Python第四课 列表,元组和字符串的使用
Posted 笔触狂放
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python第四课 列表,元组和字符串的使用相关的知识,希望对你有一定的参考价值。
4.1 列表
python中的列表类似于Java中的Object的list集合,可以在同一个列表中存放不同数据类型的数据。
4.1.1 创建列表
创建列表和创建普通变量一样,用中括号括一堆数据就可以了,数据之间用逗号隔开:
# 列表的使用
numbers=[1,2,3,4,5]
# 列表中的数据的数据类型可以不一致,也可以列表中嵌套列表使用
texts=["图片",3.14,True,1000,"abc",[1,2,3]]
# 列表的定义也可以为空,后期再进行存入数据
empty=[]4.1.2 向列表中添加元素
列表相当灵活,所有它的内存大小是不固定的,向列表中添加元素,可以使用append()方法,
# 列表中添加元素
numbers.append(6)
print(numbers) #输出结果:[1, 2, 3, 4, 5, 6]但只能一个个元素添加,而不能一次添加多个,则需要使用extend()方法:
# 列表中添加多个元素
numbers.extend([7,8,9])
print(numbers) #输出结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]该方法实际上是将一个列表追加在原列表之后,扩充了原列表。
向列表中任意位置插入元素:
# 任意位置添加元素
# 下标为0的位置上添加0
numbers.insert(0,0)
print(numbers)
# 下标为0的位置上添加一个子列表
numbers.insert(0,[-2,-1])
print(numbers)但不能给某一个位置上插入多个元素
4.1.3 从列表中获得元素
python的列表取值和Java的数组或者list集合是一样的,通过下标来获得单个元素,列表的索引值是从0开始的。
# 根据下标获得列表中元素
names=["张三","李四","王五","赵六"]
print(names[0]) #输出结果:张三
print(names[3]) #输出结果:赵六
# 修改列表中指定的元素,元素之间交换数据
names[1],names[3]=names[3],names[1]
print(names) #输出结果:['张三', '赵六', '王五', '李四']4.1.4 从列表中删除元素
从列表删除元素,这里介绍三种方法:remove(),del和pop().
# 使用remove()方法根据内容删除列表中的元素
numbers.remove(2)
print(numbers)该方法只能删除指定的单个元素。
# 使用del方法根据下标删除列表中的元素
del numbers[0]
print(numbers)
# 使用del方法删除整个列表
del numbers# 使用pop方法根据下标删除列表中的元素
# 该方法默认是将列表中末尾的元素取出来,并从列表中删除
n=numbers.pop()
print("从列表中取出的元素为:%d"%n)
print(numbers)
# 指定下标取出元素,并从列表中删除
# 取出下标为5的元素
n=numbers.pop(5)
print("从列表中取出的元素为:%d"%n)
print(numbers)4.1.5 列表分片
利用索引值每次可以从列表获取一个元素,但是这个效率还是太慢,如果能一次性获得更多的元素那就更好,这里列表的分片就能简单方便的实现:
# 列表分片
names=["张三","李四","王五","赵六"]
print(names[:2]) # ['张三', '李四']
print(names[0:2])# ['张三', '李四']
print(names[1:2])# ['李四']
print(names[1:])# ['李四', '王五', '赵六']
print(names[:])# ['张三', '李四', '王五', '赵六']通过以上的案例可以总结出,列表的分片是包头不包尾,就是根据开始的下标值获得元素,一直到结束的下标位置,但是不会输出结束下标位置的元素。如果没有开始位置,python会默认开始位置为0,同样道理,如果要得到从指定索引值到列表末尾的所有元素,把结束位置省去即可。如果没有放入任何索引值,而只有一个冒号,将得到整个列表的拷贝。
再次强调:列表分片就是建立原列表的一个拷贝,一个副本,所有如果你想对列表做出某些修改,但同时还想保持原本的哪个列表,那么直接使用分片的方法来获得拷贝就很方便了。
列表分片实际上有三个参数,第一个参数表示开始的索引下标,第二个参数表示结束的索引下标,第三个参数表示步长,用于从列表中根据下标的迭代的增值。
# 取出列表中步长为2的值
numbers=[1,2,3,4,5]
print(numbers[0:9:2]) # [1, 3, 5]
# 当步长为负数时,表示倒序获取
print(numbers[::-1]) #[5, 4, 3, 2, 1]
print(numbers[::-2])#[5, 3, 1]对列表进行分片后的赋值和原列表的直接赋值的操作情况是不同的。
#分片处理,是对原列表的拷贝,而不对原列表造成影响
list3=[1,1,22,3,4,5,33]
x1=list3[:]
x2=list3
print("x1是对list3列表的分片后的存储:%s"%x1)
print("x2是对list3列表的引用地址的存储:%s"%x2)
# 对原列表进行从小到大排序,并观察x1和x2列表的变化
list3.sort()
print("原列表排序后%s"%list3)#原列表排序后[1, 1, 3, 4, 5, 22, 33]
print("x1列表的变化%s"%x1)#x1列表的变化[1, 1, 22, 3, 4, 5, 33]
print("x2列表的变化%s"%x2)#x2列表的变化[1, 1, 3, 4, 5, 22, 33]
#通过观察可发现,分片处理是对原列表的拷贝,不受元列表的影响,是独立的。
#但x2列表是被原列表的地址赋值,也就是说list3与x2都指向原列表,属于同一块内存。4.1.6 列表的常用操作
列表可以用来比较大小,也可以用来做加减乘除的快速生成列表操作。
# 比较两个列表的大小
x1=[123,234,345]
x2=[234,123,345]
print(x1>x2) #False列表之间的比较与Java中字符串之间的比较是类似的,取各自的第一个元素进行比较,如果第一个元素的结果是True才会去比较第二个元素,如果第一个元素为False,那么不再继续比较,直接得到结果为False。
# 两列表做+法拼接
x3=x1+x2
print(x3)# [123, 234, 345, 234, 123, 345]
# 但需要需要给列表中添加单个元素,不能使用加法连接符,只能使用insert或者append方法#快速创建列表的模拟数据
a1=[8]
a1=a1*4
print(a1) # [8, 8, 8, 8]#判断列表中是否存在某个元素
print(123 in x1) # True
print(123 not in x1) #False
print(123 in x2[1]) # True
print(123 not in x2[1]) #False关键字in和not in只能判断一个层次的成员关系,与break,continue的概念是一致的,如果出现列表嵌套列表,该关键字是判断不了多层嵌套内部的元素是否存在。
4.1.7 列表的其他常用方法
以上我们学习了很多列表的增删改查的方法,其实列表还有很多方法,我们可以使用dir()函数将列表中的方法都列举出来。
#查看列表中的所有可用方法
print(dir(list)) #list就是列表的类名运行结果:
['add', 'class', 'contains', 'delattr', 'delitem', 'dir', 'doc', 'eq', 'format', 'ge', 'getattribute', 'getitem', 'gt', 'hash', 'iadd', 'imul', 'init', 'init_subclass', 'iter', 'le', 'len', 'lt', 'mul', 'ne', 'new', 'reduce', 'reduce_ex', 'repr', 'reversed', 'rmul', 'setattr', 'setitem', 'sizeof', 'str', 'subclasshook', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
以后可以通过dir()方法来查看某一个对象的常用方法。
接着我们再来学习列表中的几个常用方法:
count()这个方法的作用是计算它的参数在列表中出现的次数:
# 查找列表中某个元素出现的次数
list1=[1,1,2,3,4,8,13,21]
print("1在列表中出现的次数为:%d"%list1.count(1))# 1在列表中出现的次数为:2index()找出列表中某个元素在列表中的下标索引位置:
# 获得元素索引位置
print(list1.index(8)) # 5
#找出第一个1的索引位置
print(list1.index(1)) # 0
#找出第二个1的索引位置
print(list1.index(1,list1.index(1)+1,len(list1))) #1
#index函数的第一个参数表示要查找的元素,第二个参数表示从列表中开始搜索的索引值
#第三个参数表示结束搜索的索引值使用index函数时,如果搜索不到该元素,则会使程序报错。
reverse()方法的作用是将整个列表原地翻转,也就是倒序排列。注意这个倒序不是拷贝副本,而是原列表进行倒序。
#将列表进行倒序
list1.reverse()
print(list1) # [21, 13, 8, 4, 3, 2, 1, 1]sort()方法将乱序的列表进行排序,默认为从小到大排序
#列表排序,默认为从小到大排序
list2=[2,3,42,54,5,12,9,100]
list2.sort()
print(list2)# [2, 3, 5, 9, 12, 42, 54, 100]
#从大到小排序
list2.sort(reverse=True)
print(list2)其实sort函数中有三个参数,第一个参数func用于设置排序的算法,默认为归并排序,属于分治算法。第二个参数key用于设置关键字,第三个参数reverse用于设置是升序排序还是降序排序。
4.2 元组
Python中的元组类似与Java中的数组,也类似于字符串,长度是固定的,不能进行随意的删减添加元素。
4.2.1 创建和访问元组
元组的创建大部分时候用的是小括号,在特殊情况创建的形式会不同。
# 元组的创建和访问
tuple1=(1,2,3,4,5,6,7,8)
print(tuple1)#(1, 2, 3, 4, 5, 6, 7, 8)
# 根据索引值获得元组中的元素
print(tuple1[2],tuple1[4],tuple1[6])#3 5 7
#元组中使用分片
print(tuple1[3:])#(4, 5, 6, 7, 8)
print(tuple1[:6])#(1, 2, 3, 4, 5, 6)
元组的创建并不是完全由(小括号)决定的,而是有(,)逗号决定的。
# 初始化定义元组
temp=(1)
print(type(temp))#显示是<class 'int'>,说明小括号并不是定义元组的关键写法
temp=1,
print(type(temp))#显示是<class 'tuple'>,说明逗号才是定义元组的关键写法
#当需要初始化一个空元组的时候,可以使用小括号表示
temp=()
print(type(temp))#<class 'tuple'>
#当定义有值的元组时,有以下两种用法
temp=(1,)
print(type(temp))#输出结果为:<class 'tuple'>
temp=1,
print(type(temp))#输出结果为:<class 'tuple'>
#快速生成元组数据
temp=8,
temp=temp*8
print(temp)#(8, 8, 8, 8, 8, 8, 8, 8)4.2.2 更新和删除元组
元组不能和列表的使用一样在原列表中进行修改和删除数据,元组是固定的,那么如果要修改和删除数据,只能和字符串拼接的操作一样去处理元组的数据的更新。
# 元组的修改和删除
texts=("苹果","香蕉","西瓜","脐橙")
#该元组中香蕉的后面插入一个榴莲,使用+加法连接符将三个元组连接起来
texts=texts[:2]+("榴莲",)+texts[2:]
print(texts)# ('苹果', '香蕉', '榴莲', '西瓜', '脐橙')
#将元组中的西瓜删除
texts=texts[:3]+texts[4:]
print(texts)# ('苹果', '香蕉', '榴莲', '脐橙')
#如果要删除整个元组,只需要del即可
del texts在日常生活中,很少使用del去删除整个元组,因为Python的回收机制会在这个元组不再被使用到的时候自动删除。在元组中,也可以正常使用拼接操作符,关系运算符,逻辑运算符,算术运算符以及in,not in。
4.3 字符串
在学习列表和元组的知识中,我们掌握了一个很重要的知识就是分片,实际上字符串和元组很像,因此字符串中也能使用分片技术。在Python中是没有字符这个类型的,单个字符只会认为是长度为1的字符串。
#字符串的使用
text="hello python!!!"
print(text[6:])#python!!!
#根据索引值获得单个字符串
print(text[6])#p
#在字符串中插入子字符串
text=text[:6]+"P"+text[7:]
print(text)#hello Python!!!字符串的更新与元组的更新是一致的,将原字符串组合成一个新的字符串,存储在新的内存中,原字符串的内存会被Python的垃圾回收机制进行自动回收。
4.3.1 常用内置方法
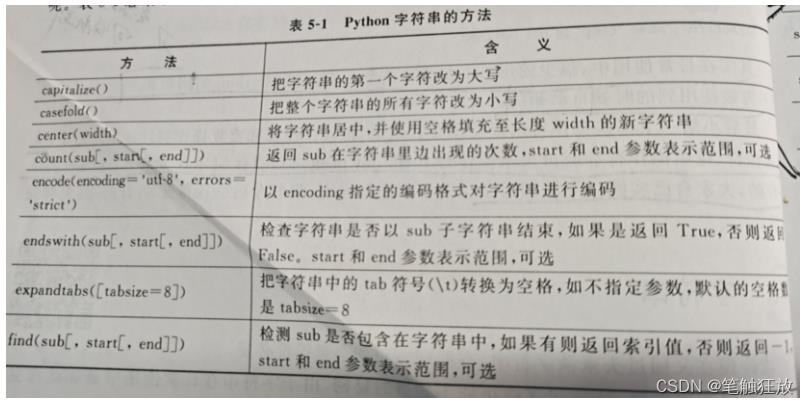

# 将字符串全部变为小写字母
s1="I'm Chinese"
s1=s1.casefold()
print(s1)#i'm chinese
# 查找某个子字符串在字符串中出现的次数,该方法是区分大小写的
s2="aBabAbababAABBAB"
print(s2.count("ab",0,len(s2)))# 3
# find()和index()都是用来查找子字符串在原字符串中的索引值
#到哪前者如果没找到则返回值为-1,后者则会直接报错,后期可以通过异常捕获处理
print(s2.find("AA",0,len(s2)))#10
print(s2.index("BB",0,len(s2)))#12
#给字符串中插入分隔符
s3="I is boy"
s3="_".join(s3)
print(s3)#I_ _i_s_ _b_o_y
#使用join()方法可以快速的将列表或者元组转换成字符串格式,做大量的字符串的拼接
print(" ".join(["abc","123","456","True","3.14","123"]))#abc 123 456 True 3.14 123
print(" ".join(("abc","123","456","True","3.14","123")))#abc 123 456 True 3.14 123
#将原字符串中某个子字符串查找后使用新的子字符串进行替换
s4="I Love You"
print(s4.replace("You","girl"))# I Love girl
# 将字符串按某个分隔符进行分割成列表,该方法与join()方法是刚好相反
s5="I_ _i_s_ _b_o_y"
s5=s5.split("_")
print(s5)# ['I', ' ', 'i', 's', ' ', 'b', 'o', 'y']4.3.2 格式化
这里的格式化其实类似于占位符,将不确定的数据用某种符号格式进行占位,等确定了数据后将数据替换占位符。
#格式化
s6="0 Love 1"
print(s6.format("You","Me"))#You Love Me
print(s6.format("boy","girl"))#boy Love girl
s7="a eat b and c"
print(s7.format(a="I",b="apple",c="banana"))#I eat apple and banana
#通过以上代码的演示用数字作为占位符是直接按顺序替换即可,用字母作为占位符时,替换的时候一定需要加上占位符的变量名
#python中可以将两种用法综合使用,但是数字的占位符一定要放置在字母占位符之前使用,否则会产生语法异常
#打印出大括号,需要嵌套一层大括号,这里就不再表示占位符了
print("0".format())#0
#控制浮点数的位数,表示为1位整数,两位小数,需要注意的是小数前需要添加.,表示四舍五入保留两位小数
print("0:1:.2f".format("圆周率",3.1415926))格式化操作符: %
| 符号 | 含义 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 用科学计数法格式化浮点数 |
| %g | 根据值的大小决定使用%f还是%e |
| %G | 根据值的大小决定使用%f还是%E |
#将字符a的ASCII码的值97转换成字符
print("ASCII码为%d对应的字符是%c"%(97,97))#ASCII码为97对应的字符是a
print("%c%c%c%c"%(70,105,115,104))#Fish
print("%d转换成八进制为%o"%(123,123))#123转换成八进制为173
print("%d转换成十六进制为%x"%(123,123))#123转换成十六进制为7b
print("%f用科学计数法表示%e"%(149500000,149500000))#149500000.000000用科学计数法表示1.495000e+08
print("%f用科学计数法表示%E"%(149500000,149500000))#149500000.000000用科学计数法表示1.495000E+08格式化操作符的辅助指令
| 符号 | 含义 |
|---|---|
| m.n | m是显示的最小总长度,n是小数点后的位数 |
| - | 结果左对齐 |
| + | 在整数前面显示加号 |
| # | 在八进制数前面显示“0o”,在十六进制数前面显示“0x”或“0X” |
| 0 | 显示的数字前面填充“0”代替空格 |
# 将该浮点数保留5位整数,1位小数进行四舍五入的浮点数
print("%5.1f"%27.658)#27.7
# 将该浮点数保留1位整数,2位小数进行四舍五入的科学计数法
print("%.2e"%27.658)#2.77e+01
# 将数字保留10位数的整数,默认靠右对齐,前面以空白填充
print("%10d"%27.658)# 27
# 将数字保留10位数的整数,靠左对齐,后面以空白填充
print("%-10d"%27.658)#27
# 将数字保留10位数的整数,默认靠右对齐,前面以0填充
print("%010d"%27.658)#0000000027
# 将十进制转换成十六进制,并添加进制符号
print("%#X"%100)#0X64
转义字符及含义
| 符号 | 说明 | 符号 | 说明 |
|---|---|---|---|
| \\' | 单引号 | \\r | 回车符 |
| \\" | 双引号 | \\f | 换页符 |
| \\a | 发出系统响铃声 | \\o | 八进制数代表的字符 |
| \\b | 退格符 | \\x | 十六进制数代表的字符 |
| \\n | 换行符 | \\0 | 表示一个空格符 |
| \\t | 横向制表符(Tab) | \\\\ | 反斜杠 |
| \\v | 纵向制表符 |
4.4 序列
这里对列表,元组,字符串之间的共性做一个汇总,并使用常用的几个方法对列表,元组和字符串之间的互相转换进行操作。
-
都可以通过索引得到每一个元素
-
默认索引值总是从0开始
-
可以通过分片的方法得到一个范围内的元素的集合
-
有很多共同的操作符
下面介绍一下常用BIF(内建方法):
4.4.1 list([iterable])
该方法可以将字符串,元组转换成列表
#创建空列表
list1=list()
print(list1)#[]
#将字符串转换为列表
list2=list("abcdefg")
print(list2)#['a', 'b', 'c', 'd', 'e', 'f', 'g']
#将元组转换为列表
list3=list((1,2,3,4,5,6,7))
print(list3)#[1, 2, 3, 4, 5, 6, 7]4.4.2 tuple([iterable])
该方法可以将字符串,列表转换成元组
#创建空元组
t1=tuple()
print(t1)#[]
#将字符串转换为元组
t2=tuple("abcdefg")
print(t2)#('a', 'b', 'c', 'd', 'e', 'f', 'g')
#将列表转换为元组
t3=tuple([1,2,3,4,5,6,7])
print(t3)#(1, 2, 3, 4, 5, 6, 7)4.4.3 str(obj)
将obj对象转换为字符串,这里包括各种数据类型,在前面已介绍过。
#将浮点型转换成字符串
r1=str(3.14)
print(r1)4.4.4 len(sub)
该方法用于获得列表,元组或者字符串的长度
#获得字符串长度
str1="aaaaaaaaaaa"
print(len(str1))
#获得列表长度
list1=["a",123,True]
print(len(list1))
#获得元组长度
tuple1="a","b","c","d"
print(len(tuple1))4.4.5 Max(……)和Min(……)
该方法用于获得字符串,列表,元组中最大值和最小值的元素,一般操作在数字上比较多。但一定要保证每一个元素的数据类型是一致的。
# 获得最大值,最小值
list1=[1,18,13,0,-98,34,54,76,32]
print("列表中最大值为:%d,最小值为:%d"%(max(list1),min(list1)))
str1="I Love fishc.com"
print("字符串中最大值为:%s,最小值为:%s"%(max(str1),min(str1)))
t1=(5,8,1,13,5,29,10,7)
print("元组中最大值为:%s,最小值为:%s"%(max(t1),min(t1)))运行结果:
列表中最大值为:76,最小值为:-98 字符串中最大值为:v,最小值为: 元组中最大值为:29,最小值为:1
4.4.6 sum(iterable[,start])
该方法用于做累加求和。
#累加求和
list1=[1,2,3,4,5]
print(sum(list1))#15
print(sum(list1,100))#1154.4.7 sorted(iterable,key=none,reverse=False)
该方法用于返回一个排序的列表,与sort()内建方法实现的效果是一致的,但sort()函数是将原列表进行排序,而该方法是拷贝一个副本进行排序,原列表不受影响。
#列表排序
list1=[1,18,13,0,-98,34,54,76,32]
#将列表分片获得副本
list2=list1[:]
#将原列表进行sort内建方法排序
list1.sort()
print(list1)#[-98, 0, 1, 13, 18, 32, 34, 54, 76]
list3=sorted(list2)
print(list3)#[-98, 0, 1, 13, 18, 32, 34, 54, 76]
print(list2)#[1, 18, 13, 0, -98, 34, 54, 76, 32]通过输出结果可以发现,sort内建函数直接将list1列表进行排序了,而通过分片获得的副本list2在通过sorted函数做排序之后,又获得一个副本list3,其原本list2并没有发现变化。
4.4.8 reversed(sequence)
该方法用于返回逆向迭代序列的值,其效果和reverse内建函数的效果是一致的,都是将列表数据进行倒序输出,但内建函数是将原列表进行倒序,而该方法是拷贝一个副本进行倒序,原列表并不受影响,但倒序后获得的不是列表而是迭代对象,不能进行直接输出。
#列表倒序
print(reversed(list1))# <list_reverseiterator object at 0x0000000002938B00>
for i in reversed(list1):
print(i,end=",")
#76,54,34,32,18,13,1,0,-98,通过输出结果发现反转后获得的是迭代对象,并不是列表也不是元组,因此输出的时候是一个列表反转后的迭代对象,打印的是地址编码。只能通过循环遍历获得,并在每次输出后面填逗号拼接。
4.4.9 enumerate(iterable)
该方法是将字符串,列表或者元组转换成枚举类型的迭代对象输出,该迭代由索引值和元素组成。
#转换成枚举类型迭代输出
str1="Fish"
for i in enumerate(str1):
print(i)
for i in enumerate(list1):
print(i)第一个循环输出结果为:
(0, 'F') (1, 'i') (2, 's') (3, 'h')
第二个循环输出结果为:
(0, -98) (1, 0) (2, 1) (3, 13) (4, 18) (5, 32) (6, 34) (7, 54) (8, 76)
4.4.10 zip(iter1[,iter2[……]])
该方法用于返回由各个可迭代参数共同组成的元组。例如列表,字符串,元组进行每项组合压缩成一个元素显示,类似于打包,但要求项数保持一致。
#数据打包
list1=[2,4,6,8,10]
str1="abcde"
t1=1,3,5,7,9
for i in zip(list1,str1,t1):
print(i)结果为:
(2, 'a', 1) (4, 'b', 3) (6, 'c', 5) (8, 'd', 7) (10, 'e', 9)
以上是关于Python第四课 列表,元组和字符串的使用的主要内容,如果未能解决你的问题,请参考以下文章