音频识别(Audio Classification)学习笔记
Posted 收尾人VEM
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音频识别(Audio Classification)学习笔记相关的知识,希望对你有一定的参考价值。
音频分类(audio classification)
一.音频的定义以及音频三要素
音频(audio)在不同场合有不同的定义。一般来说,音频就是人耳可以听到的频率在20Hz-20kHz之间的声波。当然,也可以指像.wav这样的存储音频信息的文件。
既然是声波,通过中学物理知识我们知道:声波其实就是声带或者其他物体通过振动产生的能量的传递,也是一种运动状态的传递。
声波归根结底还是波,那就有三个基本要素来定义波:
1.振幅:决定声波的振动大小,也就是响度。
2.频率:决定声波的振动频率,一般比较刺耳的声音,频率就比较大,也就是音调比较高。
3.波形:决定声波的形状,可以决定声音的音色如何。
二.音频数据的存储方式
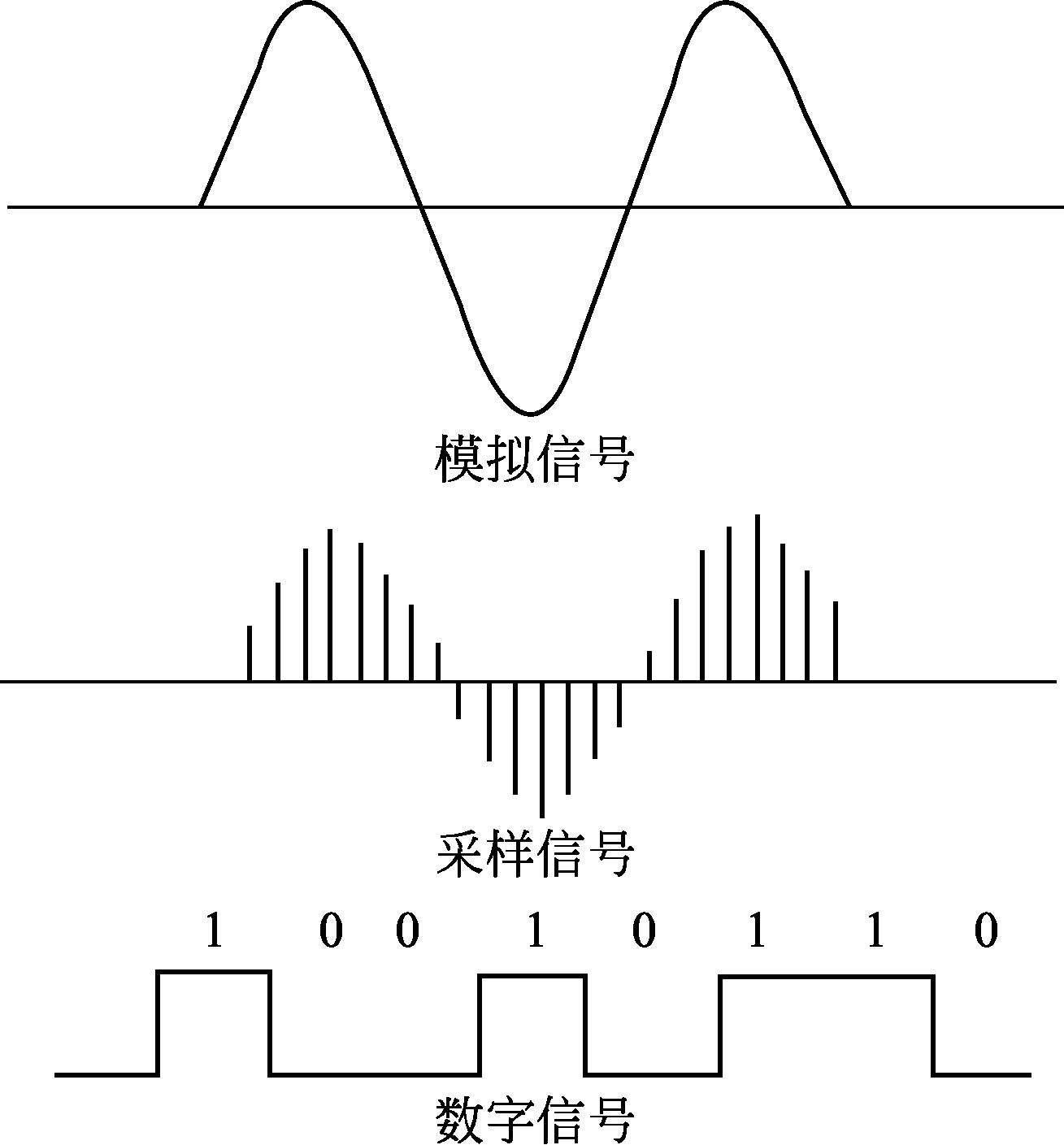
我们已经知道了音频就是一种波,那么我们得使用什么方法去记录和存储呢?一般来说,我们可以使用脉冲编码调制(PCM,pulse code modulation)。
所谓的PCM,是对连续变化的模拟信号进行抽样、量化和编码产生的数字信号。其主要过程包括:
1.抽样:将连续时间模拟信号变为离散时间、连续幅度的抽样信号。因为我们都知道,声波是连续的,但是我们要训练的数据是离散的。
根据奈奎斯特采样定理:采样频率不小于模拟信号频谱中最高频率的的2倍。
2.量化:将抽样信号变为离散时间、离散幅度的数字信号。
3.编码:对每一组数据的幅度进行编码。(这个就类似于哈夫曼编码了)就比如说给你515组数据,一共有32组不同的幅度,那么你就可以用5位的二进制数来表示,也就是5bytes。
三.关于音频的一些专业名词
1.采样率
刚刚已经提到了,就是每单位时间需要采集的样本点个数。
2.采样位数
模拟信号的数据是连续的,而在数字信号中,信号是不连续的,也就是说量化之后的振幅值需要取得一个近似整数,采样器就会固定使用一个位数来进行采样。
3.比特率
表示编码过后的音频数据每秒需要用多少个比特来表示,通常单位为kbps。
4.音频编码
刚刚也已经提到了,就是仅仅由0和1构成的编码表示不同的振幅。
5.声道数
记录声音的时候,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道。
6.码率
指的是数据流中,每一秒能够通过的信息量,单位为(bps,bit per second)
7.音频帧
视频的每一帧就是图像,对于PCM流来说,采样率为ER,采样位数EN,通道数为c,那么每一秒的音频大小为:
E R × E N × c 8 ( 单 位 : 字 节 ) \\fracER\\times EN\\times c8(单位:字节) 8ER×EN×c(单位:字节)
8.音频格式
常见的音频格式有:.wav、.MP3、.MIDI、.AAC。
在计算机处理音频文件的时候,也是要对数据进行**数字信号-模拟信号(数-模,A/D)**转换的,这个过程同样是由采样和量化构成的。
不同的采样和量化方法有不同的效果,所以音频格式就是存放音频数据的文件格式。
四.python处理音频文件
1.wave包处理音频并绘制模拟信号图
import wave
import matplotlib.pyplot as plt
import os
import random
import pandas as pd
import numpy as np
# tips:我们使用的是read-bytes模式,如果想要更改wav文件则需要以write模式读入
# write模式和read两种模式的方法和能使用的函数不同
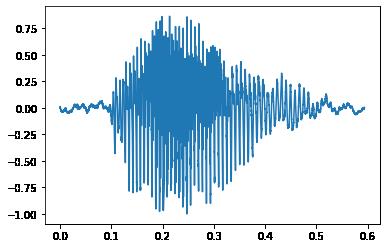
f=wave.open('./1_02_3.wav','rb')
params=f.getparams()
nchannels,sampwidth,framerate,nframes=params[:4]
print(params)
_wave_params(nchannels=1, sampwidth=2, framerate=48000, nframes=28490, comptype='NONE', compname='not compressed')
str_bytes_data=f.readframes(nframes=nframes) # 输入采样后得到的帧数返回一个音频数据的二进制数据字符串
wavedata=np.frombuffer(str_bytes_data,dtype=np.int16)
wavedata=wavedata*1.0/(max(abs(wavedata))) # 归一化处理
time=np.arange(0,nframes)*(1.0/framerate)
plt.plot(time,wavedata)
[<matplotlib.lines.Line2D at 0x1cbc6dba370>]
为了后面数据载入方便,我们还是写一个函数方便读取音谱图:
def get_wave_plot(wave_path,plot_save_path=None,plot_save=False):
f=wave.open(wave_path,'rb')
params=f.getparams()
nchannels,sampwidth,framerate,nframes=params[:4]
str_bytes_data=f.readframes(nframes=nframes)
wavedata=np.frombuffer(str_bytes_data,dtype=np.int16)
wavedata=wavedata*1.0/(max(abs(wavedata)))
time=np.arange(0,nframes)*(1.0/framerate)
plt.plot(time,wavedata)
if plot_save:
plt.savefig(plot_save_path,bbox_inches='tight')
2.音频数据的准备
关于音频的变换其实就是说——目标检测一样,一般我们用txt存储每一条数据信息,但是输入的并不是这个txt,而是txt指向的数据本身并且还要进行一定处理。
本文所使用的是一个记录了60个人的0-9数字的英文发音,但是我只取了其中一部分。
import torch
import torchaudio
from tqdm import tqdm
from torchaudio import transforms
from IPython.display import Audio
from torch.optim import Adam
from torch.autograd import Variable
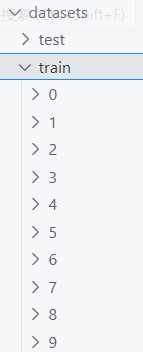
data_path='./datasets'
test_wave_path='./1_02_3.wav'
另外,刚刚我们使用librosa读入了wav文件,其实深度学习框架pytorch中有对应的处理包——torchaudio(图像就是torchvision),接下来我们来学习一下如何使用这个包来创造一个“音频读取器”。
跟我们的librosa一样,读取audio的过程就是“采样——量化——编码”,唯一比较不同的地方就是pytorch一般我们习惯用面向对象的编程方式。
(1)wave文件的读入(torchaudio.load)
我们先来看看这个load到底载入入了啥?
# help(torchaudio.load)
Args:
filepath: Path to audio file
out: An optional output tensor to use instead of creating one. (Default: ``None``)
normalization: Optional normalization.
If boolean `True`, then output is divided by `1 << 31`.
Assuming the input is signed 32-bit audio, this normalizes to `[-1, 1]`.
If `float`, then output is divided by that number.
If `Callable`, then the output is passed as a paramete to the given function,
then the output is divided by the result. (Default: ``True``)
channels_first: Set channels first or length first in result. (Default: ``True``)
num_frames: Number of frames to load. 0 to load everything after the offset.
(Default: ``0``)
offset: Number of frames from the start of the file to begin data loading.
(Default: ``0``)
signalinfo: A sox_signalinfo_t type, which could be helpful if the
audio type cannot be automatically determined. (Default: ``None``)
encodinginfo: A sox_encodinginfo_t type, which could be set if the
audio type cannot be automatically determined. (Default: ``None``)
filetype: A filetype or extension to be set if sox cannot determine it
automatically. (Default: ``None``)
Returns:
(Tensor, int): An output tensor of size `[C x L]` or `[L x C]` where
L is the number of audio frames and
C is the number of channels.
An integer which is the sample rate of the audio (as listed in the metadata of the file)
简单解释一下就是说:
常用的输入参数有如下几个:
1.wav文件路径:字符串,没啥好说的
2.normalization:布尔值,归一化,将我们的数据x、y方向也就是时间和振幅控制在一定范围内。
3.channel_first:布尔值,最后我们输出的是已经数字化的tensor。(可以参考上面的实例)
4.num_frames:整型,指定取多少个“起始点帧数”后面的帧。
5.offset:整型,”起始点帧数“。
输出:
[tensor,sample_rate]
sample_rate就是采样率。
tensor的话,如果是channel_first,那么输出就是[channel_num,frames_num],否则颠倒过来。
sig,sr=torchaudio.load('./1_02_3.wav',channels_first=True)
print(sig)
print(sig.shape)
print(sr)
tensor([[1.2207e-04, 9.1553e-05, 1.2207e-04, ..., 6.1035e-05, 6.1035e-05,
3.0518e-05]])
torch.Size([1, 28490])
48000
看得出来采样率sr是48000——每秒48000帧,那么知道了nframes为28490,相除就可以得到我们的采样时长。
并且通过sig(信号)的size就可以知道他是一个单声道。
为了方便我们后续操作,我们不妨写一个函数:
def audio_open(audio_path):
"""
audio_path -> [tensor:channel*frames,int:sample_rate]
"""
sig,sr=torchaudio.load(audio_path,channels_first=True)
return [sig,sr]
(2)wave文件的声道统一化
我们载入了wave的文件后,得到的是tensor和sr,接下里就是数据的归一化了,首先对tensor的size的channels进行归一化:
def regular_channels(audio,new_channels):
"""
torchaudio-file([tensor,sample_rate])+target_channel -> new_tensor
"""
sig,sr=audio
if sig.shape[0]==new_channels:
return audio
if new_channels==1:
new_sig=sig[:1,:] # 直接取得第一个channel的frame进行操作即可
else:
# 融合(赋值)第一个通道
new_sig=torch.cat([sig,sig],dim=0) # c*f->2c*f
# 顺带提一句——
return [new_sig,sr]
其实这一步就是把单声道和立体声(双通道)统一化。
(3)wave文件的采样率统一化
接下来对采样率进行标准化。
有些细心的同志就会发现上面的librosa进入rb模式后是不能更改sr的,不用单项,torchaudio已经为我们写好了一个类——Resample。
是不是感觉有点像torchvision的Reshaple?
def regular_sample(audio,new_sr):
sig,sr=audio
if sr==new_sr:
return audio
channels=sig.shape[0]
re_sig=torchaudio.transforms.Resample(sr,new_sr)(sig[:1,:])
if channels>1:
re_after=torchaudio.transforms.Resample(sr,new_sr)(sig[1:,:])
re_sig=torch.cat([re_sig,re_after])
# 顺带提一句torch.cat类似np.concatenate,默认dim=0
return [re_sig,new_sr]
(4)调整为相同长度大小
这几部就是将音频样本的大小调整为同一个长度,方法就是使用静默填充或者通过截断的方式来延长采样时间。所谓静默填充,顾名思义就是一段时间后的音频振幅为0。
def regular_time(audio,max_time):
sig,sr=audio
rows,len=sig.shape
max_len=sr//1000*max_time
if len>max_len:
sig=sig[:,:max_len]
elif len<max_len:
pad_begin_len=random.randint(0,max_len-len)
pad_end_len=max_len-len-pad_begin_len
# 这一步就是随机取两个长度分别加在信号开头和信号结束
pad_begin=torch.zeros((rows,pad_begin_len))
pad_end=torch.zeros((rows,pad_end_len))
sig=torch.cat((pad_begin,sig,pad_end),1) # 注意哦我们不是增加通道数,所以要制定维度为1
return [sig,sr]
3.数据的变换与增广
再进行了数据的统一化后,按照图像分类中数据预处理的基本步骤,接下来在数据导入之前应该先进行数据的变换来提升训练的难度。如果数据量不够大,还可以通过数据增广的方式增加数据量。
(1)时移增广
顾名思义,就是用时间偏移将音频向左或向右移动随机量来对原始音频信号进行数据增广。
def time_shift(audio,shift_limit):
sig,sr=audio
sig_len=sig.shape[1]
shift_amount=int(random.random()*shift_limit*sig_len) # 移动量
return (sig.roll(shift_amount),sr)
Tips:
Tensor.roll:Roll the tensor along the given dimension
是torch函数roll的实例,返回一个视图,不会进行原地修改。
简单来说就是将Tensor的元素沿着某个dim(参数)滚动shifts(参数)个单位。
意思就是说,所有元素沿着一个人方向移动n个单位,如果出界,回到第一位。
t1=torch.randint(0,9,(4,2))
print(t1)
# 沿着列的方向移动(横向方向)
t2=t1.roll(3,1)
t3=t1.roll(4,1)
print(t2)
print(t3)
# 沿着纵轴方向
t4=t1.roll(3,0)
print(t4)
tensor([[2, 2],
[3, 2],
[0, 8],
[8, 3]])
tensor([[2, 2],
[2, 3],
[8, 0],
[3, 8]])
tensor([[2, 2],
[3, 2],
[0, 8],
[8, 3]])
tensor([[3, 2],
[0, 8],
[8, 3],
[2, 2]])
(2)梅尔谱图
我们可以将增广后的音频转换为梅尔图谱,获取图谱基本特征,一般都是是音频是数据输入到深度学习模型中常用的、合适的方法。
# get Spectrogram
def get_spectro_gram(audio,n_mels=64,n_fft=1024,hop_len=None):
sig,sr=audio
top_db=80
spec=transforms.MelSpectrogram(sr,n_fft=n_fft,hop_length=hop_len,n_mels=n_mels)(sig)
spec=transforms.AmplitudeToDB(top_db=top_db)(spec)
return spec
(3)数据增广:时间和频率屏蔽
在得到梅尔频谱的基础上可以利用一种SpecAugment的技术:
1.频率屏蔽,在频谱图上添加水平条来随机屏蔽一些列连续频率。
2.时间掩码,利用纵轴方向随机遮挡了一定时间范围。
def spectro_augment(spec,max_mask_pct=0.1,n_freq_masks=1,n_time_masks=1):
_,n_mels,n_steps=spec.shape
mask_value=spec.mean()
aug_spec=spec
freq_mask_param=max_mask_pct*n_mels
for _ in range(n_freq_masks):
aug_spec=transforms.FrequencyMasking(freq_mask_param)(aug_spec,mask_value)
return aug_spec
4.数据的载入
在经过了以上依次处理后,我们得到的的x就是一个梅尔频谱tensor(shape=(channels,mel_freqbands,time_steps))+sample_rate。
现在就对我们的数据进行载入,后面的操作跟识别手写数字数据集没太大差别了。
我们可以先用pandas看看存储数据信息的dataframe。
csv_f=pd.read_csv("./datasets/data_info.csv",encoding='utf-8')
csv_f.head()
| Unnamed: 0 | filename | label | filepath | |
|---|---|---|---|---|
| 0 | 0 | 0_01_0.wav | 0 | ./datasets/data/0_01_0.wav |
| 1 | 1 | 0_01_1.wav | 0 | ./datasets/data/0_01_1.wav |
| 2 | 2 | 0_01_10.wav | 0 | ./datasets/data/0_01_10.wav |
| 3 | 3 | 0_01_11.wav | 0 | ./datasets/data/0_01_11.wav |
| 4 | 4 | 0_01_12.wav | 0 | ./datasets/data/0_01_12.wav |
可以看一下有多少类:
print(set(csv_f['label']))
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
然后编写一个数据集(torch.util.data.DataSet)子类用于加载自己的数据集。
from torch.utils.data import Dataset,DataLoader,random_split
class SoundDataSet(Dataset):
"""
初始化函数:
输入:info_data文件的数据框格式读取信息+数据集路径
并且写入相关属性。
"""
def __init__(self,df,data_path):
self.df=df
self.data_path=data_path
self.duration=4000 # 统一时长
self.sr=44100 # 统一采样率
self.channel=2 # 统一声道
self.shift_pct=0.4
# 一般重写这三个方法就够了
def __len__(self):
return len(os.listdir(self.data_path+'/'+'data'))
def __getitem__(self,index):
class_id=torch.Tensor(self.df['label'].tolist())[index]
audio_file=audio_open(self.df['filepath'][index])
re_sample_file=regular_sample(audio_file,self.sr)
re_channel_file=regular_channels(re_sample_file,self.channel)
re_duration_file=regular_time(re_channel_file,self.duration)
shift_time_file=time_shift(re_duration_file,self.shift_pct)
sgram=get_spectro_gram(shift_time_file,n_mels=64,n_fft=1024,hop_len=None)
aug_sgram=spectro_augment(sgram,max_mask_pct=0.1,n_freq_masks=2,n_time_masks=2)
return aug_sgram.float(),class_id.float()
Tips:
其实之前我一直是按照模板来写这3个方法的,但是后面我学习了一些代码,我是这样猜想的。
len(class_name):按照这个形式调用的话就会去调用这个__len__方法,后面我们实例化DataLoader的时候,DataLoader会自动调用len方法把该准备好的文件都调用完。
__getitem__:这个方法是一个关键,它决定DataLoader在load你的DataSet会返回哪些东西到实例化的变量中去。因此,在这里你就得返回你的x,y。
但是值得特别注意的是:
这个方法会输入一个index参数用于后续DataLoader遍历你的数据集返回item(每一个数据项)。因此,我刚开始误以为是直接返回zip好的x_train,y_train(shape(2,1,sample_size,-1,-1))。其实应该返回单个数据项。(毕竟人家叫做get"item")
init:为啥要把init函数放在最后?因为getitem和len方法不可能只用它们自己的输入参数,更多的,还需要通过self调用实例化属性来得到一些“额外信息”,eg:数据集路径、数据集信息文件等等。
不然getitem从哪里得到数据项呢?
来看看效果如何?
dataframe=pd.read_csv('./datasets/data_info.csv')
data_path='./datasets'
mydatasets=SoundDataSet(dataframe,data_path)
num_items=len(mydatasets)
num_train=round(num_items*0.8)
num_test=num_items-num_train
train_dataset,test_dataset=random_split(mydatasets,[num_train,num_test])
train_dataloader=DataLoader(train_dataset,batch_size=16,shuffle=True)
test_dataloader=DataLoader(test_dataset,batch_size=16,shuffle=True)
5.模型建立
通过上面的数据处理,输入网络的tenor应该为:
(batch_size,channels,mel_freq_bands,time_steps),在经过conv层后,进入分类器得到10个类别的预测值。
from torch.nn import *
class AudioClassificationModel(Module):
def __init__(self):
super().__init__()
conv_layers=[]
self.conv1=Conv2d(2,8,kernel_size=(5,5),stride=(2,2),padding=(2,2))
self.relu1=ReLU()
self.bn1=BatchNorm2d(8)
conv_layers+=[self.conv1,self.relu1,self.bn1]
self.conv2=Conv2d(8,16,kernel_size=(3,3),stride=(2,2),padding=(1,1))
self.relu2=ReLU()
self.bn2=BatchNorm2d(16)
conv_layers+=[self.conv2,self.relu2,self.bn2]
self.conv3=Conv2d(16,32,kernel_size=(3,3),stride=(2,2),padding=(1,1))
self.relu3=ReLU()
self.bn3=BatchNorm2d(32)
conv_layers+=[self.conv3,self.relu3,self.bn3]
self.conv4=Conv2d(32,64,kernel_size=(3,3),stride=(2,2),padding=(1,1))
self.relu4=ReLU()
self.bn4=BatchNorm2d(64)
conv_layers+=[self.conv4,self.relu4,self.bn4]
self.ap=AdaptiveAvgPool2d(output_size=语音识别
可视化音频信号 - 从文件读取并进行处理
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
frequency_sampling, audio_signal = wavfile.read("C:\\Users\\Administrator\\Desktop\\test.wav")
#标准化
audio_signal = audio_signal / np.power(2, 15)
audio_signal = audio_signal[21000:22000]
time_axis = 1000 * np.arange(0, len(audio_signal), 1) / float(frequency_sampling)
plt.plot(time_axis, audio_signal, color=‘blue‘)
plt.xlabel(‘Time (milliseconds)‘)
plt.ylabel(‘Amplitude‘)
plt.title(‘Input audio signal‘)
plt.show()
表征音频信号:转换到频域
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
#读取音频文件, 返回采样频率和音频信号
frequency_sampling, audio_signal = wavfile.read(‘C:\\Users\\Administrator\\Desktop\\test.wav‘)
audio_signal = audio_signal / np.power(2, 15)#标准化
length_signal = len(audio_signal)#信号长度
half_length = np.ceil((length_signal+1)/2).astype(np.int)#信号半长
#傅里叶转化到频域
signal_frequency = np.fft.fft(audio_signal)
#频域信号归一化并平方
signal_frequency = abs(signal_frequency[0:half_length])/length_signal
signal_frequency **= 2
len_fts = len(signal_frequency)#频率变化信号的长度
#傅里叶信号针对奇偶调整
if length_signal % 2:
signal_frequency[1:len_fts] *= 2
else:
signal_frequency[1:len_fts - 1] *= 2
signal_power = 10*np.log10(signal_frequency)#以分贝(dB)为单位提取功率
x_axis = np.arange(0, len_fts, 1) * (frequency_sampling/length_signal)/1000#X轴以kHz为单位
#特征可视化
plt.plot(x_axis, signal_power, color=‘blue‘)
plt.xlabel(‘Frequency (kHz)‘)
plt.ylabel(‘Signal power (dB)‘)
plt.title(‘Characterize audio signals: convert to frequency domain‘)
plt.show()
以上是关于音频识别(Audio Classification)学习笔记的主要内容,如果未能解决你的问题,请参考以下文章