为什么要使用 transaction data?
Posted 互联网创业项目
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么要使用 transaction data?相关的知识,希望对你有一定的参考价值。
可能你也注意到了,在跟智能合约交互(例如发送 token)时,你的事务会自动包含 input data(“输入数据”)。在 MyCrypto 钱包界面,这些数据有个简单的标签:“Data(数据)” —— 它是做什么的呢?
这篇文章就是从技术上解释事务输入数据是怎么一回事,它实质是什么,又是怎么工作的。
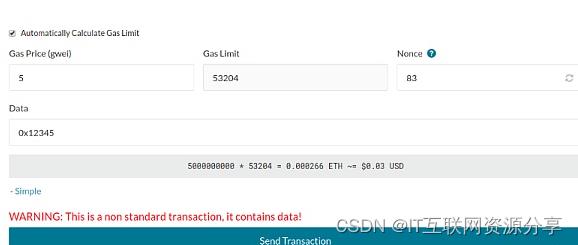
- MyCrypto 钱包的高级事务设定 -
什么是 Input Data?
我们先来看看这笔 token 转账交易。某个人发送了 0 ETH 到 0xd26114cd6ee289accf82350c8d8487fedb8a0c07(OmiseGo 合约地址),而且 Etherscan 网站呈现了这是一笔意图发送 0.19 OMG token 到这个地址的事务。那么,EVM (以太坊虚拟机)究竟是怎么知道,这个人想要转账某个数额的 token 到另一地址的呢?
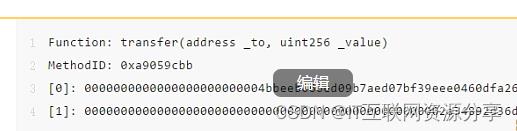
你再仔细看 Etherscan,就能看到这笔事务带着 input data。input data 是发送者为这笔事务附加的额外数据,既可以是普通的文本,也可以是数字(以十六进制的形式编码)。但在这笔交易中,发送者使用这部分数据来 “告诉” 合约,让合约运行特定的函数。智能合约本身是由一系列函数组成的。举例而言,一个 ERC-20 token 合约使用比如 “transfer” 来把 token 从 A 账户转移到 B账户,使用 “balancerOf” 函数来获得某个地址的余额,等等。在我们研究的这笔交易中,你可以看到它调用了 transfer(address_to, uint256_value) 函数。
这笔事务的输入数据为0xa9059cbb0000000000000000000000004bbeeb066ed09b7aed07bf39eee0460dfa26152000000000000000000000000000000000000000000000000002a34892d36d6c74。你可以把这一长串的 十六进制 数据分解一下。开头的 0x 表示这是一个十六进制数值,紧接着的 8 个字节(a9059cbb)是函数标识符,再然后就全部是以 32 字节(也就是 64 个 16 进制字符)为一组的函数参数。所以第一组是 0000000000000000000000004bbeeb066ed09b7aed07bf39eee0460dfa261520 而第二组是 000000000000000000000000000000000000000000000000002a34892d36d6c74。
- Input Data 分解 -
如果你在 Etherscan 上查看这些数据,你会看到它以下文这个形式呈现
十六进制是啥?
十六进制是一种计数系统,就像十进制和二进制一样;十六进制使用数字 0 到 9 和字母 A 到 F(不区分大小写),来对应表示十进制的 0 到 15。下面这种图展现的就是这样的对应关系。十六进制常常用来更直观地表示大数字。

- 十进制数字与对应的十六进制字符 -
单个十六进制字符所能表示的最大数值是 15,长度是 4 个比特(bit)。多个十六进制字符相连时,你要把每个字符的二进制表示前后拼接在一起,才能得到其十进制数值。举个例子,0x5C,可以写成 0101 (=5) 和 1100 (=C),前后拼接就是 01011100,这就是二进制形式的 92,所以十六进制数 0x5C 的数值就是 92。
大多数编程语言都使用前缀 0x 作为绝对标识符(arbitrary identifier),将十六进制数与其他的计数类型(比如普通的十进制、二进制等)区别开来。这个前缀本身没有任何意义,只是为了清晰。我们这篇文章也会采取一样的做法,十六进制数都用 0x 开头。
讲完这些,我们继续。如果你还是没能理解十六进制,也不用担心 —— 对于理解 input data 来说不是必需的。
Input Data 与智能合约
Input Data 的首要用途就是与智能合约交互。大部分智能合约都使用 合约 ABI 规范,使得 Etherscan 这样的网站能自动解码 input data 并显示事务所调用的具体操作。在我们上面那个例子中,这是一笔有关代币合约的事务,而且代币合约遵循 ERC-20 标准。这也就意味着,我们都知晓所有可能调用的函数,以及它们的 签名。举例,用于 ERC-20 合约的 transfer(转账)函数的完整签名总是 transfer(address, uint256),意味着这个函数需要两个参数,所传入的第一个参数会被解读为一个地址,第二个参数会被解读为一个未签名的 256 位的数字(大小上限为 2256-1)。
Solidity 语言有多种参数类型。如果你有兴趣学习 Solidity 语言和智能合约,你可以在Solidity 文档页面了解更多。
函数签名
如你所见,transfer 函数的签名是 transfer(address, uint256),这个对所有 ERC-20 合约都是一样的。如果某个合约给转账函数安排不一样的参数类型,比如一个地址和一个 uint128(未签名的 128 位整数),这个合约就不是 “ERC-20 兼容” 的。
要获得一个函数的签名的十六进制形式,我们先要获得这个函数的 SHA-3(或者说 Keccak-256)哈希值的前面 4 个字节(也就是 8 个十六进制字符)。而要想知道一个数据的 Keccak-256 哈希值,你可以使用 JavaSceript 语言的 web3 库,或者求助于这样的在线工具。在这个工具页面填入 transfer(address,uint256),它会显示 0xa9059cbb2ab09eb219583f4a59a5d0623ade346d962bcd4e46b11da047c9049b 作为结果。取前 8 个字符(忽略掉 0x),就是 a9059cbb,恰好跟上述事务的 MethodID 一致。
另一个例子:ERC-20 标准合约的 approve(许可)函数的函数签名是 approve(address,uint256),其 SHA-3 哈希值是 0x095ea7b334ae44009aa867bfb386f5c3b4b443ac6f0ee573fa91c4608fbadfba,首 8 个字符是 095ea7b3,因此,调用许可函数的 input data 开头就会是 0x095ea7b3。这笔发往 DAI token 合约的事务就是如此。
地址和数量
每一个参数(除了 列表/数组 和纯文本 —— 这些我们后文再说)的长度都是 32 字节,或者说 64 个十六进制字符。但以太坊地址只有 40 个字节长(不算 0x 的话)。为了解决这个问题,地址参数要用 0 来填充。在十六进制里面,0x0000123 和 0x123 是一样的,因此 0x0000000000000000000000004bbeeb066ed09b7aed07bf39eee0460dfa261520(上述事务中的地址参数)等同于 0x4bbeeb066ed09b7aed07bf39eee0460dfa261520,而且 0x00000000000000000000000000000000000000000000000002a34892d36d6c74 也就等于 0x2a34892d36d6c74。那为什么我们要填充这些 0 呢?
就像我们上面说到的,Solidity 合约可以接受的最大数值是 2256 - 1,刚好是 32 字节。使用固定的长度可以让 EVM 和其他应用在解码数据时候更轻松,因为你可以假设每一个参数的长度都是一样的。
那数组和字符串呢?
如上所述,在 input data 中使用数组和字符串,情形会有些许不同。因为数组本质是多个东西组成的一个列表。举个例子,1、2、3 三个数所组成的列表在大多数编程语言中都可以写为 [1, 2, 3]。要在事务中发送这种数据,列表中的每一个对象都要作为 32 字节一组的数据发送,列在 input data 的结尾。指明数组长度的指针就作为参数。
假定我们有一个叫做 calledmyFunction 的函数,接收一个地址和数字的数组作为参数,即 myFunction(address,uint256[])。该函数的函数签名是 0x4b294170。地址这一项,我们照上面所说的操作。因为我们的数组包含 3 个对象,数组的长度用十六进制表示为 0x3。然后每个对象都要占据恰好 32 自己的空间,且数组要放在所有其它参数之后,所以数组会从 32 32 = 64 字节之后开始。

- 例子:input 数据要按照 32 字节一组来切分 -
因为字符串的长度是任意的(可能长过 32 字节),它们要按 32 字节一组来切分,处理方式跟数组相同。
像 Etherscan 这样的网站是如何解码 input data 的?
哈希函数是单向函数,所以如果你只有函数签名的哈希值,是不可能会恢复出函数签名的(你要试试暴力破解吗老弟)。合约的所有者可以将合约的 ABI 作为 JSON 文件上传,就像这个例子,这可以用来拿到函数签名的哈希值。
即使合约的所有者不上传合约的 ABI,也能够解码 input 数据(对大多数合约而言)。因为,ERC-20 合约函数的签名都是一样的,因此 Etherscan 只需使用一个预定义的合约 ABI 即可服务大部分合约。举个例子,ERC 20 合约的转账函数的合约 ABI 如下文所示:
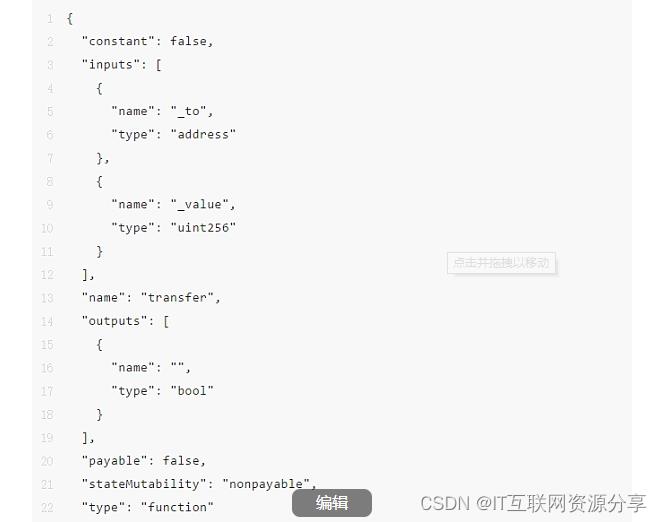
如果输入数据里的签名与任意一个预定义的函数相匹配,Etherscan 都能解码 input data。
input data 的大小有没有什么限制?
既有,也没有。以太坊协议没有为 input data 的长度设固定的上限,但 input data 也消耗 gas。单个区块可用的 Gas 数量是有上限的,在本文撰写时是 800 万(译者注:原文撰写于 2019 年 2 月,在 2021 年 4 月,已经上升到 1500 万)。每一个 0 字节(0x00)都要消耗 4 gas,而非零的字节要消耗 68 gas。一笔标准的 ETH 转账事务要消耗 21000 单位 gas,所以,如果不考虑调用合约的交易,当前 input data 的最大长度是 2 MB(全部由 0 组成),或者全部用非零字节的话,就是 0.12 MB。因为 input data 不会只有零,也不会一个 0 也没有,所以实际的大小会在两者之间。
如果你想看实时的 区块 Gas 上限,可以看 ETHStats.net。
- 特定区块的 Gas 上限 -
只需将鼠标停留在 “Gas Limit” 部分的某个区块上,就可以看到其 Gas 上限。
为啥使用 Spring Data JPA 更新实体时@Transactional 隔离级别不起作用?
【中文标题】为啥使用 Spring Data JPA 更新实体时@Transactional 隔离级别不起作用?【英文标题】:Why does @Transactional isolation level have no effect when updating entities with Spring Data JPA?为什么使用 Spring Data JPA 更新实体时@Transactional 隔离级别不起作用? 【发布时间】:2021-01-02 04:41:01 【问题描述】:对于这个基于spring-boot-starter-data-jpa 依赖和H2 内存数据库的实验项目,我定义了一个带有两个字段(id 和firstName)的User 实体,并通过扩展声明了一个UsersRepository CrudRepository 接口。
现在,考虑一个提供两个端点的简单控制器:/print-user 读取同一个用户两次,间隔打印出其名字,/update-user 用于在两次读取之间更改用户的名字。请注意,我特意设置了Isolation.READ_COMMITTED 级别,并期望在第一个事务的过程中,通过相同 id 检索两次的用户将具有不同的名称。但相反,第一笔交易两次打印出相同的值。为了更清楚,这是完整的操作序列:
-
最初,
jeremy 的名字设置为 Jeremy。
然后我调用/print-user,它会打印出Jeremy 并进入睡眠状态。
接下来,我从另一个会话中调用 /update-user,它会将 jeremy 的名字更改为 Bob。
最后,当第一个事务在睡眠后被唤醒并重新读取jeremy 用户时,它再次打印出Jeremy 作为他的名字,即使名字已经更改为Bob(如果我们打开数据库控制台,它现在确实存储为Bob,而不是Jeremy)。
似乎设置隔离级别在这里没有效果,我很好奇为什么会这样。
@RestController
@RequestMapping
public class UsersController
private final UsersRepository usersRepository;
@Autowired
public UsersController(UsersRepository usersRepository)
this.usersRepository = usersRepository;
@GetMapping("/print-user")
@ResponseStatus(HttpStatus.OK)
@Transactional (isolation = Isolation.READ_COMMITTED)
public void printName() throws InterruptedException
User user1 = usersRepository.findById("jeremy");
System.out.println(user1.getFirstName());
// allow changing user's name from another
// session by calling /update-user endpoint
Thread.sleep(5000);
User user2 = usersRepository.findById("jeremy");
System.out.println(user2.getFirstName());
@GetMapping("/update-user")
@ResponseStatus(HttpStatus.OK)
@Transactional(isolation = Isolation.READ_COMMITTED)
public User changeName()
User user = usersRepository.findById("jeremy");
user.setFirstName("Bob");
return user;
【问题讨论】:
不应该findById(....)返回Optional<User>吗?
这里为了简单而省略了。
您可能尚未提交更新中的更改。您可能需要在设置后添加此行usersRepository.save(user)。
当一个方法是事务性的,那么在该事务中检索到的实体处于托管状态,这意味着对它们所做的所有更改都将在事务结束时自动填充到数据库中。因此,save() 调用是多余的。
findById 看起来不对,应该是 findByFirstName 吗?
【参考方案1】:
您的代码有两个问题。
您在同一事务中执行了两次usersRepository.findById("jeremy");,您的第二次读取可能是从Cache 检索记录。第二次读取记录时需要刷新缓存。我已经更新了使用entityManager 的代码,请检查如何使用JpaRepository 来完成
User user1 = usersRepository.findById("jeremy");
Thread.sleep(5000);
entityManager.refresh(user1);
User user2 = usersRepository.findById("jeremy");
这是我的测试用例的日志,请检查 SQL 查询:
第一次读取操作已完成。线程正在等待超时。触发对 Bob 的更新,它选择然后更新记录。休眠:选择 person0_.id 作为 id1_0_0_,person0_.city 作为 city2_0_0_,person0_.name 作为 name3_0_0_ from person person0_ where person0_.id=?
休眠:选择 person0_.id 作为 id1_0_0_,person0_.city 作为 city2_0_0_,person0_.name 作为 name3_0_0_ from person person0_ where person0_.id=?
现在线程从睡眠中唤醒并触发第二次读取。我看不到任何触发的数据库查询,即第二次读取来自缓存。Hibernate:更新人集 city=?, name=? id=?
第二个可能的问题是/update-user 端点处理程序逻辑。您正在更改用户的名称,但没有将其持久化,仅调用 setter 方法不会更新数据库。因此,当其他端点的 Thread 唤醒时,它会打印 Jeremy。
因此您需要在更改名称后致电userRepository.saveAndFlush(user)。
@GetMapping("/update-user")
@ResponseStatus(HttpStatus.OK)
@Transactional(isolation = Isolation.READ_COMMITTED)
public User changeName()
User user = usersRepository.findById("jeremy");
user.setFirstName("Bob");
userRepository.saveAndFlush(user); // call saveAndFlush
return user;
另外,您需要检查数据库是否支持所需的隔离级别。可以参考H2 Transaction Isolation Levels
【讨论】:
我试过了。即使在/update-user 事务结束时显式调用usersRepository.save(user),结果也是一样的。
save 不会提交您的数据。您应该使用saveAndFlush() 或从baeldung.com/spring-data-jpa-save-saveandflush 显式调用commit():当我们使用save() 方法时,与保存操作相关的数据将不会被刷新到数据库,除非并且直到显式调用flush()或 commit() 方法。
好的。我用JpaRepository 替换了CrudRepository 并添加了明确的usersRepository.saveAndFlush(user); - 没有任何改变
@escudero380 我已经更新了答案。在您的情况下,似乎第二次读取是从缓存中检索值。你需要刷新缓存。
@GoviS,是的。我刚刚通过构造函数注入EntityManager,并按照您所说的调用entityManager.refresh(user1, LockModeType.PESSIMISTIC_WRITE);。现在/print-user 交易按预期打印Jeremy 和Bob。【参考方案2】:
您更新@GetMapping("/update-user") 的方法设置为隔离级别@Transactional(isolation = Isolation.READ_COMMITTED),因此在此方法中永远不会达到commit() 步骤。
您必须更改隔离级别或读取事务中的值才能提交更改:)
user.setFirstName("Bob"); 不保证你的数据会被提交
线程摘要将如下所示:
A: Read => "Jeremy"
B: Write "Bob" (not committed)
A: Read => "Jeremy"
Commit B : "Bob"
// Now returning "Bob"
【讨论】:
对不起,我不认为我明白你的意思。那我应该使用哪个隔离级别?我通过显式调用存储库的save() 方法尝试了所有这些方法,然后从存储库中重新读取了值,但这并没有解决问题。
@escudero380 您应该允许printName() 使用此隔离级别READ_UNCOMMITTED 读取未提交的数据,或者显式调用flush() 或commit()。我已经在@GoviS 的帖子下解释了这一点。 save() 不提交数据...并且在 READ_COMMITTED 事务下无法检索未提交的数据(因为它只允许读取已提交的数据)。
另外,请考虑在您的控制器和存储库之间使用服务,因为您的实现不遵守关注点分离。您的存储库应该只处理数据并将其传输到服务,服务将调用存储库以提供答案,您的存储库应该只将数据转换为 db 的实体
根据您的建议,我尝试了两种技术:1)用READ_UNCOMMITTED 替换隔离级别,用于printName() 方法,但它没有改变任何东西; 2)然后,我将usersRepository.saveAndFlush(user) 添加到changeName() 方法,但它再次没有帮助。
我的评论不仅仅是关于服务层。这里的答案是“永远无法达到承诺”。在我看来,它已经达到了(好吧,当然是在数据库异常的情况下回滚)。以上是关于为什么要使用 transaction data?的主要内容,如果未能解决你的问题,请参考以下文章