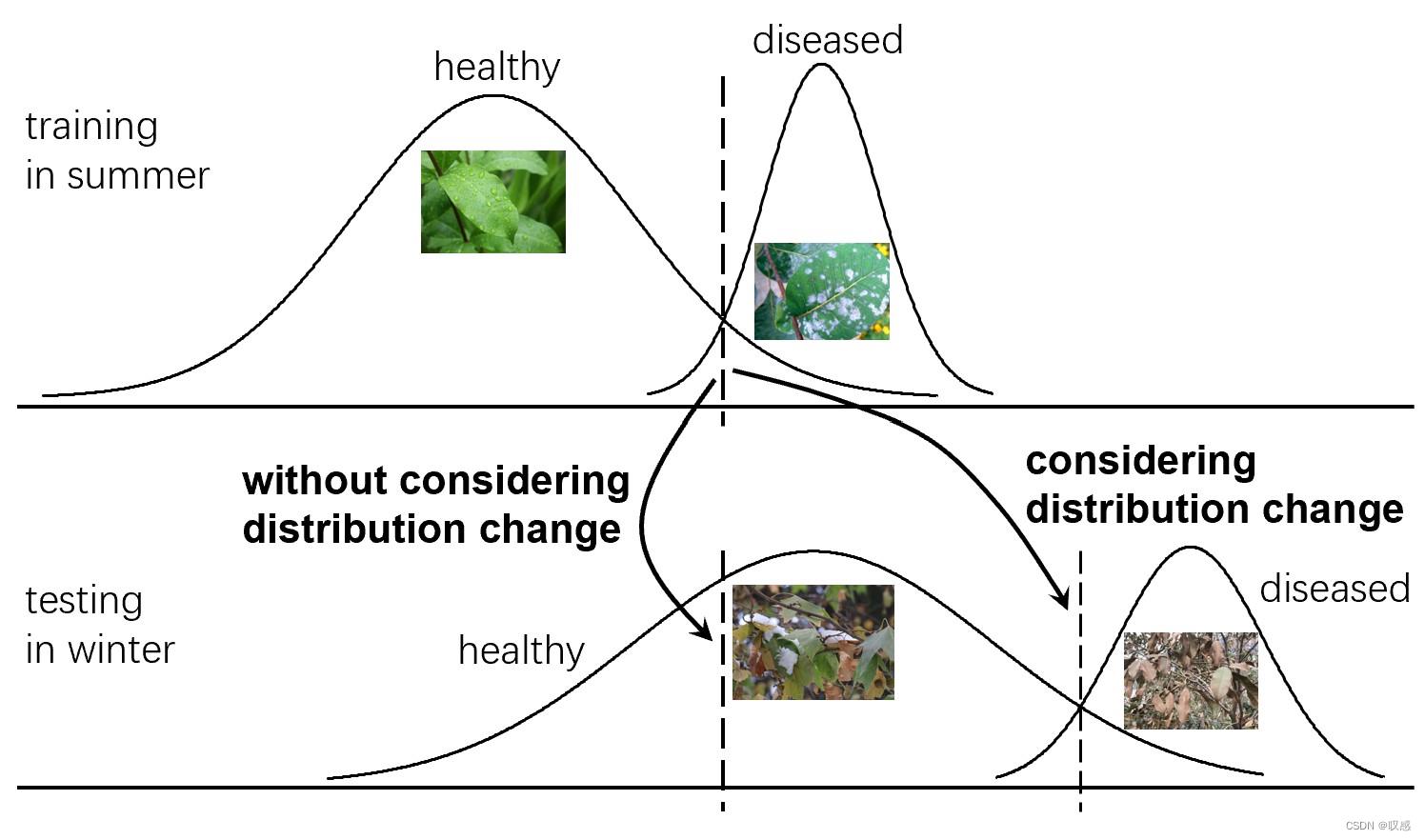
这要看数据分布变化能否被拿捏了,如果随意的、无时无刻肆无忌惮的变化,那不好意思,没办法了。通常,我们认为当前观测的数据与最近观测的数据市有关的,时间间隔越远越不相似。有三种解决方式:滑动窗、遗忘学习(对每个实例赋予权重,离得远的实例权重越小)、集成机制。大多数基于滑动窗口或集成的方法需要多次扫描数据。最近,人们提出了一种简单而有效的基于遗忘机制的方法来解决这一问题。该方法不需要关于更改的先验知识,并且每个实例在扫描后都可以被丢弃。
不同的学习目标
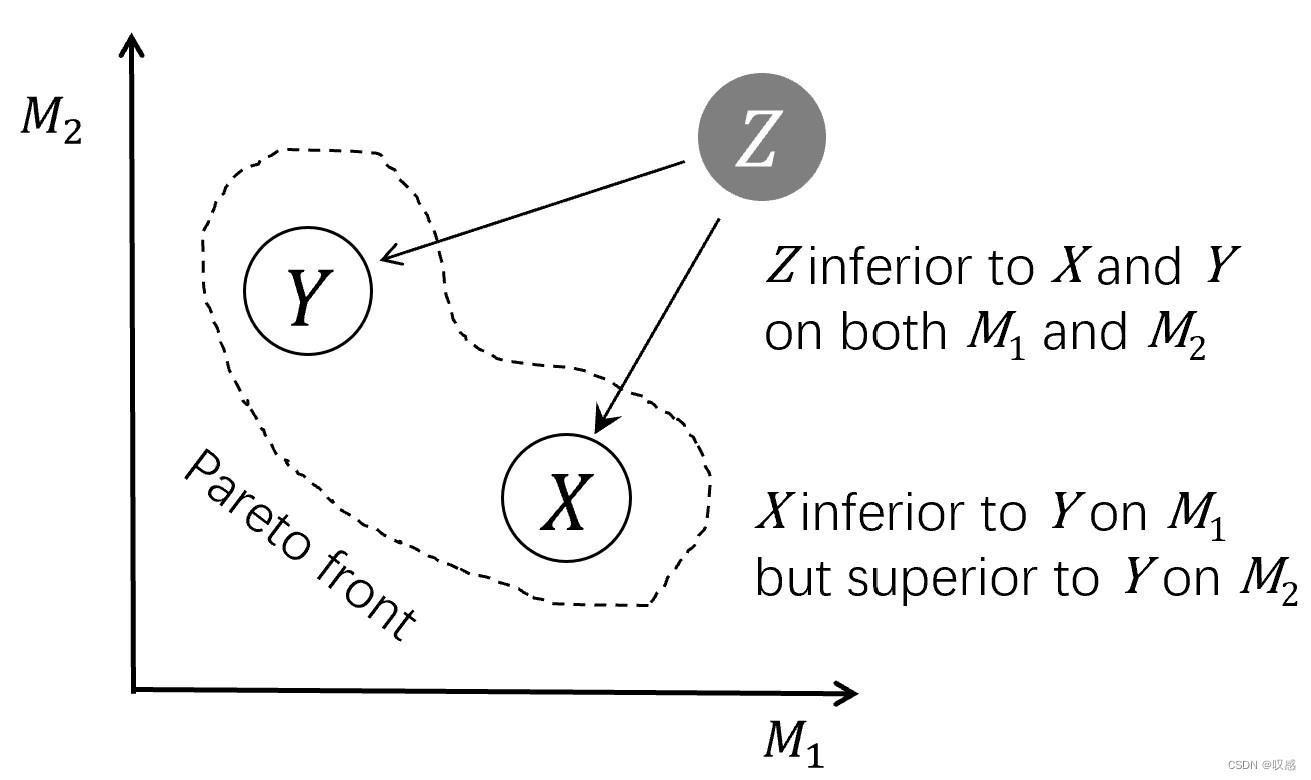
评价模型好坏的指标很多,根据不同的指标学习得到的模型也不一样。可以证明的是,在所有评价指标上表现都是最优的单一模型是不存在的,另外,一个模型很难从一个评价指标自然地切换到另一个指标。这里提出pareto优化,目标是找到pareto前沿:属于pareto前沿的模型在各个指标上的表现总有至少一个是最优的。 遗传算法是pareto优化的一种实现方式。
除了显示的评价指标外,其实还有一些隐式指标,如:我觉得这个模型比那个模型好。但我们是可以想方设法的找到与之对应的显式指标去替代隐式指标的。
论文的最后讲了很多关于OpenML的理论研究现状,总结就是理论不成熟,后辈需努力。值得关注的是,对于OpenML,拖尾问题需引起注意:
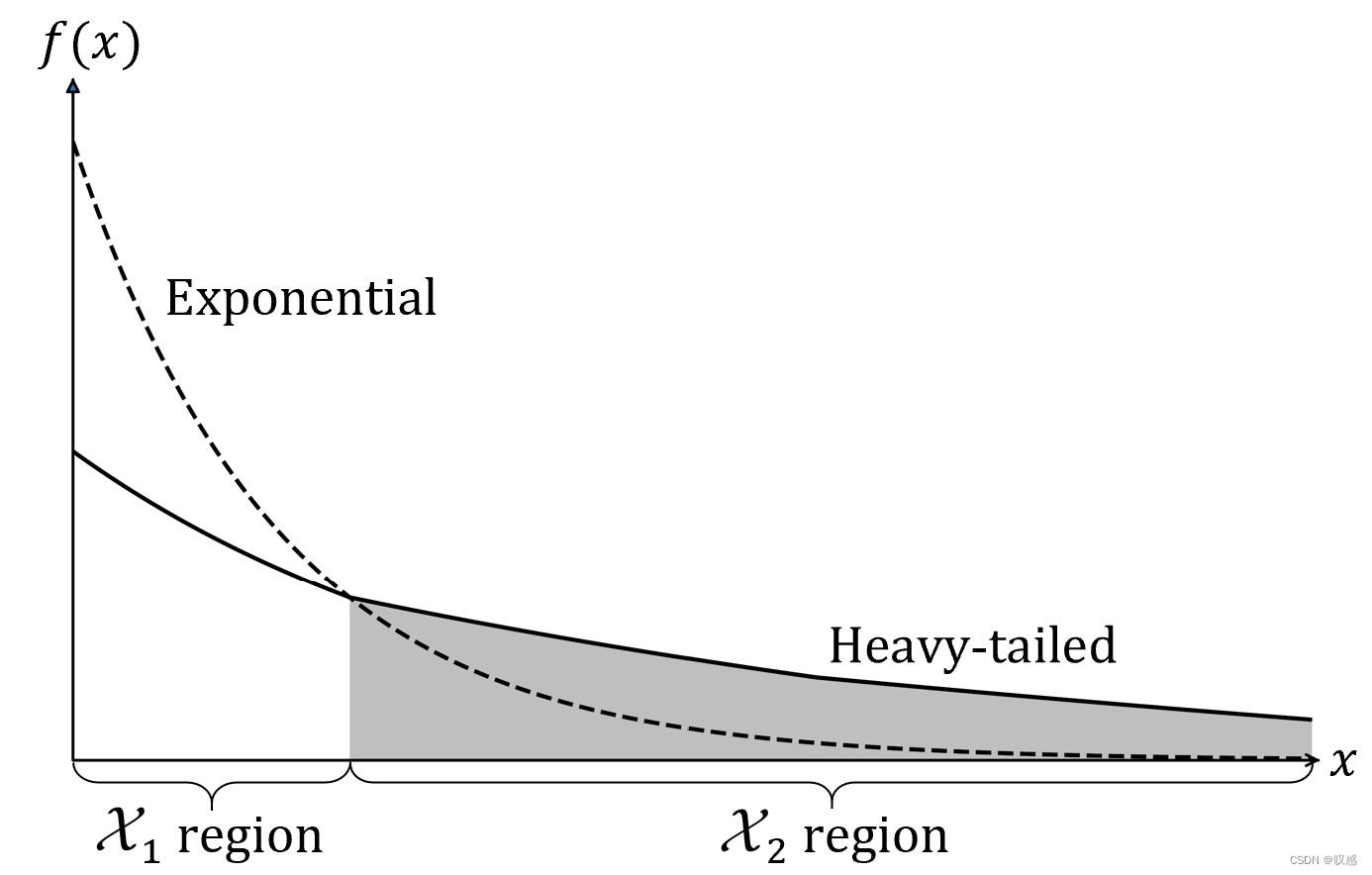
这里的拖尾不是正态分布的指数逼近,他被称为重尾或超重(肥胖)尾。对于OpenML需要满足在拖尾的小样本上能有较好的性能,同时要保证在绝大多数样本上性能也要很好,可以用下式表示:
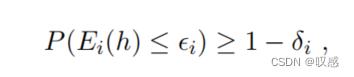
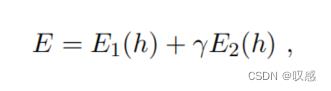
给定想要的“误差指标”,我需要训练出一个模型 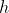 满足模型在区域1和区域2的误差小于误差指标的概率尽可能大,同时二者的误差值和要尽可能小。当然,也可以理解成,拖尾是对绝大多数样本的正则化项。
满足模型在区域1和区域2的误差小于误差指标的概率尽可能大,同时二者的误差值和要尽可能小。当然,也可以理解成,拖尾是对绝大多数样本的正则化项。
总结:
OpenML的意义是什么呢?是保证无论发生什么意外的不幸问题,机器学习模型在通常情况下都能实现优异的、令人满意的性能。
以上是关于Open ML的主要内容,如果未能解决你的问题,请参考以下文章