分布式搜索引擎ElasticSearch
Posted 星悦糖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式搜索引擎ElasticSearch相关的知识,希望对你有一定的参考价值。
目录
5.3 ElasticSearch的可视化工具Kibana安装
完整代码有需要的私信
1、ElasticSearch简介
ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(GB<TB<PB<EB)的数据。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
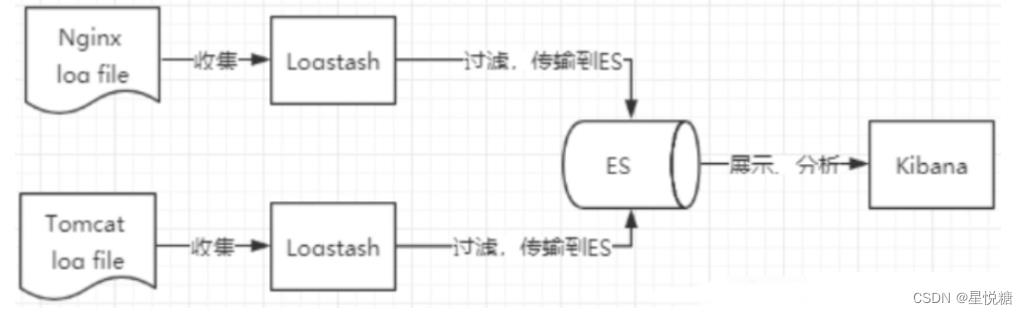
2、ELK简介
ELK是Elasticsearch、Logstash、 Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。
- 其中Elasticsearch基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
- 像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。
- Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ )收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
- Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
- 市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
3、为什么要使用ES?
(1)使用SQL数据量大的话,就十分慢,这时候就需要用到ES。项目中使用ES存储机构信息(大概有几千万条数据)。
(2)ES基本是开箱即用(解压就可以用),非常简单。
(3)如果你要做搜索这个功能。它将会极大地帮助你提高搜索效率。
另一个方面原因就是如果你了解并且会熟练使用ES,在找工作时很大程度上会成为你的一个加分项,薪资待遇会有一定的改善,而且ES在大厂中也在普遍使用。
4、ES能干什么?
说了这么多,ES到底能干什么呢,下面我们以百度为例来简单说一下,最后我们会逐一实现这些功能。
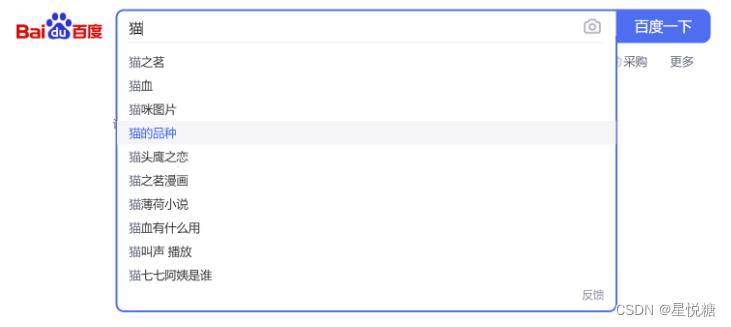
(1)在使用搜索框搜索时,会进行搜索补全
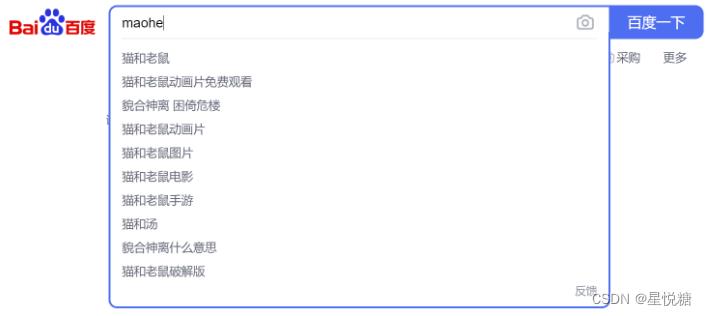
(2)使用拼音可以进行检索
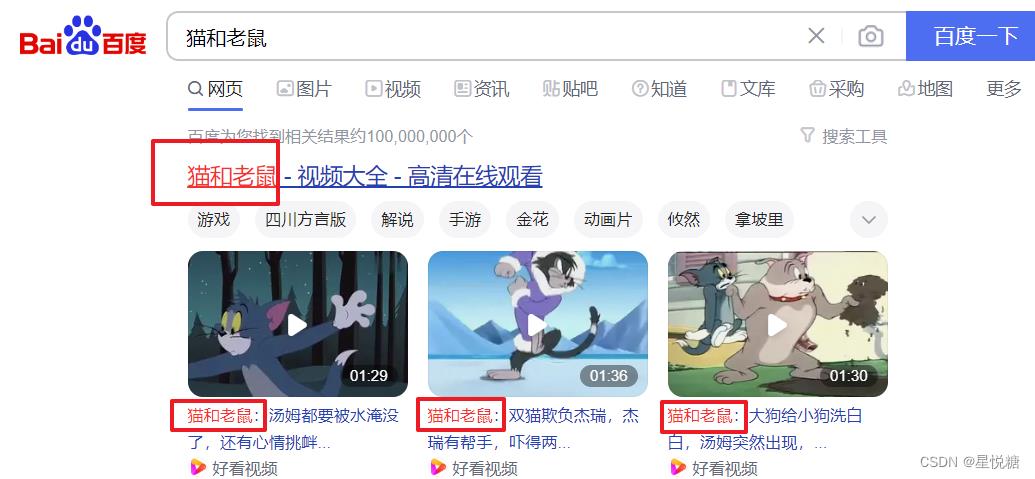
(3)搜索关键字高亮显示
(4)热搜词(猜你想搜)功能实现
这里简单描述一下,热搜词的关键在于,智能检测我们需要查询什么。一般来说热搜词为搜索数量最多的词。所以,我在全文检索时对流媒体进行查询时,会写一个切面类,在查询之前,将输入框中的词保存到ES的热搜词索引库中。然后通过聚合的方式对他们进行排序,本项目中我们以截取前十个进行显示。
5、环境准备(软件安装)
这里为大家提供一个下载链接,下载速度比较快、版本齐全。 下载中心 - Elastic 中文社区
5.1 安装ES—Windows
(1)下载
这里需要强调一点,就是版本对应问题,在这里以7.6.2版本为例。如果你下载了elasticsearch-7.6.2,那么接下来kibana以及分词器等插件版本也必须是7.6.2
(2)解压即可(尽量将ElasticSearch相关工具放在统一目录下)
(3)目录结构
bin:启动文件目录
config:配置文件目录
log4j2:日志配置文件
jvm.options:java 虚拟机相关的配置(默认启动占1g内存默认在20行左右,内容不够需要自己调整)
elasticsearch.ym1:elasticsearch 的配置文件! 默认9200端口!跨域!
lib:相关jar包
modules:功能模块目录
plugins:插件目录(ik分词器)
(4)启动ES:运行bin目录下的elasticsearch.bat文件
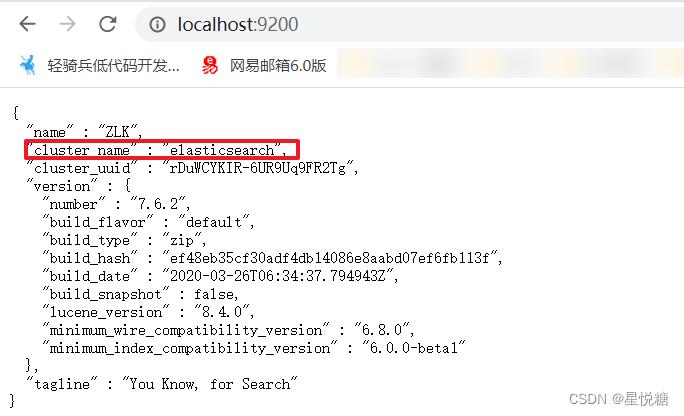
(5)测试访问:http://127.0.0.1:9200
从运行结果我们可以发现即使是单机情况下,ElasticSearch也是集群形式的,且集群名称默认是elasticsearch。
5.2 ElasticSearch-Head插件安装
在这里我们采用本地web项目安装。安装步骤如下:
(1)下载并解压(版本一致,这里不过多赘述)
(2)在根目录下打开cmd窗口
(3)运行 cnpm install 命令
(4)执行启动命令 npm run start
(5)测试访问 http://127.0.0.1:9100/ ,此时我们发现在连接ES时会出现跨域的问题,需要配置ElasticSearch的跨域,不然不能访问。
修改elasticsearch.yml文件:
- http.cors.enabled: true
- http.cors.allow-origin: "*"
(6)重启ES进行访问,此处我已经创建了几个索引:
我们来对上图做一个简单的解析:
-
索引 可以看做 “数据库”
-
类型 可以看做 “表”
-
文档 可以看做 “库中的数据(表中的行)”
这里的这个Head,我们只是把它当做可视化数据展示工具,可以查看索引和里面的数据,但是因为不支持json格式化,不方便;所以我们之后所有的查询都在kibana中进行。
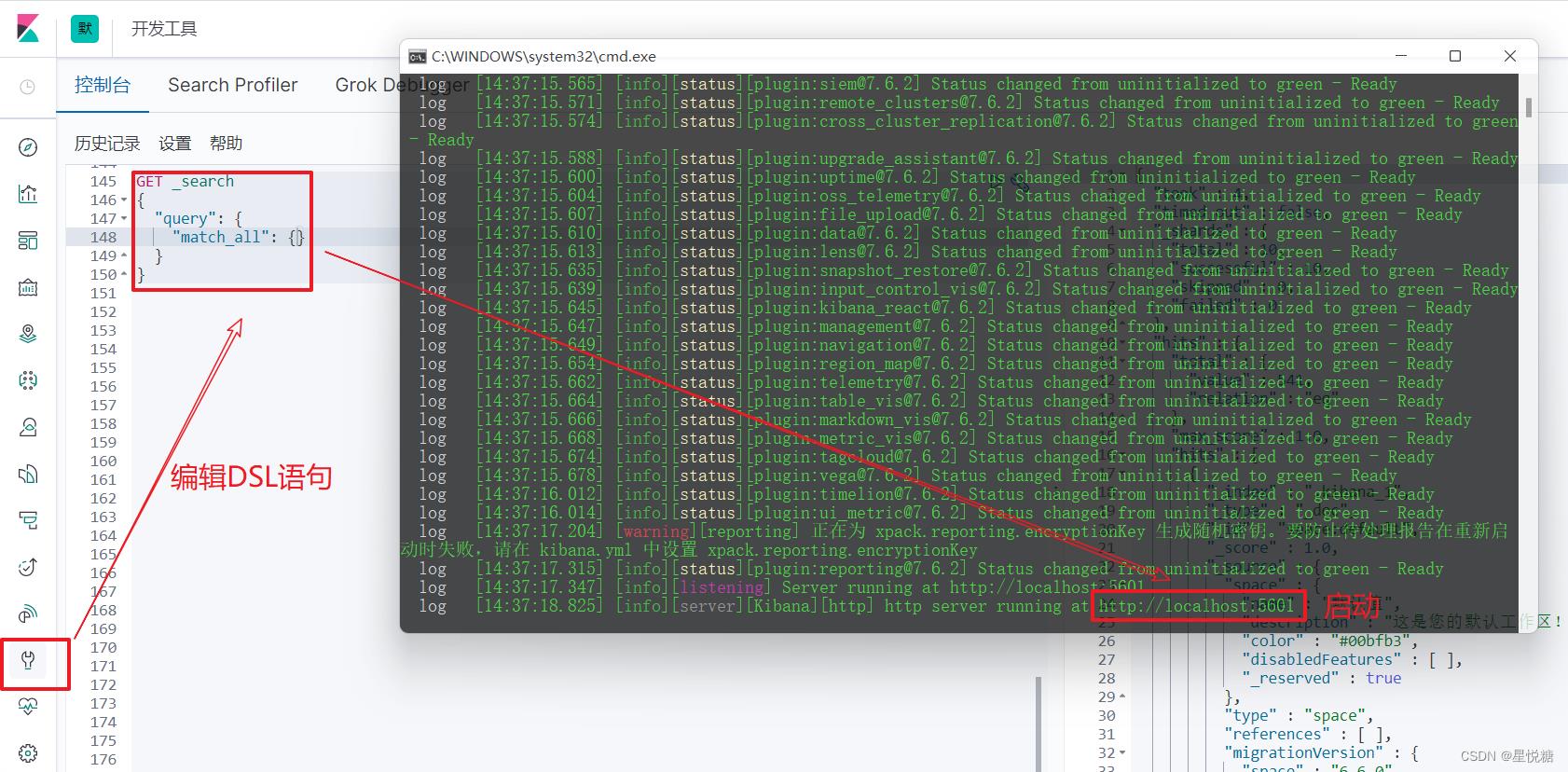
5.3 ElasticSearch的可视化工具Kibana安装
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
(1)下载解压即可使用(版本一致性)
(2)修改config/kibana.yml,进行kibana汉化
// 在kibana.yml的116行
il8n.locale: "zh-CN"
// 启动
kibana.bat
// 访问
http://127.0.0.1:5601/
(3)运行bin目录下的kibana.bat文件
5.4 IK分词器插件
IK提供了两个分词算法: ik_smart和ik_max_word
- ik_smart为最少切分
- ik_max_word为最细粒度划分(穷尽词库的可能)
(1)下载并解压(版本一致性),这里要注意的的解压存放的位置。

(2)这时候重启ES可以发现ik分词器插件被加载。

(3)使用Kibana测试IK分词器
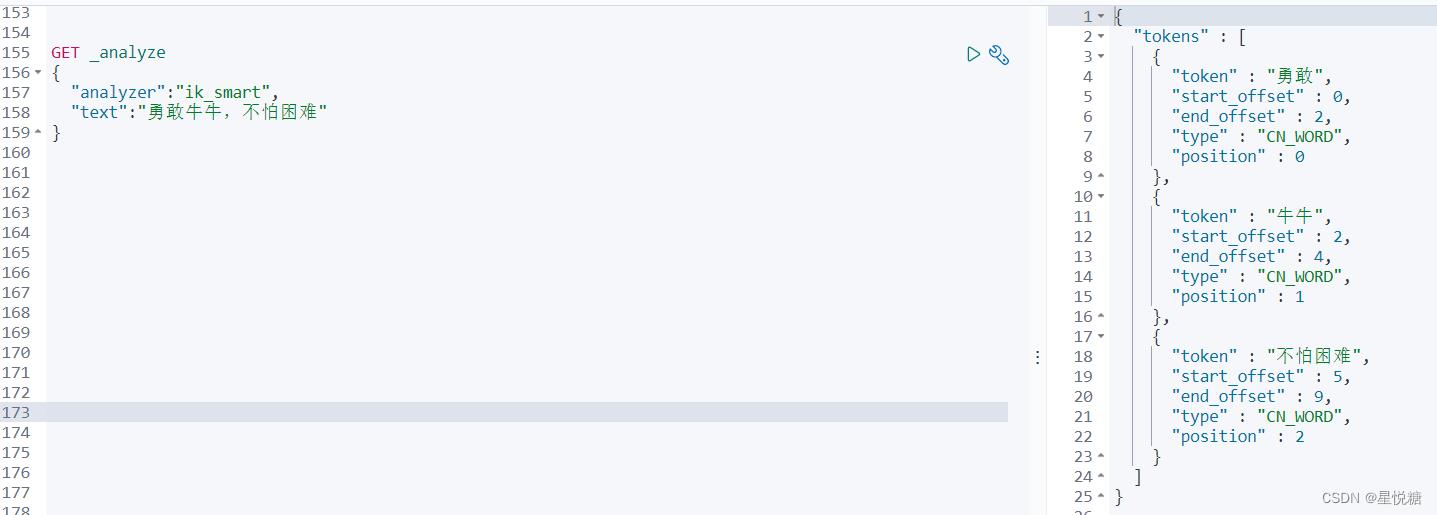
最少切分:
GET _analyze
"analyzer":"ik_smart",
"text":"勇敢牛牛,不怕困难"
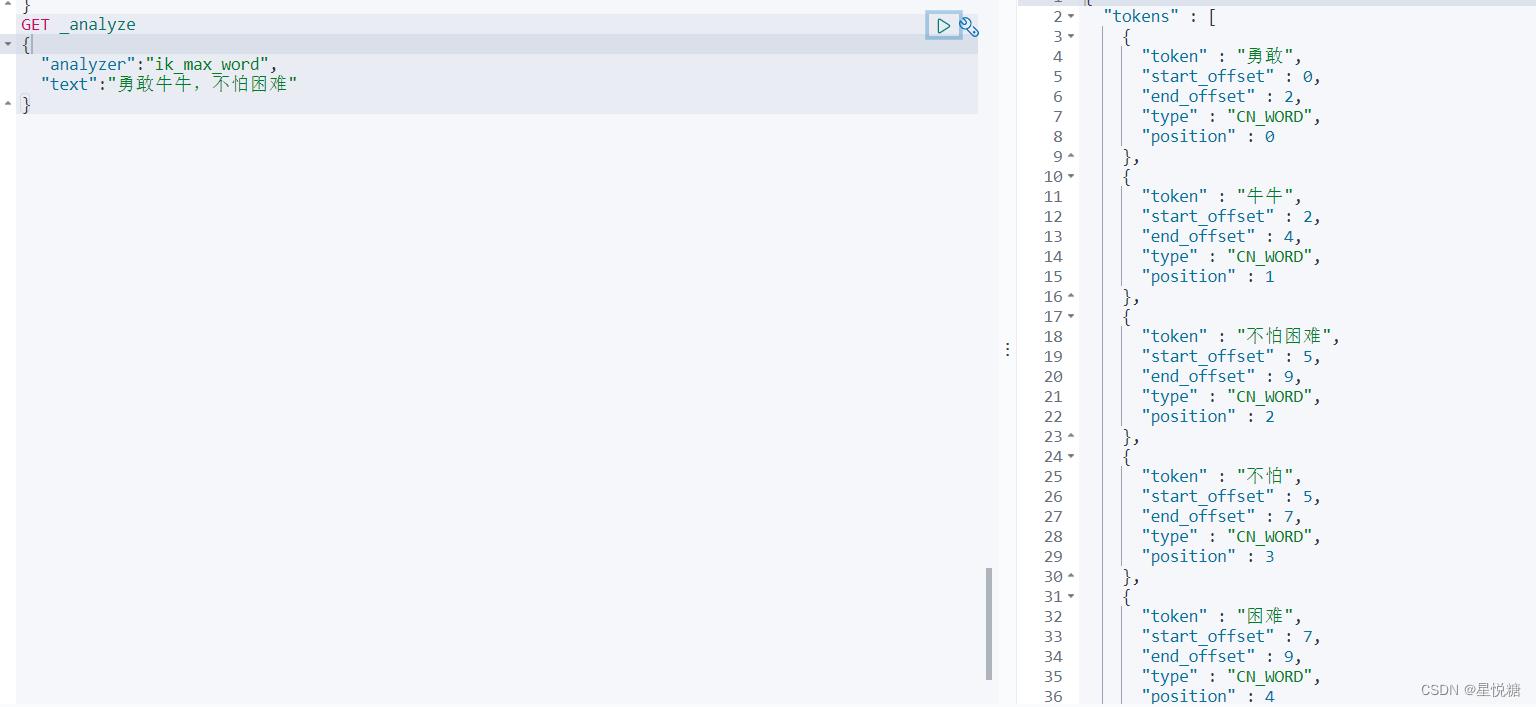
最细粒度划分:
GET _analyze
"analyzer":"ik_max_word",
"text":"勇敢牛牛,不怕困难"
(4)扩展词条、停用词条
-
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
-
在词典中添加拓展词条或者停用词条
5.5 拼音分词器插件
(1)下载并解压(版本一致性),这里要注意的的解压存放的位置。
(2)这时候重启ES可以发现 pinyin分词器插件被加载。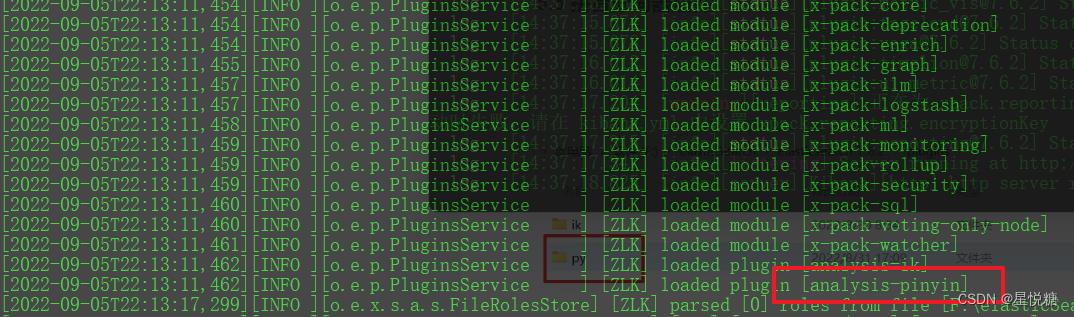
6、ES核心概念
- ElasticSearch是面向文档,一切都是JSON!
-
Elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types (慢慢会被弃用) |
| 行(rows) | documents |
| 字段(columns) | fields |
6.1 物理设计
Elasticsearch在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移,一个ES就是一个集群! 即启动的ElasticSearch服务,默认就是一个集群,且默认集群名为elasticsearch。
一个集群至少有一个节点,而一个节点就是一个Elasricsearch进程,节点可以有多个索引;默认情况下,如果你创建索引,那么索引将会有个5个分片(primary shard ,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
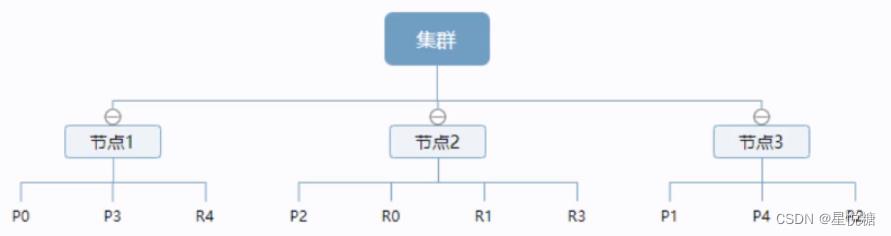
上图是一个有3个节点的集群,可以看到主分片P和对应的复制分片R都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引(一个ElasticSearch索引包含多个Lucene索引),一个包含倒排索引的文件目录,倒排索引的结构使得Eelasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
6.2 倒排索引
倒排索引的概念是基于mysql这样的正向索引而言的。那么什么是正向索引呢?
(1)正向索引
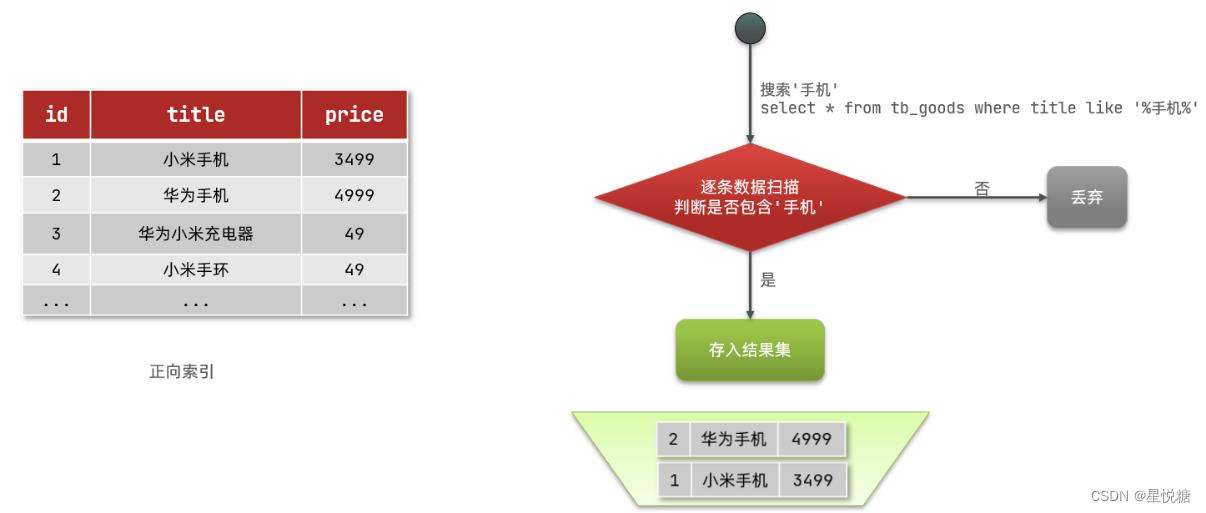
如果是根据id查询,那么直接走索引,查询速度非常快。但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
如上如果基于title就需要逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
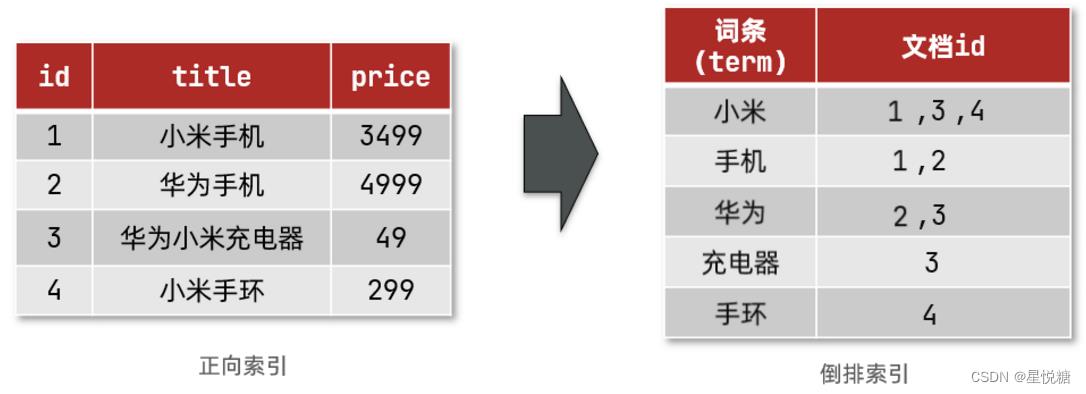
(2)倒排索引(将文档拆分成一个个的词条)
倒排索引中有两个非常重要的概念:文档、词条(后面我们会遇到,这里了解一下这个概念)
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。
创建倒排索引是对正向索引的一种特殊处理,流程如下:
-
将每一个文档的数据利用算法分词(分词器),得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建索引,例如hash表结构索引
倒排索引的搜索流程:(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
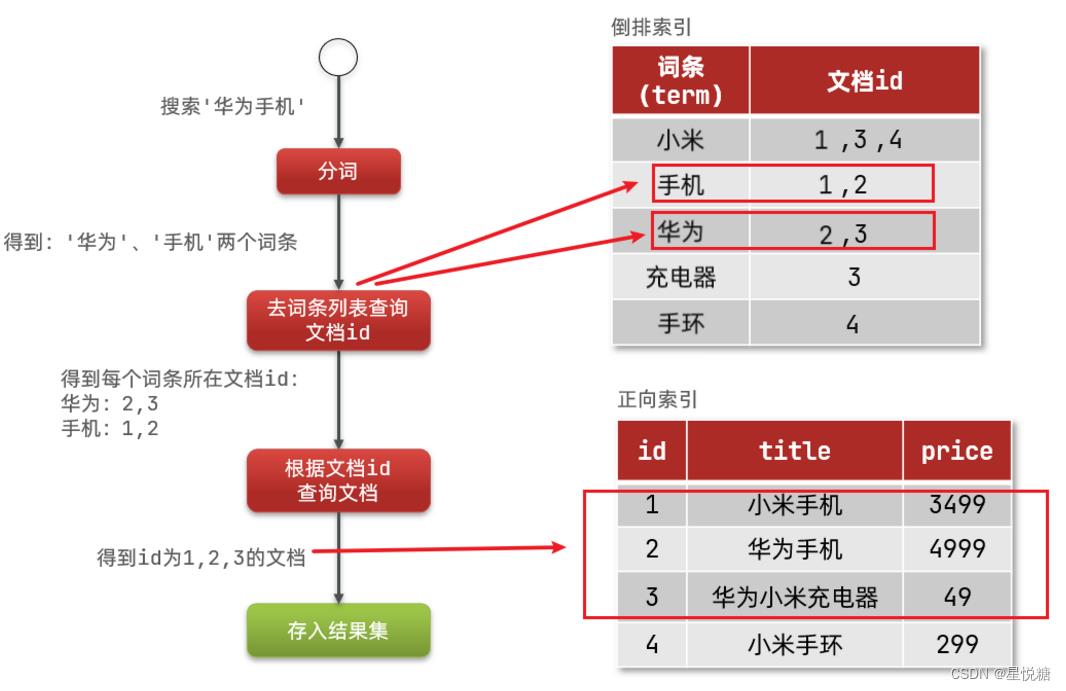
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,这样的话查询速度就非常快!无需进行全表扫描。
正向索引和倒排索引的区别在哪?
-
正向索引是根据id索引的方式。当根据词条查询时,必须先逐条获取每个文档,进行全表扫描,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,先找到用户要搜索的词条,根据词条得到词条所在的文档的id,然后根据id获取文档。是根据词条找文档的过程。
6.3 文档和字段
(1)在前面我们提过ES是面向文档的,那么这就说明索引和搜索数据的最小单位是文档;这里的文档可以是数据库中的一条商品数据,一个订单信息。在向ES进行存储时,文档数据会被序列化为json格式。
(2)json格式的数据中包含有若干个字段,其实也就相当于我们数据库中的列。

6.4 索引和映射
(1)ES中索引是一个比较重要的概念,它指的是相同类型文档的集合。学习ES也是基于项目中对人员和部门开发的需要,这里就需要建立人员和部门两个索引(这里以用户为例):

所有用户文档组织在一起,构成用户的索引。
(2)映射就是创建索引时指定都包含哪些字段以及字段的数据类型、分词器等一些设置。(如果你仅仅是想完成这样的一个功能,ES的DSL可以不用过多了解,后面我们直接套用模板)
常见的mapping属性(做一下了解,后面在进行DSL操作时要求能够看懂)
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
-
数值:long、integer、short、byte、double、float、
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
7、Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
8、 mysql和elasticsearch对比
前面我们大致上了解了什么是ES,下面我们来看一下它和mysql有什么区别呢,是不是学会了ES我们就可以抛弃mysql了?
· 事实上并非如此,两者各有各的优势,在工作中往往是两者结合使用:
(1)Mysql:擅长事务类型操作,可以确保数据的安全和一致性
(2)Elasticsearch:擅长海量数据的搜索、分析、计算
那么具体什么情况下用MySQL,什么情况下用ES呢?
(1)对安全性要求较高的写操作,使用mysql实现
(2)对查询性能要求较高的搜索需求,使用elasticsearch实现
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
9、通过Kibana操作文档和索引库
9.1 索引库操作
9.2 文档操作
10、SpringBoot整合ES【环境搭建】
(1)创建数据库、建表,数据结构如下:
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名称',
`address` varchar(255) NOT NULL COMMENT '酒店地址',
`price` int(10) NOT NULL COMMENT '酒店价格',
`score` int(2) NOT NULL COMMENT '酒店评分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌',
`city` varchar(32) NOT NULL COMMENT '所在城市',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级',
`business` varchar(255) DEFAULT NULL COMMENT '商圈',
`latitude` varchar(32) NOT NULL COMMENT '纬度',
`longitude` varchar(32) NOT NULL COMMENT '经度',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;(2)建Moudle、改pom、主启动、yml、业务类(个人编程习惯),这里仅介绍一些重点内容。
改POM:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency><properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6</elasticsearch.version>
</properties>主启动:
@MapperScan("cn.itcast.hotel.mapper")
@SpringBootApplication
public class HotelDemoApplication
public static void main(String[] args)
SpringApplication.run(HotelDemoApplication.class, args);
@Bean
public RestHighLevelClient restHighLevelClient()
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://127.0.0.1:9200")
));
11、在SpringBoot中操作索引库
操作索引库的代码整体上分为三步:
1)创建Request对象。
2)添加请求参数,其实就是DSL的JSON参数部分。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
3)发送请求,client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。
准备工作:初始化代码同时注入RestHighLevelClie
//索引库的增删改查
@SpringBootTest
class HotelIndexTest
@Resource
private RestHighLevelClient client;
//初始化代码
@BeforeEach
void setUp()
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://127.0.0.1:9200")
));
@AfterEach
void tearDown() throws IOException
client.close();
创建一个类,定义mapping映射的JSON字符串常量:
//定义mapping映射的JSON字符串常量
public class HotelIndexConstants
public static final String MAPPING_TEMPLATE = "\\n" +
" \\"mappings\\": \\n" +
" \\"properties\\": \\n" +
" \\"id\\": \\n" +
" \\"type\\": \\"keyword\\"\\n" +
" ,\\n" +
" \\"name\\": \\n" +
" \\"type\\": \\"text\\",\\n" +
" \\"analyzer\\": \\"ik_max_word\\",\\n" +
" \\"copy_to\\": \\"all\\"\\n" +
" ,\\n" +
" \\"address\\": \\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"index\\": false\\n" +
" ,\\n" +
" \\"price\\": \\n" +
" \\"type\\": \\"integer\\"\\n" +
" ,\\n" +
" \\"score\\": \\n" +
" \\"type\\": \\"integer\\"\\n" +
" ,\\n" +
" \\"brand\\": \\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"copy_to\\": \\"all\\"\\n" +
" ,\\n" +
" \\"city\\": \\n" +
" \\"type\\": \\"keyword\\"\\n" +
" ,\\n" +
" \\"starName\\": \\n" +
" \\"type\\": \\"keyword\\"\\n" +
" ,\\n" +
" \\"business\\": \\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"copy_to\\": \\"all\\"\\n" +
" ,\\n" +
" \\"pic\\": \\n" +
" \\"type\\": \\"keyword\\",\\n" +
" \\"index\\": false\\n" +
" ,\\n" +
" \\"location\\": \\n" +
" \\"type\\": \\"geo_point\\"\\n" +
" ,\\n" +
" \\"all\\": \\n" +
" \\"type\\": \\"text\\",\\n" +
" \\"analyzer\\": \\"ik_max_word\\"\\n" +
" \\n" +
" \\n" +
" \\n" +
"";
11.1 创建索引
//创建索引库
@Test
void testCreateIndex() throws IOException
// 1.创建request对象 PUT /hotel
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求参数 ,MAPPING_TEMPLATE是静态常量字符串,在cn.itcast.hotel.constants中已经声明,里面内容是创建索引库的DSL语句
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求 ,client.indices()方法来获取索引库的操作对象
client.indices().create(request, RequestOptions.DEFAULT);
11.2 删除索引
//删除索引库
@Test
void testDeleteIndex() throws IOException
// 1.准备Request
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
11.3 判断索引是否存在
//判断索引库是否存在
@Test
void testExistsIndex() throws IOException
// 1.准备Request
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.发送请求
boolean isExists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(isExists ? "存在" : "不存在");
12、在SpringBoot中操作文档【重要】
为了与索引库操作分离,在这里我们另外在写一个测试类来对存储在数据库中的数据进行系列化的操作。首先我们来做一下准备工作:
-
初始化RestHighLevelClient
-
新建一个Hotel实体类
-
我们的酒店数据在数据库,需要利用IHotelService去查询,所以注入这个接口
新建一个Hotel实体类:
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("tb_hotel") //实体类和数据库中的表实现映射
public class Hotel
@TableId(type = IdType.INPUT)
private Long id;//酒店id
private String name;//酒店名称
private String address;//酒店地址
private Integer price;//酒店价格
private Integer score;//酒店评分
private String brand;//酒店品牌
private String city;//所在城市
private String star_name;//酒店星级
private String business;//商圈
private String longitude;//经度
private String latitude;//纬度
private String pic;//酒店图片
可以看出,这个实体类与我们定义的索引库是存在一些差异的,有几个特殊字段需要在这里说明一下:
-
location:地理坐标,里面包含精度、纬度
-
all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户进行搜索

所以我们需要在此基础上定义一个新的实体类来与索引库进行衔接:
@Data
@AllArgsConstructor
@NoArgsConstructor
//数据库与我们的索引库存在一些差异,在这里我们定义一个新的类型来与索引库的结构吻合
public class HotelDoc
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;//地理坐标(里面整合了数据库中精度、纬度两个字段)
private String pic;
初始化操作:
@SpringBootTest
public class HotelDocumentTest
@Autowired
private IHotelService hotelService;
private RestHighLevelClient client;
@BeforeEach
void setUp()
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
@AfterEach
void tearDown() throws IOException
this.client.close();
12.1 新增文档
我们这里的目的是 将数据库中的数据查询出来存储到ES索引库中。
新增文档的Java代码:【这里面对应的查询语句比较简单,这里就不过多赘述】整体步骤如下:
//新增文档,将某条数据从数据库中查询出来然后添加到elasticsearch中
@Test
void testAddDocument() throws IOException
// 1.查询数据库hotel数据,返回一个Hotel对象
Hotel hotel = hotelService.getById(2062643523L);
// 2.转换为和索引库对应的实体类
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.转JSON
String json = JSON.toJSONString(hotelDoc);
// 4.准备Request
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 5.准备请求参数DSL,其实就是文档的JSON字符串
request.source(json, XContentType.JSON);
// 6.发送请求
client.index(request, RequestOptions.DEFAULT);
12.2 修改文档
修改存在两种方式:
-
全量修改:本质上是先根据id删除,然后再新增
-
增量修改:修改文档中的指定字段值【重点关注】
在RestClient的API中,全量修改与新增的API完全一致,其判断依据是ID:
-
如果修改时,ID已经存在,则修改。
-
如果修改时,ID不存在,则新增。
修改文档的Java 代码:
//根据id修改文档中的某条记录
@Test
void testUpdateById() throws IOException
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备参数
request.doc(
"price", "870"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
12.3 查询文档
查询文档的 Java代码:
//根据id查询文档中的具体数据
@Test
void testGetDocumentById() throws IOException
// 1.准备Request // GET /hotel/_doc/id
GetRequest request = new GetRequest("hotel", "61083");
// 2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果,返回json字符串
String json = response.getSourceAsString();
// 4.转换为HotelDoc类型的对象
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
12.4 删除文档
删除文档的 Java 代码:
//根据id删除文档中的某条记录
@Test
void testDeleteDocumentById() throws IOException
// 1.准备Request // DELETE /hotel/_doc/id
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
12.5 批量导入文档
操作步骤如下:
-
利用mybatis-plus查询酒店数据
-
将查询到的酒店数据(Hotel)转换为索引库类型数据(HotelDoc)
-
利用JavaRestClient中的BulkRequest批处理,实现批量新增文档
//批量导入文档,利用BulkRequest批量将数据库数据导入到索引库中
@Test
void testBulkRequest() throws IOException
// 查询所有的酒店数据
List<Hotel> list = hotelService.list();
// 1.准备Request,创建Bulk请求
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : list)
// 2.1.转为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.转json
String json = JSON.toJSONString(hotelDoc);
// 2.3.添加要批量提交的请求,创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotel.getId().toString())
.source(json, XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
13、DSL查询文档
查询的语法基本一致,除了match_all查询,其它查询无非就是查询类型、查询条件发生变化
GET /indexName/_search
"query":
"查询类型":
"查询条件": "条件值"
13.1 查询所有数据(match_all)
// 查询所有,没有查询条件
GET /indexName/_search
"query":
"match_all":
13.2 全文检索查询
全文检索查询利用了我们前面提到过的分词器,先分词,再利用倒排索引去索引库中进行匹配。全文检索查询的基本步骤如下:
-
1)对用户搜索的内容做分词,得到词条
-
2)根据词条去倒排索引库中匹配,得到文档id
-
3)根据文档id找到文档,返回给用户
全文检索查询通常情况下包括如下两种:
-
1)match查询:单字段查询
GET /indexName/_search
"query":
"match":
"FIELD": "TEXT"
-
2)multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
GET /indexName/_search
"query":
"multi_match":
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
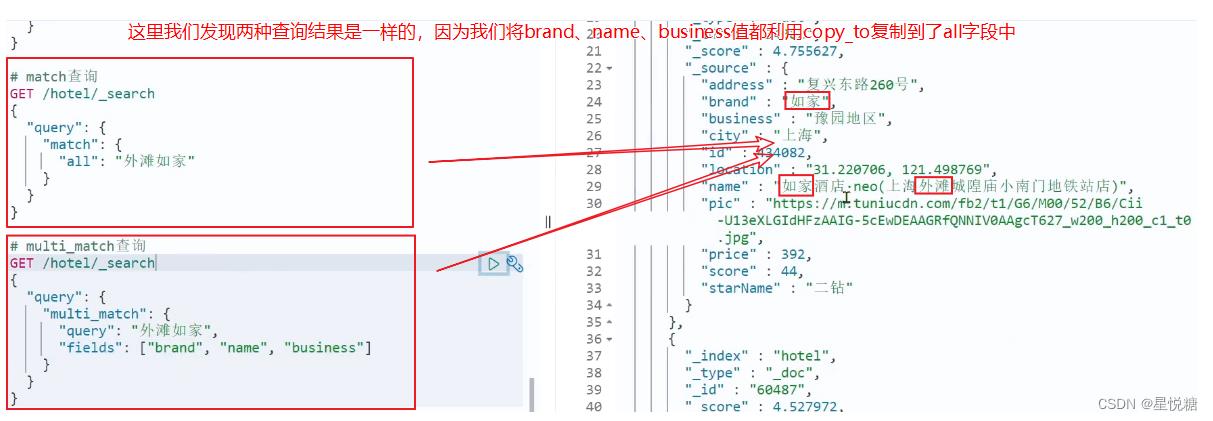
参与查询字段越多,查询性能越差 ,因此在搜索字段比较多的情况下建议采用copy_to的方式。
13.3 精确查询
精确查询一般是查找keyword、数值、日期、boolean等不会分词类型的字段,常见方式:
-
term:根据词条精确值查询(例如web页面的头部标签,相当于条件过滤的作用)
-
range:根据数值范围查询,可以是数值、日期的范围
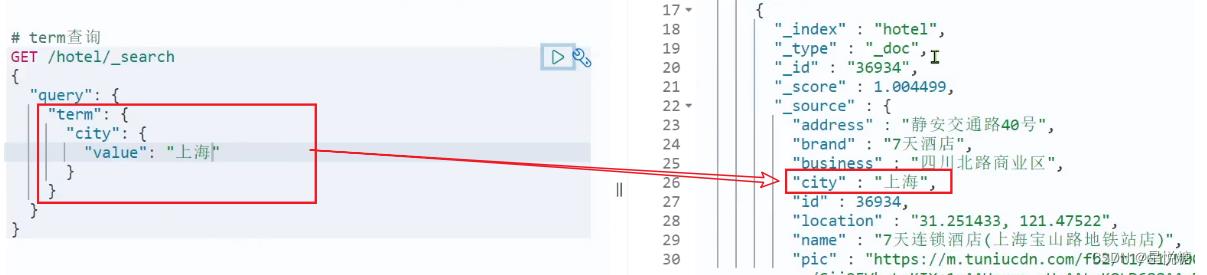
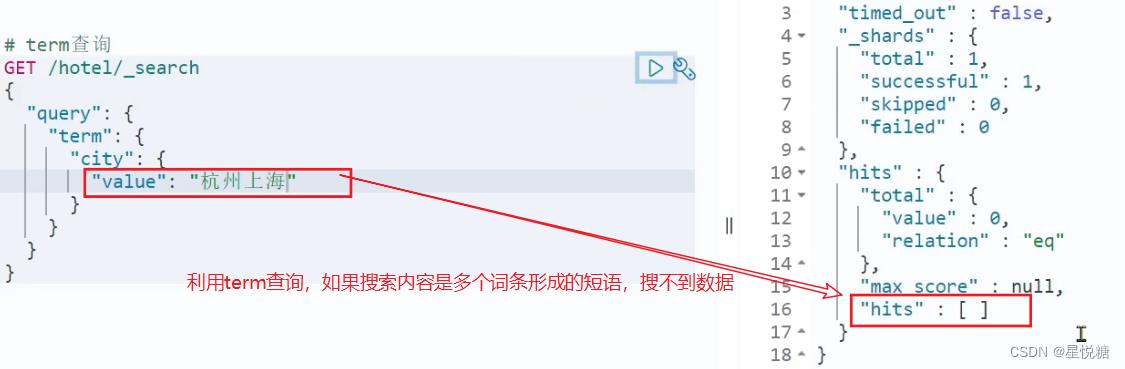
(1)term查询
// term查询
GET /indexName/_search
"query":
"term":
"FIELD":
"value": "VALUE"
(2)range查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如京东淘宝中做价格范围过滤。
// range查询
GET /indexName/_search
"query":
"range":
"FIELD":
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
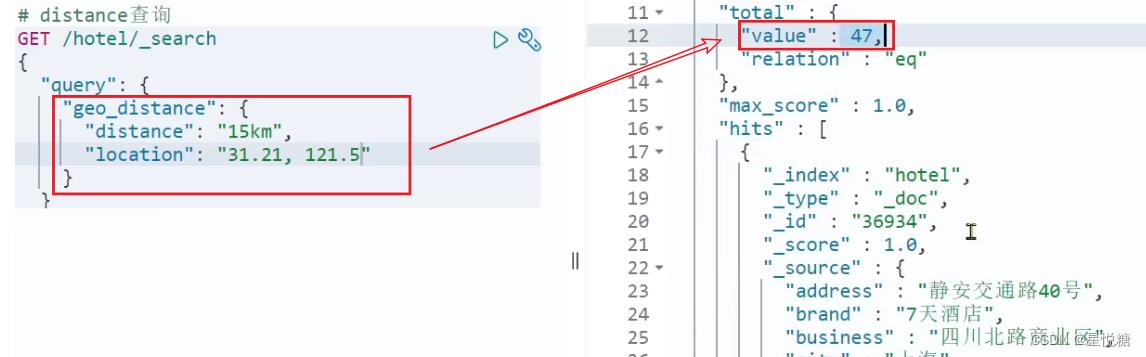
13.4 地理坐标查询(geo_distance )
在实体类中我们已经定义了经纬度,这里的地理坐标查询就是根据经纬度来进行查询。根据前面学习的知识,我们很容易明白附近查询就是查询到指定中心点小于某个距离值的所有文档。
常见的应用场景:
-
美团:搜索我附近的酒店
-
滴滴:搜索我附近的车
-
微信:搜索我附近的人
// geo_distance 查询
GET /indexName/_search
"query":
"geo_distance":
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
13.5 复合(compound)查询【重要】
复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。
-
fuction_score:算分函数查询,可以控制文档相关性算分,控制文档排名
-
bool_query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
(1)相关性算分
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。【这是ES默认的一种打分机制】
ES 5.1版本以后采用的是BM25打分机制,它会根据词条和文档的相关度进行打分,此外单个词条的打分也会有一个上限,并不会因为词条频率而决定最后的打分结果。
(2)算分函数查询
根据相关度打分其实是比较合理的需求,但实际生活中合理的不一定是产品经理需要的。有时候在你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱越多谁的排名越靠前。
要想人为的控制相关性算分,就需要利用elasticsearch中的function_score 查询。
function_score 查询中包含四部分内容:
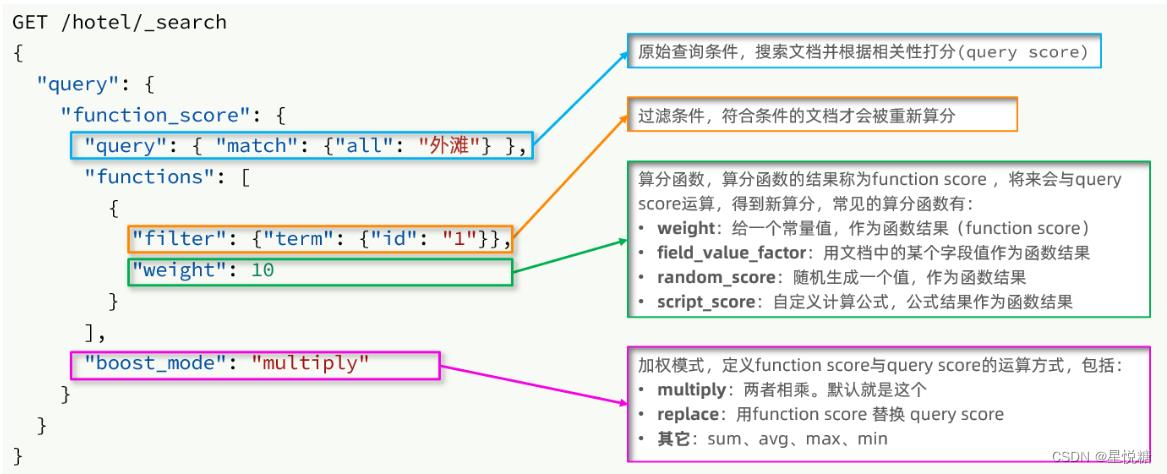
function score的运行步骤如下:
-
1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
2)根据过滤条件,过滤文档
-
3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
-
4)将原始算分(query score)和函数算分(function score)
以上是关于分布式搜索引擎ElasticSearch的主要内容,如果未能解决你的问题,请参考以下文章