Linux C/C++并发编程实战2万字解读C/C++ 6种内存时序memory_order(内存屏障)指令重排原子操作
Posted 奇妙之二进制
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux C/C++并发编程实战2万字解读C/C++ 6种内存时序memory_order(内存屏障)指令重排原子操作相关的知识,希望对你有一定的参考价值。
背景知识:cpu缓存,缓存一致性协议。
文章目录
接口预览
#include <stdatomic.h>
_Bool atomic_compare_exchange_strong( volatile A* obj,
C* expected, C desired ); (1) (since C11)
_Bool atomic_compare_exchange_weak( volatile A *obj,
C* expected, C desired ); (2) (since C11)
_Bool atomic_compare_exchange_strong_explicit( volatile A* obj,
C* expected, C desired,
memory_order succ,
memory_order fail );(3) (since C11)
_Bool atomic_compare_exchange_weak_explicit( volatile A *obj,
C* expected, C desired,
memory_order succ,
memory_order fail ); (4) (since C11)
上面几个函数的作用:原子的比较obj所指对象和expected所指对象的内容,如果它们相等,则将desired的值赋值给obj。否则,将obj所指向的内容load到expected所指向的空间。
上述过程用代码表示如下:
if (memcmp(obj, expected, sizeof *obj) == 0)
memcpy(obj, &desired, sizeof *obj);
return true;
else
memcpy(expected, obj, sizeof *obj);
return false;
obj指向我们想修改的对象,
desired是我们想赋值给obj的值,
但是在修改之前,我们要先测试下obj是否是我们期待的值*expected,这是以防我们修改obj之前,obj的值已经被其他人偷偷改了(多线程场景)。
如果改之前是我们期待的,说明还没有人对他进行修改,那就可以成功的修改*obj为desired,并返回true;
否则,将*obj赋值给*expected,并返回false。
这个操作被记为CAS。
strong和weak的区别
如果仅仅是这样子,这些接口还是不安全的,因为只保证了原子性,没有保证可见性,所以引入了一个内存时序/模型的概念(第四个参数)。
表达式的求值时序(Sequenced before术语)
来了解几个时序术语。
什么是同步?首先,单线程不存在同步的问题,其次同步是发生在多线程读写之间的,多读并不存在同步的问题。
同步点:
对于一个原子类型变量a,如果a在线程1中进行store(写)操作,在线程2中进行load(读)操作,则线程1的store和线程2的load构成原子变量a的一对同步点,其中的store操作和load操作就分别是一个同步点。
可以看出,同步点具有三个条件:
- 是一对原子变量操作中的一个,且一个操作是store,另一个操作是load;
- 这两个操作必须针对同一个原子变量;
- 这两个操作必须分别在两个线程中。
sequenced-before
sequenced-before用于表示单线程之间,两个操作上的先后顺序,这个顺序是非对称、可以进行传递的关系。
它不仅仅表示两个操作之间的先后顺序,还表示了操作结果之间的可见性关系。两个操作A和操作B,如果有A sequenced-before B,除了表示操作A的顺序在B之前,还表示了操作A的结果操作B可见。
happens-before
与sequenced-before不同的是,happens-before关系表示的不同线程之间的操作先后顺序,同样的也是非对称、可传递的关系。
如果A happens-before B,则A的内存状态将在B操作执行之前就可见。在上一篇文章中,某些情况下一个写操作只是简单的写入内存就返回了,其他核心上的操作不一定能马上见到操作的结果,这样的关系是不满足happens-before的。happens-before
synchronizes-with
synchronizes-with关系强调的是变量被修改之后的传播关系(propagate), 即如果一个线程修改某变量的之后的结果能被其它线程可见,那么就是满足synchronizes-with关系的。另外synchronizes-with可以被认为是跨线程间的happends-before关系。显然,满足synchronizes-with关系的操作一定满足happens-before关系了。
Carries dependency
同一个线程内,表达式A sequenced-before 表达式B,并且表达式B的值是受表达式A的影响的一种关系, 称之为"Carries dependency"。这个很好理解,例如:
int *a = &var1;
int *b = &var2;
c = *a + *b;
基本上大部分表达式都会传递依赖,除了:&&, ||, ?:, or ,这几个表达式。
另外,carries dependency是支持传递的。即B依赖A,C依赖B,那么C也会依赖A。
来看几条规则:
1、写在前面的表达式一定是sequenced-before后面的表达式
2、操作符的操作数一定会sequenced-before操作符运算之前。
例如 (a++) * b,a++作为*的操作数,会在进行乘法运算前完成计算。
3、函数调用的形参sequenced-before函数体内的语句。
4、&& 、||,这两个运算符的左操作数 sequenced-before右操作数
5、?: 条件表达式第一个操作数sequenced-before后面两个操作数
…
完整见:https://en.cppreference.com/w/cpp/language/eval_order
这几点都是毋庸置疑的,都是保证编程语言自身语法准确性而必须实现的。
关于重排/乱序
说到内存模型,首先需要明确一个普遍存在,但却未必人人都注意到的事实:程序通常并不是总按着照源码中的顺序一一执行,此谓之乱序,乱序产生的原因可能有好几种:
- 编译器出于优化的目的,在编译阶段将源码的顺序进行交换。
- 程序执行期间,指令流水被 cpu 乱序执行。
- inherent cache 的分层及刷新策略使得有时候某些写读操作的从效果上看,顺序被重排。
以上乱序现象虽然来源不同,但从源码的角度,对上层应用程序来说,他们的效果其实相同:写出来的代码与最后被执行的代码是不一致的。这个事实可能会 让人很惊讶:有这样严重的问题,还怎么写得出正确的代码?这担忧是多余的了,乱序的现象虽然普遍存在,但它们都有很重要的一个共同点:在单线程执行的情况 下,乱序执行与不乱序执行,最后都会得出相同的结果 (both end up with the same observable result), 这是乱序被允许出现所需要遵循的首要原则,也是为什么乱序虽然一直存在但却多数程序员大部分时间都感觉不到的根本原因。
乱序的出现说到底是编译器,CPU 等为了让你程序跑得更快而作出无限努力的结果,程序员们应该为它们的良苦用心抹一把泪。
从乱序的种类来看,乱序主要可以分为如下4种:
-
写写乱序(store store), 前面的写操作被放到了后面的操作之后,比如:
a = 3; b = 4; 被乱序为: b = 4; a = 3; -
写读乱序(store load),前面的写操作被放到了后面的读操作之后,比如:
a = 3; load(b); 被乱序为: load(b); a = 3; -
读读乱序(load load), 前面的读操作被放到了后一个读操作之后,比如:
load(a); load(b); 被乱序为: load(b); load(a); -
读写乱序(load store), 前面的读操作被放到了后一个写操作之后,比如:
load(a); b = 4; 被乱序为: b = 4; load(a);
程序的乱序在单线程的世界里多数时候并没有引起太多引人注意的问题,但在多线程的世界里,这些乱序就制造了特别的麻烦,究其原因,最主要的有2个:
- 并发导致修改和访问共享变量的存在不确定性,使得一些不期望的中间状态(往往是错误状态)被暴露了出去,因此像 mutex,各种 lock 之类的东西在写多线程时被频繁地使用。
- 变量被修改后,该修改未必能被另一个线程及时观察到,因此需要“同步”。
解决同步问题就需要确定内存模型,也就是需要确定线程间应该怎么通过共享内存来进行交互。
- 编译器的重排序
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。下面的例子来自并发编程网的文章
int A = 1+1;
int B = 2;
int C = A;
“编译期重排序的典型就是通过调整指令顺序,在不改变程序语义的前提下,尽可能减少寄存器的读取、存储次数,充分复用寄存器的存储值。假设第一条指令计算一个值赋给变量A并存放在寄存器中,第二条指令与A无关但需要占用寄存器(假设它将占用A所在的那个寄存器),第三条指令使用A的值且与第二条指令无关。那么如果按照顺序一致性模型,A在第一条指令执行过后被放入寄存器,在第二条指令执行时A不再存在,第三条指令执行时A重新被读入寄存器,而这个过程中,A的值没有发生变化。通常编译器都会交换第二和第三条指令的位置,这样第一条指令结束时A存在于寄存器中,接下来可以直接从寄存器中读取A的值,降低了重复读取的开销。”
int A = 0;
int B = 0;
void fun()
A = B + 1; // L5
B = 1; // L6
int main()
fun();
return 0;
- 指令间的直接依赖关系
编译器和处理器可能会对操作做重排序,但是要遵守数据依赖关系,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
名称 代码示例说明
写后读 a = 1;b = a;写一个变量之后,再读这个位置。
写后写 a = 1;a = 2;写一个变量之后,再写这个变量。
读后写 a = b;b = 1;读一个变量之后,再写这个变量。
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。像这种有直接依赖关系的操作,是不会进行重排序的。特别注意:这里说的依赖关系仅仅是在单个线程内。
- 指令间的隐式依赖关系
编译器和CPU都必须保证程序上下文的因果关系不发生改变。因此,在绝大多数情况下,我们写程序都不会去考虑乱序所带来的影响。但是有些程序逻辑,单纯从上下文是看不出它们的因果关系的。比如:
*addr = 5;
val = *data;
从表面上看,addr和data是没有什么联系的,完全可以放心的去乱序执行。但是如果这是在某某设备驱动程序中,这两个变量却可能对应到设备的地址端口和数据端口。并且,这个设备规定了,当你需要读写设备上的某个寄存器时,先将寄存器编号设置到地址端口,然后就可以通过对数据端口的读写而操作到对应的寄存器。那么这么一来,对前面那两条指令的乱序执行就可能造成错误。对于这样的逻辑,我们姑且将其称作隐式因果关系;而指令与指令之间直接的输入输出依赖,也姑且称作显式因果关系。CPU的乱序执行或者编译器的重排序是以保持显式因果关系不变为前提的,但是它们都无法识别隐式因果关系。再举个例子:
obj->data = xxx;
obj->ready = 1;
当设置了data之后,记下标志,然后在另一个线程中可能执行:
if (obj->ready)
do_something(obj->data);
虽然这个代码看上去有些别扭,但是似乎没错。不过,考虑到乱序,如果标志被置位先于data被设置,那么结果很可能就杯具了。因为从字面上看,前面的那两条指令其实并不存在显式的因果关系,乱序是有可能发生的。总的来说,如果程序具有显式的因果关系的话,乱序一定会尊重这些关系;否则,乱序就可能打破程序原有的逻辑。这时候,就需要使用屏障来抑制乱序,以维持程序所期望的逻辑。
类似的例子还有
a = 0;
//写线程
public void writer()
a = 1;
flag = true;
//读线程
public void reader()
if (flag)
int i = a * a;
虽然从读线程和写线程的逻辑关系上来说,写线程不能进行重排序,否则读线程会产生错误的结果;但是实际上写线程还是可能发生重排序的,因为从写线程自身的角度来看,a和flag的写操作完全没有依赖关系,可以随意重排序。编译器没有那么智能,它只能将依赖分析限制在单线程中,不能跨线程进行依赖分析。
这种场景下,假设writer发生了重排,那么reader得到的i结果是0。
4.CPU的重排序(指令乱序执行)
现在的CPU一般采用流水线来执行指令。一个指令的执行被分成:取指、译码、访存、执行、写回、等若干个阶段。然后,多条指令可以同时存在于流水线中,同时被执行。指令流水线并不是串行的,并不会因为一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。相反,流水线是并行的,多个指令可以同时处于同一个阶段,只要CPU内部相应的处理部件未被占满即可。比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同时处于“执行”阶段, 而两条加法指令在“执行”阶段就只能串行工作。
然而,这样一来,乱序可能就产生了。比如一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的“顺序流入,乱序流出”。
指令流水线除了在资源不足的情况下会卡住之外(如前所述的一个加法器应付两条加法指令的情况),指令之间的相关性也是导致流水线阻塞的重要原因。CPU的乱序执行并不是任意的乱序,而是以保证程序上下文因果关系为前提的。有了这个前提,CPU执行的正确性才有保证。比如:
a++;
b=f(a);
c--;
由于b=f(a)这条指令依赖于前一条指令a++的执行结果,所以b=f(a)将在“执行”阶段之前被阻塞,直到a++的执行结果被生成出来;而c–跟前面没有依赖,它可能在b=f(a)之前就能执行完。(注意,这里的f(a)并不代表一个以a为参数的函数调用,而是代表以a为操作数的指令。C语言的函数调用是需要若干条指令才能实现的,情况要更复杂些)。
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开距离, 以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如将指令重排为:
a++;
c--;
b=f(a);
由于重排序和乱序执行的存在,如果在并发编程中,没有做好共享数据的同步,很容易出现各种看似诡异的问题。
memory order引入
什么是内存模型?
内存模型是用来描述编程语言在支持多线程编程中对共享内存访问的顺序。更简单的说,内存模型的本质是指在单线程情况下编译器/CPU指令在多大程度上发生指令重排(reorder)。
一个良好的memory model定义包含3个方面:
- Atomic Operations
- Partial order of operations
- Visable effects of operations
这里要强调的是:我们这里所说的内存模型和CPU的体系结构、编译器实现和编程语言规范3个层面都有关系。
首先,不同的CPU体系结构内存顺序模型是不一样的,但大致分为两种:
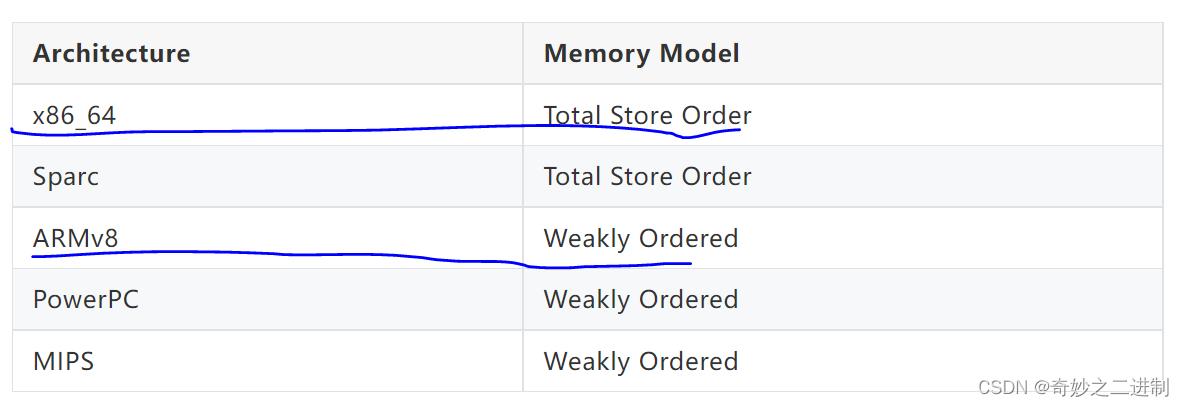
x86_64和Sparc是强顺序模型(Total Store Order),这是一种接近程序顺序的顺序模型。所谓Total,就是说,内存(在写操作上)是有一个全局的顺序的(所有人看到的一样的顺序), 就好像在内存上的每个Store动作必须有一个排队,一个弄完才轮到另一个,这个顺序和你的程序顺序直接相关。所有的行为组合只会是所有CPU内存程序顺序的交织,不会发生和程序顺序不一致的地方。TSO模型有利于多线程程序的编写,对程序员更加友好,但对芯片实现者不友好。CPU为了TSO的承诺,会牺牲一些并发上的执行效率。
弱内存模型(简称WMO,Weak Memory Ordering),是把是否要求强制顺序这个要求直接交给程序员的方法。换句话说,CPU不去保证这个顺序模型(除非他们在一个CPU上就有依赖), 程序员要主动插入内存屏障指令来强化这个“可见性”。ARMv8,PowerPC和MIPS等体系结构都是弱内存模型。每种弱内存模型的体系架构都有自己的内存屏障指令,语义也不完全相同。弱内存模型下,硬件实现起来相对简单,处理器执行的效率也高, 只要没有遇到显式的屏障指令,CPU可以对局部指令进行reorder以提高执行效率。
对于多线程程序开发来说,对并发的数据访问我们一般到做同步操作, 可以使用mutex,semaphore,conditional等重量级方案对共享数据进行保护。但为了实现更高的并发,需要使用内存共享变量做通信(Message Passing), 这就对程序员的要求很高了,程序员必须时时刻刻必须很清楚自己在做什么, 否则写出来的程序的执行行为会让人很是迷惑!值得一提的是,并发虽好,如果能够简单粗暴实现,就不要搞太多投机取巧!要实现lock-free无锁编程真的有点难。
其次,不同的编程语言对内存模型都有自己的规范,例如:C/C++和Java等不同的编程语言都有定义内存模型相关规范。
2011年发布的C11/C++11 ISO Standard为我们带来了memory order的支持, 引用C++11里的一段描述:
The memory model means that C++ code now has a standardizedlibrary to call regardless of who made the compiler and onwhat platform it’s running. There’s a standard way to controlhow different threads talk to the processor’s memory.[7]
memory order的问题就是因为指令重排引起的, 指令重排导致 原来的内存可见顺序发生了变化, 在单线程执行起来的时候是没有问题的, 但是放到 多核/多线程执行的时候就出现问题了, 为了效率引入的额外复杂逻辑的的弊端就出现了[8]。
C++11引入memory order的意义在于我们现在有了一个与运行平台无关和编译器无关的标准库, 让我们可以在high level languange层面实现对多处理器对共享内存的交互式控制。我们的多线程终于可以跨平台啦!我们可以借助内存模型写出更好更安全的并发代码。真棒,简直不要太优秀~
memory_oder详解
#include <atomic>
typedef enum memory_order
memory_order_relaxed,
memory_order_consume,
memory_order_acquire, (since C++11)
memory_order_release, (until C++20)
memory_order_acq_rel,
memory_order_seq_cst
memory_order;
这6种语义描述了原子操作上下附近的内存操作顺序的重排约束。
relaxed 语义
首先是 relaxed 语义,这表示一种最宽松的内存操作约定,该约定对其他读写操作没有同步和顺序约束的限制,只保证操作本身的原子性,以这种方式修改内存时,不需要保证该修改会不会及时被其它线程看到,也不对乱序做任何要求,因此当对公共变量以 relaxed 方式进行读写时,编译器,cpu 等是被允许按照任意它们认为合适的方式来加以优化处理的。
x=y=0
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
如果没有发生重排,就不可能出现r1=r2=42(D->A->B->C的结果),结果是会出现的。
releaxed语义的应用场景就是计数器自增。例如std::shared_ptr的引用计数的自增。但引用计数的自减需要使用acquire-release 。
示例:
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = 0;
void f()
for (int n = 0; n < 1000; ++n)
cnt.fetch_add(1, std::memory_order_relaxed);
int main()
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n)
v.emplace_back(f);
for (auto& t : v)
t.join();
std::cout << "Final counter value is " << cnt << '\\n';
Output:
Final counter value is 10000
不使用原子变量的情况:
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
int cnt = 0;
void f()
for (int n = 0; n < 1000; ++n)
cnt++;
int main()
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n)
v.emplace_back(f);
for (auto& t : v)
t.join();
std::cout << "Final counter value is " << cnt << '\\n';
Output:
Final counter value is 9046
当程序员所写的代码被编译器翻译成机器语言时,编译器可能会为了优化性能来重排程序员所写的代码,比如:
int a = 0;
int b = 0;
void func()
int t = 1;
a = t;
b = 2;
编译器最终优化后的代码可能是这样子的:
int a = 0;
int b = 0;
void func()
b = 2;
a = 1;
在单线程中,这种优化是无关紧要的,因为这两个变量是不相关的,谁先谁后,最后结果一样。但是,如果在多线程环境中,比如另一个线程通过b的值来输出a的值:
void func2()
while (b != 2);
std::cout << a << std::endl;
假如func()与func2()是在不同线程中执行,则func2()中的输出结果可能就不是1,因为编译器可能改变了func()中的代码顺序。
即使编译器没有重排你的代码,最终CPU执行的时候可能也会不一样(这里假设你已经了解缓存一致性协议(MESI)和store-buffer以及invalidate-queue)。变量a的值1可能暂时存储到CPU1的store-buffer中,变量b的值2可能存储到CPU2的cacheline中,然后func2()可能是在CPU2上执行,此时CPU2从cacheline上读取b的值,发现是2,因此while循环退出,执行输出语句。但是此时a的最新值1在CPU1的store-buffer中,因此CPU2上看不到a的值1,只能看到a的值0,因此就会输出0,而不是输出1。
如果a和b都是原子变量,且其store操作和load操作都是用的relaxed内存序,则其执行过程跟上述非原子变量类似。
relaxed内存序模型允许编译器对代码的任意优化和重排,也允许CPU的指令重排,relaxed唯一保证的是原子变量上的操作都是原子性的,即一个操作不会被中断,是排他性的,只有当一个操作完成后,才能执行另一个操作,即使是多线程。但是其他方面就不能保证了,例如上面分析的那样。
acquire语义
1、保证acuqire之后的读写操作不会重排到load操作之前
2、其他线程的release前的所有写操作在当前线程可见。
这样设计的含义是结合经验的,我们往往读取某个数,然后进行运算或者赋值,所以不期待load之后的读写操作重排到load之前。至于load之前的读写操作我们并不关心。
release语义
1、当前线程的store之前的任何读写操作不会重排到store之后。
2、release之前的所有的写操作,对其他使用acquire操作的线程可见。
data.push_back(42);
flag.store(1, std::memory_order_release);
例如上述代码的语义是,push了数据之后,标识flag为1,如果push操作被重排到store之后,那么就会出现flag为1,但data里面却没数据的情况,这是我们不期待的。
来一个完整的例子:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y()
x.store(true, std::memory_order_relaxed); // 1
y.store(true, std::memory_order_relaxed); // 2
void read_y_then_x()
while(!y.load(std::memory_order_relaxed)); // 3
if(x.load(std::memory_order_relaxed)) // 4
++z;
int main()
x = false;
y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!= 0); // 5
release-acquire 语义
如果你曾经去看过别的介绍内存模型相关的文章,你一定会发现 release 总是和 acquire 放到一起来讲,这并不是偶然。事实上,release 和 acquire 是相辅相承的,它们必须配合起来使用,这俩是一个 “package deal”, 分开使用则完全没有意义。具体到其中, release 用于进行写操作,acquire 则用于进行读操作,它们结合起来表示这样一个约定:
如果一个线程A对一块内存 m 以 release 的方式进行修改,那么在线程 A 中,所有在该 release 操作之前进行的内存操作,都在另一个线程 B 对内存 m 以 acquire 的方式进行读取之后,变得可见。
cppref的解释:
If an atomic store in thread A is tagged memory_order_release and an atomic load in thread B from the same variable is tagged memory_order_acquire, all memory writes (non-atomic and relaxed atomic) that happened-before the atomic store from the point of view of thread A, become visible side-effects in thread B. That is, once the atomic load is completed, thread B is guaranteed to see everything thread A wrote to memory. This promise only holds if B actually returns the value that A stored, or a value from later in the release sequence.
互斥锁std::mutex和自旋锁便是release-acquire同步机制的例子。
cppref的解释:
Mutual exclusion locks, such as std::mutex or atomic spinlock, are an example of release-acquire synchronization: when the lock is released by thread A and acquired by thread B, everything that took place in the critical section (before the release) in the context of thread A has to be visible to thread B (after the acquire) which is executing the same critical section.
举个粟子,假设线程 A 执行如下指令:
a.store(3);
b.store(4);
m.store(5, release);
线程 B 执行如下:
e.load();
f.load();
m.load(acquire);
g.load();
h.load();
如上,假设线程 A 先执行,线程 B 后执行, 因为线程 A 中对 m 以 release 的方式进行修改, 而线程 B 中以 acquire 的方式对 m 进行读取,所以当线程 B 执行完 m.load(acquire) 之后, 线程 B 必须已经能看到 a == 3, b == 4. 以上死板的描述事实上还传达了额外的不那么明显的信息:
- release 和 acquire 是相对两个线程来说的,它约定的是两个线程间的相对行为:如果其中一个线程 A 以 release 的方式修改公共变量 m, 另一个线程 B 以 acquire 的方式时读取该 m 时,要有什么样的后果,但它并不保证,此时如果还有另一个线程 C 以非 acquire 的方式来读取 m 时,会有什么后果。
- 一定程度阻止了乱序的发生,因为要求 release 操作之前的所有操作都在另一个线程 acquire 之后可见,那么:
- release 操作之前的所有内存操作不允许被乱序到 release 之后。
- acquire 操作之后的所有内存操作不允许被乱序到 acquire 之前。
而在对它们的使用上,有几点是特别需要注意和强调的:
- release 和 acquire 必须配合使用,分开单独使用是没有意义。
- release 只对写操作(store) 有效,对读 (load) 是没有意义的。
- acquire 则只对读操作有效,对写操作是没有意义的。
综合例子:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data