一Kubernetes详解-k8s概念和名词解释理解。包括组件架构资源管理kubectl命令
Posted 北漂IT民工_程序员_ZG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一Kubernetes详解-k8s概念和名词解释理解。包括组件架构资源管理kubectl命令相关的知识,希望对你有一定的参考价值。
Kubernetes详解-对k8s里面概念和名词的解释理解
一、k8s简介
1、k8s是什么?
Kubernetes(k8s)是Google开源的容器集群管理系统。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。
Kubernetes所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。
所以说,Kubernetes的本质,是为用户提供一个具有普遍意义的容器编排工具。
什么是容器编排呢?简单举例介绍下,比如说我们有两个容器,一个容器部署mysql,另一个部署应用系统。启动时,必须要先启动mysql(因为应用系统要连接mysql),后启动应用系统, 如果我们忘记起了mysql,就会导致应用系统起不来,两个容器还好说,如果是10来个容器呢,运维人员好记着每个容器的启动顺序,那就太麻烦了,使用k8s就可以避免这个问题。
容器编排不止只有起容器的先后顺序这么简单,还包括容器的弹性伸缩、网络管理等都自动化处理。
2、k8s主要功能
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器。
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整。
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务。
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡。
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本。
- 存储编排:可以根据容器自身的需求自动创建存储卷。
3、k8s组件
一个kubernetes集群主要是由控制节点(master)、工作节点(node) 构成,每个节点上都会安装不同的组件。
1、master(集群的控制平面,负责集群的决策 ( 管理 ))
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制。
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上。
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等。
Etcd : 负责存储集群中各种资源对象的信息。
2、node(集群的数据平面,负责为容器提供运行环境 ( 干活 ))
Kubelet : 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器。
KubeProxy : 负责提供集群内部的服务发现和负载均衡。
Docker : 负责节点上容器的各种操作。
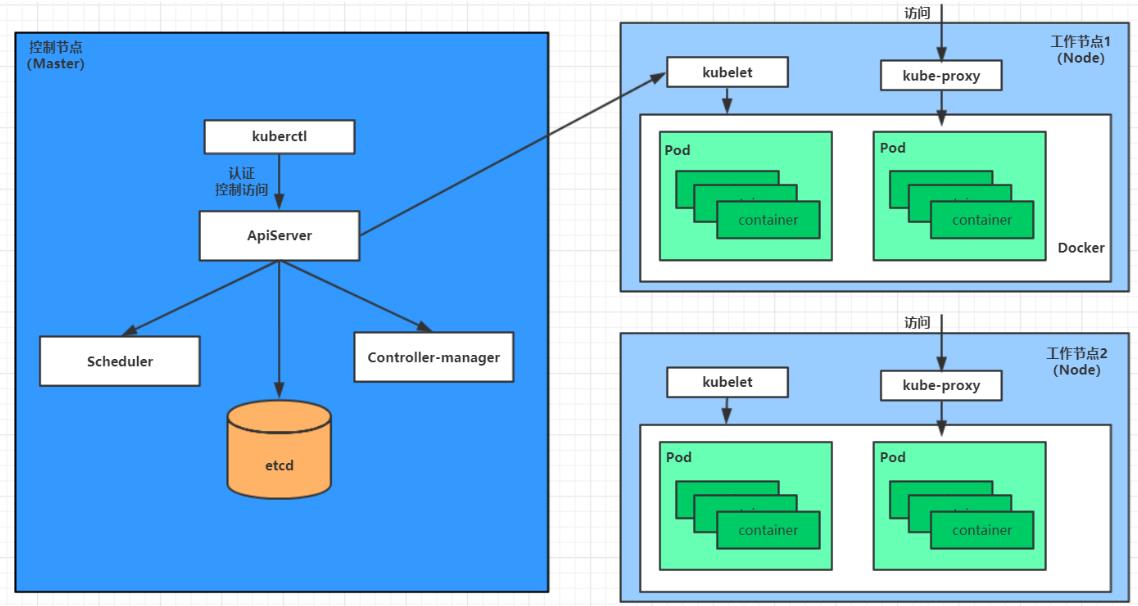
下面,以部署一个nginx服务来说明kubernetes系统各个组件调用关系:
1、首先要明确,一旦kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中。
2、一个nginx服务的安装请求会首先被发送到master节点的apiServer组件。
3、apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上,在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告apiServer。
4、apiServer调用controller-manager去调度Node节点安装nginx服务。
5、kubelet接收到指令后,会通知docker,然后由docker来启动一个nginx的pod,pod是kubernetes的最小操作单元,容器必须跑在pod中。
6、一个nginx服务就运行了,如果需要访问nginx,就需要通过kube-proxy来对pod产生访问的代理
4、k8s概念
Master: 集群控制节点,每个集群需要至少一个master节点负责集群的管控。
Node: 工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的docker负责容器的运行。
Pod: kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器。
Controller: 控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等。
Service: pod对外服务的统一入口,下面可以维护者同一类的多个pod。
Label: 标签,用于对pod进行分类,同一类pod会拥有相同的标签。
NameSpace: 命名空间,用来隔离pod的运行环境。
5、资源管理
1、资源管理介绍
在kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理kubernetes。
kubernetes的本质上就是一个集群系统,用户可以在集群中部署各种服务,所谓的部署服务,其实就是在kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中。
kubernetes的最小管理单元是pod而不是容器,所以只能将容器放在Pod中,而kubernetes一般也不会直接管理Pod,而是通过Pod控制器来管理Pod的。
Pod可以提供服务之后,就要考虑如何访问Pod中服务,kubernetes提供了Service资源实现这个功能。
当然,如果Pod中程序的数据需要持久化,kubernetes还提供了各种存储系统。
学习kubernetes的核心,就是学习如何对集群上的Pod、Pod控制器、Service、存储等各种资源进行操作。
2、资源管理方式
1、命令式对象管理: 直接使用命令去操作kubernetes资源
kubectl run nginx-pod --image=nginx:1.17.1 --port=80
2、命令式对象配置: 通过命令配置和配置文件去操作kubernetes资源,nginx-pod.yaml该文件需要自己编写创建,下节讲怎么创建的。
kubectl create/patch/delete -f nginx-pod.yaml
3、声明式对象配置: 通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml
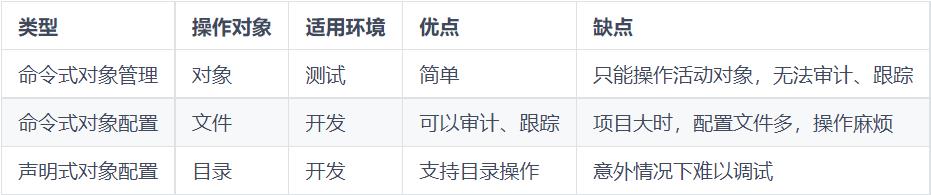
简单来说下,命令式对象管理就是平常在xshell中敲的一些命令,命令式对象配置是执行文件对资源的增删改查,声明式对象配置是执行文件对资源的新增(资源不存在)或者更新(资源已存在)。
3、kubectl命令
1、kubectl是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署。kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]
参数详情:
comand:指定要对资源执行的操作,例如create、get、delete等。
type:指定资源类型,比如deployment、pod、service
name:指定资源的名称,名称大小写敏感
flags:指定额外的可选参数
2、以查看pod为列,具体操作service、deploy等在下节讲。
查看所有pod
kubectl get pod
查看某个pod
kubectl get pod pod名称
#查看某个pod,以yaml格式展示结果
kubectl get pod pod名称 -o yaml
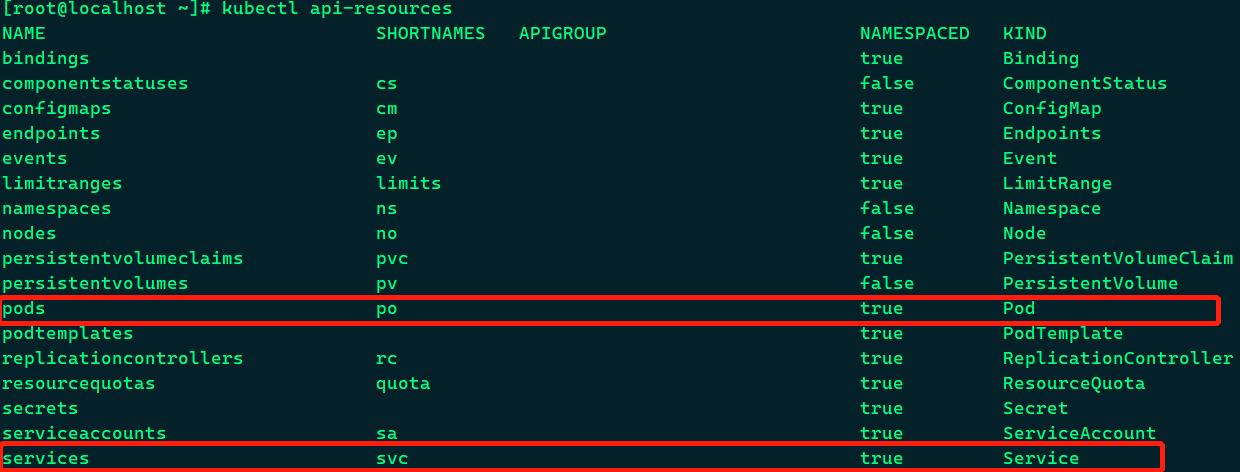
3、kubectl api-resources查看所有资源
如下图所示,可以看到资源的简写,资源的Name,和资源的KIND。查看pod时用简写、Name、KIND命令都可以,比如kubectl get po、kubectl get pod、kubectl get pods
二、k8s学习链接
k8s学习链接:
一、Kubernetes详解-(对k8s里面概念和名词的解释理解)
二、Kubernetes详解-(对k8s里namespace、pod、deployment、service的简单使用)
三、K8s详解-Pod、Pod控制器、Service特性详解
Python 详解K-S检验与3σ原则剔除异常值
文章目录
一、引言
异常值分析是检验数据是否有录入错误,是否含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地将异常值放入数据的计算分析过程中,会对结果造成不良影响;重视异常值的出现,分析其产生的原因,经常成为发现问题进而改进决策的契机。
异常值是指样本中的个别值,其数值明显偏离其他的观测值。异常值也称为离群点,异常值分析也称为离群点分析。
而对于数据异常值的处理,3σ 原则是一种基于统计的方法,简单实用。
二、3σ原则
什么叫 3σ 原则呢?
- 3σ 原则,又叫拉依达原则,它是指假设一组检测数据中只含有随机误差,需要对其进行计算得到标准偏差,按一定概率确定一个区间,对于超过这个区间的误差,就不属于随机误差而是粗大误差,需要将含有该误差的数据进行剔除。
- 局限性:仅局限于对正态或近似正态分布的样本数据处理,它是以测量次数充分大为前提(样本>10),当测量次数少的情形用准则剔除粗大误差是不够可靠的。在测量次数较少的情况下,最好不要选用该准则。
3σ 原则:
- 数值分布在(μ-σ,μ+σ)中的概率为 0.6827
- 数值分布在(μ-2σ,μ+2σ)中的概率为 0.9545
- 数值分布在(μ-3σ,μ+3σ)中的概率为 0.9973
其中,μ 为平均值,σ 为标准差。一般可以认为,数据 Y 的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到 0.3%,这些超出该范围的数据可以认为是异常值。
在实验科学中有对应正态分布的 3σ 定律(Three-sigma Law),是一个简单的推论,内容是 “几乎所有” 的值都在平均值正负三个标准差的范围内,也就是在实验上可以将 99.7% 的机率视为 “几乎一定” 。不过上述推论是否有效,会视探讨领域中 “显著” 的定义而定,在不同领域,“显著” 的定义也随着不同,例如在社会科学中,若置信区间是在正负二个标准差(95%)的范围,即可视为显著。但是在粒子物理中,若是发现新的粒子,置信区间要到正负五个标准差(99.99994%)的程度。
即使在不是正态分布的情形下,也有另一个对应的 3σ 定律(three-sigma rule)。即使是在非正态分布的情形下,至少会有 88.8% 的机率会在正负三个标准差的范围内,这是依照切比雪夫不等式的结果。若是单模分布(unimodal distributions)下,正负三个标准差内的机率至少有95%,若符合特定一些条件的分布,机率可能会到 98% 。所以如果数据不服从正态分布,也可以用远离平均值的标准差的自定义倍数来描述。
三、K-S检验
可以使用 K-S 检验一列数据是否服从正态分布
from scipy.stats import kstest
kstest(rvs, cdf, args=(), N=20, alternative='two-sided', mode='auto')
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kstest.html

补充学习:
四、Python实现
Python实现步骤具体步骤如下:
- 首先需要保证数据列大致上服从正态分布(可以使用 box-cox 变换等);
- 计算需要检验的数据列的平均值 μ 和标准差 σ;
- 比较数据列的每个值与平均值的偏差是否超过 3 倍标准差,如果超过 3 倍,则为异常值;
- 剔除异常值,得到规范的数据。
K-S 正态分布检验和 3σ 原则剔除异常值,Python 代码如下:
import numpy as np
import pandas as pd
from scipy.stats import kstest
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
from scipy.special import inv_boxcox
def KsNormDetect(df):
# 计算均值
u = df['value'].mean()
# 计算标准差
std = df['value'].std()
# 计算P值
print(kstest(df['value'], 'norm', (u, std)))
res = kstest(df['value'], 'norm', (u, std))[1]
print('均值为:%.2f,标准差为:%.2f' % (u, std))
# 判断p值是否服从正态分布,p<=0.05 拒绝原假设 不服从正态分布
if res <= 0.05:
print('该列数据不服从正态分布')
print("-" * 66)
return True
else:
print('该列数据服从正态分布')
return False
def OutlierDetection(df, ks_res):
# 计算均值
u = df['value'].mean()
# 计算标准差
std = df['value'].std()
if ks_res:
# 定义3σ法则识别异常值
outliers = df[np.abs(df['value'] - u) > 3 * std]
# 剔除异常值,保留正常的数据
clean_data = df[np.abs(df['value'] - u) < 3 * std]
# 返回异常值和剔除异常值后的数据
return outliers, clean_data
else:
print('请先检测数据是否服从正态分布')
return None
if __name__ == '__main__':
# 构造数据 某一列数据 含有异常值
data = np.random.normal(60, 5, 200)
data[6], data[66], data[196] = 16, 360, 180
print(data)
print("-" * 66)
# 可以转换为pandas的DataFrame 便于调用方法计算均值和标准差
df = pd.DataFrame(data, columns=['value'])
# box-cox变换
lam = boxcox_normmax(df["value"] + 1)
df["value"] = boxcox1p(df['value'], lam)
# K-S检验
ks_res = KsNormDetect(df)
outliers, clean_data = OutlierDetection(df, ks_res)
# 异常值和剔除异常值后的数据
outliers = inv_boxcox(outliers, lam) - 1
clean_data = inv_boxcox(clean_data, lam) - 1
print(outliers)
print("-" * 66)
print(clean_data)
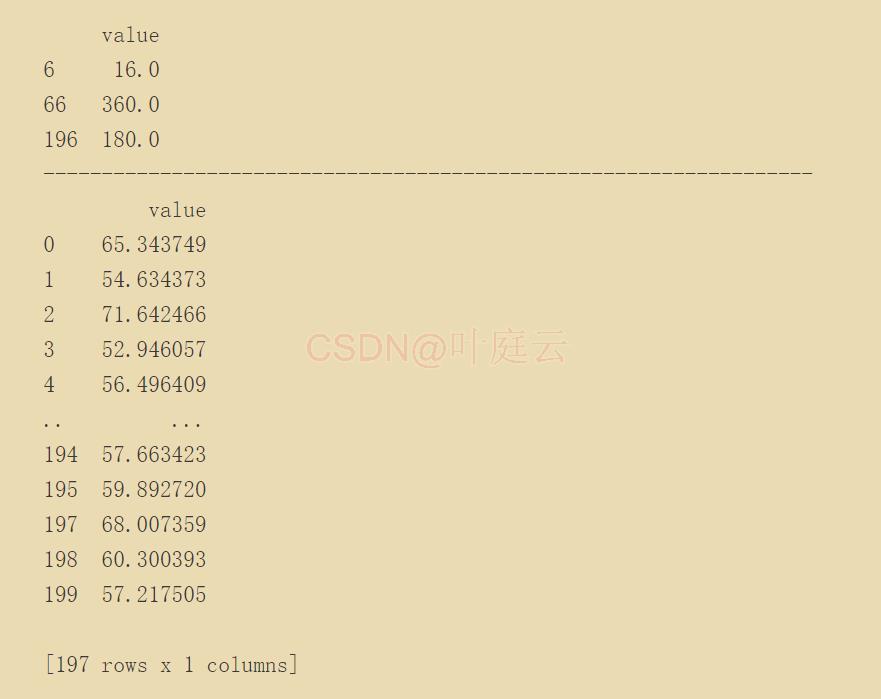
剔除异常值结果如下:
补充学习:
- Python 机器学习 | 正态分布检验以及异常值处理3σ原则
- Python实现基于3σ原则的异常值检测
- 知乎 | 机器学习中的异常值检测
- 公众号文章 | 什么是脏数据?怎样用箱形图分析异常值?终于有人讲明白了
以上是关于一Kubernetes详解-k8s概念和名词解释理解。包括组件架构资源管理kubectl命令的主要内容,如果未能解决你的问题,请参考以下文章