REDIS01_概述安装key字符串String列表List集合SetHash哈希Zset有序集合持久化策略
Posted 所得皆惊喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了REDIS01_概述安装key字符串String列表List集合SetHash哈希Zset有序集合持久化策略相关的知识,希望对你有一定的参考价值。
文章目录
- ①. Redis - 概述
- ②. Redis - 安装
- ③. 常用五大数据类型
- ④. 字符串类型 - String
- ⑤. 列表类型 - list
- ⑥. 集合类型 - Set
- ⑦. 哈希类型 - hash
- ⑧. 有序集合类型 - Zset
- ⑨. 持久化 - AOF、RDB
- ⑩. REDIS - 事务
- ⑩①. REDIS - 监视测试
①. Redis - 概述
-
①. redis是一款高性能的开源NOSQL系列的非关系型数据库,Redis是用C语言开发的一个开源的高键值对(key value)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前Redis支持的键值数据类型如下:(字符串类型String、哈希类型hash、列表类型list、集合类型set、有序集合类型sortedset)
-
②. 缓存思想:从缓存中获取数据
有数据,直接返回
没有数据,从数据库查询,将数据放入缓存,返回数据
/**
* 加强补充,避免突然key实现了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class)
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null)
//4 查询mysql拿数据
user = userMapper.selectByPrimaryKey(id);//mysql有数据默认
if (user == null)
return null;
else
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
//setnx 不存在才创建
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
return user;
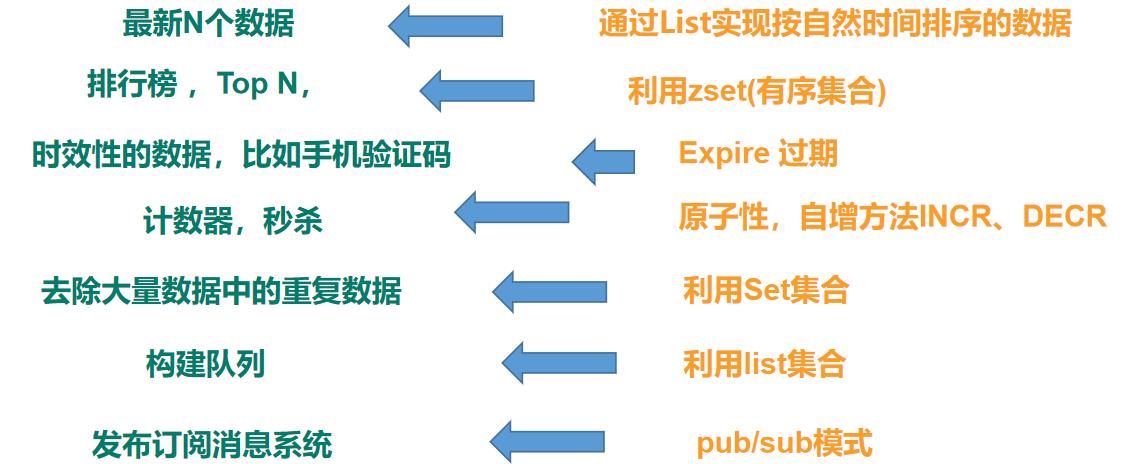
- ③. 使用场景
- 高频次,热门访问的数据,降低数据库IO
- 分布式架构,做session共享
- 多样的数据结构存储持久化数据
-
④. Redis默认端口6379的由来(Alessia Merz)

-
⑤. 默认16个数据库,类似数组下标从0开始,初始默认使用0号库
使用命令 select dbid来切换数据库。如: select 8
统一密码管理,所有库同样密码。
dbsize查看当前数据库的key的数量
flushdb清空当前库
flushall通杀全部库

-
⑥. redis常用的几个网址(建议收藏)
redis中文网址、redis英文网址、redis-linux下载、 redis命令中心、redis命令参考
②. Redis - 安装
-
①. Redis6.0.9安装
-
③. linux下Redis的目录信息
- redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何
- redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
- redis-check-dump:修复有问题的dump.rdb文件
- redis-sentinel:Redis集群使用
- redis-server:Redis服务器启动命令
- redis-cli:客户端,操作入口

③. 常用五大数据类型
-
②. 9大类型:String(字符类型)、Hash(散列类型)、List(列表类型)、Set(集合类型)、SortedSet(有序集合类型,简称zset)、Bitmap(位图)、HyperLogLog(统计)、GEO(地理)、Stream
Stream(了解即可)
(1). Redis Stream是Redis 5.0 版本新增加的数据结构
(2). Redis Stream主要用于消息队列(MQ,Message Queue),Redis本身是有一个Redis发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息就会被丢弃。简单来说发布订阅(pub/sub)可以分发消息,但无法记录历史消息
(3). 而Redis Stream提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。它算是redis自己消息功能的补充
(4). 但是,一般主流MQ都固定了(Kafka/RabbitMQ/RocketMQ/Pulsar),我们只用redis做缓存,不做mq消息的发送
-
③. 命令不区分大小写,而key是区分大小写的
help @类型名词 (string类型的命令查询:help @string) -
④. redis常用命令
| 命令 | 解释 |
|---|---|
| keys * | 查看当前库所有key (匹配:keys *1) |
| exists key | 判断某个key是否存在 |
| type key | 查看你的key是什么类型 |
| exists key | 判断某个key是否存在 |
| del key | 根据value选择非阻塞删除 |
| unlink key | 判断某个key是否存在 |
| 仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作 | |
| expire key 10 | 10秒钟:为给定的key设置过期时间(单位是s) |
| ttl key | 查看还有多少秒过期,-1表示永不过期,-2表示已过期 |
| select | 命令切换数据库 |
| dbsize | 查看当前数据库的key的数量 |
| flushdb | 清空当前库 |
| flushall | 通杀全部库 |
④. 字符串类型 - String
-
①. String是Redis最基本的类型,一个key对应一个value。
-
②. String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象
-
③. String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList -
④. 存储( set key value) 获取(get key) 删除(del key)
127.0.0.1:9736> keys *
(empty array)
127.0.0.1:9736> set name TANGZHI
OK
127.0.0.1:9736> get name
"TANGZHI"
127.0.0.1:9736> del name
(integer) 1
127.0.0.1:9736> get name
(nil)
- ⑤. 其他关于String的操作指令
| 指令 | 解释 |
|---|---|
| append key value | 将给定的value 追加到原值的末尾 |
| strlen key | 获得值的长度 |
| setnx key value | 只有在key不存在时,设置key的值(分布式锁) |
| incr key | 将 key 中储存的数字值增1,只能对数字值操作,如果为空,新增值为1 |
| decr key | 将 key 中储存的数字值减1,只能对数字值操作,如果为空,新增值为-1 |
| incrby / decrby key 步长 | 将key中储存的数字值增减。自定义步长 |
| mset key1 value1 key2 value2 | 同时设置一个或多个 key-value对 |
| mget key1 key2 key3 | 同时获取一个或多个value |
| msetnx key1 value1 key2 value2 | 同时设置一个或多个key-value,当且仅当所有给定key都不存在,才会执行成功 |
| getrange key 起始位置 结束位置 | 获得值的范围,类似java中的substring,前包,后包 |
| setrange key 起始位置 value | 用 value 覆写key所储存的字符串值,从起始位置开始(索引从0开始)。 |
| setex key 过期时间 value | 设置键值的同时,设置过期时间,单位秒 |
| getset key value | 以新换旧,设置了新值同时获得旧值 |
127.0.0.1:9736> set age 24
OK
127.0.0.1:9736> incr age
(integer) 25
127.0.0.1:9736> get age
"25"
127.0.0.1:9736> decr age
(integer) 24
127.0.0.1:9736> get age
"24"
127.0.0.1:9736> incrby age 10
(integer) 34
127.0.0.1:9736> decrby age 10
(integer) 24
127.0.0.1:9736> get age
"24"
-
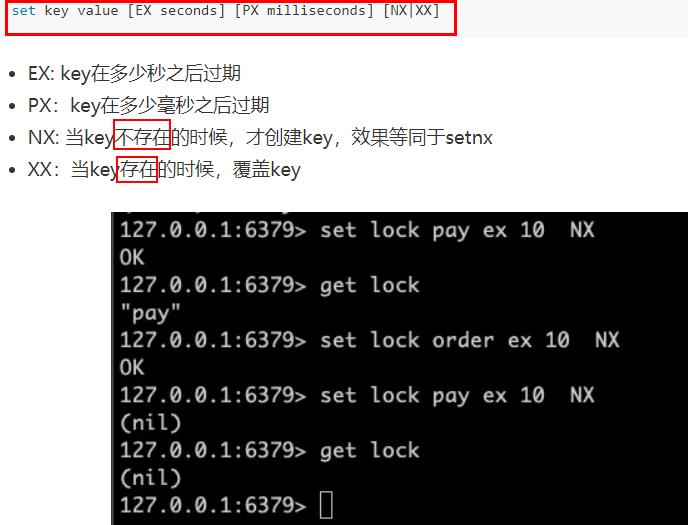
⑥. 分布式锁
setnx key value
set key value [EX seconds] [PX milliseconds] [NX|XX]
-
⑦. 应用场景一:比如抖音无限点赞某个视频或者商品,点一下加一次

-
⑧. 应用场景二:是否喜欢的文章(阅读数:只要点击了rest地址,直接可以使用incr key 命令增加一个数字1,完成记录数字)
public void likeArticle(String articleId)
String key = ARTICLE+articleId;
Long likeNumber = stringRedisTemplate.opsForValue().increment(key);
log.info("文章编号:,喜欢数:",key,likeNumber);
⑤. 列表类型 - list
- ①. 列表list是一个单键多值的
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差

- ②. 常用命令 插入、删除、获取
| 指令 | 解释 |
|---|---|
| lpush key value | 将元素加入列表左边 |
| rpush key value | 将元素加入列表右边 |
| lpop key | 删除列表最左边的元素,并将元素返回 |
| rpop key | 删除列表最右边的元素,并将元素返回 |
| lrang key start end(0 -1) | 按照索引下标获得元素(从左到右) |
| -1右边第一个,(0-1表示获取所有) | |
| rpoplpush key1 key2 | 从key1列表右边吐出一个值,插到key2列表左边 |
| lindex key index | 按照索引下标获得元素(从左到右) |
| llen key | 获得列表长度 |
127.0.0.1:9736> lpush mylist a
(integer) 1
127.0.0.1:9736> lpush mylist b
(integer) 2
127.0.0.1:9736> lpush mylist c
(integer) 3
127.0.0.1:9736> rpush mylist d
(integer) 4
127.0.0.1:9736> rpush mylist e
(integer) 5
127.0.0.1:9736> rpush mylist f
(integer) 6
127.0.0.1:9736> lrange mylist 0 -1
1) "c"
2) "b"
3) "a"
4) "d"
5) "e"
6) "f"
127.0.0.1:9736> rpop mylist
"f"
127.0.0.1:9736> lrange mylist 0 -1
1) "b"
2) "a"
3) "d"
4) "e"
127.0.0.1:9736>
- ③. List的数据结构为快速链表quickList
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存
当数据量比较多的时候才会改成quicklist

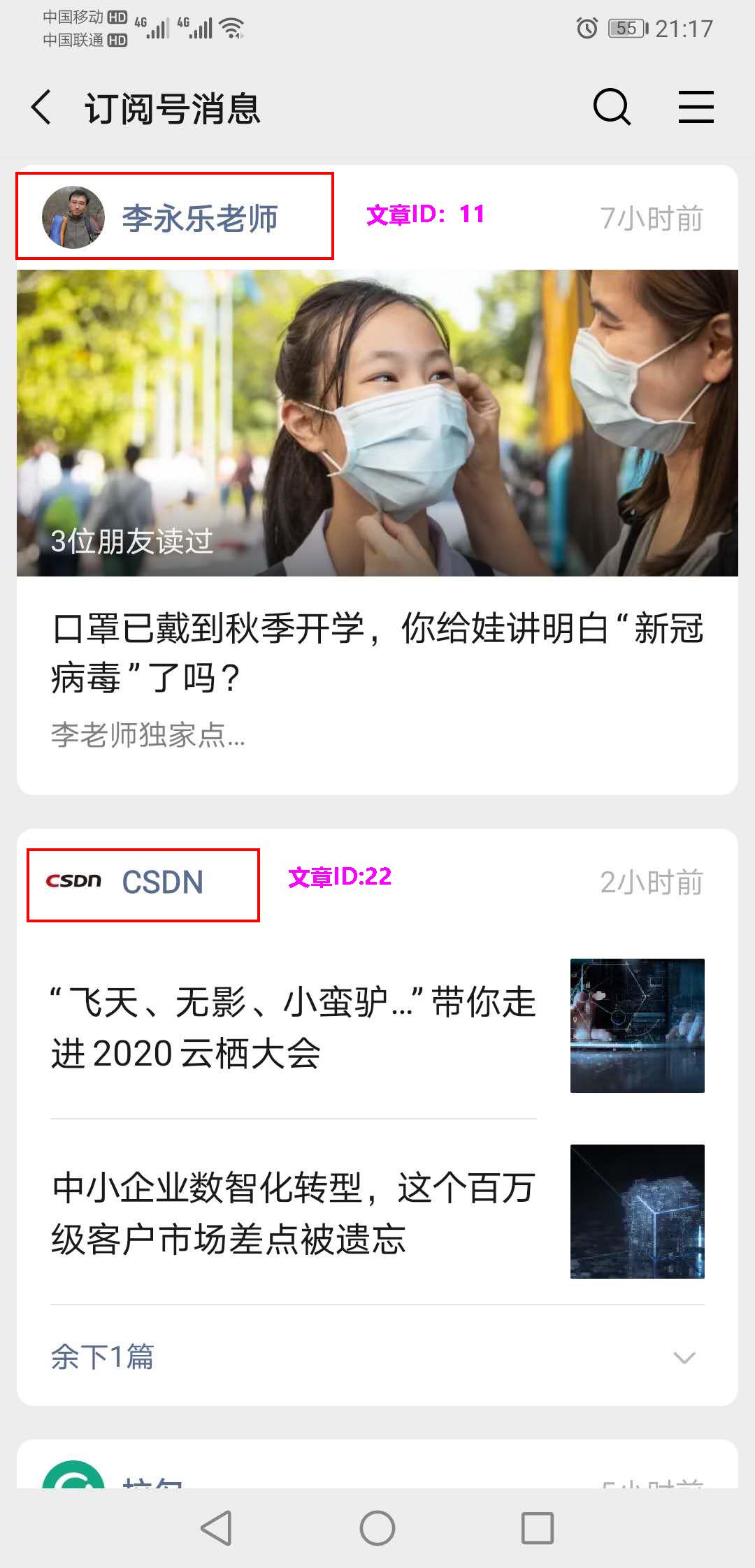
- ④. 微信公众号订阅的消息
1 大V作者李永乐老师和CSDN发布了文章分别是 11 和 22
2 小智关注了他们两个,只要他们发布了新文章,就会安装进我的List
lpush likearticle:小智id 11 22
3 查看小智自己的号订阅的全部文章,类似分页,下面0~10就是一次显示10条
lrange likearticle:小智id 0 9
⑥. 集合类型 - Set
-
①. set是可以自动排重的,不允许元素重复
Set数据结构是dict字典,字典是用哈希表实现的 -
②. 常用命令
| 指令 | 解释 |
|---|---|
| sadd key value1 value2 | 将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略 |
| smembers key | 取出该集合的所有值 |
| srem key value1 value2 … | 删除集合中的某个元素 |
| sismember keyvalue | 判断集合key是否为含有该value值,有1,没有0 |
| scard key | 返回该集合的元素个数 |
| spop key | 随机从该集合中吐出一个值 |
| srandmember key n | 随机从该集合中取出n个值。不会从集合中删除 |
| smove source destination value | 把集合中一个值从一个集合移动到另一个集合 |
| sinter key1 key2 | 返回两个集合的交集元素 |
| sunion key1 key2 | 返回两个集合的并集元素 |
| sdiff key1 key2 | 返回两个集合的差集元素(key1中的,不包含key2中的) |
127.0.0.1:9736> sadd myset a
(integer) 1
127.0.0.1:9736> sadd myset a
(integer) 0
127.0.0.1:9736> smembers myset
1) "a"
127.0.0.1:9736> srem myset a
(integer) 1
127.0.0.1:9736> smembers myset
(empty array)
127.0.0.1:9736> keys *
(empty array)
127.0.0.1:9736>
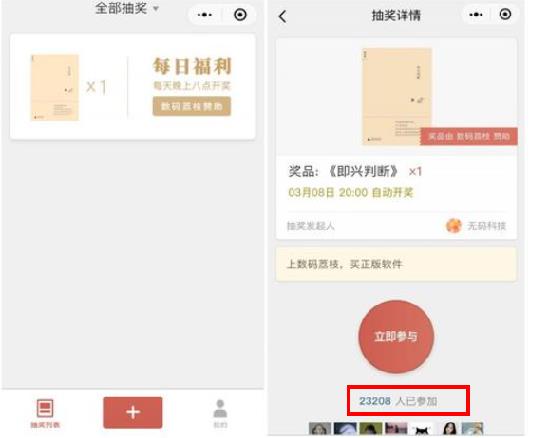
- ③. 应用场景一:微信抽奖小程序

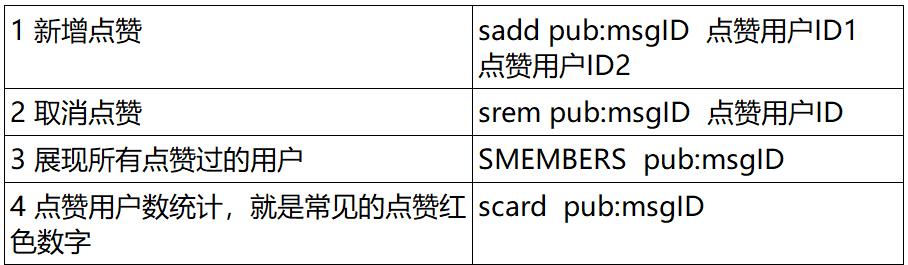
- ④. 应用场景二:微信朋友圈点赞

- ⑤. 应用场景三:微博好友关注社交关系
(共同关注的人)


 QQ内推可能认识的人
QQ内推可能认识的人

⑦. 哈希类型 - hash
-
①. Hash类型对应的数据结构是两种: ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable (Map<String,Map<Object,Obje ct>>)
-
②. 常用命令
| 指令 | 解释 |
|---|---|
| HSET key field value | 一次设置一个字段值 |
| HGET key field | 一次获取一个字段值 |
| hgetall key | 获取所有字段值 |
| hdel | 删除一个key |
| HMSET key field value [field value …] | 一次设置多个字段值 |
| HMGET key field [field …] | 一次获取多个字段值 |
| hlen | 获取某个key内的全部数量 |
| hkeys key | 列出该hash集合的所有field |
| hvals key | 列出该hash集合的所有value |
| hincrby key field increment | 为哈希表 key 中的域field的值加上增量 1 -1 |
| hsetnx key field value | 将哈希表 key 中的域field的值设置为value,当且仅当域field不存在 |
127.0.0.1:9736> hset myUser username TANGZHI
(integer) 1
127.0.0.1:9736> hset myUser password 123456
(integer) 1
127.0.0.1:9736> hget myUser username
"TANGZHI"
127.0.0.1:9736> hget myUser password
"123456"
127.0.0.1:9736> hgetall myUser
1) "username"
2) "TANGZHI"
3) "password"
4) "123456"
127.0.0.1:9736> hdel myUser username
(integer) 1
127.0.0.1:9736> hgetall myUser
1) "password"
2) "123456"
127.0.0.1:9736>
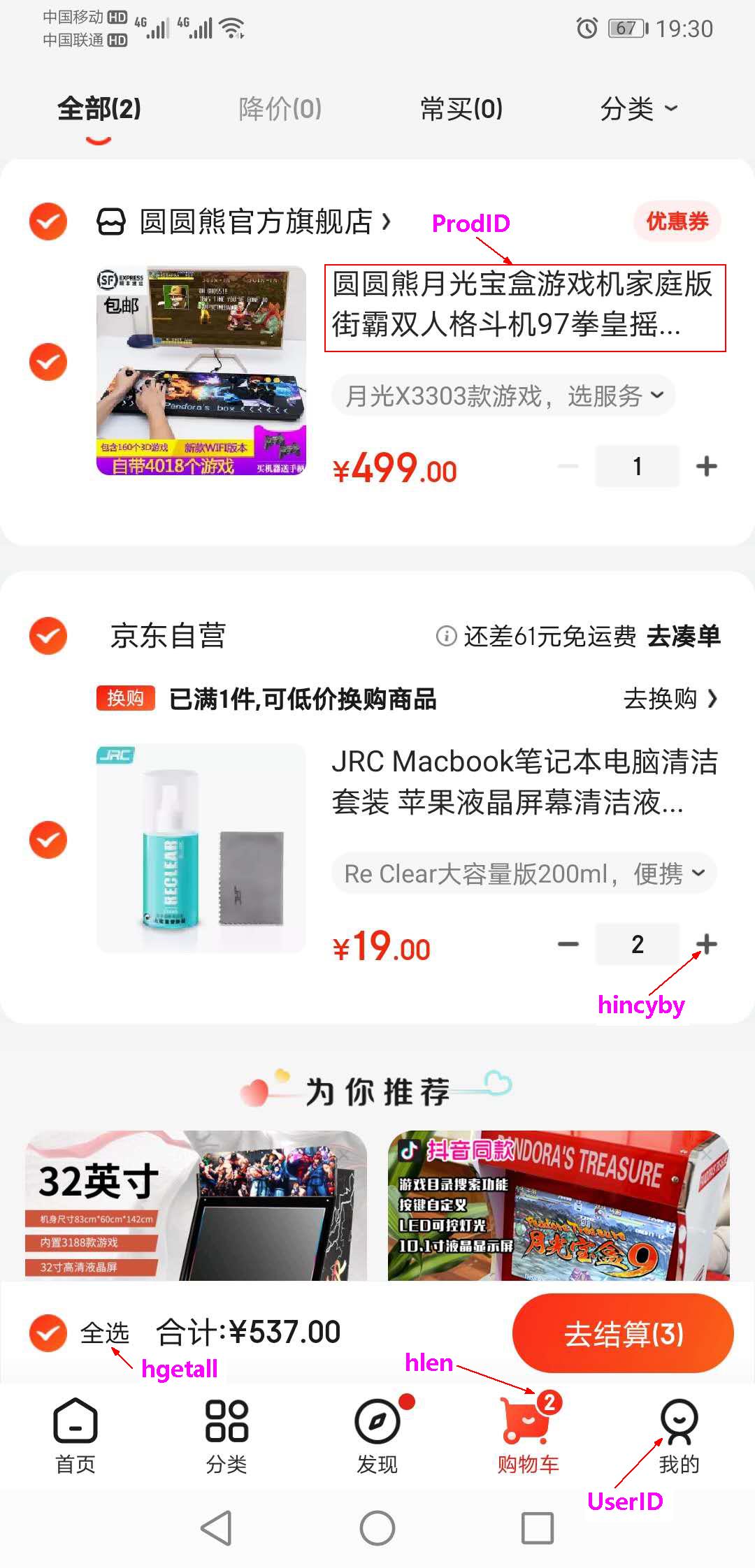
- ③. 应用场景:购物车模块
新增商品 → hset shopcar:uid1024 334488 1
新增商品 → hset shopcar:uid1024 334477 1
增加商品数量 → hincrby shopcar:uid1024 334477 1
商品总数 → hlen shopcar:uid1024
全部选择 → hgetall shopcar:uid1024
⑧. 有序集合类型 - Zset
-
①.Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了
-
②. 常用命令
| 指令 | 解释 |
|---|---|
| zadd key score1 value1 score2 value2… | 将一个或多个member元素及其score值加入到有序集key当中 |
| zrange key start stop[WITHSCORES] | 返回有序集key中,下标在startstop之间的元素 |
| 带WITHSCORES,可以让分数一起和值返回到结果集 | |
| zrem key value | 删除该集合下,指定值的元素 |
| zrangebyscore key min max[withscores][limitoffsetcount] | 返回有序集key中,所有score值介于min和max之间(包括等于min或max)的成员。有序集成员按score值递增(从小到大)次序排列 |
| zrevrangebyscore key max min[withscores][limitoffsetcount] | 同上,改为从大到小排列 |
| zincrby key increment value | 为元素的score加上增量 |
| zcount key min max | 统计该集合,分数区间内的元素个数 |
| zrank key value | 返回该值在集合中的排名,从0开始 |
127.0.0.1:9736> zadd myzset 1 mysql
(integer) 1
127.0.0.1:9736> zadd myzset 2 redis
(integer) 1
127.0.0.1:9736> zadd myzset 3 java
(integer) 1
127.0.0.1:9736> zadd myzset 3 spring
(integer) 1
127.0.0.1:9736> zrange myzset 0 -1
1) "mysql"
2) "redis"
3) "java"
4) "spring"
127.0.0.1:9736> zrem myzset spring
(integer) 1
127.0.0.1:9736> zrange myzset 0 -1
1) "mysql"
2) "redis"
3) "java"
127.0.0.1:9736>
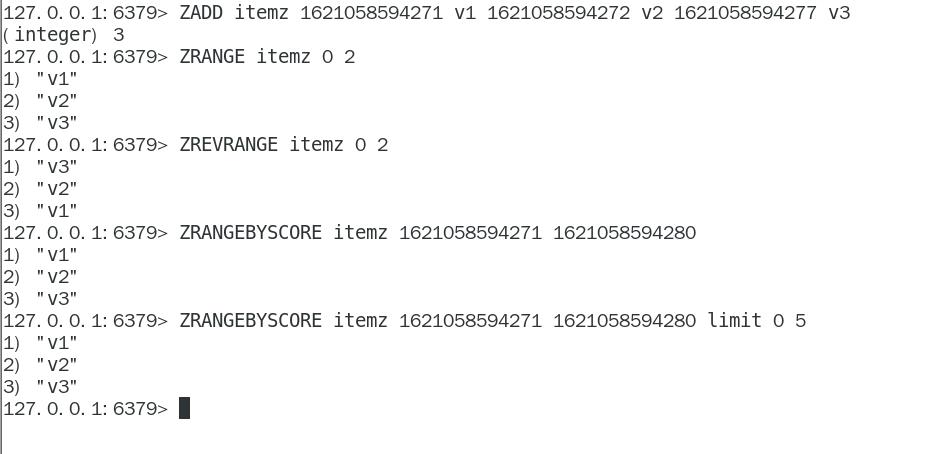
- ③. 如何利用zset实现一个文章访问量的排行榜?
127.0.0.1:9736> zrange tops 0 -1 withscores
1) "java"
2) "100"
3) "mysql"
4) "200"
127.0.0.1:9736> zrevrangebyscore tops 300 100
1) "mysql"
2) "java"
127.0.0.1:9736> zrevrange tops 0 -1
1) "mysql"
2) "java"
-
④. 根据商品销售对商品进行排序显示
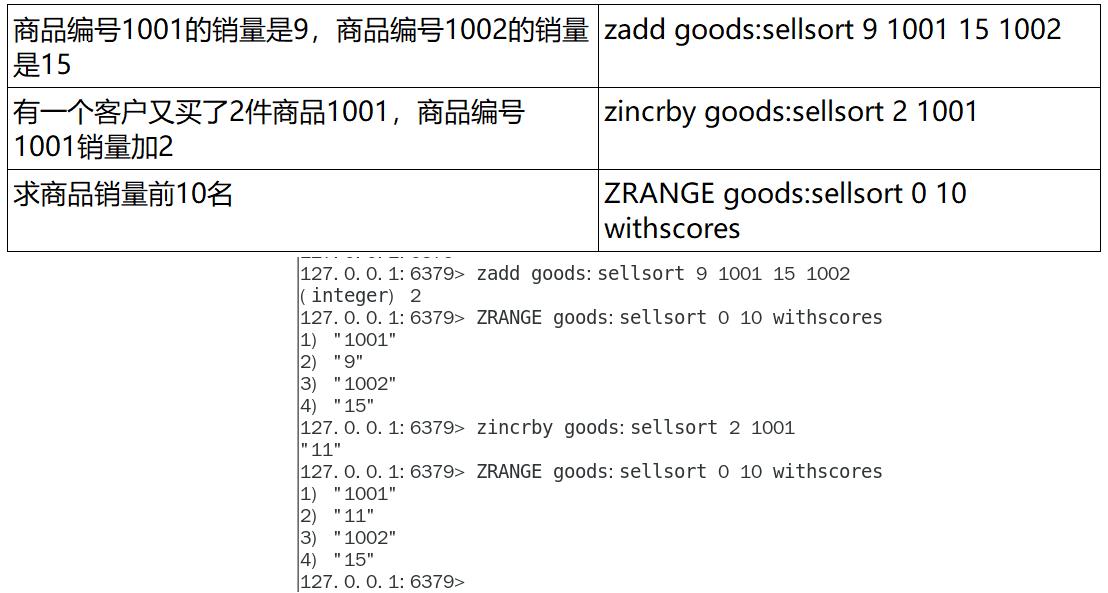
-
⑤. 抖音热搜

⑨. 持久化 - AOF、RDB
- ①. redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中
- Redis持久化策略有哪些?(RDB、AOF)
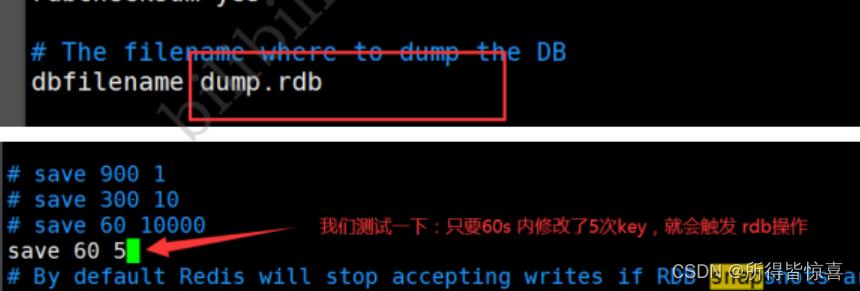
- Rdb:定时将数据保存在硬盘中(dump.rdb)
- Aof:保存所有操作的命令
- ②. RDB - 持久化机制默认
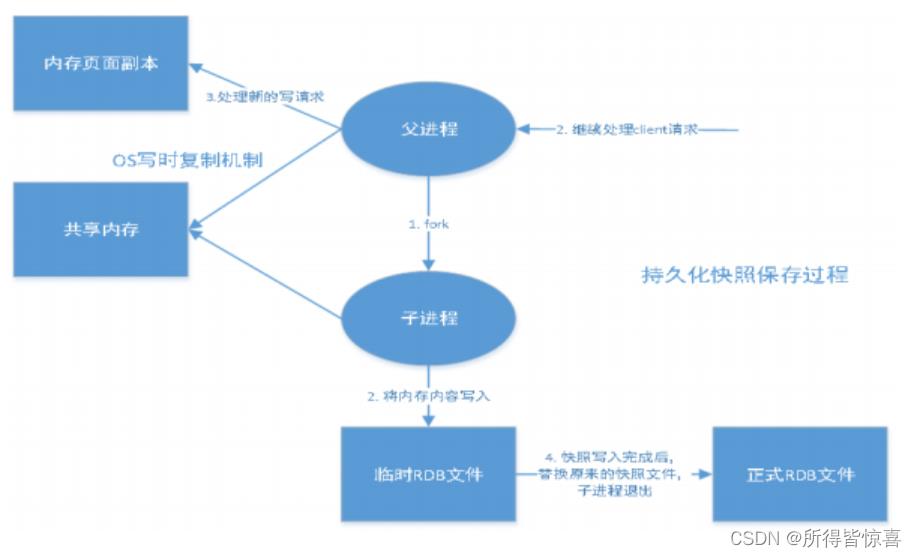
- 在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
- Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。我们默认的就是RDB,一般情况下不需要修改这个配置
- rdb保存的文件是dump.rdb都是在我们的配置文件中快照中进行配置的!
- ③. RDB - 触发机制
- save的规则满足的情况下,会自动触发rdb规则
- 执行 flushall 命令,也会触发我们的rdb规则!
- 退出redis,也会产生 rdb 文件!
- ④. 如果恢复rdb文件!
- 只需要将rdb文件放在我们redis启动目录就可以,redis启动的时候会自动检查dump.rdb 恢复其中的数据!
- 查看需要存在的位置
127.0.0.1:6379> config get dir
1) "dir"
2) "/data"
- ⑤. RDB的优缺点:
- 优点:适合大规模的数据恢复!对数据的完整性要不高
- 缺点:需要一定的时间间隔进程操作!如果redis意外宕机了,这个最后一次修改数据就没有的了!fork进程的时候,会占用一定的内容空间
- ⑥. AOF保存的是 appendonly.aof 文件
- 默认是不开启的,我们需要手动进行配置!我们只需要将 appendonly 改为yes就开启了 aof!重启,redis就可以生效了!
- aof默认就是文件的无限追加,文件会越来越大!如果aof文件大于 64m,太大了! fork一个新的进程来将我们的文件进行重写!
appendonly no # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分所有的情况下,
rdb完全够用!
appendfilename "appendonly.aof" # 持久化的文件的名字
# appendfsync always # 每次修改都会 sync。消耗性能
appendfsync everysec # 每秒执行一次 sync,可能会丢失这1s的数据!
# appendfsync no # 不执行 sync,这个时候操作系统自己同步数据,速度最快!
# rewrite 重写
- ⑦. AOF - 优点:
- 每一次修改都同步,文件的完整会更加好!
- 每秒同步一次,可能会丢失一秒的数据
- 从不同步,效率最高的!
- ⑧. RBD - 缺点:
- 相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢!
- Aof运行效率也要比rdb慢,所以我们redis默认的配置就是rdb持久化
⑩. REDIS - 事务
-
①. Redis单条命令保持原子性,但是Redis事务不保证原子性
原子性: 要么都成功,要么都失败 -
③. Redis事务的三个特性:一致性,顺序性,排他性
| 关键字 | 命令 | 作用 |
|---|---|---|
| multi | MULTI | 开启事务 |
| exec | EXEC | 执行事务 |
| discard | DISCARD | 关闭事务(放弃事务) |
- ④. 正常执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name tangzhi
QUEUED
127.0.0.1:6379> get name
QUEUED
127.0.0.1:6379> set age 26
QUEUED
127.0.0.1:6379> exec
1) OK
2) "tangzhi"
3) OK
127.0.0.1:6379>
- ⑤. 放弃事务
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set age 23
QUEUED
127.0.0.1:6379> append age 15
QUEUED
127.0.0.1:6379> get age
QUEUED
127.0.0.1:6379> discard # 放弃事务
OK
# 一旦放弃事务,之前入队的全部命令都不会执行
(nil)
127.0.0.1:6379> get age # 无结果
(nil)
- ⑥. 编译型异常(又叫入队错误)的特点:事务中有错误的命令,会导致默认放弃事务,所有的命令都不会执行
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set name zs
QUEUED
127.0.0.1:6379> append name2 # 错误的命令
ERR wrong number of arguments for 'append' command
127.0.0.1:6379> get name
QUEUED
127.0.0.1:6379> EXEC # 执行事务,出现编译型异常
EXECABORT Transaction discarded because of previous errors.
- ⑦. 运行时异常(又叫执行错误):在事务执行的过程中语法没有出现任何问题,但是它对不同类型的key执行了错误的操作,Redis只会将返回的报错信息包含在执行事务的结果中,并不会影响Redis事务的一致性
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name tangzhi
QUEUED
127.0.0.1:6379> incr name # 语法正确,但是对一个String类型的k1执行了错误的操作
QUEUED
127.0.0.1:6379> get name
QUEUED
127.0.0.1:6379> exec # 执行事务,出现运行时异常
OK # 执行ok
ERR value is not an integer or out of range # 命令报错,但是不影响事务整体的运行
tangzhi# 依旧执行
⑩①. REDIS - 监视测试
-
①. 悲观锁:很悲观,无论执行什么操作都会出现问题,所以会
以上是关于REDIS01_概述安装key字符串String列表List集合SetHash哈希Zset有序集合持久化策略的主要内容,如果未能解决你的问题,请参考以下文章