详解Spark Streaming的Graceful Shutdown
Posted Mr-Bruce
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解Spark Streaming的Graceful Shutdown相关的知识,希望对你有一定的参考价值。
对于Spark Streaming程序而言,一旦运行起来后,就会不断的从数据流中消费数据,按照Batch间隔生成BatchRDD进行处理,即处于7*24小时运行的状态,除非我们主动将其停止或者遇到异常退出。所谓Graceful Shutdown,即优雅的将Spark Streaming程序停止,本文将重点探讨三点(写作背景:Spark 2.2):
- 为什么需要Graceful Shutdown?
- 如何触发Graceful Shutdown?
- Graceful Shutdown过程是怎样的?
为什么需要Graceful Shutdown
考虑使用Graceful Shutdown的前提是,业务对数据的准确性要求很高,不允许数据丢失。如果这个前提不成立,其实可以不使用Graceful Shutdown,直接采用"yarn -kill application_id"即可。
Spark Streaming是基于micro-batch机制工作的,程序在运行中,由Receiver负责从Stream中不断读取数据(比如1秒读取一次),当Batch Interval到达时,会将收下来的数据组合成一个新的BatchRDD来处理。在这个过程中,如果程序出现异常退出,可能会导致正在处理的BatchRDD中的数据或者已经接收下来但是还没有生成BatchRDD的数据丢失。为了避免数据丢失,Spark Streaming引入了Checkpoint和WAL机制,将程序运行的上下文信息和接收的数据持久化到磁盘,从而可以在异常退出后能恢复到上次继续处理。
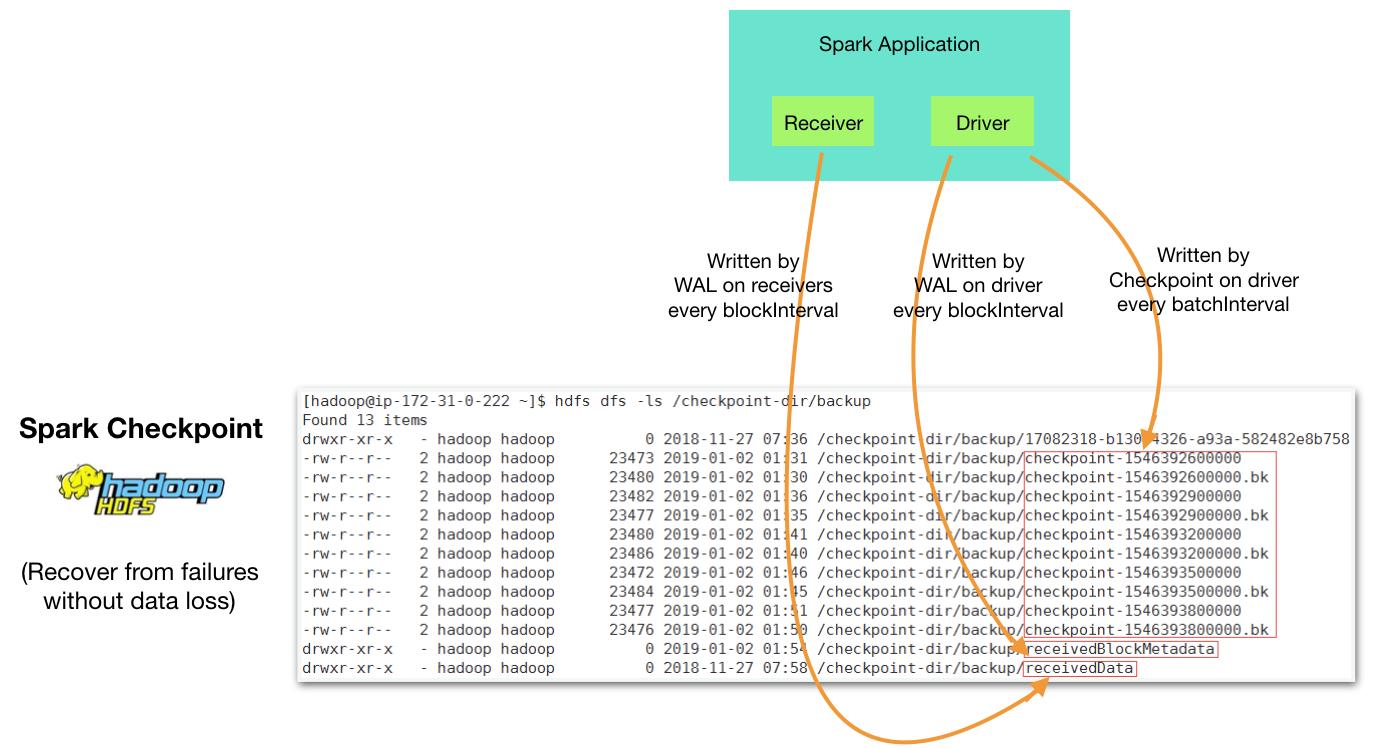
Checkpoint机制保证了数据不丢失,但是为程序更新带来了隐患。因为保存下来的数据中包含了当前程序运行的上下文信息,将程序停止、更换新的代码、再重新启动起来时,轻则更新的代码没有生效,重则程序报错无法运行。因此,更新Spark Streaming程序代码时,必须将Checkpoint清除掉,可是这样又引入了数据丢失的问题。
Graceful Shutdown便是为解决这样的问题而生。通过Graceful Shutdown,首先将Reciever关闭,不再接收新数据,然后将已经收下来的数据都处理完,最后再退出。这样一来,Checkpoint就可以被安全删除了。
如何触发Graceful Shutdown
关于如何触发Graceful Shutdown,Spark官方文档并没有给出具体的方法。从代码来看,是通过Hadoop的ShutdownHook来实现的,StreamingContext在初始化时会注册一个Hook函数。因此,理论上一切可以触发Shutdown Hook的方法都可以触发Spark Streaming的Graceful Shutdown。
logDebug("Adding shutdown hook") // force eager creation of logger
shutdownHookRef = ShutdownHookManager.addShutdownHook(
StreamingContext.SHUTDOWN_HOOK_PRIORITY)(stopOnShutdown)
private def stopOnShutdown(): Unit =
val stopGracefully = conf.getBoolean("spark.streaming.stopGracefullyOnShutdown", false)
logInfo(s"Invoking stop(stopGracefully=$stopGracefully) from shutdown hook")
// Do not stop SparkContext, let its own shutdown hook stop it
stop(stopSparkContext = false, stopGracefully = stopGracefully)
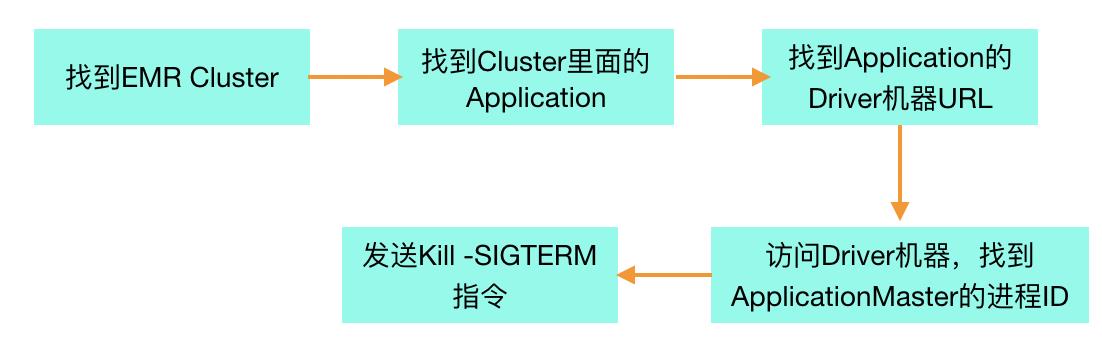
笔者推荐的方法是:发送"kill -SIGTERM pid"信号给Driver进程,在YARN Cluster模式下,也就等同于ApplicationMaster进程。这种做法对代码本身没有任何侵入,具体方法是:
- 设定Spark配置项: spark.streaming.stopGracefullyOnShutdown = true
- 发送指令:kill -SIGTERM ApplicationMaster_PID
自动化脚本可以参考:git: spark_streaming_graceful_shutdown。因为笔者所在产品的Spark业务都是部署在AWS EMR服务上面,所以主要针对如何对EMR上面某个Cluster里面的某个Spark Streaming Application进行Graceful Shutdown而言,基本思路是如下。
Graceful Shutdown 过程
了解了什么情况下用、怎么用Graceful Shutdown就基本可以应对大多数的场景了,但是人类的好奇心岂会停止?用过Graceful Shutdown的人都会发现,它需要经历2~3 Batch的间隔才会完全停下来,为什么需要这么久?中间在做什么?Graceful Shutdown真的可以做到数据不丢失吗?以笔者的业务为例,就出现了数据丢失,当然缘由是我们对Spark Streaming源码的一处定制改动引发的。
要搞清楚个中缘由,阅读源码自然是最佳途径,从上面提到的stopOnShutdown入手,一路看下去即可。这里笔者将尽可能跳过源码,以两张图的形式来简单介绍,这两张图也是笔者在公司内部分享时使用的。
第一种图,是Graceful Shutdown被触发后,Driver中的Spark日志信息(这里的Batch Interval是5分钟)。从图中可以看到,整个过程基本可以分为四个步骤:
- 在09:03:33时发送SIGTERM信号,StreamingContext进入Graceful Shutdown阶段;
- 发送信号给所有的Receiver,通知Receiver退出,Receiver退出的具体工作由Receiver所在的Executor来完成;
- 停止JobGenerator,这个过程从09:04:20持续到09:15:01才结束,包含了三个Batch时间(09:05:00、09:10:00、09:15:00),确保接收的数据被处理完并不再产生新的Job;
- 按顺序停止其他各个资源

可以看到,"停止JobGenerator"是整个过程的重点,第二张图主要针对这点。从图中可以看到:
- 由于Spark Streaming是按照Batch Interval来运转的,已经接收下来但是还没有分配到BatchRDD中的数据,需要等到一个新的Batch到来才会被分配。因此这里可能需要花费1个Batch间隔的时间,之所以说是"可能",是因为如果刚好没有这种"已接收但是没有分配"的数据,就直接过了这关了。
- 停止JobGeneration Timer只是将stopped这个变量置为true而已,图中的代码为Timer里面的Loop代码,可以看到是通过双重确定来保证没有新的Job产生和处理,这个过程最多需要经历2个Batch的时间才过关。

后话
最后来说说Graceful Shutdown的缺陷,目前来看有两点:
- 整个过程需要2~3个Batch 间隔的时间,具体时间取决于Batch Interval值的设定,不管怎么说,都会出现一段时间的Downtime,能不能接受这样的行为就取决于业务了。
- 如笔者上述所言,在我们对Spark Streaming源码做了一处定制改动后,发现Graceful Shutdown变得不再可靠(后续会撰文来分享),同样的情形会不会出现在读者的业务中呢?
(全文完,本文地址:https://blog.csdn.net/zwgdft/article/details/85849153 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2019/01/06 晚
更新于2019/02/15:有新坑,请留意
笔者撰写这篇文章时,使用的是Spark 2.2.0 + Hadoop 2.7.3,后来在升级时发现了另一个坑:在Hadoop 2.8.0之后,Hadoop对ShutHookManager进行了一个调整(HADOOP-12950),会对所有Shutdown Hook函数默认设置10秒超时时间,超过就会强制停止。这个调整会导致Spark的Graceful Shutdown功能受到影响(SPARK-25020),会在Log中看到如下信息。目前社区已在Hadoop 2.9.2中修复该问题(HADOOP-15679),修复方法为增加了一个配置项:hadoop.service.shutdown.timeout,默认值为30秒。
针对这个坑,笔者建议跳过Hadoop 2.7.3与2.9.2之间的版本,并在新版本中设置hadoop.service.shutdown.timeout >= 4 * BatchInterval。
19/02/15 02:04:49 ERROR Utils: Uncaught exception in thread pool-4-thread-1
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at org.apache.spark.streaming.scheduler.JobGenerator.stop(JobGenerator.scala:132)
at org.apache.spark.streaming.scheduler.JobScheduler.stop(JobScheduler.scala:123)
at org.apache.spark.streaming.StreamingContext$$anonfun$stop$1.apply$mcV$sp(StreamingContext.scala:681)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1361)
at org.apache.spark.streaming.StreamingContext.stop(StreamingContext.scala:680)
at org.apache.spark.streaming.StreamingContext.org$apache$spark$streaming$StreamingContext$$stopOnShutdown(StreamingContext.scala:714)
at org.apache.spark.streaming.StreamingContext$$anonfun$start$1.apply$mcV$sp(StreamingContext.scala:599)
at org.apache.spark.util.SparkShutdownHook.run(ShutdownHookManager.scala:216)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1$$anonfun$apply$mcV$sp$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:1992)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply$mcV$sp(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anonfun$runAll$1.apply(ShutdownHookManager.scala:188)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.util.SparkShutdownHookManager.runAll(ShutdownHookManager.scala:188)
at org.apache.spark.util.SparkShutdownHookManager$$anon$2.run(ShutdownHookManager.scala:178)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
以上是关于详解Spark Streaming的Graceful Shutdown的主要内容,如果未能解决你的问题,请参考以下文章