大数据批量处理神器 - 自定义周期批量消费队列的实现
Posted Pushkin.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据批量处理神器 - 自定义周期批量消费队列的实现相关的知识,希望对你有一定的参考价值。
文章目录
1. 前言
工作中,我们经常需要处理各种大批量数据的逻辑处理、数据的入库。高峰期获取大量数据时,无论是数据的处理还是数据存储到库,建立的多线程或者连接到数据库的连接数都可能超出峰值,造成性能压力。
为解决这种问题场景,我们可以对读与写进行解耦,并控制峰值时处理的流速,以实现系统的稳定。
使用一些中间件比如kafka、MQ等消息队列,对于小场景的批量处理比较大材小用,故我们可以自己封装下类似队列的轮子,方便后期自己的使用。
2. 需求
eg:
- 解决离线大批量数据同步到表时,数据库连接数占用过大问题
- 解决大批量数据数据存储时数据量过大问题
- 解决网络传输数据量过大问题,事务过长,超时等问题
- 批量处理提升性能
- 要求能控制消费的批次大小以及频度
- 解耦数据读取;处理;存储
等等类似优化需求。。。。
3. 基础理论知识
常用队列类继承图:
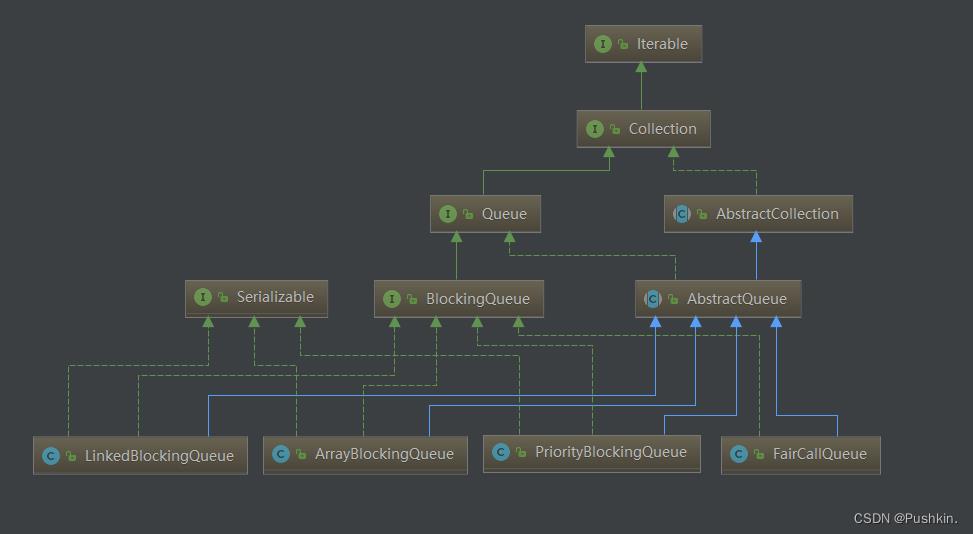
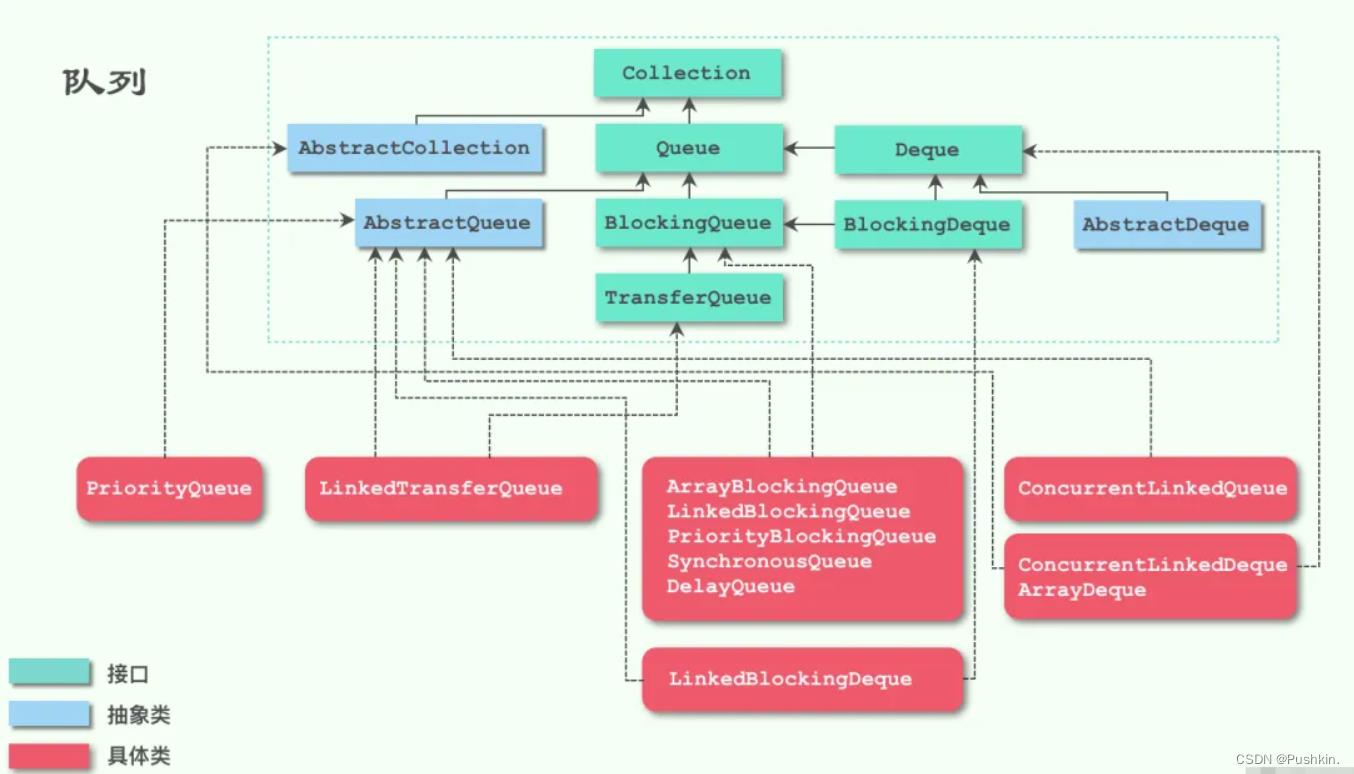
3.1 LinkedBlockingQueue
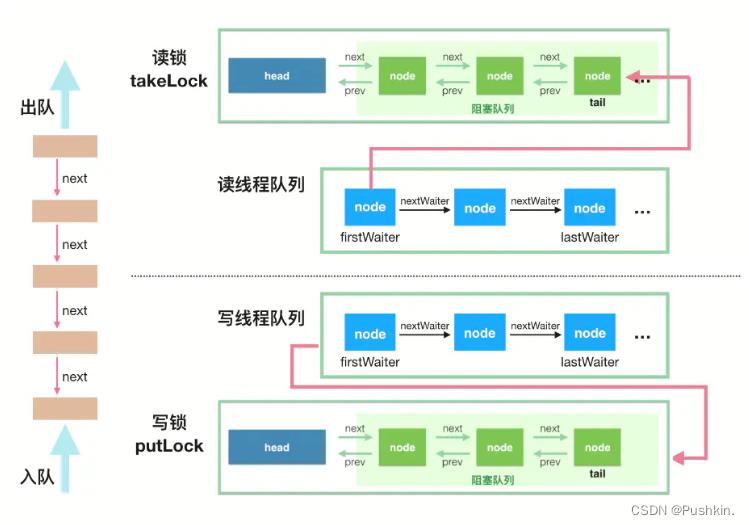
LinkedBlockingQueue基于链表实现,未指定容量时默认容量为Integer.MAX_VALUE,即无界阻塞队列,节点动态创建,节点出队后可被GC,伸缩性较好;如果消费者速度慢于生产者速度,可能造成内存空间不足,建议手动设置队列大小。采用“two lock queue”算法变体,双锁(ReentrantLock):takeLock、putLock,允许读写并行,remove(e)和迭代器iterators需要获取2个锁。
LinkedBlockingQueue同步机制:
3.2 ArrayBlockingQueue
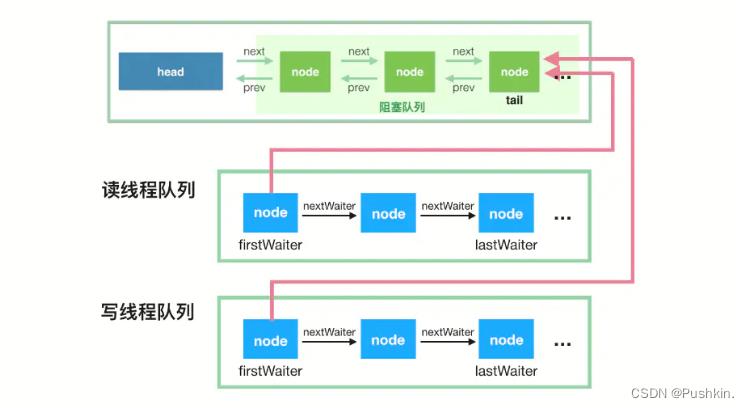
ArrayBlockingQueue底层基于数组,创建时必须指定队列大小,节点数量一开始就固定,“有界”
ArrayBlockingQueue入队和出队使用同一个lock(但数据读写操作已非常简洁),读取和写入操作无法并行。
ArrayBlockingQueue 同步机制:
3.3 对比
LinkedBlockingQueue使用双锁可并行读写,其吞吐量更高。
ArrayBlockingQueue在插入或删除元素时直接放入数组指定位置(putIndex、takeIndex),不会产生或销毁任何额外的对象实例;而LinkedBlockingQueue则会生成一个额外的Node对象,在高效并发处理大量数据时,对GC的影响存在一定的区别。
在大部分并发场景下,LinkedBlockingQueue的吞吐量ArrayBlockingQueue更好。
4. 工具类封装
V1
提取队列抽象方法类
/**
* @author pushkin
* @version v1.0.0
* @date 2022/8/24
* <p>
* Modification History:
* Date Author Version Description
* ------------------------------------------------------------
*/
public abstract class AbstractCacheQueue<T>
// 注意根据你的数据评估,是否需要限制队列大小
private final BlockingQueue<T> queue = new LinkedBlockingQueue<>();
/**
* 获取queue
*
* @return queue
*/
BlockingQueue<T> getQueue()
return queue;
public boolean add(T obj)
return queue.offer(obj);
/**
* 指定周期批量消费
*
* @param time 时间
* @param size 批量消费的大小
*/
abstract void batchConsume(long time, int size);
/**
* 指定周期单个消费
*
* @param time 时间
*/
abstract void singleConsume(long time);
/**
* 停止消费
*
*/
abstract void stopConsume();
某一消息子类的实现:
import java.util.ArrayList;
import java.util.List;
/**
* @author pushkin
* @version v1.0.0
* @date 2022/8/24
* <p>
* Modification History:
* Date Author Version Description
* ------------------------------------------------------------
*/
public class MsgQueue extends AbstractCacheQueue<String>
private static volatile Boolean START_CONSUME = true;
@Override
public void batchConsume(long sleepTime, int size)
while (START_CONSUME)
try
List<String> batchList = new ArrayList<>();
// eg: 1分钟消费500个
getQueue().drainTo(batchList, size);
Thread.sleep(sleepTime);
if (!batchList.isEmpty())
System.out.println("==================================================");
System.out.println("批量消费: " + batchList.size());
// 此处改写为你的消费逻辑,可以进行批量处理
for (String t : batchList)
System.out.println(System.currentTimeMillis()+" - 消费: "+ t);
System.out.println("==================================================");
catch (InterruptedException e)
e.printStackTrace();
@Override
void singleConsume(long time)
@Override
void stopConsume()
START_CONSUME = false;
5. 测试
public class Test
public static void main(String[] args)
MsgQueue msgQueue = new MsgQueue();
for (int i = 0; i < 10; i++)
msgQueue.add(String.valueOf(i));
// eg: 控制1秒,消费2个
msgQueue.batchConsume(1000, 2);
输出结果:
==================================================
批量消费: 2
1661274422642 - 消费: 0
1661274422642 - 消费: 1
==================================================
==================================================
批量消费: 2
1661274423659 - 消费: 2
1661274423660 - 消费: 3
==================================================
==================================================
批量消费: 2
1661274424673 - 消费: 4
1661274424673 - 消费: 5
==================================================
==================================================
批量消费: 2
1661274425684 - 消费: 6
1661274425684 - 消费: 7
==================================================
==================================================
批量消费: 2
1661274426685 - 消费: 8
1661274426685 - 消费: 9
==================================================
测试结果中,可以看到,周期性指定时间1s, 每个周期消费2条数据 (当不足2条时,等待1s后剩余的数据也会全部被消费)
以上是关于大数据批量处理神器 - 自定义周期批量消费队列的实现的主要内容,如果未能解决你的问题,请参考以下文章