云原生&k8s的架构及基本组件原理
Posted highly2009
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生&k8s的架构及基本组件原理相关的知识,希望对你有一定的参考价值。
1.iaas 基础设施即服务
公司:服务器购买、建设机房、dns路由器、硬件、存储...--抽象成服务提供给公司(用户)使用
2.paas 平台即服务
在iaas层上进行了更高级层次抽象,iaas提供硬件服务,paas提供基础软件服务
3.saas 软件即服务
钉钉,企业微信
云原生:
架构:软件开发思想(软件架构思想)
应用:就是为了让应用程序(项目、mysql、elasticsearch...)都运行在云上容器中,这样的技术就叫做云原生
特点:
1.容器化:容器项目部署,起到了隔离的作用
2.微服务:实现原生最好采用微服务架构,微服务按照function拆分后,可以做到高内聚,低耦合,实现CI/CD
3.devops
开发+运维-开发运维的结合体。Devops是一种敏捷思维,开发一种组织形式
4.CI/CD
持续交付:不停机更新
云扩展思维:
caas container as a service
faas function as a service 函数即服务
service mesh 服务网格架构 服务治理-服务限流-服务降级-服务监控 istio
serverless 无服务架构,是指程序员开发不需要关系服务器的事情,只需要开发业务代码即可
如何云原生?
本地部署应用可能需要停机更新,而云原生就不需要,始终是最新的状态,支持频繁的变更
本地部署应用无法进行动态扩展(动态伸缩容),云原生可以利用云资源的弹性进行自动伸缩容,从而为企业降本增效
本地部署应用对物理硬件ip,网络端口有强依赖,云原生就不需要了
本地部署需要人肉运维,云原生实现自动化运维
容器编排技术:
为什么要管理容器(虚拟机)?
怎么扩容?(自动)
容器宕机了,怎么恢复?(自动)
更新容器会不会影响业务?(不影响)
如何监控?(自动)
如何调度?(自动)
数据安全(自动)
2.容器编排技术
2.1 docker-compose
docker-compose组件可以批量的创建容器,管理容器,粗颗粒度
2.2 swarm
swarm容器编排工具是docker公司自己的开发,但是docker公司自己都不使用,docker使用的kubernetes:kubernetes采用pod和label这样的概念把容器组合成一个个互相存在依赖关系的逻辑单元,相关容器被组合成pod后被共同部署和调度,形成服务。
kubernetes基本结构:
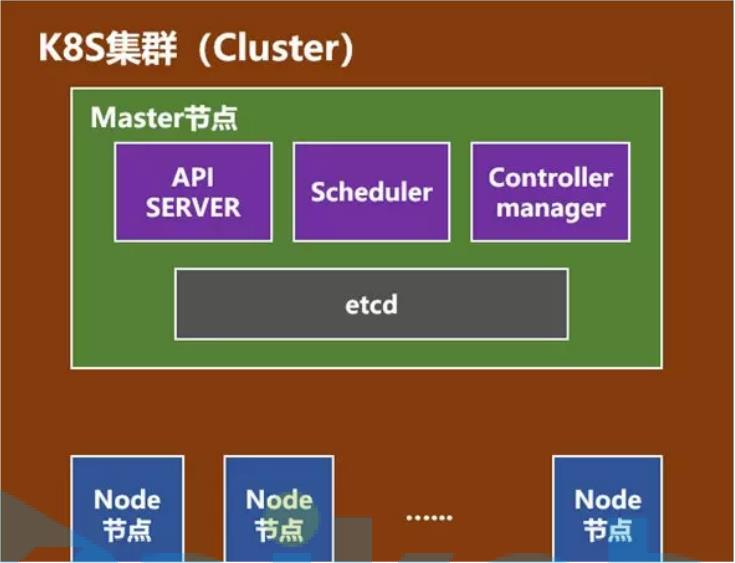
1.master节点 :负责调度,存储集群状态(服务注册发现),提供统一api入口,一个master对应一群node节点
2.node节点:node节点存储pod(pod内部封装容器),一个node节点理论上可以存储无数个pod,但是node节点存储pod的数量受限于硬件资源的限制,同时受限于内部服务器运行所占用的资源
3.kubernetes
borg系统。kubernetes也是google公司开发的,架构设计思想是参考borg系统来架构设计的
发送请求:kubectl 客户端指令,浏览器(可视化方式 rancher,dashboard)
master节点 :schedule调度器,负责计算该把pod调度到哪一个node节点
contollers: 控制器,负责维护node节点资源对象
apiServer:网关,所有请求都必须要经过网关
etcd 服务发现,注册。集群状态信息,调度信息
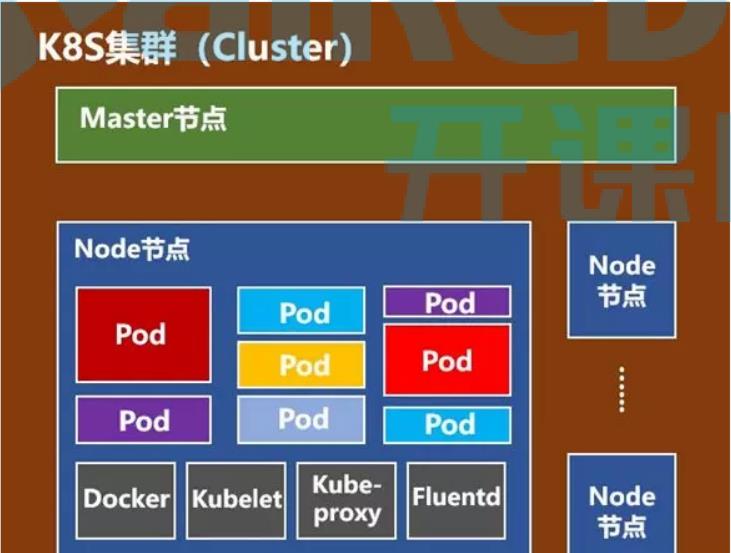
node节点 每一个node节点都运行一个kubelet进程,此进程负责本机服务的pod创建
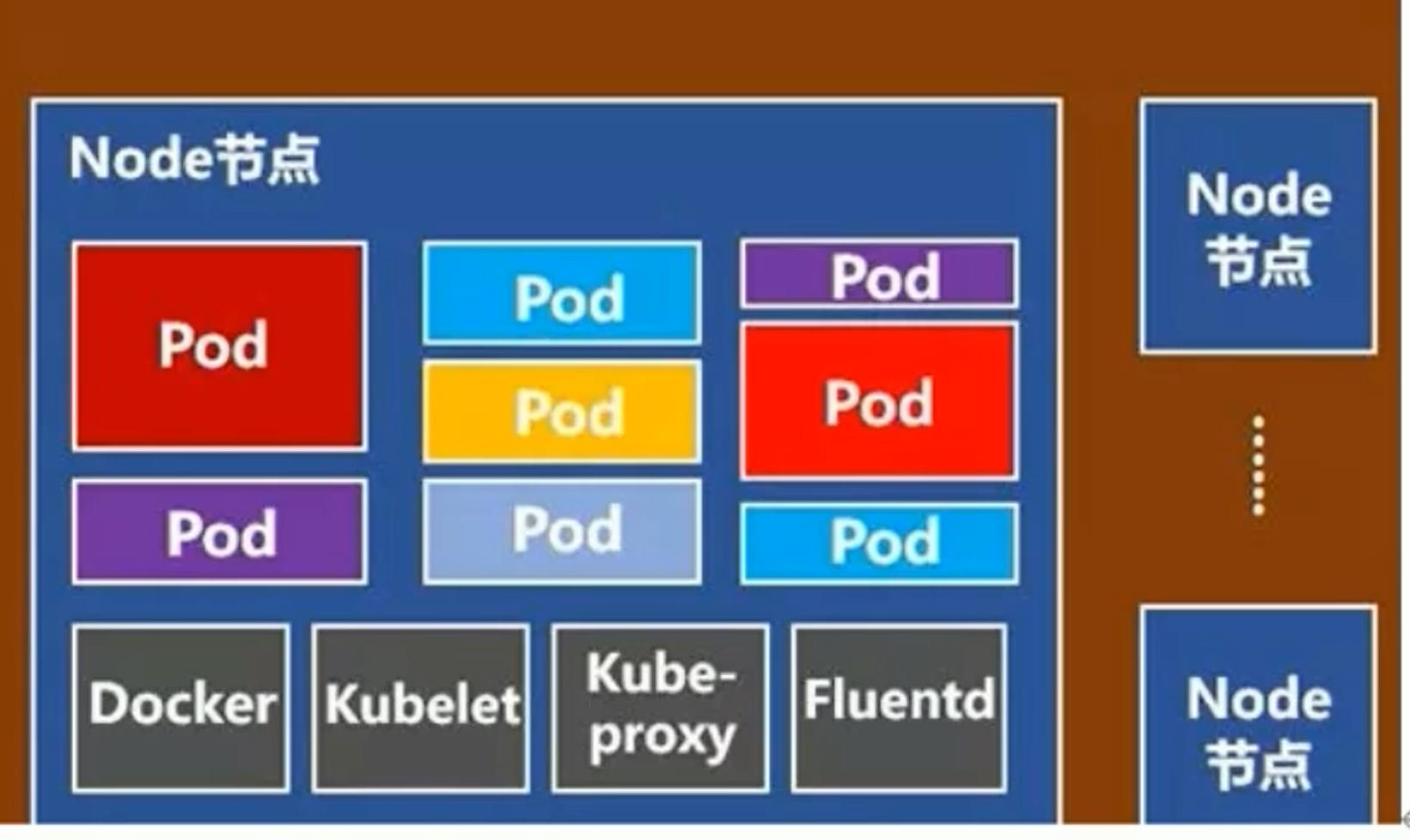
pod是k8s管理的最小基本单元,pod内部可以运行一个或多个容器,一般情况下,pod内部只允许一个容器运行,便于管理
docker:docker引擎,pod内部运行的都是容器,这个容器是由docker引擎创建的,docker引擎是node节点基础服务
kubelet:node节点代理,kubelet代理master节点请求,在本地node节点执行
kube-proxy:网络代理,主要用来生成网络规则,创建访问路由,创建service网络访问规则,负责均衡规则
fluentd:日志,日志收集
master节点
apiserver:集群的统一入口,各组件协调者,以http api 提供接口服务,所有对象资源的增删改查和监听操作都交给apiserver处理后再提交给etcd存储
manager controller:
replication controller:副本控制器
service cotroller:管理维护service(虚拟ip),提供负载以及服务代理
endpoints controller: 管理维护endpoints,关联service和pod
persistent volumn controller: 持久化数据卷控制器
daemon set controller:让每一个node节点都运行相同的服务
deployment controller:无状态部署服务
4.scheduler
创建pod的流程:
1.kubctl发送创建pod的指令,此时这个指令被apiserver拦截,把创建的pod存储在etcd
2.scheduler发起调用请求,此时这个指令被spiserver拦截,获取etcd中的podQueue NodeList
调度算法:预选调度,优选策略
3.把选择合适的node、pod存储在etcd
4.node节点上有一个kubelet进程,发送请求获取pod,node对应创建资源
5.
云架构及其基本组件
1.云原生技术
- 何为云原生?
云原生技术: 以k8s和为核心的一套云原生架构体系叫做云原生技术; 软件的架构设计遵循kubernetes软件架构设计思想,云原生架构;
云原生:
1)架构思想:软件架构开发思想
2)应用: 让开发的软件或者服务(MySQL,es,mq,nacos………)都必须运行在容器中,容器编排技术使用kubernetes;这样的架构就叫做云原生架构- 云原生特点:
1)容器化 : 所有的应用都必须部署在容器中
2)微服务 : 按照function拆分,拆分的很细致;适合在容器中运行,实现云原生架构模式;
3)DevOps : 开发+运维结合体,DevOps是一种敏捷开发的思想,一种组织形式,实现项目流水线生产模式;
4)CI/CD : 可持续集成,可持续部署CNCF(云原生组织)对云原生定义扩展:
ServiceMesh 服务网格架构(ServiceMesh + Istio) ------------ 云原生架构
2.云原生架构理念
* iaas 【Infrastructure as a service 基础设施即服务】
# 用户:购买服务器,建设机房,DNS,交换机,路由,网络... (硬件环境)
# 云计算提供商:提供 网络、存储、dns、服务器..服务,用户只需要租用云主机即可,不需要关系硬件建设。
# 网络、存储、dns、服务器,操作系统 这样服务就叫做基础设施即服务。
思考: 用户购买一台iaas服务? 就相当于买了一台空的服务器。
* paas 【platform as a service】
# 在iaas基础上安装一些软件:基础服务软件---MYSQL,RocketMQ,ElasticSearch...作为基础服务
思考:用户购买这样的服务后,此时用户只需要关系项目业务代码开发,基础软件服务不需要自己安安装。
* caas 【container as a service】
# 容器就是一个服务。软件,服务都运行在容器中。
* saas 【software as a service】
# OA(多租户)
# 钉钉 (多租户)
# 财务 (多租户)
* faas 【function as a service】,baas 【backend as a service】
# 视频服务提供商(直播)---- 函数收费 (函数运行,收费)
# CDN服务商 (视频缓存服务)---- 函数收费
# 短信服务 --- 发一条短信
# 支付服务 --- 函数收费
* service mesh
# 客户端 --> proxy代理服务--> 服务(集群)
# 客户端+proxy(集成在一起:服务治理--降级,限流、监控..)--> 服务+proxy(集成在一起:服务治理--降级,限流、监控..)(集群)
注意:
# 一般企业直接使用 proxy代理模式就ok,至于服务治理:springcloud
# service mesh 不建议使用,落地非常困难,中小型企业玩不起,技术能力
* serverless
# server 服务器,less 无 ---> 无服务器
# 未来开发境界:程序员只需要关心代码业务开发即可,服务器环境不需要关心,所有的服务都上云。
# 未来:
公有云: 阿里云,腾讯云、网易云,百度云,滴滴云...
私有云: k8s 自己公司构建自己的私有云 ------ 很多公司在使用私有云
3.容器编排
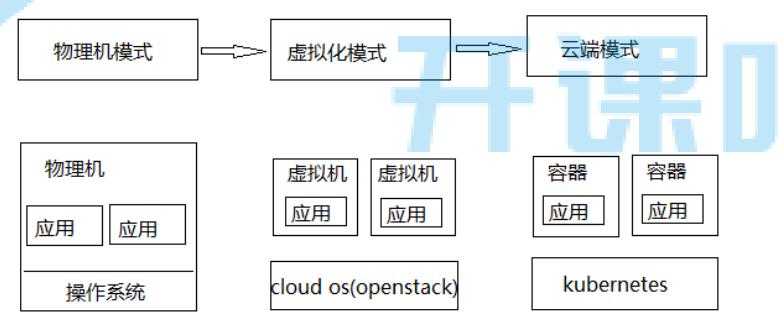
1)应用部署变迁
* 物理机
操作系统
* 虚拟机
OpenStack
* 云原生
kubernetes
思考:微服务架构,服务拆分成千上万个服务,就需要非常多的容器来进行部署,那么这些容器怎么管理?
怎么横向扩容?
服务宕机了,怎么恢复,你是如何知道的?
版本更新,上线,更新容器后,线上业务如何不受影响?
监控容器?
调度问题?
安全问题?
window系统:海量的文件,如何管理??
资源管理器(管理文件:调度)2)容器管理
* 解决问题
怎么横向扩容?
服务宕机了,怎么恢复,你是如何知道的?
版本更新,上线,更新容器后,线上业务如何不受影响?
监控容器?
调度问题?
安全问题?
以上问题,容器编排技术来说,一个指令,一个按钮就可以搞定一切。
* docker-compose
非常轻量级容器编排技术,可以通过yaml文件方式,对容器进行批量管理,不能实现复杂容器编排
* rancher
可视化的容器管理工具,v2版本提供对k8s兼容。中小型使用,性能非常差,不能实现复杂的容器编排。
* swarm
docker公司自己研发的容器编排技术,docker也在使用kubernetes.
* mesos
apache软件基金会提供开源的容器编排技术。
* borg
google研发一套容器编排技术,这套技术没有对外公开,强大,稳定。
* kubernetes
google研发一套容器编排技术,使用go开发。性能非常强大、稳定、通过指令、yaml编程方式管理容器,非常灵活。
4.kubernetes -- k8s 基本认识
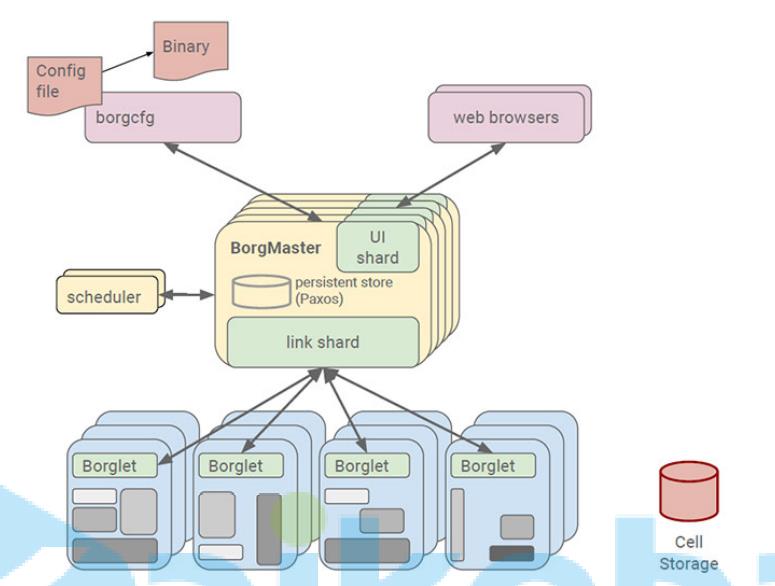
- borg系统
Borg. Google的Borg系统运行几十万个以上的任务,来自几千个不同的应用,跨多个集群,每个集群 (cell)有上万个机器。它通过管理控制、高效的任务包装、超售、和进程级别性能隔离实现了高利用 率。它支持高可用性应用程序与运行时功能,最大限度地减少故障恢复时间,减少相关故障概率的调度 策略。以下就是Borg的系统架构图。其中Scheduler负责任务的调度。- kubernetes
就在Docker容器技术被炒得热火朝天之时,大家发现,如果想要将Docker应用于具体的业务实现,是 存在困难的——编排、管理和调度等各个方面,都不容易。于是,人们迫切需要一套管理系统,对 Docker及容器进行更高级更灵活的管理。就在这个时候,K8S出现了。 *K8S*,就是基于容器的集群管理平台,它的全称,是kubernetes*- k8s主要功能
Kubernetes是docker容器用来编排和管理的工具,它是基于Docker构建一个容器的调度服务,提供资 源调度、均衡容灾、服务注册、动态扩缩容等功能套件。Kubernetes提供应用部署、维护、 扩展机制 等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下:
1)数据卷: Pod中容器之间共享数据,可以使用数据卷。
2)应用程序健康检查: 容器内服务可能进程堵塞无法处理请求,可以设置监控检查策略保证应用健壮性。
3)复制应用程序实例: 控制器维护着Pod副本数量,保证一个Pod或一组同类的Pod数量始终可用。
4)弹性伸缩: 根据设定的指标(CPU利用率)自动缩放Pod副本数。
5)服务发现: 使用环境变量或DNS服务插件保证容器中程序发现Pod入口访问地址。
6)负载均衡: 一组Pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部 其他Pod可通过这个ClusterIP访问应用
7)滚动更新: 更新服务不中断,一次更新一个Pod,而不是同时删除整个服务。
8)服务编排: 通过文件描述部署服务,使得应用程序部署变得更高效。
9)资源监控: Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDB时序数据库,再由Grafana展示。
10)提供认证和授权: 支持属性访问控制(ABAC)、角色访问控制(RBAC)认证授权策略。
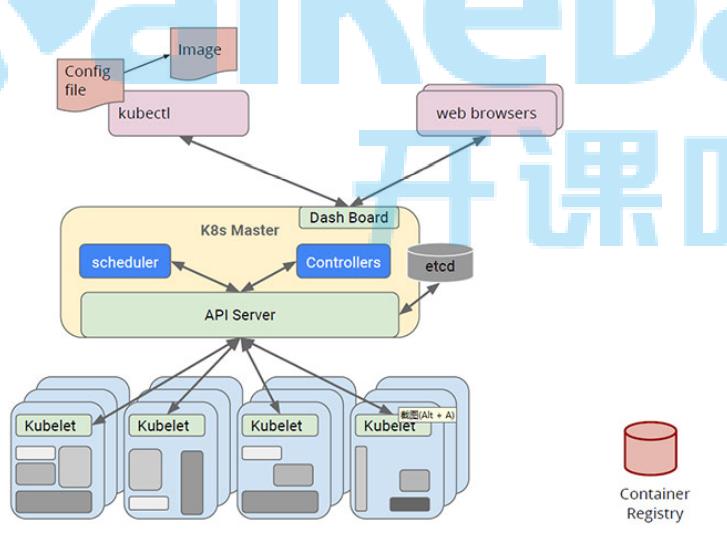
5.k8s 集群 -- 分布式架构(一个master-主节点,一群node节点-计算节点)
* master
* Api Server 网关 ,所有的请求指令都必须经过 ApiServer 转发
* scheduler 调度器,把请求指令(crud)调用到合适的node节点上。把调度请求发送给apiserver,apiserver将会把请求指令存储在etcd. node节点有kubelet监控etcd,
监控到本node节点的指令,就会获取指令,在node节点执行。
* controllers 控制器(十几个控制器),每一个控制器对应相应的资源,控制器对这些资源进行管理(curd)
* etcd nosql,存储一些指令,用来做服务注册与发现
* node节点
* pod 是k8s最小的管理单位,pod内部有一个或者多个容器,pod是一个用来封装容器的容器。
一个node节点可以多个pod,理论上是无限制的,取决于硬件环境。
* docker 容器引擎(程序),k8s管理容器,容器由docker进行创建,k8s底层必须有docker引擎。
* kubelet 监听etcd,获取指令管理pod,kubelet是真正管理pod的组件。
* kube-proxy 代理服务,主要用来做负载均衡。设置iptables负载规则,更新service虚拟endpoints
* fluentd 日志收集组件
* dns 域名解析服务器
6.controllers ---- 控制器
* replication controller : 副本控制器,控制副本数量与预期设定的数量保持一致。
* Node Controller : 检查node节点监控状况;由k8s本身内部实现的。
* namespce controller : 创建pod,会把pod分配在不同命名空间下,定期清理无效的namespace
* service controller : 虚拟服务控制器,维护虚拟ip,提供负载均衡。
* endpoints controller : 提供了pod,service关联服务。
* service Account controller : 安全认证
* persistent volume controller : 持久化存储控制器-有状态服务部署,数据持久化存储 PVC
* daemon set controller : 让每一个服务器都具有一个相同的服务,管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正 常的运行Daemon Pod
* deployment controller : 部署控制器,支持滚动更新,发版
* Job controller : 定时任务控制器
* pod autoscale controller : 自动更新控制器,cup利用率>=80% ,自动扩容。
7.etcd
etcd 是一个分布式的、可靠的 key-value 存储系统,它用于存储分布式系统中的关键数据,这个定义非 常重要。
etcd是一个第三方服务,分布式键值存储系统。用于保持集群状态,比如Pod、Service等对象信息 etcd是一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于 Go语言实现。Etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象 的状态信息。整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置,分别是: 1)网络插件flannel、对于其它网络插件也需要用到etcd存储网络的配置信息 2)kubernetes本身,包括各种对象的状态和元信息配置
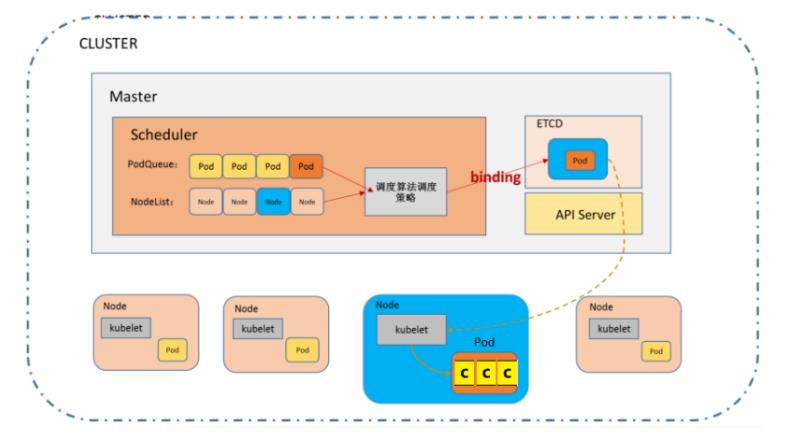
8.scheduler调度器
根据调度算法为新创建的Pod选择一个Node节点。 scheduler在整个系统中承担了承上启下的重要功 能,承上是指它负责接收controller manager创建新的Pod,为其安排一个落脚的目标Node,启下是指 安置工作完成后,目标Node上的kubelet服务进程接管后继工作。
也就是说scheduler的作用是通过调度算法为待调度Pod列表上的每一个Pod从Node列表中选择一个最 合适的Node。
* podQueue (即将要创建的pod进行排队)
* nodeList (存储pod的节点的集合)
* scheduler通过调度策略算法把pod 和 某一个node进行配对,存储在etcd,node节点kubelet监控到数据,把pod获取到在本地创建pod.
* 调度算法
* 预选调度
判断pod是否存在冲突
pod名称是否重复
* 最优节点
cpu利用率最小的节点
9.kubelet
kubelet是Master在Node节点上的Agent(代理),每个节点都会启动 kubelet进程,用来处理 Master 节点下 发到本节点的任务,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、 下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
kubelet 是 k8s 在node节点上的代理服务。pod的CRUD的是有node节点上kubelet来进行操作。kubelet实际上就相当于链式调用,上游服务是master(scheduler,apiserver),有node记得kubelet接受请求,执行具体操作。
1)kubelet 默认监听四个端口,分别为 10250 、10255、10248、4194
- 10250(kubelet API):kubelet server 与 apiserver 通信的端口,定期请求 apiserver 获取自己 所应当处理的任务,通过该端口可以访问获取 node 资源以及状态。
- 10248(健康检查端口):通过访问该端口可以判断 kubelet 是否正常工作, 通过 kubelet 的启动 参数 --healthz-port 和 --healthz-bind-address 来指定监听的地址和端口。
- 4194(cAdvisor 监听):kublet 通过该端口可以获取到该节点的环境信息以及 node 上运行的容 器状态等内容,访问 http://localhost:4194 可以看到 cAdvisor 的管理界面,通过 kubelet 的启动参 数 --cadvisor-port 可以指定启动的端口。
- 10255 (readonly API):提供了 pod 和 node 的信息,接口以只读形式暴露出去,访问该端口 不需要认证和鉴权。

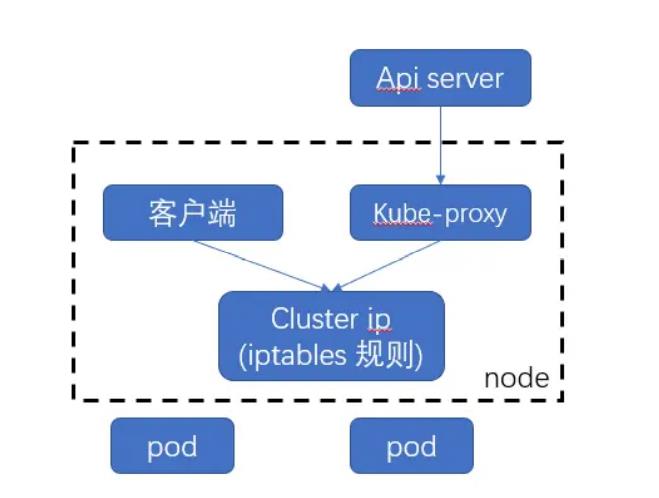
10.kube-proxy
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作,kube-proxy 本质上,类似一个反 向代理. 我们可以把每个节点上运行的 kube-proxy 看作 service 的透明代理兼LB.
kube-proxy 监听 apiserver 中service 与Endpoint 的信息, 配置iptables 规则,请求通过iptables 直接转 发给 pod
kube-proxy 反向代理,但是kube-proxy不执行具体的代理任务,设置iptables/ipvs路由规则,serviceVIP & iptables来实现的路由规则
以上是关于云原生&k8s的架构及基本组件原理的主要内容,如果未能解决你的问题,请参考以下文章