Elastic Search 浅浅认识 快速使用 keyword 和 text 的区别之处 spring boot 集成案例 es 增删改查
Posted T_Antry
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elastic Search 浅浅认识 快速使用 keyword 和 text 的区别之处 spring boot 集成案例 es 增删改查相关的知识,希望对你有一定的参考价值。
很早就想写,严重拖延症,好在出品了。不完善,后续再补充。
文章目录
前言
____________. ___. .__ __. .____________. .________ .___ ___.
|████████████| / \\ | \\ | | |████████████| | ___ \\ \\ \\ / /
| | / /\\ \\ | \\ | | | | | | ) | \\ \\ / /
| | / /__\\ \\ | . \\| | | | | |___/ / \\ \\/ /
| | / ______ \\ | |\\ ` | | | | ___ < \\ /
| | .____________. | | | | | | \\ | | | | | \\ \\ | |
|__| |████████████| /__/ \\__\\ |__| \\__| |__| |__| \\__\\ |__|
最近项目使用了 elastic search ,为了更好地认识这个组件,同时也是想记录部分笔记,采用了撰写博客的方式推动由浅入深的学习。本系列并不能解决所有使用遇到的问题,主要是为了学会在使用的过程中思考和解决遇到的问题,分享一些我遇到且注意到的内容,同时结交一群志同道合的朋友,我觉得这是一件有意义的事情。
喜欢可收藏,现在比较懒了,佛系出品。
什么是ES,为何使用ES?
es 课先理解为一种数据库,kibana是es引擎的一个可视化平台
部分加粗的字体都是后续章节需要挖掘的内容。
它是一个 分布式、高扩展、高实时 的 搜索 与数据分析 引擎 。它能很方便地使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
Elasticsearch 的 实现原理 主要分为以下几个步骤:
- 首先用户将数据提交到Elasticsearch 数据库中
- 再通过分词控制器去将对应的语句 分词
- 将其 权重 和 分词 结果 一并存入数据
- 当用户搜索数据时候,再根据权重将结果排名,打分
- 再将返回结果呈现给用户
Elasticsearch 是一个企业级海量数据的搜索引擎,提供了全文搜索的功能,适用于电商商品搜索、App搜索、企业内部信息搜索、IT系统搜索等。
如果你没有环境,请安装一个先吧,我始终相信实践才能够带来更为深刻的认知,踏出第一步安装。
es&kibana 安装教程 安装的部分,网上教程很多了。
dev tools 使用
上kibana感受一下,这其实就是发送CURL 命令的工具,例如要查看es版本,只要访问根路径就可以了。

既然是get请求,在浏览器的地址栏访问跟路径也可以达到同样的效果
http://localhost:9200 //localhost为安装es的主机ip port 默认9200 如有更改需要调整

如果有配置账号密码的
http://账号:密码@localhost:9200
索引
创建索引
es的索引可以理解为数据库的表
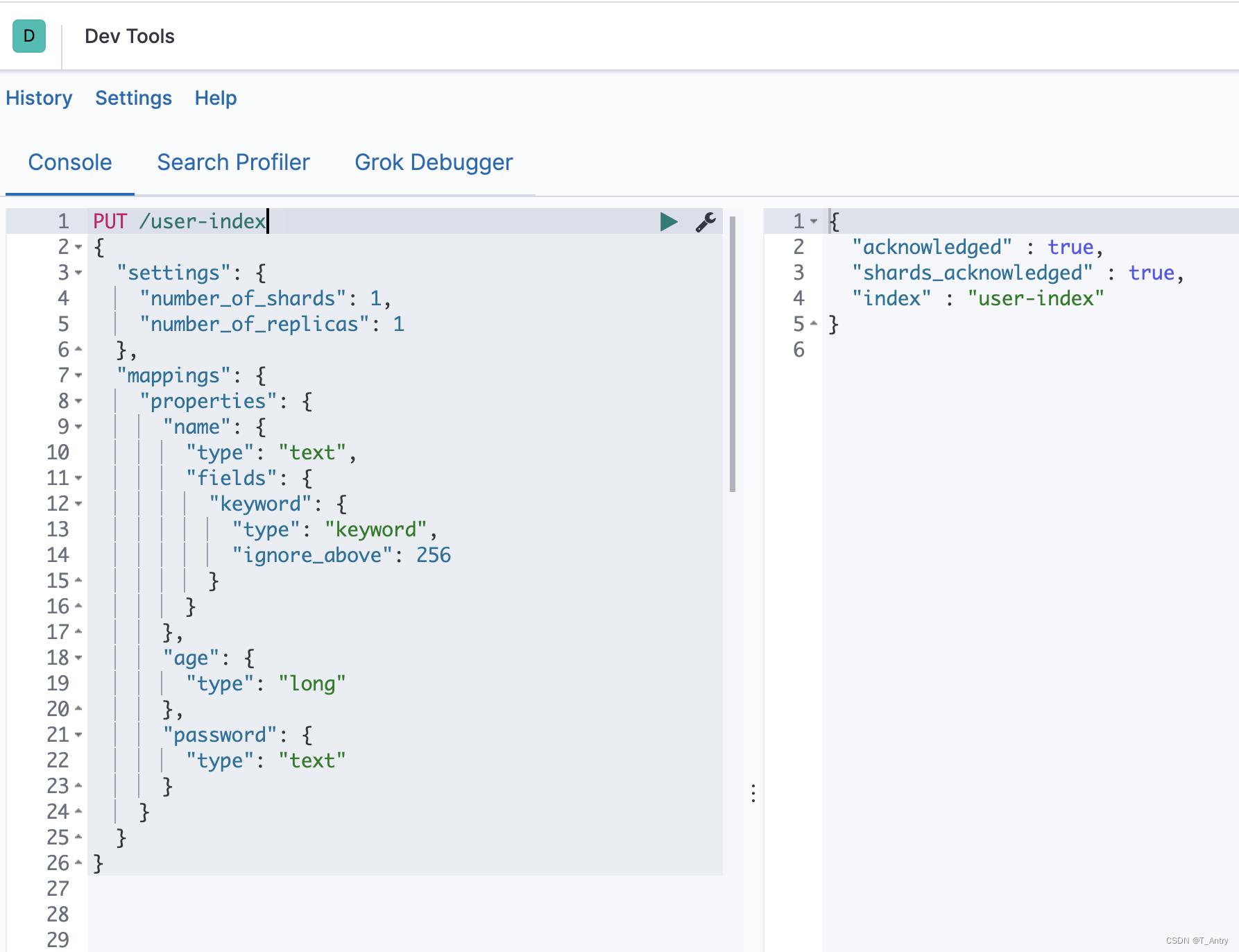
创建一个user 索引user-index,其中包含三个属性:name,age , password。
PUT /user-index
"settings":
"number_of_shards": 1,
"number_of_replicas": 1
,
"mappings":
"properties":
"name":
"type": "text",
"fields":
"keyword":
"type": "keyword",
"ignore_above": 256
,
"age":
"type": "long"
,
"password":
"type": "text"
setting 部分可以配置属性,属性分为两种
索引的配置项按是否可以更改分为静态属性与动态属性,所谓的静态配置即索引创建后不能修改。
| 静态配置项 | 作用 | 其他 |
|---|---|---|
| index.number_of_shards | 索引分片的数量 | 默认值5,ES支持的最大分片数默认为1024 |
| index.shard.check_on_startup | 分片在打开之前是否检查该分片是否损坏,当检测到分片损坏时,将阻止打开。 | 可选值:(默认值):false:不检测 checksum:只检查物理结构 true:检查物理结构和路基损坏,相对比较消耗CPU |
| ndex.codec | 数据存储的压缩算法 | 默认值LZ4,可选值best_compression,比LZ4可以获得更好的压缩比例(占用较小的磁盘空间,但是存储性能比LZ4低)。 |
| index.routing_partition_size | 路由分区数 | 如果设置了该参数,其路由算法为:(hash(_routing) + hash(_id) % index.routing_parttion_size ) % number_of_shards 如果没有设置,路由算法为:hash(_routing) % number_of_shardings _routing默认值为 _id |
ES中分片是用来解决节点容量上限问题,通过主分片,可以将数据分布到集群的所有节点,作为测试用例,无需考虑这些问题配1足矣。
| 静态配置项 | 作用 | 其他 |
|---|---|---|
| index.number_of_replicas | 索引复制分片的个数 | 默认值1,一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。 |
| index.auto_expand_replicas | 基于可用节点的数量自动分配副本数量 | 默认为 false(即禁用此功能),可设置为:0-all |
| index.refresh_interval | 执行刷新操作的频率,该操作可以对索引的最新更改对搜索可见 | 默认1s。可以设置-1禁止刷新 |
| index.max_result_window | 控制分页搜索的总记录数 | from+size的大小不能超过该值,默认为10000 |
| index.max_inner_result_window | 用于控制top aggregations | 默认100。内部命中和顶部命中聚合占用堆内存,并且时间与from+size成正比,这限制了内存 |
| 还有… | 配置的参数查看文档吧… | 这个部分其实不只是几个字这么简单,后面应该单独拿出来研究… |
成功创建在dev tools右侧能够看到响应。
通过
GET /user-index
查看索引的信息
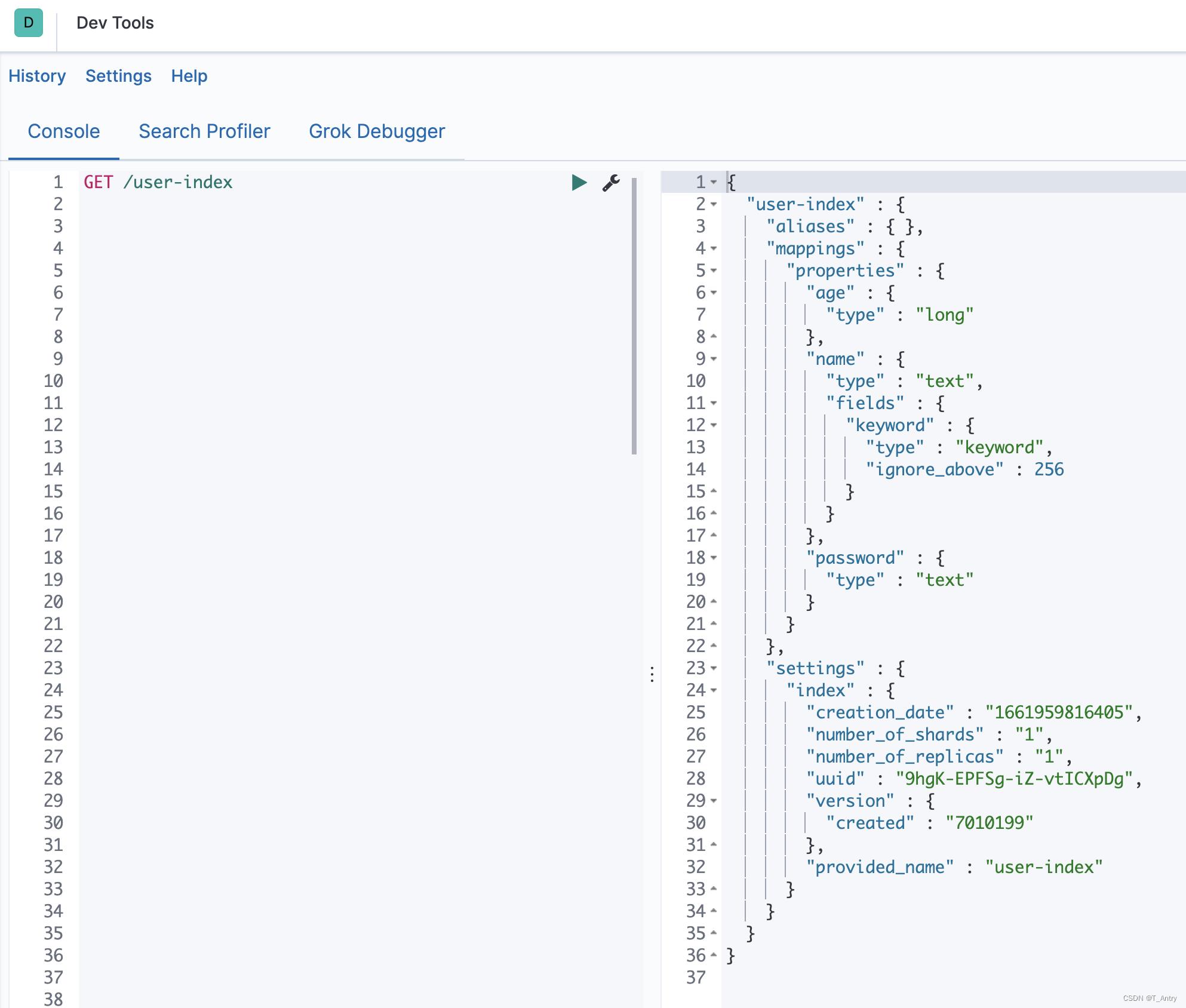
其中 aliases 是别名,别名的作用是,支持通过别名对索引进行查询,由于创建索引的时候没有配置别名,因此别名是空的。 mapping 是配置各个字段的数据类型,具体类型有哪些,一切以官方为准。
官方数据类型说明 官方文档非常全,百度翻译也很好。
不同: 相比数据库,新增数据时允许含没有预先配置的字段类型,甚至在创建索引时,不做任何配置。如:
PUT /user-index
删除索引
使用的时候就不要删除了,如已删除,请重新创建索引
DELETE /user-index
增删改查
新增/修改
POST /索引/类型/ID
类型默认为_doc
id不给的话能够默认生成
可见多写了个money字段,依然能够插入成功,应证了上面所介绍同数据库的不同。
POST /user-index/_doc/1
"name": "Antry",
"age": 44,
"pasword":"antry44",
"money":1000000000
给定id的方式,如果id已经存在,就会修改该条数据。
查询
GET /user-index/_search
查询结果
"took" : 0,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 1,
"relation" : "eq"
,
"max_score" : 1.0,
"hits" : [
"_index" : "user-index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" :
"name" : "Antry",
"age" : 44,
"pasword" : "antry44",
"money" : 1000000000
]
返回时有其他参数,这些参数很有意义,了解这些参数能够让我们进一步理解它的特性
| 参数 | 说明 |
|---|---|
| took | 表示整个搜索请求花费了多少毫秒 |
| hits.total | 本次搜索,返回了几条结果 |
| hits.max_score | 本次搜索的所有结果中,最大的相关度分数是多少。每一条document对于search的相关度,越相关,_score分数越大,排位越靠前。(计算这些分数是es的强大之一) |
| hits.hits | 默认查询出前10条数据,完整数据,_score降序排序 |
| timeout | 默认无timeout,latency平衡completeness,手动指定timeout,timeout查询执行机制 |
由于新增时多给了money字段,再次查询一下mapping
GET /user-index/_mapping
结果
"user-index" :
"mappings" :
"properties" :
"age" :
"type" : "long"
,
"money" :
"type" : "long"
,
"name" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
,
"password" :
"type" : "text"
多了个money的字段,且自动识别为long类型
查询当然还有条件查询,有很多特性,还要后面详细介绍
删除
DELETE 索引/类型/ID
DELETE user-index/_doc/1
同样删除也是有条件删除
spring boot 集成
这里使用的客户端是RestHighLevelClient
pom
要注意的是版本一定要和安装的es版本相同
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.1.0</version>
<scope>compile</scope>
</dependency>
yml
地址 端口 账号 密码这些信息一般不写死在配置类中,因为不同的环境,参数也不同
elasticSearch:
hosts: localhost
user: elastic
password: elastic
配置类
将RestHighLevelClient 注入ioc
@Configuration
public class ElasticSearchClient
@Value("$elasticSearch.hosts")
private String hosts;
@Value("$elasticSearch.user")
private String userName;
@Value("$elasticSearch.password")
private String password;
@SuppressWarnings("deprecation")
@Bean
public RestHighLevelClient getClient()
String[] hosts = this.hosts.split(",");
HttpHost[] httpHosts = new HttpHost[hosts.length];
for(int i=0;i<hosts.length;i++)
httpHosts[i] = new HttpHost(hosts[i], 9200, "http");
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));
RestClientBuilder builder = RestClient.builder(httpHosts).setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback()
@Override
public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder)
requestConfigBuilder.setConnectTimeout(-1);
requestConfigBuilder.setSocketTimeout(-1);
requestConfigBuilder.setConnectionRequestTimeout(-1);
return requestConfigBuilder;
).setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback()
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder)
httpClientBuilder.disableAuthCaching();
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
);
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
测试类
/**
* @author T_Antry
* @date 2022-09-01 19:35
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class ESTest
@Autowired
private RestHighLevelClient restHighLevelClient;
创建索引
//创建索引
@Test
public void testCreateIndex() throws IOException
CreateIndexRequest createIndexRequest = new CreateIndexRequest("java-user-index");
CreateIndexResponse response = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
删除索引
/**
* 删除索引
*/
@Test
public void deleteIndex() throws IOException
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("java-user-index");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
索引是否存在
/**
* 索引是否存在
*/
@Test
public void testIsExist() throws IOException
GetRequest getRequest = new GetRequest("java-user-index", "1");
//不获取返回的source的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
新增数据
/**
*
* 新增数据
* @throws IOException
*/
@Test
public void createDocument() throws IOException
Map<String,Object> map = new HashMap<>();
map.put("name","T_Antry");
map.put("age",18);
map.put("password","123455Antry");
IndexRequest request = new IndexRequest("java-user-index");
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
//将我们的数据放入请求,json
request.source(JSON.toJSONString(map), XContentType.JSON);
//客服端发送请求
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
//对应我们的命令返回状态
System.out.println(response.status());
批量新增Bulk
在新增数量非常大的情况下,每次新增都发起一次请求是需要大量连接的
因此es同样提供了bulk批量新增的功能,bulk的使用在大数据的场景更多。可以配置n条提交一次,或者一定时间提交一次,等多种可配条件。
/**
* 批量插入数据
* @throws IOException
*/
@Test
public void testBulkRequest() throws IOException
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
for (int i = 0; i < 100; i++)
Map map = new HashMap<>();
map.put("name","T_Antry"+i);
map.put("age",i);
map.put("password","Antry888888-"+i);
bulkRequest.add(
new IndexRequest("java-user-index")
.id("" + i + 1)
.source(JSON.toJSONString(map), XContentType.JSON)
);
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk.status());
查询
/**
*
* 查询
* @throws IOException
*/
@Test
public void testGetDocument() throws IOException
GetRequest getRequest = new GetRequest("java-user-index", "1");
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//打印文档信息
System.out.println(response.getSourceAsString());
分页查询
/**
* 分页查询
* @throws IOException
*/
@Test
public void testPageRequest() throws IOException
SearchRequest searchRequest = new SearchRequest("java-user-index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(0);
sourceBuilder.size(10);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
for (SearchHit hit : search.getHits().getHits())
System.out.println(hit.getSourceAsMap());
条件查询
查询条件是id为1
/**
* 条件查询
* @throws IOException
*/
@Test
public void testCondRequest() throws IOException
SearchRequest searchRequest = new SearchRequest("java-user-index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("_id","1");
sourceBuilder.query(termQueryBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
for (SearchHit hit : search.getHits().getHits())
System.out.println(hit.getSourceAsMap());
我想有的朋友肯定还会尝试修改条件为name,password等
就会发现有查询不到的情况,这是因为创建索引时,没有指定对应字段为keyword的原因。keyword类型不分词,text类型分词。
Keyword类型
对于keyword类型,由于Elasticsearch不会使用分析器对其进行分析,所以你输入什么文本,索引就会按照原样进行保存。下图为文本在倒排索引中存储的样子。
假设数据为T_Antry
| Term | count | Document |
|---|---|---|
| T_Antry | 1 | example |
Text类型
对于text类型,Elasticsearch会先使用分析器对文本进行分析,再存储到倒排索引中。Elasticsearch默认使用标准分析器(standard analyzer),先对文本分词再转化为小写。
标准分析器对文本进行分析后的结果
假设数据为Antry888888-1
| Term | count | Document |
|---|---|---|
| antry888888 | 1 | example |
| 1 | 1 | example |
这个结果并不是我瞎写的,是有依据的
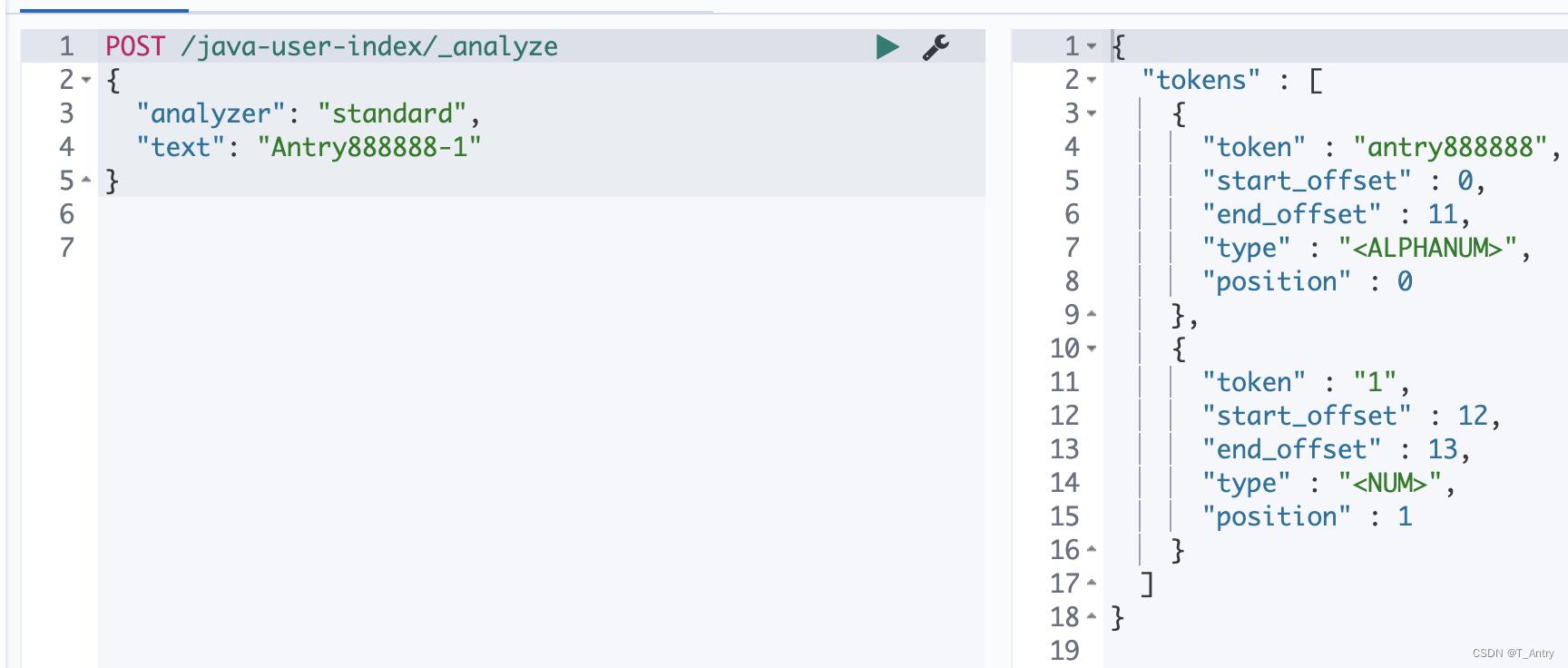
从上面的结果,可以看出,在使用text的时候,由于被分词,特殊符号“-”似乎丢失,所以通过“Antry888888-1”去查询password字段时,什么都查不到,这个时候用antry888888却可以查到。
mapping的修改
- 索引创建之后,mapping中已经存在的字段不可以修改其定义
- 新增字段是可以的
如果一定要修改,百度一下,网友很强大。
全文检索
对所有字段进行搜索
/**
* 全文检索
* @throws IOException
*/
@Test
public void testCondRequest() throws IOException
SearchRequest searchRequest = new SearchRequest("java-user-index");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery("Antry1");
sourceBuilder.query(queryStringQueryBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
for (SearchHit hit : search.getHits().getHits())
System.out.println(hit.getSourceAsMap());
es的查询功能非常强大,模糊,分组等等。
修改
/**
*
* 修改
* @throws IOException
*/
@Test
public void testUpdateDocument() throws IOException
UpdateRequest request = new UpdateRequest("java-user-index", "1");
request.timeout("1s");
Map<String,Object> map = new HashMap<>();
map.put("name","T_Antry");
map.put("age",18);
map.put("password","Antry123456");
request.doc(JSON.toJSONString(map),XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println(update.status());
删除
/**
*
* 删除文档
* @throws IOException
*/
@Test
public void testDeleteDocument() throws IOException
DeleteRequest request = new DeleteRequest("java-user-index", "1");
request.timeout("10s");
DeleteResponse update = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(update.status());
结束语
以上就是本期对 elastic search 的学习,喜欢就点个关注吧。
以上是关于Elastic Search 浅浅认识 快速使用 keyword 和 text 的区别之处 spring boot 集成案例 es 增删改查的主要内容,如果未能解决你的问题,请参考以下文章