shell 学习笔记
Posted 皮卡丘吉尔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell 学习笔记相关的知识,希望对你有一定的参考价值。
shell学习笔记
一. 基本语法
1.1 基本操作
- 包含头文件 用来做解析。
#! /bin/bash
上面是用 /bin/bash 来解析脚本 也可以用 /bin/sh 来解析的
- 输出信息
比如我们C的printf 在shell 可以用 echo 来输出。
下面是输出 hello world 这个字符串
#! /bin/bash
echo "hello world" #输出 hello world 字符串
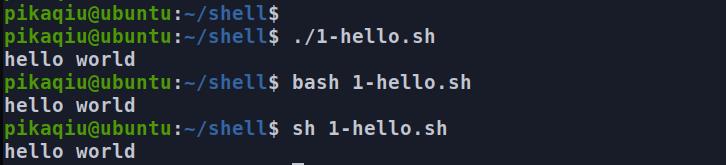
也可以直接在你的终端执行 echo "hello world" 一样的效果 如下图

- 如何运行脚本
比如你的脚本名字叫 1-hello.sh (一般会 用.sh 作为后缀,不用也可以。)
执行这个有好多种方法,我这里就写几种我想到的。
# 第一种 最常用
./xx.sh #这种你需要 给它一个可执行权限
#命令: chmod +x xx.sh 才可以执行.
# 第二种
bash xx.sh
# 第三种
sh xx.sh
也可以看下方我在终端执行的命令
- echo 的简单使用
echo 不单单就是输出信息 其实它是一个命令,其实用的别的也很多。
指令:
首先我这里建立一个文件 叫 xx 里面内容为空
touch xx
然后我通过echo 方式 写 hello world 到 xx文件中。(不先创建 xx也是可以的,如果你没有xx文件,下面指令也会给你创建的)
echo "hello world" > xx
> 是会将内容覆盖的 就是会原来有数据 将会被清空, 再写入内容
如图所示:

如果不想覆盖原来的 在后面增加进去,则可以用下方的这个
指令:
把 hello world 追加到 xx 文件
echo "hello world" >> xx
>> 是追加的方式写入文件 原有的内容保留,再末尾添加内容

1.2 变量
首先得知道下面的几种符号的含义。
$n
n:为数字 $0代表该脚本的名称 $1~$9代表第一到第九个参数,十以上的参数需要用大括号包含如 $10
$#
获取所有输入参数的个数 常用于循环 判断参数的个数是否正确以及加强脚本的健壮性。
$*
这个变量代表命令行中的所有参数 $*把所有的参数看成一个整体
$@
这个变量也代表命令行中的所有参数 不过$@把每一个参数区分对待
$?
最后一次执行的命令的返回状态,如果这个变量的值为0 证明上一个命令正确执行,如果这个变量的值
为非0 (具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了
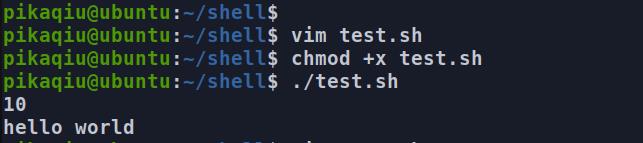
变量的定义 (变量没有类型的,所以直接写就行了)
简单的代码实例
#! /bin/bash
num=10
string="hello world"
echo $num #输出 num 的值
echo $string #输出 string 的值
运行结果:
环境变量
下面的操作只能在同一个终端才有效。
- 在终端:创建环境变量 一个
XX为 100 的这么个环境变量
export XX=100
- 在终端查看有哪些环境变量
export
- 在终端删除环境变量
XX
unset XX
- 输出环境变量XX的内容
echo $XX
- 用户级变量操作
环境变量得写到~/.profile文件中去.
比如把这个XX=100添加到~/.profile文件中去
echo "export AA=100" >> ~/.profile
执行这个指令 让上面这行 生效
source ~/.profile
输出环境变量值
echo $XX
- 系统级变量
系统级变量 那么我们得写到/etc/profile里面去
把这个 export AA=100 输出到 /etc/profile 里面去
echo "export AA=100" >> /etc/profile
执行这个文件 让我们指令生效
source /etc/profile
输出环境变量值
echo $AA
1.3 数组
#! /bin/bash
################################# 常用数组 #################################
array1=(1 2 3 4 5)
array2=('1' '2' '3' '4' '5')
array3=("111" "222" "333" "444" "555")
echo $array1[0] #输出第0个元素
echo $array2[1] #输出第0个元素
echo $array3[2] #输出第0个元素
echo $array3[@] #输出所有元素
echo $#array3[@] #输出元素个数
echo $!array3[@] #输出所有下标
echo $array3[@]:1 #输出从下标为1开始输出
echo $array3[@]:1:2 #输出从下标为1开始输出 到 下标为2结束
################################# 关联数组 #################################
#定义方式
declare -A array4
declare -A array5
#单个赋值
array4[num]=4
array4[name]="pipi"
array4[score]=60
#全部赋值
array5=([num]=5 [name]="keke" [score]=50)
#输出信息
echo $array4[@]
echo $array5[@]
1.4 命令行获取参数
这个就相当于我们 main函数的参数 int main(int argc,char **argv) 运行的时候 就带上参数。
这里先说一下 $n
n:为数字 $0代表该脚本的名称 $1~$9代表第一到第九个参数,十以上的参数需要用大括号包含如 $10
我们还是直接写个小示例
#! /bin/bash
name=$1
echo "hello $name"
echo "参数个数为 $#"
echo "所有参数为 $*"
执行结果:

1.5 数学运算 多种方法
数学运算 方式1
#! /bin/bash
# 方式1
# 注意: 用下方let 方式计算 不能有空格不能如 num=num + 100 这是错误写法
num=100
# 加法
let num=num+100
# 减法
let num=num-100
# 乘法
let num=num*100
# 除法
let num=num/100
echo $num
数学运算 方式2
#! /bin/bash
# 方式2
# 注意: 下方写法表达式内可以用空格隔开 如 num=$[ num + 100 ] 这是可以的
num=100
# 加法
num=$[num+100] 或 num=$[ num + 100 ]
# 减法
num=$[num-100] 或 num=$[ num - 100 ]
# 乘法
num=$[num*100] 或 num=$[ num * 100 ]
# 除法
num=$[num/100] 或 num=$[ num / 100 ]
echo $num
数学运算 方式3
#! /bin/bash
# 方式3
# 注意: 下方写法表达式内可以用空格隔开 如 num=$(( num + 100 )) 这是可以的
num=100
# 加法
num=$((num+100)) 或 num=$(( num + 100 ))
# 减法
num=$((num-100)) 或 num=$(( num - 100 ))
# 乘法
num=$((num*100)) 或 num=$(( num * 100 ))
# 除法
num=$((num/100)) 或 num=$(( num / 100 ))
echo $num
数学运算 方式4
#! /bin/bash
# 方式4
# 注意: 下方表达式必须 空格 隔开 !!!
num=100
# 加法
num=`expr $num + 100`
# 减法
num=`expr $num - 100`
# 乘法
num=`expr $num \\* 100` # *符号前面请加 \\
# 除法
num=`expr $num / 100`
echo $num
以上就是不同方式进行 数学运算的方法了,我个人还是觉得用 方式3 好点。
1.6 if 语句
示例代码:
1.61 if 整数比较
整数比较 方式1
用表中符号来判断 想了解判断符号可在终端输入命令 man 1 test 来查看.
| 符号 | 等价于C语言的符号 |
|---|---|
| -eq | == |
| -ne | != |
| -gt | > |
| -lt | < |
| -ge | >= |
| -le | <= |
示例:
#!/bin/bash
num=$1 #获取一个命令行参数
######################## 方式1 ########################
if [ $num -eq 100 ]
then
echo "等于100"
elif [ $num -gt 100 ]
then
echo "大于100"
else
echo "小于100"
fi
# 或者也可以加上双引号 如下
if [ "$num" -eq "100" ]
then
echo "等于100"
elif [ "$num" -gt "100" ]
then
echo "大于100"
else
echo "小于100"
fi
也可以不用上面表中符号,直接用 >、>=、 等符号 但是请用 (()) 来写。
示例
整数比较 方式2
#!/bin/bash
######################## 方式2 ########################
if (( $num == 100 ))
then
echo "等于100"
elif (( $num >= 100 ))
then
echo "大于100"
else
echo "小于100"
fi
# 或者也可以加上双引号 如下
if (( "$num" == "100" ))
then
echo "等于100"
elif (( "$num" >= "100" ))
then
echo "大于100"
else
echo "小于100"
fi
1.62 if 字符串比较
字符串比较 方式1
[]的表示方式 其中用 = 和 == 都是可以的
#! /bin/bash
string1="hello"
string2="hello"
if [ $string1 = $string2 ]
then
echo "字符串一样"
else
echo "字符串不一样"
fi
# 也可以加上双引号 如下方
#! /bin/bash
string1="hello"
string2="hello"
if [ "$string1" = "$string2" ]
then
echo "字符串一样"
else
echo "字符串不一样"
fi
字符串比较 方式2
[[]] 的表示方式 其中用 = 和 == 都是可以的
#! /bin/bash
string1="hello"
string2="hello"
if [[ $string1 == $string2 ]]
then
echo "字符串一样"
else
echo "字符串不一样"
fi
# 也可以加上双引号 如下方
#! /bin/bash
string1="hello"
string2="hello"
if [[ "$string1" == "$string2" ]]
then
echo "字符串一样"
else
echo "字符串不一样"
fi
1.7 switch语句
示例代码:
)相当于C语言的case中的:。 ;;相当于C语言的 break;
#! /bin/bash
# 获取键盘上值 (相当于C语言的 scanf)
read num
case $num in
[a-z])
echo "小写字母"
;;
[A-Z])
echo "大写字母"
;;
[0-9])
echo "数字"
;;
*)
echo "其它"
;;
esac
1.8 for 语句
for 方式1
示例代码:
#! /bin/bash
# 循环3次 分别 i 的值是 0、1、2
for ((i=0;i<3;i++))
do
touch $i
echo "hello $i" > $i
done
# 也可以用空格隔开如下
for (( i=0; i<3; i++ ))
do
echo $i
done
# 也可以用空格隔开如下
for (( i = 0; i < 3; i++ ))
do
echo $i
done
# 一般比较多的是我们去 遍历数组里面的元素 把每一个元素打印出来
#! /bin/bash
# 数组的定义
array=( "111" "222" "333" )
# 遍历每一个元素,并输出
for (( i = 0; i < $#array3[@]; i++ ))
do
echo "$i"
done
# $#array3[@] 就是指数组元素个数
# 输出结果:
111
222
333
for 方式2
#! /bin/bash
# 循环3次 分别 i 的值是 0、1、2
for i in 0..2
do
echo $i
done
# 在shell中是没有类型这说法的,所以for循环字符串也是可以的。
# 数组的定义
array=( "111" "222" "333" )
# 遍历每一个元素,并输出
for i in $array[@]
do
echo $i
done
# $array[@] 是指所有元素
# 输出结果:
111
222
333
for 方式3
# 循环3次 分别 i 的值是 0、1、2
for i in 1 2 3
do
echo $i
done
# 可以随意写 字符串也可以的
# 循环3次 分别 i 的值是 0、100、1000
for i in 1 100 1000
do
echo $i
done
# 也可以这样
# 循环3次 分别 i 的值是 111、222、333
for i in "111" "222" "333"
do
echo $i
done
1.9 while 语句
#!/bin/bash
# 死循环
while :
do
# 在这里添加要执行的代码
done
# 不断获取键盘值 并且输出 read 就相当于 C语言的 scanf()
while read i
do
echo $i
done
# 不断从xx.txt文件中读取内容 并且输出
while read i
do
echo $i
done < xx.txt
二. 正则表达式
正则表达式
通常被用来检索/替换那些符合某个模式的文本,在linux中
grep, sed, awk 等文本处理工具都支持通过正则表达式进行模式匹配。下面表中符号切记记住,因为经常会用来结合 三剑客的。
| 符号 | 描述 |
|---|---|
| ^ | 匹配行首,比如 ^hello 就是匹配以 hello 开头的行 |
| $ | 匹配结尾,比如 hello$ 就是匹配以 hello 结尾的行 |
| . | 匹配任意一个字符(除了换行符) |
| * | 前一个字符匹配0次或任意多次 |
| [] | 匹配中括号里面指定的任意一个字符,只匹配一个字符, 例如 [abc] 表示匹配a、b、c 这三个任意一个字符。[a-z] 表示匹配是小写字母,[0-9] 表示匹配是数字0~9。 |
| [^] | 匹配除了中括号的字符之外的任意一个字符,跟上述是相反的。例如 [^abc] 匹配的是除了a,b,c的其他任意字符。[^0-9] 表示匹配除了数字的任意字符。 |
1. grep
基本用法
grep 是一个文件过滤工具。
grep [options] [pattern] file
选项参数说明
作用:文本搜索工具,过滤 条件
| 选项参数 | 描述 |
|---|---|
| -i | ignorecase 忽略字符大小写 |
| -o | 仅显示匹配到的字符串本身 |
| -v | 显示不能被模式匹配的行 |
| -E | 支持用扩展的正则表达式 |
| -q | 静默模式,即不输出任何信息 |
| -n | 显示行号 |
| -c | 只统计匹配行数 |
| -w | 只匹配过滤的单词 |
| –color=auto | 使用grep过滤结果添加颜色 |
演示示例
常规匹配
一串不包含特殊字符的正则表达式 匹配它自己,例如
- 比如查看
aa.c文件 中 找 字符串abc
cat aa.c | grep adc
- 查看
aa.c文件中 以abc开头的字符串
cat aa.c | grep ^abc
- 查看
aa.c文件中 以abc结尾的字符串
cat aa.c | grep abc$
- 查看
aa.c文件中 以abc开头 并且 以abc结尾 的字符串
cat aa.c | grep ^abcabc$ (这样写法只有 abcabc 才能匹配上)
- 查看
aa.c文件中空行
cat aa.c | grep ^$
- 如果要
显示行号请加上-n
cat aa.c | grep -n ^$
- 查看
aa.c文件中 以i开头, 中间两个任意字符(包括特殊符号),f结尾的 字符串
cat aa.c | grep i..f
- 特殊字符 匹配一个任意的字符 (包括特殊字符等)
.
*
不单独使用,他和上一个字符连用,表示匹配上一个字符0次或多次,例如 下面会匹配 rot root rooot roooot…等
cat aa.c | grep ro*t
- 匹配任意一个字符 出现任意次
cat aa.c | grep .*
- 查看
aa.c文件中 以i开头 以f结尾
cat aa.c | grep ^i.*f$
- 查看
aa.c文件中 以i开头 中间随意 然后 出现in然后中间随意f结尾的字符串
cat aa.c | grep ^i.*in.*f$
字符区间[]
- [] 表示匹配某个范围内的一个字符,例如
- [6,8] 匹配6或者8
- [0-9] 匹配一个0~9的数字
- [0-9]* 匹配任意长度的数字字符串
- [a-z] 匹配一个a-z之间的字符串
- [a-z]* 匹配任意长度的字母字符串
- [a-c,e-f] 匹配a-c 或者 e-f 的任意字符
- 查看
aa.c文件中 出现 i开始 中间是字符a-z 不限个数 f
cat aa.c | grep i[a-z]*f
- 查看
aa.c文件中 出现 $字符的字符串 需要转义
cat aa.c | grep '\\$'
grep 也可以配合 选项参数 来进一步获取想要的内容。我这里就不写那么多了。
2. awk
awk 是一个强大的文本分析工具,把文件逐行的读入,以空格为默认分割符将每行切片,切开
的部分再进行分析处理。
基本用法
awk [option] 'pattern[action]' file...pattern:- 表示awk 在数据中查找的内容 就是匹配模式。
action:- 在找到匹配内容时所执行的一系列命令。
file- 对应的文件名
awk 可选参数 模式 '条件动作' 文件
选项参数说明
默认是空格作为空格符,且多个空格也识别成为一个空格 作为分隔符
awk是按行处理文件 一行处理完毕 处理下一行 …
自定义输出,必须外层单引号,内层双引号。
-F指定分隔符-v定义或修改一个awk内部的变量-f从脚本文件中读取awk命令
下面是 awk 特殊的内置变量, 这里只是列举了我常用的,更多命令 可通过 命令 man awk 查看
| 选项参数 | 描述 |
|---|---|
| $0 | 所有内容 |
| $n | 第n列。例如 $1 就是第 1 列,$10 就是第 10 列 |
| $NF | 最后一列 |
| $(NF-n) | 倒数第n列。例如 倒数第二列则是 $(NF-1) |
| NR | 行数。 例如 NR==1 就是第一行 |
| FILENAME | 文件名 |
演示示例
如果不懂第几列 行的概念,我这里就举例一下。
比如我有一个文件叫 xx ,内容如下
AAA BBB CCC DDD EEE
111 222 333 444 555
!!! === --- *** +++
1 22 333 444 555

是不是很容易理解,awk 是 按空格 来分割的,按行处理的。
再来一个 示例 free -m 列出内容如下图,记得是按 空格 分割的。下面同颜色框起来的为同一列

下面就开始列举一些示例
- 获取
xx文件中全部内容,$0表示所有内容
awk 'print $0' xx
- 获取
xx文件中第一列内容,$1表示第一列 (第列 就 $n)
awk 'print $1' xx
- 获取
xx文件中 最后一列内容,$NF表示最后一列
awk 'print $NF' xx
- 获取
xx文件中 第一列和第二列内容 并且空格隔开。
awk 'print $1,$2' xx
- 获取
xx文件中第一行所有内容,NR==1表示第一行,$0表示 所有内容。(第n行 就 NR==n)
awk 'NR==1 print $0' xx
- 获取
xx文件中第一行,第二行所有内容。
awk 'NR==1,NR==2 print $0' xx
或
awk 'NR==1 || NR==2 print $0' xx
- 获取
xx文件中 第一行到第三行的所有内容
awk '(NR>=1)&&(NR<=3)print' xx
- 获取
xx文件中 奇数 行 所有内容
awk '(NR%2)==1 print $0' xx
- 获取
xx文件中 偶数 行 所有内容
awk '(NR%2)==0 print $0' xx
- 获取
xx文件中 第一行 第一列 内容
awk 'NR==1 print $1' xx
指定符号分割操作
- 获取
xx文件中 按:符号 进行分割,第一列内容。 指定符号分割 加上-F "符号"即可
awk -F ":" 'print $1' xx
这个还是比较简单,这里就不多演示了。
寻找文件中是否 有需要找的 字符串
- 输出
xx文件中 有AAA字符串的 行内容
awk '/AAA/ print $0' xx
- 把
xx文件中 第二行 第一列中的111+1 变成 112. (注意: +1操作不会影响文件中本身的值,还是保持 111)
方式1 直接 +1
awk 'NR==2 print $1+1' xx
方式2 可以通过-v 引入变量 实现运算
awk -v i=1 'NR==2 print $1+i' xx
- 获取
xx文件中所有内容,并且在每一行后面加上" XXX"(这里只是输出,并不是会在原文件添加" XXX")
awk 'print $0 " XXX"' xx
- 如果想在 输出信息前和输出信息后增加打印信息 可以看下方示例
获取xx文件中 第一行 内容,并且在输出第一行内容前 输出"hello"在输出第一行内容后 输出"world"。
BEGIN:在所有数据读取行之前执行END:在所有数据执行后执行
awk 'BEGINprint "hello" NR==1print $0 ENDprint "world"' xx
输出结果如下:
hello
AAA BBB CCC DDD EEE
world
- 输出
xx文件中当前文件名 并且输出第一行的内容,并且空格隔开。
awk 'NR==1 print FILENAME,$1' xx
- 小示例: 用awk 获取 IP 地址
ifconfig | awk '/netmask/ print $2'
结果如下:
192.168.1.101
127.0.0.1
3. sed
基本语法
sed 用法
sed [项目] [sed内置命令字符] [输入文件]
选项参数
下面表的内容只是一部分。
| 选项参数 | 描述 |
|---|---|
| -n | 取消默认sed的输出 常与sed内置命令p一起用 |
| -i | 直接将修改结果写入文件 不用-i sed修改的是内存数据 |
| -e | 多次编辑 不需要管道符了 |
| -r | 支持正则扩展 |
下面是 sed 的 内置命令
| 内置命令 | 描述 |
|---|---|
| a | append 对文本追加 在指定后面添加一行/多行文本 |
| d | Delete 删除匹配行 |
| i | insert 表示插入文本,在指定行前添加一行/多行文本 |
| p | print 打印匹配行的内容 通过p与-n 一起用 |
| c | 替换指定的整行内容 |
演示示例
下面写一些操作示例。
获取文件内容
- 获取
xx文件中 第一行内容 (请加上-n不然是所有内容都输出的. 想输出第n行就改成'np')
sed -n '1p' xx
- 获取
xx文件中 所有内容
sed -n 'p' xx
- 获取
xx文件中 第一行到第三行 内容
sed -n '1,3p' xx
- 获取
xx文件中 最后一行 内容
sed -n '$p' xx
给文件添加内容
如果想要将修改结果写入文件 请一定要在sed 后面 加上 -i
如果想要将修改结果写入文件 请一定要在sed 后面 加上 -i
如果想要将修改结果写入文件 请一定要在sed 后面 加上 -i
不加 -i 是不会真正修改的,只是输出给你看而已。(调试建议还是先不加,免得乱改文件内容)
我下面是没有加 -i 的,所以下面的命令不会对文件进行修改。
在指定行上面添加内容
- 在
xx文件 第一行的上面插入 “hello world” (ni+要插入的内容,其中n代表行号)
sed '1ihello world' xx
- 在
xx文件 最后的行上面插入 “hello world” 到文件末尾 ($i+要插入内容)
sed '$ihello world' xx
- 在
xx文件 每一行的上面插入 “hello world” (i+要插入的内容)
sed 'ihello world' xx
在指定行下面添加内容
- 给
xx文件 第一行的下面插入 “hello world” (na+要插入的内容,其中n代表行号)
sed '1ahello world' xx
- 在
xx文件 最后的行下面插入 “hello world” 到文件末尾 ($a+要插入内容)
sed '$ahello world' xx
- 在
xx文件 每一行的下面插入 “hello world” (a+要插入的内容)
sed 'ahello world' xx
指定字符行添加内容
- 在
xx文件 凡是以 “AAA” 开头的,在该行的上面插入 “hello world”
sed '/^AAA/ihello world' xx
- 在
xx文件 凡是以 “AAA” 开头的,在该行的下面插入 “hello world”
sed '/^AAA/ahello world' xx
替换指定的整行内容
- 在
xx文件中 把第一行内容 换成 “hello world” (第1行就1c,第n行 则是nc)
sed '1chello world' xx
- 在
xx文件中 把所有行内容 换成 “hello world”
sed 'chello world' xx
- 在
xx文件中 把 “AAA” 开头的行 都换成 “hello world”
sed '/^AAA/chello world' xx
替换指定的字符
语法格式:
sed "s/需要替换的内容/新的内容/g" 文件名
s :替换指定字符
g :全局的意思
- 把
xx文件中 AAA 改成 666. 不加g则替换一个, 加上g则是全局替换
sed 's/AAA/666/g' xx
删除指定的整行内容
- 在
xx文件中 删除第一行内容 (想删除第一行就1d第n行就nd)
sed '1d' xx
- 在
xx文件中 删除最后一行内容
sed '$d' xx
- 在
xx文件中 删除第一行到第三行内容
sed '1,3d' xx
4. cut
基本语法
文本处理工具
cut的工作就是"剪" 具体的说就是在文件中负责剪切数据用的,cut命令从文件的每一行剪切字节,字符和字段并将这些字节,字符和字段输出。
cut [选项参数] filename
说明 默认分割符是制表符
选项参数
| 选项参数 | 描述 |
|---|---|
| -f | 列号 提取第几列 |
| -d | 分割符 按照指定分割符分割列 默认是制表符 “\\t” |
| -c | 按字符进行切割 后加加n 表示取第几列 比如 -c 1 |
演示示例
还是用这个 xx 文件内容来举例把
xx 文件内容如下
AAA BBB CCC DDD EEE
111 222 333 444 555
!!! === --- *** +++
1 22 333 444 555
- 获取
xx文件中 以一个空格 进行裁剪 输出第一列内容 (-d指定分割符号-f指定获取第几列)
cut -d " " -f 1 xx
输出内容如下:
AAA
111
!!!
结果看出来了吧,cut 和 awk 是不一样的。
- 获取
xx文件中 第一列到第三列 内容 以一个空格进行裁剪
cut -d " " -以上是关于shell 学习笔记的主要内容,如果未能解决你的问题,请参考以下文章