Matlab实现WAV音频文件计算声品质参数:dBA响度粗糙度尖锐度波动度
Posted 机械工人杨师傅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Matlab实现WAV音频文件计算声品质参数:dBA响度粗糙度尖锐度波动度相关的知识,希望对你有一定的参考价值。
1.dBA
首先读取WAV文件
[x,Fs] = audioread('pink.wav'); %读取音频文件对时域信号进行加窗划分
function [dBA,dBZ,t,windowTime] = analyzeSignal(x,Fs)
responseType = 'fast';
C = 55;
t = 1/Fs:1/Fs:length(x)/Fs;
%% 确定傅里叶窗的大小
if strcmp(responseType,'slow')
duration = 1.0;
else
duration = 0.125;
end
N = ceil(duration*Fs);
N = 2^nextpow2(N);
%% 确定信号的dBA
windowStart = [1:N:(length(x)-N)];
dBA = zeros(length(windowStart),1);
dBZ = zeros(length(windowStart),1);
windowTime = t(windowStart+round((N-1)/2));
for i = [1:length(windowStart)]
[dBA(i),dBZ(i)] = estimateLevel(x(windowStart(i)-1+[1:N]),Fs,C);
end调用子函数计算dBA
function [dBA,dBZ] = estimateLevel(x,Fs,C)
X = abs(fft(x));
%% 避免产生对数取0的情况
X(find(X == 0)) = 1e-17;
%% 保证奈奎斯特采样定律
f = (Fs/length(X))*[0:(length(X)-1)];
ind = find(f<Fs/2); f = f(ind); X = X(ind);
%% 通过A-weighting滤波器实现dBA计算
A = filterA(f);
XA = A'.*X;
%Z-weighting filter
Z = zeros(length(f),1);
Z(1:end) = 1;
XZ = Z.*X;
%% 用能量计算dBA
totalEnergy = sum(XA.^2)/length(XA);
meanEnergy = totalEnergy/((1/Fs)*length(x));
dBA = 10*log10(meanEnergy)+C;
totalEnergy1 = sum(XZ.^2)/length(XZ);
meanEnergy1 = totalEnergy1/((1/Fs)*length(x));
dBZ = 10*log10(meanEnergy1)+C;A-weighted滤波器子函数
function A = filterA(f,plotFilter)
%% Define filter coefficients.
c1 = 3.5041384e16;
c2 = 20.598997^2;
c3 = 107.65265^2;
c4 = 737.86223^2;
c5 = 12194.217^2;
%% Evaluate A-weighting filter.
f(find(f == 0)) = 1e-17;
f = f.^2; num = c1*f.^4;
den = ((c2+f).^2) .* (c3+f) .* (c4+f) .* ((c5+f).^2);
A = num./den;
%% 画dBA计权图.
if exist('plotFilter') & plotFilter
% Plot using dB scale.
figure(2); clf;
semilogx(sqrt(f),10*log10(A));
title('A-weighting Filter');
xlabel('Frequency (Hz)');
ylabel('Magnitude (dB)');
xlim([10 100e3]); grid on;
ylim([-70 10]);
% Plot using linear scale.
figure(3); plot(sqrt(f),A);
title('A-weighting Filter');
xlabel('Frequency (Hz)');
ylabel('Amplitude');
xlim([0 44.1e3/2]); grid on;
end2.响度
首先确定窗的大小
function [Loudness,Sharpness,Roughness,Fluctuation] = frameToCalculate(x,Fs);
%% 划分时域帧的长度
responseType = 'fast';
%避免输入信号不存在的情况
if ~exist('x')
[x,Fs] = audioread();
t = (1/Fs)*[0:(length(x)-1)]; t = t+81;
else
t = (1/Fs)*[0:(length(x)-1)];
end
%根据fast和slow进行时间帧的划分
if strcmp(responseType,'slow')
duration = 1;
else
duration = 0.125;
end
N = ceil(duration*Fs);
N = 2^nextpow2(N);
% Estimate signal level (within each windowed segment).
windowStart = [1:N:(length(x)-N)];
Loudness = zeros(length(windowStart),1);
Sharpness = zeros(length(windowStart),1);
Roughness = zeros(length(windowStart),1);
Fluctuation = zeros(length(windowStart),1);
windowTime = t(windowStart+round((N-1)/2));
%% 按照划分的时间帧,分帧计算每帧的平均响度
for i = [1:length(windowStart)]
Loudness(i) = estimateLoudness(x(windowStart(i)-1+[1:N]),Fs);
Sharpness(i) = estimateSharpness(x(windowStart(i)-1+[1:N]),Fs);
Roughness(i) = estimateRoughness(x(windowStart(i)-1+[1:N]),Fs);
Fluctuation(i) = estimateFluctuation(x(windowStart(i)-1+[1:N]),Fs);
end
end本文采用Zwicker模型,通过24Barks的特征响度进行总响度计算:


function loudness = estimateLoudness(x,Fs)
%% 24Barks划分
fc = [20 100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000;
50 150 250 350 450 570 700 840 1000 1170 1370 1600 1850 2150 2500 2900 3400 4000 4800 5800 7000 8500 10500 13500;
100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000 15500];
BandWidth = [80 100 100 100 110 120 140 150 160 190 210 240 280 320 380 450 550 700 900 1100 1300 1800 2500 3500];
%% 中心频带率,有何意义
z = zeros(1,length(fc(2,:)));
for i = 1:length(z)
z(i) = 13.*atan(0.76*fc(2,i)/1000)+3.5.*(atan(fc(2,i)/1000)).^2; %?
end
%% 听阈下限声压级,用getData在听阈曲线上估计出来
Lspl = [48.72457794 28.15401982 16.78690581 10.97541703 7.18374514 3.645302897 1.116392826 -0.152013044 0.093691208 -0.165558761 -0.9278816 -1.94268155 -2.95710523 -4.475730591 -6.751034742 -7.765458422 -8.528157532 -8.030352439 -5.516869434 -1.490781387 4.047911702 6.813119278 8.569170952 11.83632259];
%% Calculate magnitude of FFT.
X = abs(fft(x));
X(find(X == 0)) = 1e-17;%避免产生对数取0的情况
% Retain frequencies below Nyquist rate.
f = (Fs/length(X))*[0:(length(X)-1)];
ind = find(f<Fs/2); f = f(ind); X = X(ind);
%% 按bark进行声压级计算
SPL = zeros(1,24);
for i = 1:24
location = find(f>=fc(1,i)&f<=fc(3,i));
if ~isempty(location)
totalEnergy = sum(X(location).^2)/length(location);
SPL(i) = 10*log10(totalEnergy/((1/Fs)*length(x)))+55;
else
SPL(i) = 0;
end
end
%% 按Bark进行响度计算
N = zeros(1,length(Lspl));
N = 0.08.*((10.^(Lspl/10)).^0.23).*((0.5+0.5.*10.^((SPL-Lspl)/10)).^0.23-1);%得到24bark响度分布图
loudness = sum(N);
end3.尖锐度Sharpness
同样选择Zwicker模型

function sharpness = estimateSharpness(x,Fs)
%% 24Barks划分
fc = [20 100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000;
50 150 250 350 450 570 700 840 1000 1170 1370 1600 1850 2150 2500 2900 3400 4000 4800 5800 7000 8500 10500 13500;
100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000 15500];
BandWidth = [80 100 100 100 110 120 140 150 160 190 210 240 280 320 380 450 550 700 900 1100 1300 1800 2500 3500];
%% 中心频带率,有何意义?
z = zeros(1,length(fc(2,:)));
for i = 1:length(z)
z(i) = 13.*atan(0.76*fc(2,i)/1000)+3.5.*(atan(fc(2,i)/1000)).^2; %?
end
%% 根据中心频带率z加上响度计权函数
gz = zeros(1,length(z));
for i = 1:length(z)
if z(i)<=16
gz(i) = z(i);
else
gz(i) = 0.06.*exp(0.17*z(i));
end
end
%% 听阈下限声压级,用getData在听阈曲线上估计出来
Lspl = [48.72457794 28.15401982 16.78690581 10.97541703 7.18374514 3.645302897 1.116392826 -0.152013044 0.093691208 -0.165558761 -0.9278816 -1.94268155 -2.95710523 -4.475730591 -6.751034742 -7.765458422 -8.528157532 -8.030352439 -5.516869434 -1.490781387 4.047911702 6.813119278 8.569170952 11.83632259];
%% Calculate magnitude of FFT.
X = abs(fft(x));
X(find(X == 0)) = 1e-17;%避免产生对数取0的情况
% Retain frequencies below Nyquist rate.
f = (Fs/length(X))*[0:(length(X)-1)];
ind = find(f<Fs/2); f = f(ind); X = X(ind);
%% 按bark进行声压级计算
SPL = zeros(1,24);
for i = 1:24
location = find(f>=fc(1,i)&f<=fc(3,i));
if ~isempty(location)
totalEnergy = sum(X(location).^2)/length(location);
SPL(i) = 10*log10(totalEnergy/((1/Fs)*length(x)))+55;
else
SPL(i) = 0;
end
end
%% 按Bark进行响度计算
N = zeros(1,length(Lspl));
N = 0.08.*((10.^(Lspl/10)).^0.23).*((0.5+0.5.*10.^((SPL-Lspl)/10)).^0.23-1);%得到24bark响度分布图
%% 计算sharpness
sharpness = 0.104.*sum(N.*gz.*z)./sum(N);
end4.粗糙度
粗糙度计算公式
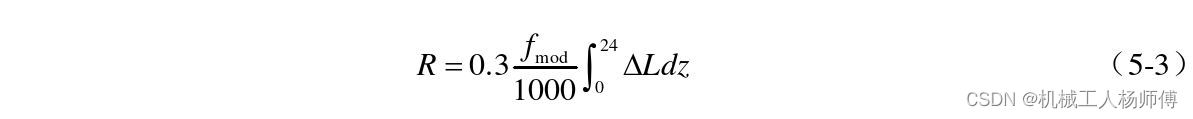
由于掩蔽深度无法用数学公式进行描述,在这里用一个系数乘以响度简单代替(希望各位能教教我更准确的数值计算方法)
function roughness = estimateRoughness(x,Fs)
%% 24Barks划分
fc = [20 100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000;
50 150 250 350 450 570 700 840 1000 1170 1370 1600 1850 2150 2500 2900 3400 4000 4800 5800 7000 8500 10500 13500;
100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000 15500];
BandWidth = [80 100 100 100 110 120 140 150 160 190 210 240 280 320 380 450 550 700 900 1100 1300 1800 2500 3500];
%% 中心频带率
z = zeros(1,length(fc(2,:)));
for i = 1:length(z)
z(i) = 13.*atan(0.76*fc(2,i)/1000)+3.5.*(atan(fc(2,i)/1000)).^2; %
end
%% 听阈下限声压级,用getData在听阈曲线上估计出来
Lspl = [48.72457794 28.15401982 16.78690581 10.97541703 7.18374514 3.645302897 1.116392826 -0.152013044 0.093691208 -0.165558761 -0.9278816 -1.94268155 -2.95710523 -4.475730591 -6.751034742 -7.765458422 -8.528157532 -8.030352439 -5.516869434 -1.490781387 4.047911702 6.813119278 8.569170952 11.83632259];
%% Calculate magnitude of FFT.
X = abs(fft(x));
X(find(X == 0)) = 1e-17;%避免产生对数取0的情况
% Retain frequencies below Nyquist rate.
f = (Fs/length(X))*[0:(length(X)-1)];
ind = find(f<Fs/2); f = f(ind); X = X(ind);
%% 按bark进行声压级计算
SPL = zeros(1,24);
for i = 1:24
location = find(f>=fc(1,i)&f<=fc(3,i));
if ~isempty(location)
totalEnergy = sum(X(location).^2)/length(location);
SPL(i) = 10*log10(totalEnergy/((1/Fs)*length(x)))+55;
else
SPL(i) = 0;
end
end
%% 按Bark进行粗糙度计算
N = zeros(1,length(Lspl));
N = 0.08.*((10.^(Lspl/10)).^0.23).*((0.5+0.5.*10.^((SPL-Lspl)/10)).^0.23-1);%得到24bark响度分布图
fmod = 300/1000; %调制声频率
k = 0.01; %掩蔽深度转换为响度的系数
L = k.*N; %掩蔽深度
roughness = 0.3.*fmod.*sum(L);
end5.波动度
根据计算模型

function fluctuation = estimateFluctuation(x,Fs)
%% 24Barks划分
fc = [20 100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000;
50 150 250 350 450 570 700 840 1000 1170 1370 1600 1850 2150 2500 2900 3400 4000 4800 5800 7000 8500 10500 13500;
100 200 300 400 510 630 770 920 1080 1270 1480 1720 2000 2320 2700 3150 3700 4400 5300 6400 7700 9500 12000 15500];
BandWidth = [80 100 100 100 110 120 140 150 160 190 210 240 280 320 380 450 550 700 900 1100 1300 1800 2500 3500];
%% 中心频带率
z = zeros(1,length(fc(2,:)));
for i = 1:length(z)
z(i) = 13.*atan(0.76*fc(2,i)/1000)+3.5.*(atan(fc(2,i)/1000)).^2; %?
end
%% 听阈下限声压级,用getData在听阈曲线上估计出来
Lspl = [48.72457794 28.15401982 16.78690581 10.97541703 7.18374514 3.645302897 1.116392826 -0.152013044 0.093691208 -0.165558761 -0.9278816 -1.94268155 -2.95710523 -4.475730591 -6.751034742 -7.765458422 -8.528157532 -8.030352439 -5.516869434 -1.490781387 4.047911702 6.813119278 8.569170952 11.83632259];
%% Calculate magnitude of FFT.
dBZ(dBZ == 0) = 1e-17;%避免产生对数取0的情况
%% 按bark进行声压级计算
SPL = zeros(1,24);
for i = 1:24
location = find(f>=fc(1,i)&f<=fc(3,i));
if ~isempty(location)
SPL(i) = sum(X(location))/length(location);
else
SPL(i) = 0;
end
end
%% 按Bark进行响度计算
N = zeros(1,length(Lspl));
N = 0.08.*((10.^(Lspl/10)).^0.23).*((0.5+0.5.*10.^((SPL-Lspl)/10)).^0.23-1);%得到24bark响度分布图
k = 0.01; %掩蔽深度转换为响度的系数
L = k.*N; %掩蔽深度
fmod = 300/1000; %调制频率
fluctuation = 0.008.*sum(L)/((fmod/4)+(4/fmod));
end(对于掩蔽深度的计算暂未找到合适的数学模型)
wav音频文件解析读取 定点转浮点分析 幅值提取(C语言实现)
文章目录
引言
在之前的研究中,实现了arm平台C语言对FFT的频谱分析以及失真度测试
从Matlab平台进行FFT到ARM平台C语言FFT频谱分析
上述文章分析通过sine生成的信号,实际工作中需要解析外部传入的音频文件,然后再进行fft等操作
音频编码
音频编码基本原理
音频信号的冗余信息
数字音频信号如果不加压缩地直接进行传送,将会占用极大的带宽。例如,一套双声道数字音频若取样频率为 44.1KHz,每样值按 16bit 量化,则其码率为:
2 x 44.1 kHz x 16 bit = 1.411 Mbit/s
如此大的带宽将给信号的传输和处理都带来许多困难,因此必须采取音频压缩技术对音频数据进行处理,才能有效地传输音频数据。
数字音频压缩编码在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩。数字音频压缩编码采取去除声音信号中冗余成分的方法来实现。所谓冗余成分指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。
冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为 20Hz~20KHz,除此之外的其它频率人耳无法察觉,都可视为冗余信号。此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应,主要表现在频谱掩蔽效应和时域掩蔽效应。
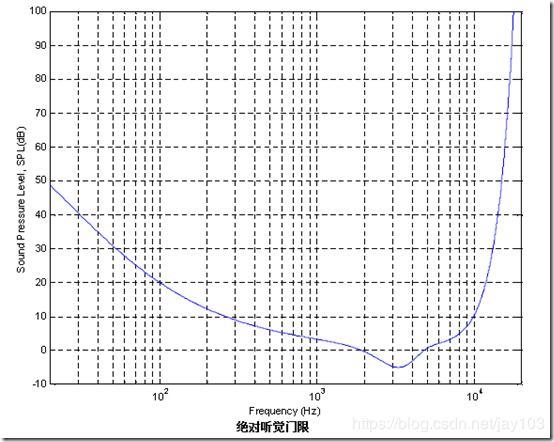
频谱掩蔽效应
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈。当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,即所谓的掩蔽效应。如图所示:

由图中我们可以看出人耳对 2KHz~5KHz 的声音最敏感,而对频率太低或太高的声音信号都很迟钝,当有一个频率为 0.2K Hz、强度为 60dB 的声音出现时,其附近的阈值提高了很多。由图中我们可以看出在 0.1KHz 以下、1KHz 以上的部分,由于离 0.2KHz 强信号较远,不受 0.2KHz 强信号影响,阈值不受影响;而在 0.1KHz~1KHz 范围,由于 0.2KHz 强音的出现,阈值有较大的提升,人耳在此范围所能感觉到的最小声音强度大幅提升。如果 0.1KHz~1KHz 范围内的声音信号的强度在被提升的阈值曲线之下,由于它被 0.2KHz 强音信号所掩蔽,那么此时我们人耳只能听到 0.2KHz 的强音信号而根本听不见其它弱信号,这些与 0.2KHz 强音信号同时存在的弱音信号就可视为冗余信号而不必传送。
时域掩蔽效应
当强音信号和弱音信号同时出现时,还存在时域掩蔽效应。即两者发生时间很接近的时候,也会发生掩蔽效应。时域掩蔽过程曲线如图所示,分为前掩蔽、同时掩蔽和后掩蔽三部分。
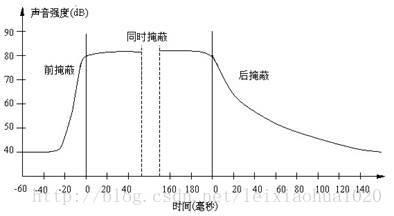
由图我们可以看出,时域掩蔽效应可以分成三种:前掩蔽,同时掩蔽,后掩蔽。前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到。同时掩蔽是指当强信号与弱信号同时存在时,弱信号会被强信号所掩蔽而听不到。后掩蔽是指当强信号消失后,需经过较长的一段时间才能重新听见弱信号,称为后掩蔽。这些被掩蔽的弱信号即可视为冗余信号。
压缩编码方法
当前数字音频编码领域存在着不同的编码方案和实现方式,但基本的编码思路大同小异,如图所示。
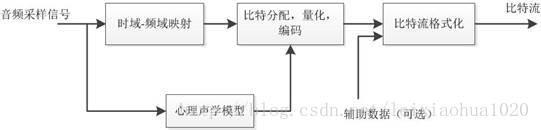
对每一个音频声道中的音频采样信号,首先都要将它们映射到频域中,这种时域到频域的映射可通过子带滤波器实现。每个声道中的音频采样块首先要根据心理声学模型来计算掩蔽门限值,然后由计算出的掩蔽门限值决定从公共比特池中分配给该声道的不同频率域中多少比特数,接着进行量化以及编码工作,最后将控制参数及辅助数据加入数据之中,产生编码后的数据流。
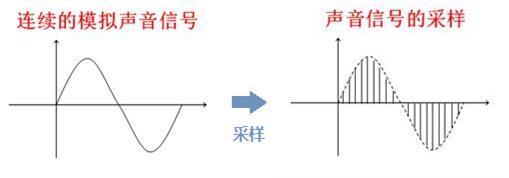
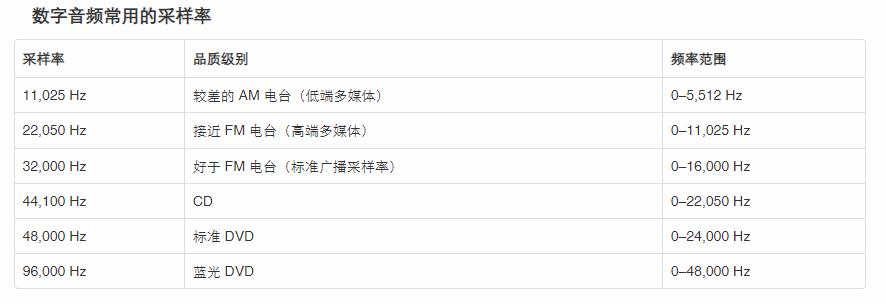
音频采样
真实世界中的声音都是连续的,因为声音是模拟信号。但是在计算机中存储的信息都是数字信号。所以在将声音存储到计算机之前,就必须要进行声音的数字化,转换成计算机能够存储的形式。
模拟信号转换为数字信号,一种比较通用的方法就是进行等间隔采样。根据奈奎斯特定理,采样频率至少为信号频率的 2 倍,才能无失真的保存原有的音频信号。因此采样频率的高低决定了数字信号的保真度,自然是越高越好。比如,一个周期为 1ms 的正弦信号,采两个点和采 100 个点的信号在还原成模拟信号的时候,肯定是采 100 个点信号的还原效果更好。
音频量化
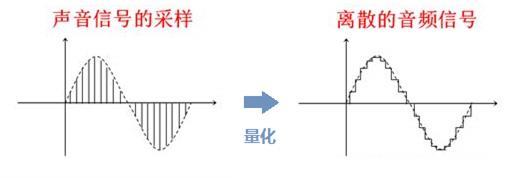
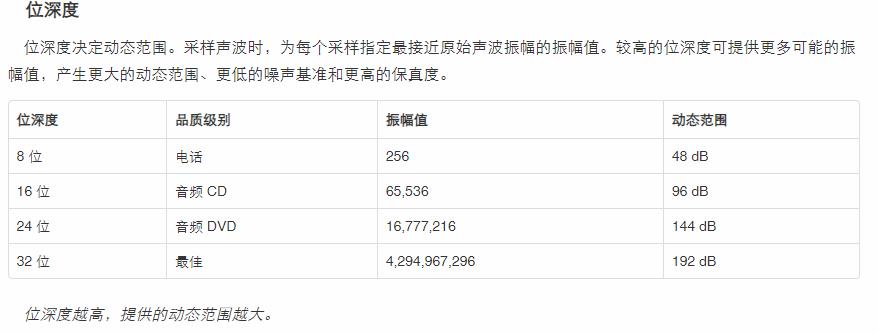
量化就是把经过采样得到的瞬时值将其幅度离散,即用一组规定的电平,把瞬时采样值用最接近的电平值来表示。所谓的音频量化,就是用二进制数据来表示电平的大小。一般采用8位(256级)或者16位(65536级)的数据来表示。
常见的量化器有:均匀量化器,对数量化器,非均匀量化器。量化过程追求的目标是:最小化量化误差,并尽量减低量化器的复杂度(这二者本身就是一个矛盾)。
均匀量化器:最简单,性能最差,仅适应于电话语音。
对数量化器:比均匀量化器复杂,也容易实现,性能比均匀量化器好。
Non-uniform量化器:根据信号的分布情况,来设计量化器。信号密集的地方进行细致的量化,稀疏的地方进行粗略量化。
语音 / 音频编码算法
语音 / 音频编码算法主要有以下 6 种:
- 波形编码
波形编码是最简单也是应用最早的语音编码方法。最基本的一种就是 PCM 编码,如 G.711 建议中的 A 律或 μ 律。APCM、DPCM 和 ADPCM 也属于波形编码的范畴,使用这些技术的标准有 G.721、G.726、G.727 等。波形编码具有实施简单、性能优良的特点,不足是编码带宽往往很难再进一步下降。 - 预测编码
语音信号是非平稳信号,但在短时间段内(一般是30ms)具有平稳信号的特点,因而对语音信号幅度进行预测编码是一种很自然的做法。最简单的预测是相邻两个样点间求差分,编码差分信号,如G.721。但更广为应用的是语音信号的线性预测编码(LPC)。几乎所有的基于语音信号产生的全极点模型的参数编码器都要用到 LPC, 如 G.728、G.729、G.723.1。 - 参数编码
参数编码建立在人类语音产生的全极点模型的理论上,参数编码器传输的编码参数也就是全极点模型的参数——基频、线谱对、增益。对语音来说,参数编码器的编码效率最高,但对音频信号,参数编码器就不太合适。典型的参数编码器有 LPC- 10、LPC-10E,另外,G.729、G.723.1 以及 CELP(FS- 1016)等码激励线性预测声码器都离不开参数编码。 - 变换编码
一般认为变换编码在语音信号中作用不是很大,但在音频信号中它却是主要的压缩方法。比如,MPEG 伴音压缩算法(含著名的 MP3) 用到 FFT、MDCT 变换,AC-3 杜比立体声也用到 MDCT,G.722.1 建议中采用的 MLT 变换。在近年来出现的低速率语音编码算法中,STC(正弦变换编码)和 WI(波形插值)占有重要的位置,小波变换和 Gabor 变换在其中就有用武之地。 - 子带编码
子带编码一般是同波形编码结合使用,如 G.722 使用的是 SB-ADPCM 技术。但子带的划分更多是对频域系数的划分(这可以更好地利用低频带比高频带感觉更重要的特点),故子带编码中,往往先要应用某种变换方法得到频域系数,在 G.722.1 中使用 MLT 变换,系数划分为 16 个子带;MPEG 伴音中用 FFT 或 MDCT 变换,划分的子带多达 32 个。 - 统计编码
统计编码在图像编码中大量应用,但在语音编码中出于对编码器整体性能的考虑(变长编码易引起误码扩散),很少使用。对存在统计冗余的信号来说,统计编码确实可以大大提高编码的效率,所以,近年来出现的音频编码算法中,统计编码又重新得到了重视。MPEG 伴音和 G.722.1 建议中采纳了哈夫曼变长编码。
PCM格式
PCM (Pulse Code Modulation) 也被称为脉冲编码调制。PCM 音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准的数字音频数据。
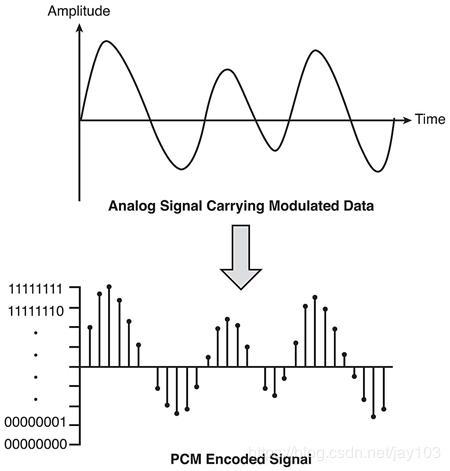
PCM 音频数据的存储
如果是单声道的音频文件,采样数据按时间的先后顺序依次存入(有的时候也会采用 LRLRLR 方式存储,只是另一个声道的数据为 0),如果是双声道的话通常按照 LRLRLR 的方式存储,存储的时候还和机器的大小端有关。大端模式如下图所示:
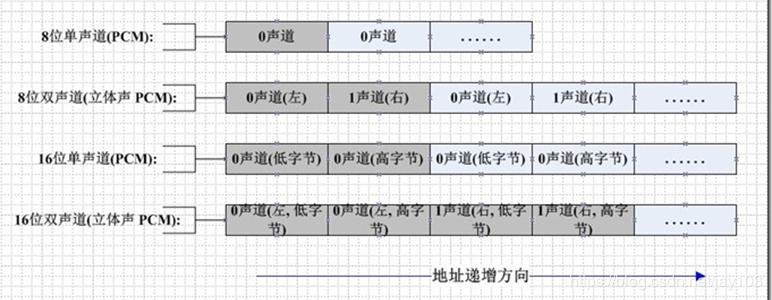
PCM 音频数据是未经压缩的数据,所以通常都比较大,常见的 MP3 格式都是经过压缩的,128Kbps 的 MP3 压缩率可以达到 1:11
PCM 音频数据的参数
一般我们描述 PCM 音频数据的参数的时候有如下描述方式:
44100HZ 16bit stereo: 每秒钟有 44100 次采样, 采样数据用 16 位(2 字节)记录, 双声道(立体声)
22050HZ 8bit mono: 每秒钟有 22050 次采样, 采样数据用 8 位(1 字节)记录, 单声道
48000HZ 32bit 51ch: 每秒钟有 48000 次采样, 采样数据用 32 位(4 字节浮点型)记录, 5.1 声道
44100Hz 指的是采样率,它的意思是每秒取样 44100 次。采样率越大,存储数字音频所占的空间就越大。
16bit 指的是采样精度,意思是原始模拟信号被采样后,每一个采样点在计算机中用 16 位(两个字节)来表示。采样精度越高越能精细地表示模拟信号的差异。
Stereo 指的是声道数,也即采样时用到的麦克风的数量,麦克风越多就越能还原真实的采样环境(当然麦克风的放置位置也是有规定的)。
一般来说 PCM 数据中的波形幅值越大,代表音量越大。
WAV格式
WAV 是 Microsoft 和 IBM 为 PC 开发的一种声音文件格式,它符合 RIFF(Resource Interchange File Format)文件规范,用于保存 Windows 平台的音频信息资源,被 Windows 平台及其应用程序所广泛支持。WAVE 文件通常只是一个具有单个 “WAVE” 块的 RIFF 文件,该块由两个子块(”fmt” 子数据块和 ”data” 子数据块),它的格式如下图所示:

WAV 格式定义
该格式的实质就是在 PCM 文件的前面加了一个文件头,每个字段的的含义如下:
typedef struct
char ChunkID[4]; //内容为"RIFF"
unsigned long ChunkSize; //存储文件的字节数(不包含ChunkID和ChunkSize这8个字节)
char Format[4]; //内容为"WAVE“
WAVE_HEADER;
typedef struct
char Subchunk1ID[4]; //内容为"fmt"
unsigned long Subchunk1Size; //存储该子块的字节数(不含前面的Subchunk1ID和Subchunk1Size这8个字节)
unsigned short AudioFormat; //存储音频文件的编码格式,例如若为PCM则其存储值为1。
unsigned short NumChannels; //声道数,单声道(Mono)值为1,双声道(Stereo)值为2,等等
unsigned long SampleRate; //采样率,如8k,44.1k等
unsigned long ByteRate; //每秒存储的bit数,其值 = SampleRate * NumChannels * BitsPerSample / 8
unsigned short BlockAlign; //块对齐大小,其值 = NumChannels * BitsPerSample / 8
unsigned short BitsPerSample; //每个采样点的bit数,一般为8,16,32等。
WAVE_FMT;
typedef struct
char Subchunk2ID[4]; //内容为“data”
unsigned long Subchunk2Size; //接下来的正式的数据部分的字节数,其值 = NumSamples * NumChannels * BitsPerSample / 8
WAVE_DATA;
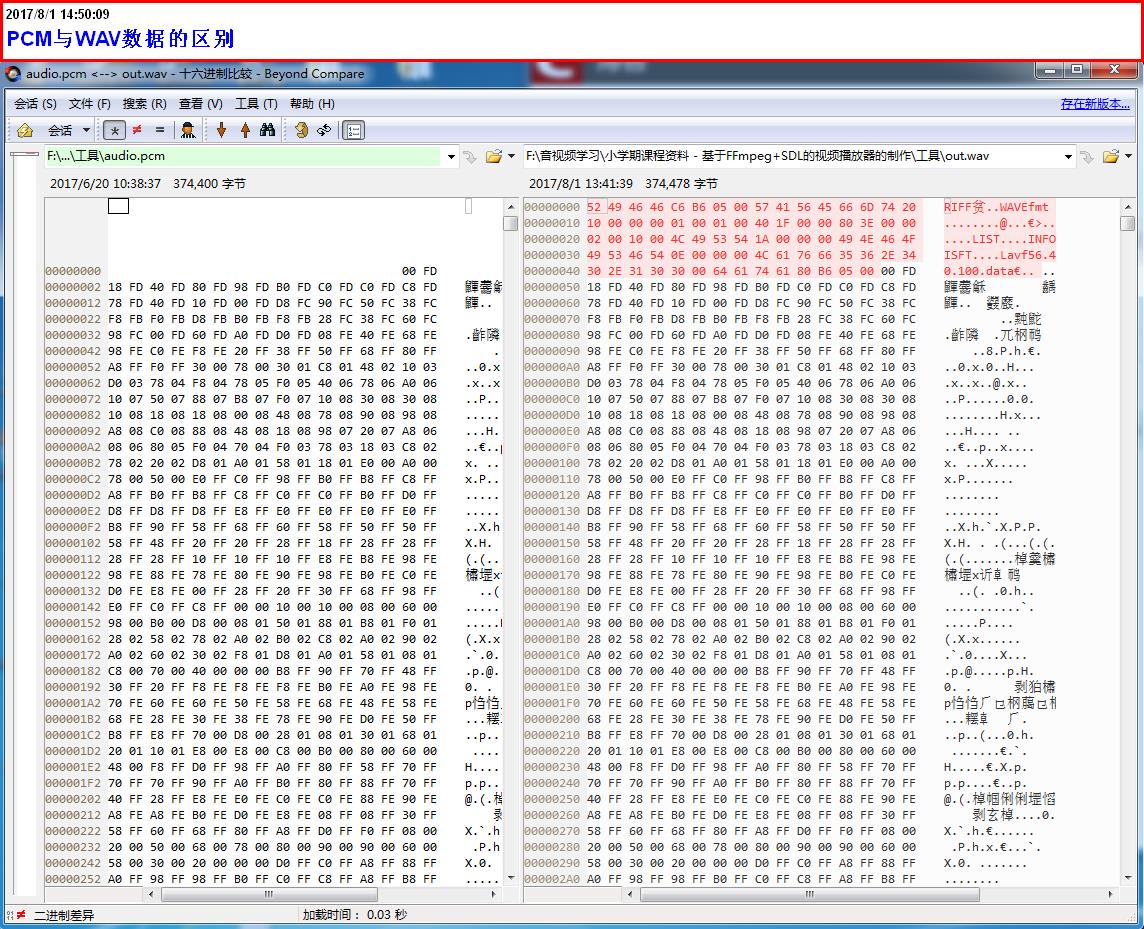
WAV 文件头解析
这里是一个 WAVE 文件的开头 72 字节,字节显示为十六进制数字:
52 49 46 46 | 24 08 00 00 | 57 41 56 45
66 6d 74 20 | 10 00 00 00 | 01 00 02 00
22 56 00 00 | 88 58 01 00 | 04 00 10 00
64 61 74 61 | 00 08 00 00 | 00 00 00 00
24 17 1E F3 | 3C 13 3C 14 | 16 F9 18 F9
34 E7 23 A6 | 3C F2 24 F2 | 11 CE 1A 0D
字段解析如下图:
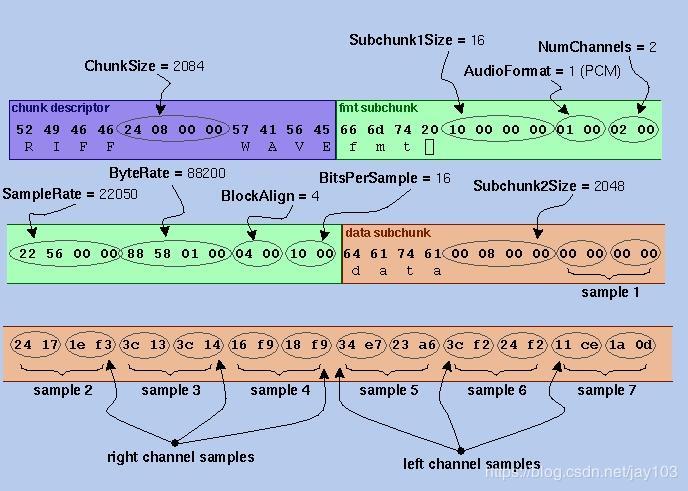
WAV解析
定点数转换浮点数
分析完原理之后,对wav文件进行解析,本质也是提取出来wav文件中的数据部分,然后把量化后的定点数变成浮点数。
matlab比较方便,可以直接解析后,然后通过图片展示,可以明确的得知第一个点的幅值为-0.0492554
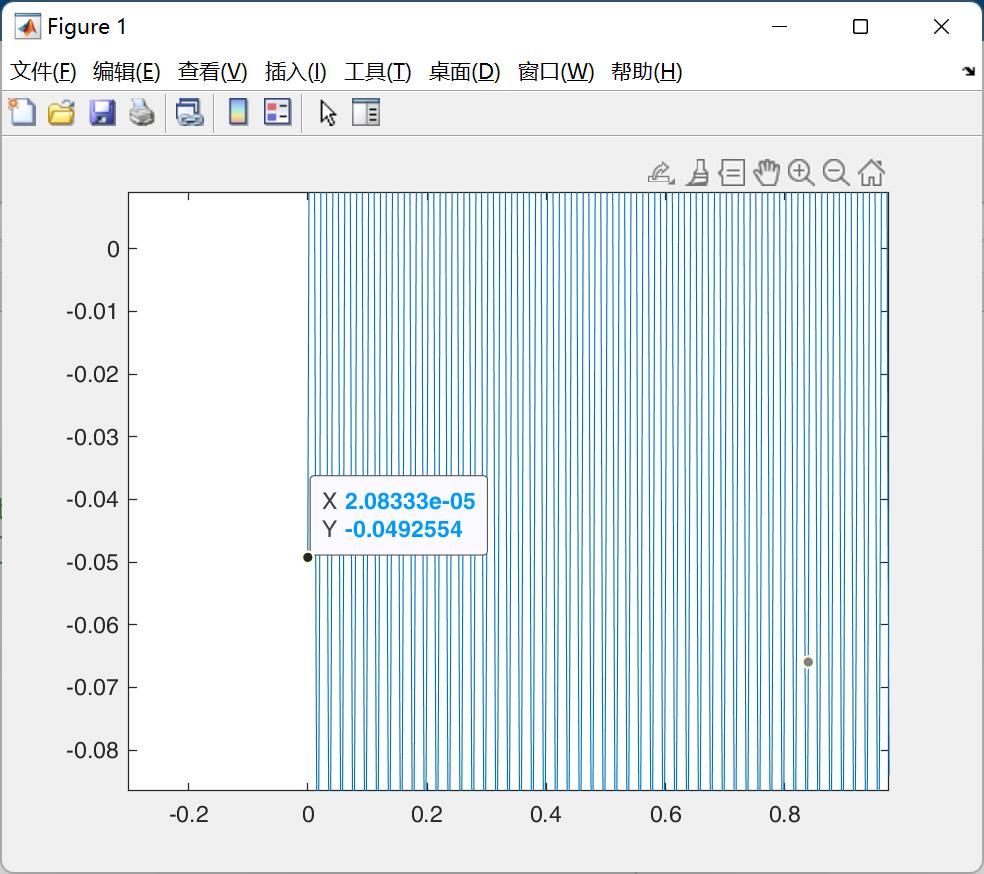
难点就来到了在C语言上如何对定点数进行分析
我们要分析的wav文件,采样率48000hz,24位,单声道
通过二进制查看软件我们可以看到wav文件的数据部分
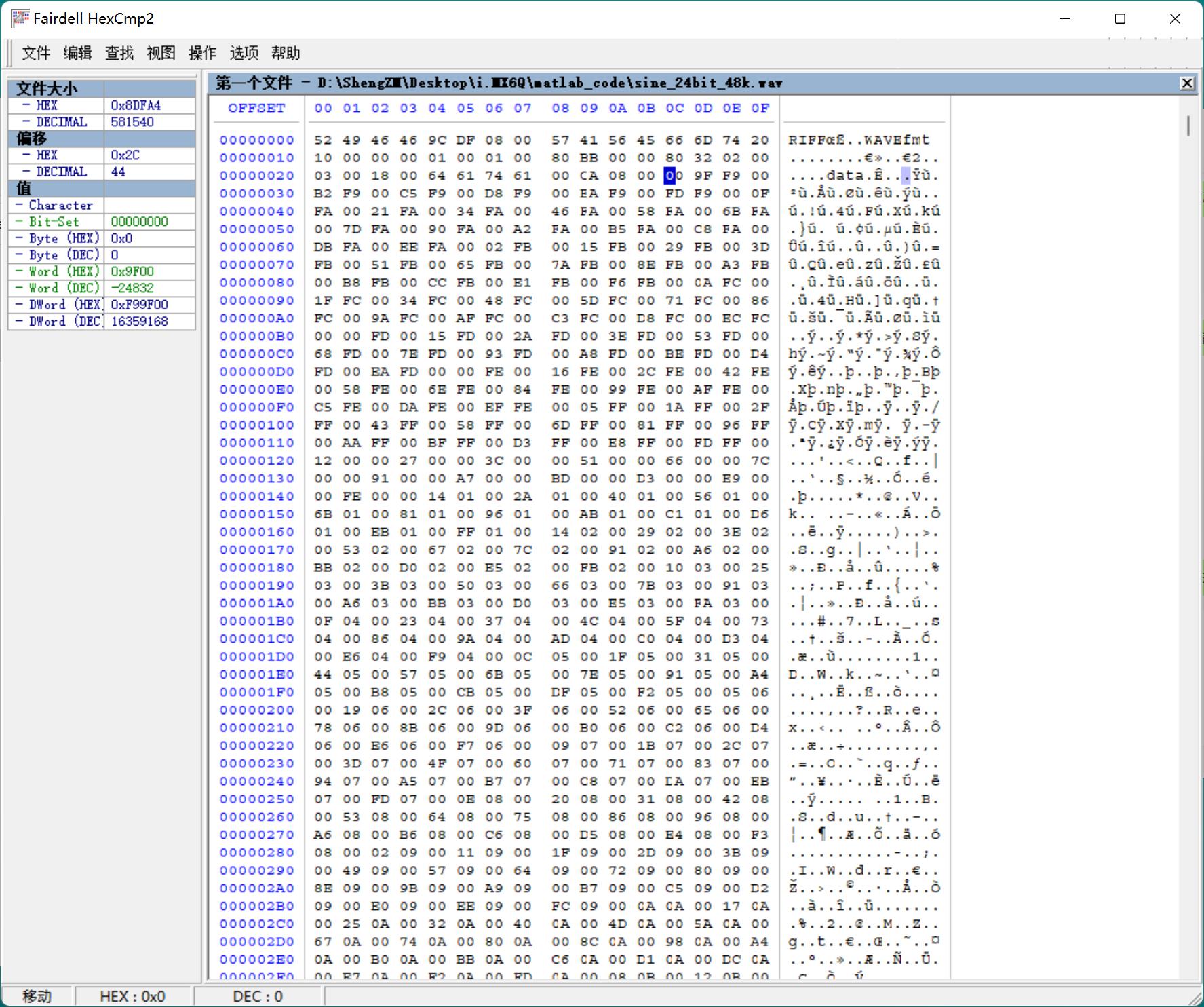
因为此文件的位深,也就是量化位24位,即去除wav的44byte头部之后,数据部分,3 byte一个数据。
但是这个24位数据不能直接进行转换,例如第一个数据 00 9F F9

得出来的是40953,对这个量化数进行还原到实际幅值便是,40953 / pow(2, 23) = 0.00488197803497314453125
因为我知道正确答案,所以可以直接告诉大家,结果是不正确的
这里有一个错误,就是我们的数据,不是00 9F F9这样存储的,实际数据应该是 F9 9F 00
确定实际的数据表示后,下一步是要明白在这24位的数据中,因为是定点数,所以第24位是符号位,只有23位表示实际的数据
问题现在变成了首先要确定数据是正负,才能进行数值的转换,正数大家都知道,就直接介绍负数吧
还是我们的这个数据F9 9F 00,1111 1001 1001 1111 0000 0000,读取到24位是1,这是一个负数,对于数据111 1001 1001 1111 0000 0000,首先要做的就是-1,然后就是取反,接着是转换成十进制,最后就是添加上负号。
-1
111 1001 1001 1111 0000 0000 - 1 = 111 1001 1001 1110 1111 1110
取反
~111 1001 1001 1110 1111 1110 = 000 0110 0110 0001 0000 0001
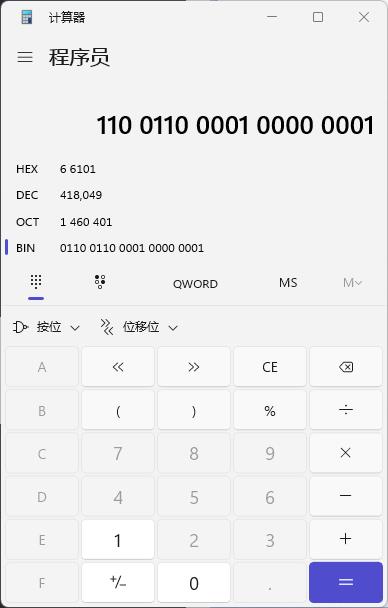
得出来的是418049,对这个量化数加上符号位,然后进行还原到实际幅值便是,-418049/ pow(2, 23) = -0.04983532428741455078125
与实际结果一致
代码
/*
* wav文件解析
*/
int parse_wave_file_double(char *filePath, double *wavData)
char head[44];
FILE *fp;
int read_len;
if ((fp = fopen(filePath, "rb")) == NULL) // 打开文件
perror("Open file failed\\n");
return -1;
read_len = fread(head, sizeof(char), 44, fp); // 读取数据到bufferp
if (head[20] != 1) // 检查是否PCM格式
return -1;
int channel = head[22];
if (channel != 1) // 检查是否单声道
return -1;
int sample = 0;
sample = head[24] + (head[25] << 8) + (head[26] << 8*2) + (head[27] << 8*3);
if (sample != 48000) // 检查采样率是否48000
return -1;
int bytesPerSecond = 0; // 平均每秒字节数
bytesPerSecond = head[28] + (head[29] << 8) + (head[30] << 8*2) + (head[31] << 8*3);
int bits = head[34]; // 采样位数
if (bits != 16 && bits != 24) // 检查位数是否为16或24
return -1;
int dataNum = 0;
dataNum = head[40] + (head[41] << 8) + (head[42] << 8*2) + (head[43] << 8*3);
if (dataNum > (bytesPerSecond * 4)) // 数据长度大于4s
return -1;
char data[dataNum];
fread(data, sizeof(char), dataNum, fp);
int bytes = 0;
int sampleNum = 0;
bytes = bits / 8; // 若采样位数bits为24位,则Bytes = 3;
sampleNum = dataNum / bytes; // 数据的总大小 / 3 = 时域中采样点的个数
int j;
int pow_2_23 = pow(2, 23);
int pow_2_15 = pow(2, 15);
for (int i = 0; i < sampleNum; i++ )
char temp[4] = 0, 0, 0, 0 ;
double nTemp = 0.0;
int bufftemp = 0;
/*
* data从bytes * i开始 复制bytes个值到temp 从temp的4-bytes位置开始存储
*/
for(j = 0; j < bytes; j++) // 24位音频数据,3个字节1个采样点数据
temp[j] = data[bytes * i + j]; // 靠右存储 例如原数据
if(bytes == 3)
bufftemp = 0;
bufftemp = temp[0] + (temp[1] << 8) + (temp[2] << 8 * 2);
if( (bufftemp | 0x7fffff) == 0xffffff ) // 若bufftemp = F99F00 = 1111 1001 1001 1111 0000 0000,& 0111 1111 1111 1111 1111 1111 若结果为ffffffff判断首位为1,否则为0
nTemp = ( ~( (bufftemp - 0x01) | 0xff000000 ) ) / (pow_2_23 * (-1.0));
else if( (bufftemp | 0x7fffff) == 0x7fffff )
nTemp = bufftemp / (pow_2_23 * 1.0);
// else if(bytes == 2)
// nTemp = temp[0] + (temp[1] << 8);
// if( (bufftemp | 0x00007fff) == 0x0000ffff )
// bufftemp = bufftemp - 0x01;
// bufftemp = bufftemp | 0xffff0000;
// bufftemp = ~bufftemp;
// nTemp = bufftemp / (pow_2_15 * (-1.0));
// else if( (bufftemp | 0x00007fff) == 0x00007fff )
// nTemp = bufftemp / (pow_2_15 * 1.0);
//
//
wavData[i] = nTemp;
fclose(fp);
return 0;
以上是关于Matlab实现WAV音频文件计算声品质参数:dBA响度粗糙度尖锐度波动度的主要内容,如果未能解决你的问题,请参考以下文章