0-Volcano是什么,和 kube-batch与kubeflow是什么关系
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0-Volcano是什么,和 kube-batch与kubeflow是什么关系相关的知识,希望对你有一定的参考价值。
前言
一直想把关于资源调度及资源管理的想法和经验做一些分享,但每次因为没有找到合适的故事线而一拖再拖。Volcano开源以后,发现很多问题在没有背景的情况下很难解释清楚。

因此,希望以 Volcano 为线索把资源调度及资源管理方面的想法展开。形式上就以Q&A的方式展开,省去了每次繁琐的铺垫,也可以根据情况加入或删除相应的内容。有什么问题请关注此公众号并留言,也会针对大家比较关心的留言分享一些想法。另外,想法及分享仅代表个人观点,望勿“过度”解读。
1. 为什么会有 Volcano 这样一个项目?需要解决什么问题?
Volcano 的历史或是想法可以一直追溯到2016年,甚至更早。早年的工作以 IBM Spectrum Symphony 为主,Symphony 是一个典型的二级调度 (Two-level scheduler)系统。
但在后续的开发及使用过程中,逐渐发现两级调度系统存在的一些问题。在调研了一些流行的集中式调度器 (Monolithic scheduler, e.g. Slurm)之后,一直在想是否可以有一个系统同时支持两种调度模型?
因为两种调度模型都有非常成功的案例:二级调度的 Mesos 和 Yarn,集中式调度的 Slurm 和 Kubernetes。随着后续容器的流行,越来越多的服务类应用 (也称作 “在线”,“长稳作业” 等) 也以容器的形式运行在分布系统中;扩展了早期分布式系统的作业类型。这也促使 “构建统一分布式平台” 成为了新的目标。
为了实现“统一平台”的目标,有多种不同的方式;在权衡之后,最终选取了 Kubernetes 作为基础平台进行开发:
- Kubernetes 社区足够活跃,而且 Kubernetes 社区有很强的意愿支持计算类任务,例如 kubeflow, spark-on-kuberentes, spark-operator
- Kubernetes 有较好的扩展性,而且预测“扩展性”也会是其后继的重点之一 (参见 https://jaxenter.com/kubernetes-interview-ma-148956.html )
- Kubernetes 对 服务类应用 已经有很好的支持,这正好跟自己在 “计算类任务” 方面的经验互补
目标及基础平台确定之后,也基本确定了 Volcano 的项目范围和需要解决的问题:
- Volcano 对 Kubernetes 在计算领域的能力进行增强,例如 kubeflow, spark, horovod/mpi
- Volcano 基于 Kubernetes 的扩展机制对其进行加强,例如 CRD, customized scheduler
总的来说,Volcano是基于Kubernetes构建的一个通用批量计算系统;帮助 Kubernetes弥补在“计算类任务”方面不足,帮助Kubernetes构建统一的容器平台。
2. Volcano 与 kube-batch 是什么关系?
就目标而言,**Volcano的目标是创建一个批量计算系统 (batch system),而kube-batch只是这个系统中的调度器 (batch scheduler) 部分。**虽然仅有一词之差 (系统 vs. 调度器),但是项目的范围却相差较多。
这也是为什么 Volcano 作为一个单独的项目存在,而没有继续在kubernetes-sigs下继续开发。
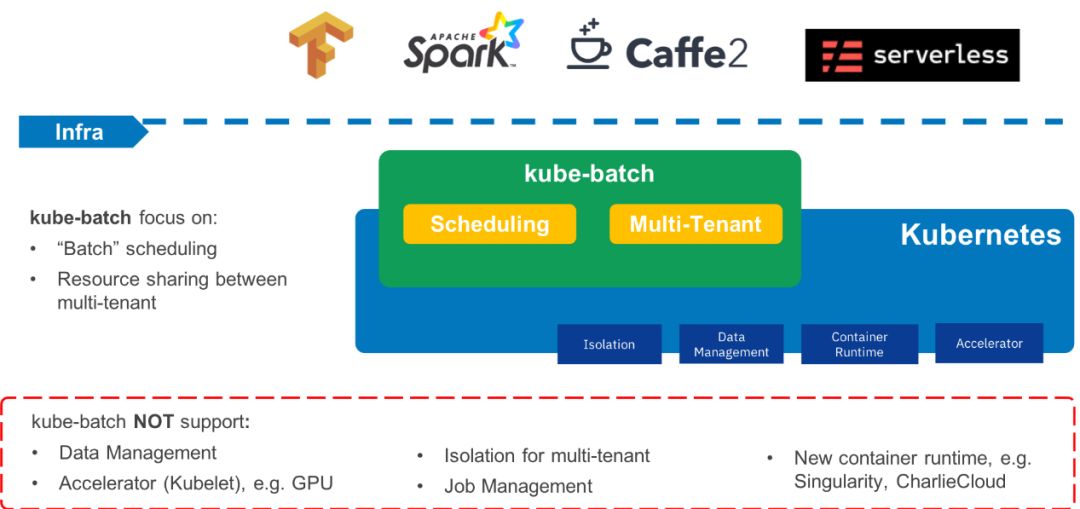
上图描述了 kube-batch 的项目范围,同时也描述了 volcano 项目的范围:
- kube-batch 仅是一个调度器,为计算类作业提供了相应的调度算法支持;但仅有调度器还不足以支持相应的批量计算作业,作为一个批量计算系统还需要其它很多组件的支持,例如 作业管理,数据管理,资源规划等等。
- Volcano 作为一个批量计算系统,包括了 调度器,作业管理,数据管理等组件在内的所有必须组件,以提供端到端的批量计算系统。因此,Volcano 作为独立项目进行孵化;并希望将Volcano贡献到CNCF ( https://github.com/cncf/toc/pull/318 ).
3. Volcano 与 kubeflow/spark-operator 是什么关系?
Volcano 是对 Kubernetes 进行的加强,因此与kubeflow/spark-operator更多的是一种合作关系。Volcano 作为新一代的批量计算系统,不仅支持二级调度模式也提供了集中式调度模式;这就为与多种计算框架的集成提供了便捷。在与kubeflow的集成中,kubeflow/tf-operator仅使用了 Volcano 的调度器部分,而 **kubeflow/arena 则使用了 作业管理及调度器两部分;**在与 spark-operator的集成过程中,spark-operator 也仅使用了调度器部分,包括正在进行的与 spark-on-kubernetes的集成。
以上是关于0-Volcano是什么,和 kube-batch与kubeflow是什么关系的主要内容,如果未能解决你的问题,请参考以下文章