django+drf_haystack+elasticsearch
Posted 骑台风走
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了django+drf_haystack+elasticsearch相关的知识,希望对你有一定的参考价值。
0.前提准备
1. 准备好django2.2
2. 创建一个app
3.elasticsearch7.5启动
4.可视化工具(实在没有,也没啥)1.安装
pip3 install jieba -i https://pypi.douban.com/simple/
pip3 install django-haystack -i https://pypi.douban.com/simple/
pip3 install drf-haystack -i https://pypi.douban.com/simple/
pip3 install elasticsearch==7.6.0 -i https://pypi.douban.com/simple/
pip3 install django==2.2 -i https://pypi.douban.com/simple/2.setting.py
es其他版本配置
Haystack 入门 — Haystack 2.5.0 文档 (django-haystack.readthedocs.io) https://django-haystack.readthedocs.io/en/master/tutorial.html
https://django-haystack.readthedocs.io/en/master/tutorial.html
# 注册
INSTALLED_APPS = [
...
'haystack',
'rest_framework',
...
]
# 配置7.x
HAYSTACK_CONNECTIONS =
'default':
'ENGINE': 'haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine',
'URL': 'http://127.0.0.1:9200/',
'INDEX_NAME': 'haystack',
,
3.配置 drf_haystack
3.1 目录介绍
文字介绍
app01/templates/search/indexes/app01/jtsgb_text.txt
indexes:是你要建立的索引的app,jtsgb是你要建立索引的那个模型名(小写)
图解
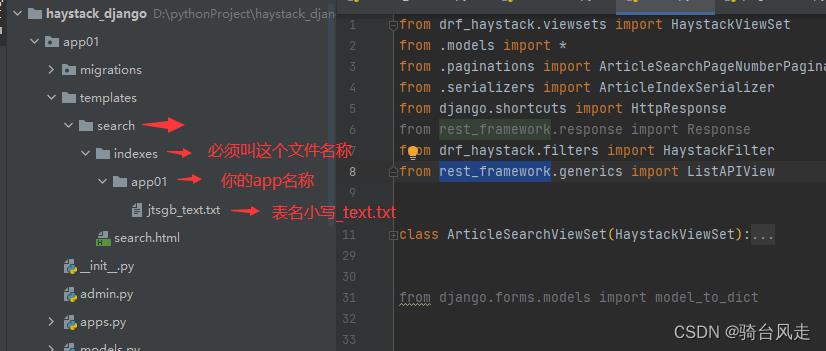
3.2 jtsgb.text.txt
意思为使用jtsgb模型的name和zzxm,id作为索引进行查询,也可以创建多个字段。
object.name
object.zzxm
object.id 4. search_indexes.py
4.1 介绍
es与model类字段相对应,在你对应要,创建索引的表的APP的根目录下,创建这个文件4.2 4.2
4.2 search_indexes.py
索引模型类的名称必须是 模型类名称 + Index
from haystack import indexes
from .models import jtsgb
# 必须继承 indexes.SearchIndex, indexes.Indexable
# jtsgbIndex是固定格式命名,jtsgb是你models.py中的类名
class jtsgbIndex(indexes.SearchIndex, indexes.Indexable):
# 以下的字段,是es里面对应的字段
# 第一个必须这样写
# document=True: 1-表示该字段为主要搜索查询的字段 2-表示该字段的索引值由模型类的多个字段组成
# use_template:表示通过模板文件来指定该字段的索引由哪些模型字段组成
text = indexes.CharField(document=True, use_template=True)
# 下面的就是和你model里面的一样了
# 注意:这里修改的话一定要重新建立索引,才能生效。python manage.py rebuild_index
# model_attr指定为对应模型的哪个字段
id = indexes.IntegerField(model_attr='id')
name = indexes.CharField(model_attr='name')
zzxm = indexes.CharField(model_attr='zzxm')
tag_name = indexes.CharField(model_attr='tag_name', null=True)
# 必须这个写,返回的就是你的model名称
def get_model(self):
"""返回建立索引的模型类"""
# 每次查询都走这个
# print(1)
return jtsgb
# 返回你的查询的结果,可以改成一定的条件的,但是格式就是这样
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
# 写入es的数据
# 对于外键字段的处理
query_set = self.get_model().objects.all()
# 外键字段写入es,把字符串对象变成对象的name
for item in query_set:
item.tag_name = item.tag.name
item.save()
return query_set
5. serializers.py
from .search_indexes import *
from drf_haystack import serializers
class ArticleIndexSerializer(serializers.HaystackSerializer):
"""
文章索引结果数据序列化器
"""
# 自定义字段,可以是新增,也可以是自定义返回类型
added = serializers.serializers.SerializerMethodField() # 注意此处是一个额外添加的字段
class Meta:
index_classes = [jtsgbIndex] # 索引模型,可以添加多个
fields = ('id', 'name', 'zzxm', 'added')
def get_added(self, obj): # 名字与字段相对应
return "added"
#
6. views.py
from drf_haystack.viewsets import HaystackViewSet
from .models import *
from .paginations import ArticleSearchPageNumberPagination
from .serializers import ArticleIndexSerializer
from django.shortcuts import HttpResponse
from rest_framework.response import Response
from drf_haystack.filters import HaystackFilter
from rest_framework.generics import ListAPIView
class ArticleSearchViewSet(HaystackViewSet):
"""
文章搜索
"""
index_models = [jtsgb] # 表模型,可以添加多个
serializer_class = ArticleIndexSerializer
pagination_class = ArticleSearchPageNumberPagination
# 这时filter,这里用到了type
filter_backends = [HaystackFilter]
filter_fields = ("name",)
# 重写,自己可以构造数据
def list(self, request, *args, **kwargs):
response = super(ArticleSearchViewSet, self).list(request, *args, **kwargs)
data = response.data
# print(data)
return response
from django.forms.models import model_to_dict
def update(request):
# 修该可以同步
"""
obj = jtsgb.objects.filter(id=1).first()
obj.name = '卡车上课'
obj.save()
"""
# book_list = []
# for i in range(100000):
# book_obj = jtsgb(name='爱%s' % i, zzxm='%s' % i)
# book_list.append(book_obj)
# jtsgb.objects.bulk_create(book_list)
# 新增可以自动同步
# jtsgb.objects.create(name='大宝', zzxm='小宝')
""" """
"""
# 不可以
jtsgb.objects.filter(id=2).update(name='兰溪市')
"""
return HttpResponse('ok')
class ReadListAPIView(ListAPIView):
queryset = ''
serializer_class = ''
7.urls.py
from django.contrib import admin
from django.urls import path, re_path
from app01 import views
# # 路由方式一,首页即可看到数据
# 全部查询
# http://127.0.0.1:8000/search/
# 查询一条
# http://127.0.0.1:8000/search/1/
# 页码为2的
# http://127.0.0.1:8000/search/?page=2
# 查询ame=卡车的,模糊查询
# http://127.0.0.1:8000/search/?name=卡车
# and
# http://127.0.0.1:8000/search/?name=看&zzxm=896
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('search', views.ArticleSearchViewSet, basename='search_api')
# router.register("", views.ArticleAPIView)
urlpatterns = [
re_path(r'^$', views.ArticleSearchViewSet.as_view('get': 'list')),
path('admin/', admin.site.urls),
path('update/', views.update)
]
urlpatterns += router.urls
# 路由方式二,大黄页
"""
# http://127.0.0.1:8000/get_many/
# http://127.0.0.1:8000/get_one/3/
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'get_one/(?P<pk>\\d+)/', views.ArticleSearchViewSet.as_view('get': 'retrieve')),
path('get_many/', views.ArticleSearchViewSet.as_view('get': 'list')),
]
"""
8.paginations
from rest_framework.pagination import PageNumberPagination
class ArticleSearchPageNumberPagination(PageNumberPagination):
"""文章搜索分页器"""
# 每页显示几条
page_size = 10
# 最大数量
max_page_size = 20
# 前端自定义查询的数量,?size=10
page_size_query_param = "size"
# 查询参数
page_query_param = "page"
9. models.py
from django.db import models
# Create your models here.
class jtsgb(models.Model):
name = models.CharField(max_length=225, db_index=True)
zzxm = models.CharField(max_length=225)
# 外键
tag = models.ForeignKey(to='Tag', on_delete=models.DO_NOTHING)
# 用于显示外键得字段,由于直接写入es的,是对象的字符串名称,无法使用
tag_name = models.CharField(max_length=225, null=True, blank=True)
class Tag(models.Model):
name = models.CharField(max_length=225)
10.执行
python manage.py makemigrations
python manage.py migrate
# 重新创建索引,删掉之前的,进行数据同步
python manage.py rebuild_index
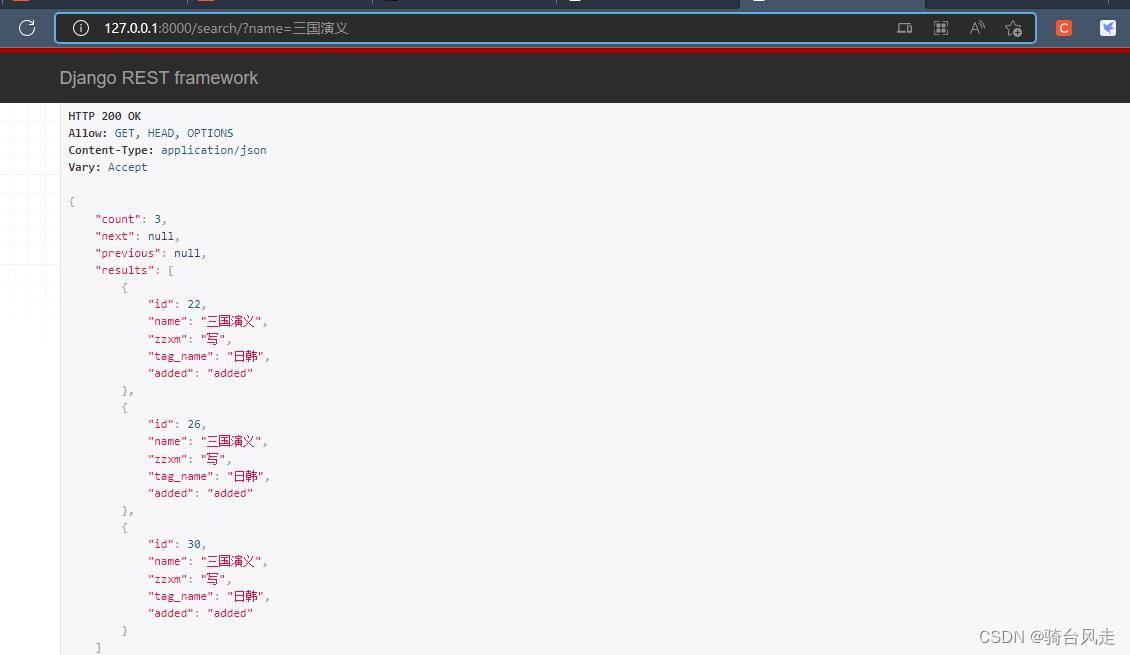
11. 验证是从es中查询的数据
1.直接修改mysql数据库数据,查看查询的数据会不会改变,不改就是es,改了就是mysql
以上是关于django+drf_haystack+elasticsearch的主要内容,如果未能解决你的问题,请参考以下文章