飞桨PaddleSpeech语音技术课程— 语音唤醒
Posted 小湉湉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了飞桨PaddleSpeech语音技术课程— 语音唤醒相关的知识,希望对你有一定的参考价值。
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
1. KWS 概述
随着人工智能的飞速发展,市场上推出了各式各样的智能设备,AI 语音的发展更是使得语音助手成为各大智能终端设备必不可少的软件。语音是人类与设备最直接的交互方式,不需要和实物接触,可远程操控,对于人们来说是最方便自然的交流方式。
自动语音识别(Automatic Speech Recognition, ASR)是一种将语音转化为文字的技术,是人与机器、人与人自然交流的关键技术之一。ASR 是人与智能设备交互的入口,它的功能就是让设备”听懂“人类的语言,从而能够根据识别到的内容去完成人类想要让它做的事情。
语音唤醒(Keyword Spotting, KWS)是语音识别的入口,如何高效、准确地对用户指令给出反应成为这一技术的最重要的目标。
下图是 IPhone 中 Siri 语音助手的交互示意图,总体上可分为以下三个步骤:
- 麦克风持续检测声音信号
- 逐帧对声音信号进行特征提取和模型预测
- 当接收到一个完整的 “Hey Siri” 的语音时,此刻模型的得分达到最大值,触发唤醒事件
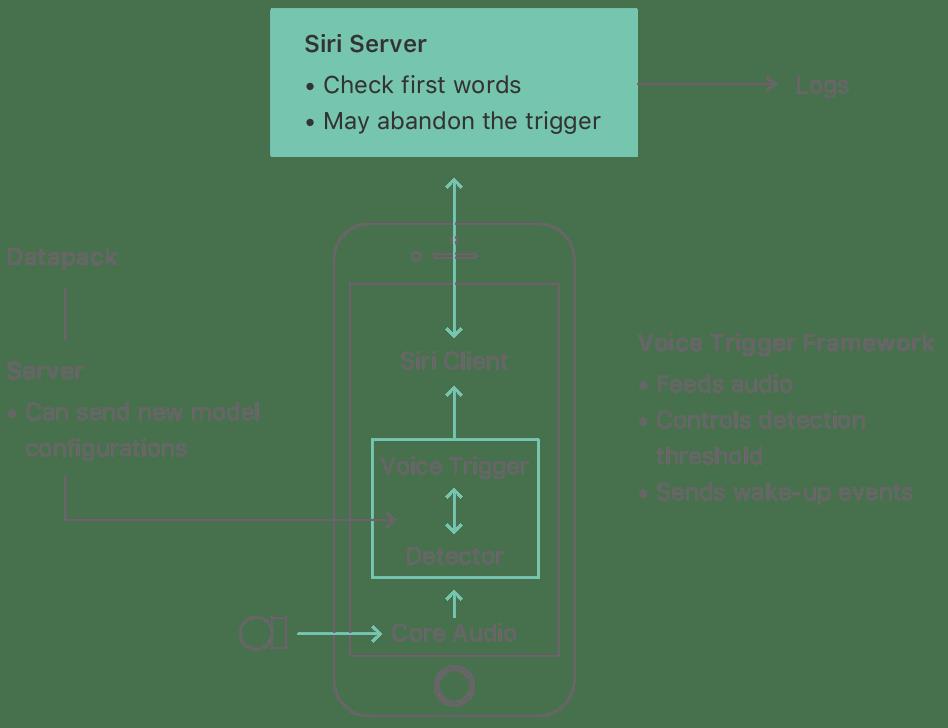
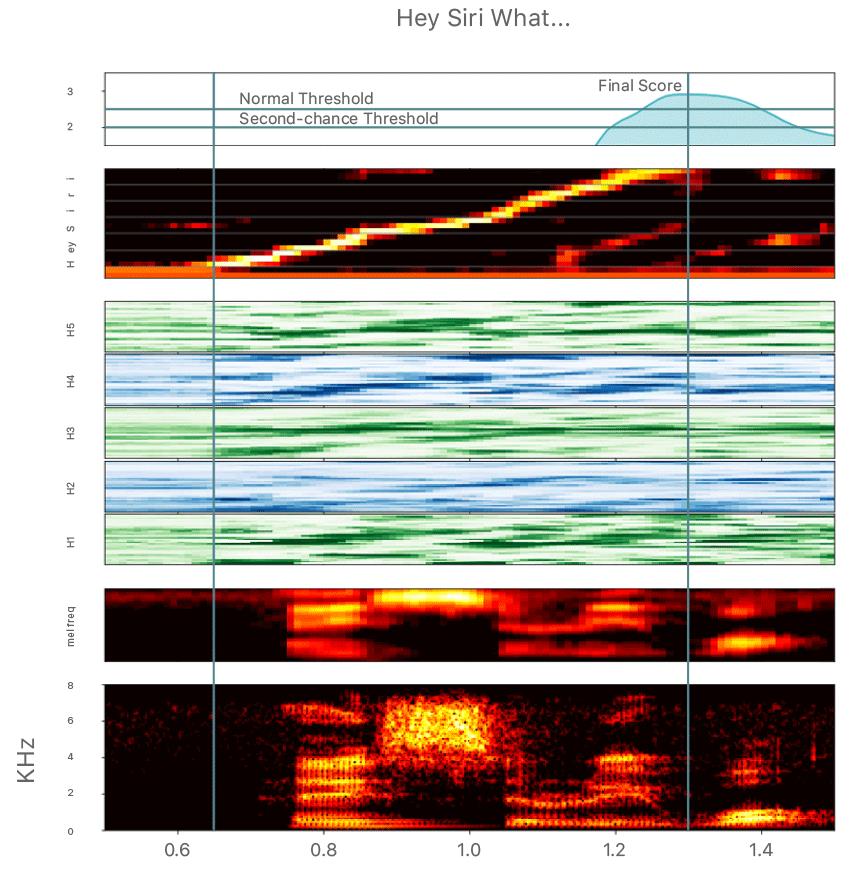
1.1 产品应用
Apple 广告中 Siri 语音助手的交互演示视频。
点击播放
1.2 KWS、ASR 和声音检测
KWS、ASR 和声音检测的关系:
- KWS VS ASR:KWS 可以看作是一类特殊的 ASR,他只识别声音中的固定的关键词。ASR 需要语言模型来理解一段声音中的文字,而 KWS 仅需关注固定样式的发音。从模型输入输出的角度看,KWS 输入音频,输出是判别结果;ASR 输入音频,输出是文字序列。
- KWS VS 声音检测:KWS 和声音检测都是捕获特定的声音,KWS 注重语音中的关键词,而声音检测的范围更为宽泛,可以是自然界中的语音,工业领域里机器产生的声音,人类的哭声,尖叫声等异常声音。从模型输入输出的角度看,KWS 和声音检测都是输入音频,输出判别结果。
2. 适用于 KWS 的模型
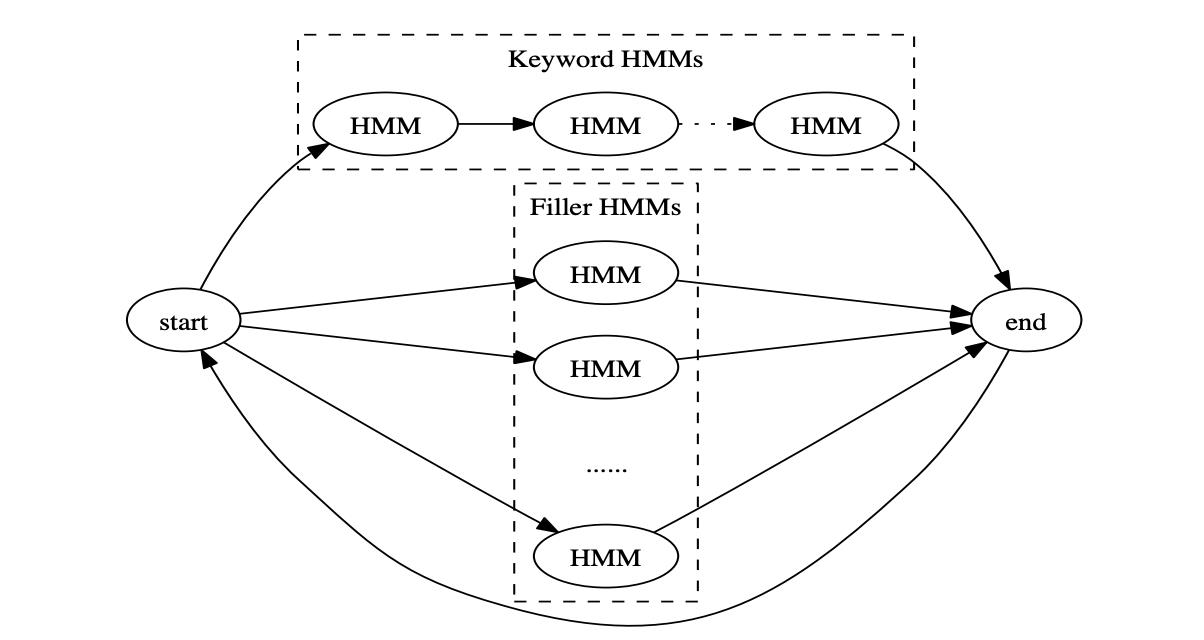
2.1 传统 HMM 模型
与语音识别 ASR 类似,KWS 可以用传统的 HMM 模型完成建模和识别,模型结构上是也是声学模型加解码器。
基于 HMM 的 KWS 模型和传统 ASR 模型的区别:
- 声学模型:KWS 只需关注少量的音素,对于其他发音可以当作 Filler 处理,因此声学模型的类别数可以做到很低,譬如在单音素建模下只需要 10 个以内;而 ASR 面向所有的发音,音素全,因此声学模型类别数会大很多。
- 解码器:ASR 的解码器是一个 FST,输入声学模型的结果输出文字序列;而 KWS 的解码器是一个 FSA,如果到达最终状态可以给出一个得分作为唤醒词的分数,解码图的大小相对于 ASR 会小很多。

2.2 端到端模型
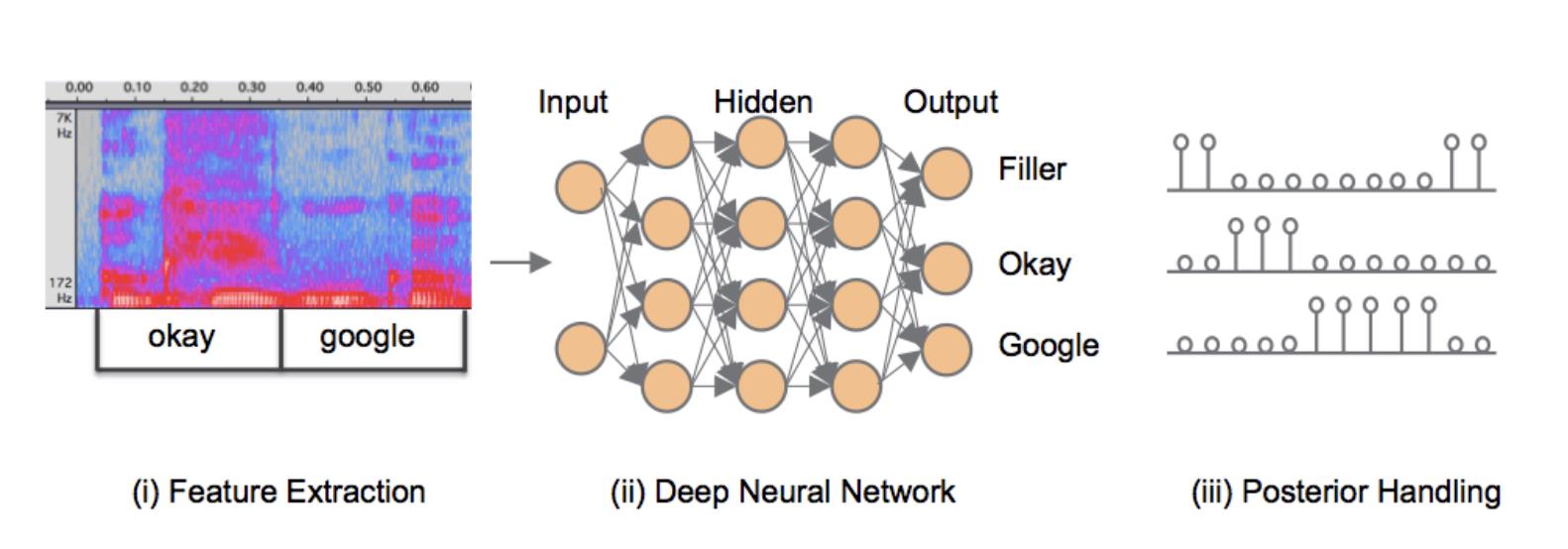
2.2.1 基于后验概率平滑的模型
在 2014 年的文章 Small-footprint keyword spotting using deep neural networks 中,作者提出了一种基于神经网络加后验概率平滑的 KWS 方法,该方法利用词粒度来建模声学模型,可分为以下四个执行步骤:
- 特征提取和重叠:对音频信号进行逐帧的特征提取,预测每一帧的声学概率分布时,加入了上下文信息(前30帧+后10帧)后作为模型输入。
- 声学模型:对叠加了上下文信息的频域特征进行声学概率分布的预测,模型总共有 N 个标签,其中标签 0 为 Filler,将与唤醒词的发音无关的归类至此。
- 后验概率平滑:从声学模型得到整段音频的声学概率分布后,采用滑窗的进行后验概率平滑的计算,这么做可以去除一些噪音,增强鲁棒性。
- 唤醒词得分计算:引入一个得分窗口,在窗口内统计除 Filler 外的所有声学概率的最大值,通过累乘和开方的计算方式得到最终得分。


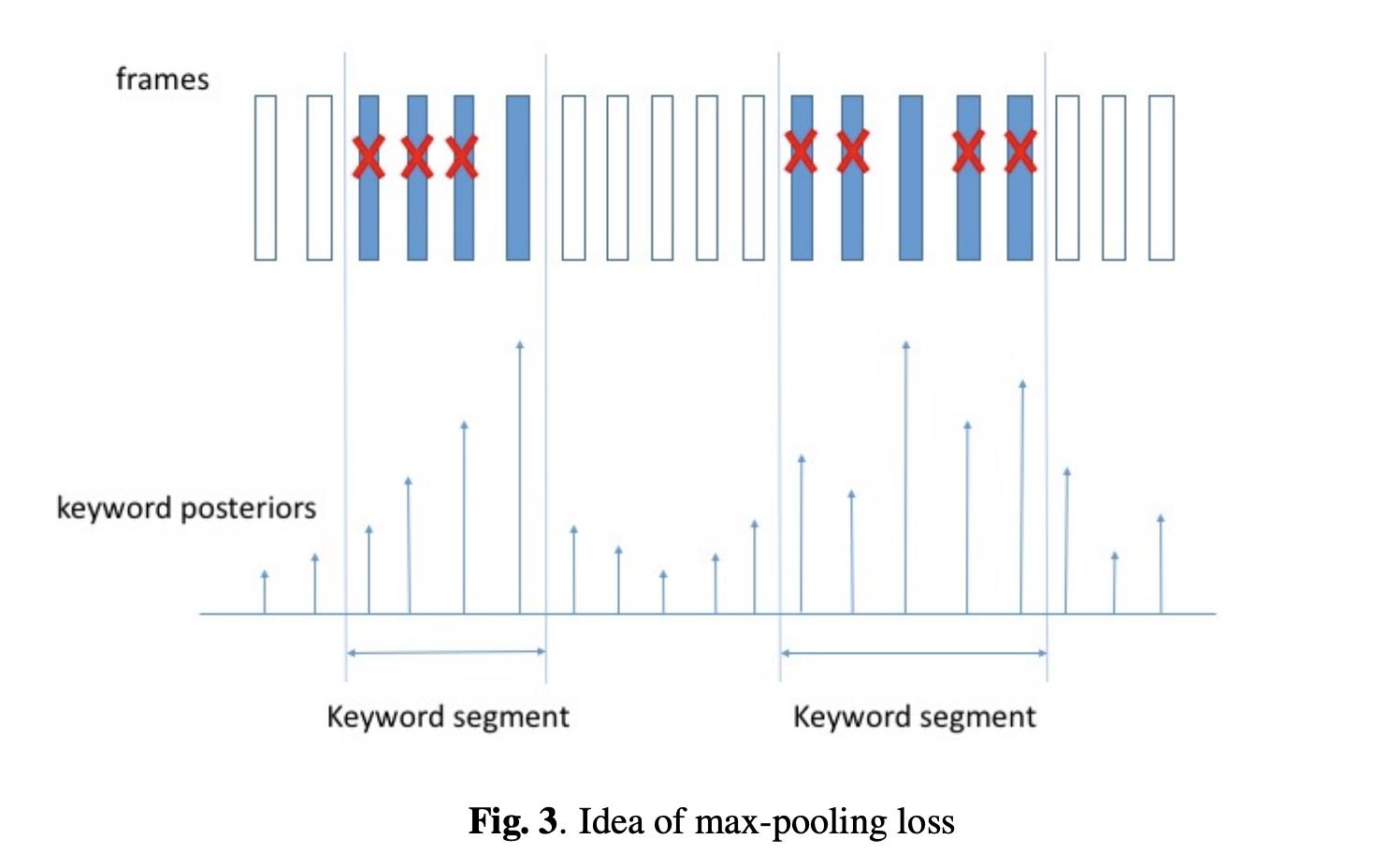
2.2.2 基于 Max-Pooling Loss 的模型
在 2017 年的文章 Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting 中,作者提出了一种基于 Max-Pooling Loss 的 KWS 模型训练方法。
这种方法可以看作是从帧级别的训练方式转向段级别的训练方式,如下图所示,蓝色填充的帧是唤醒词,在训练阶段,模型对于唤醒词片段的得分取决于某一帧中的最高的得分;而非唤醒词片段,为了保证所有帧的得分都足够低,则需要关注所有的帧。这种得分可以看作是基于声学得分的 Max-Pooling。
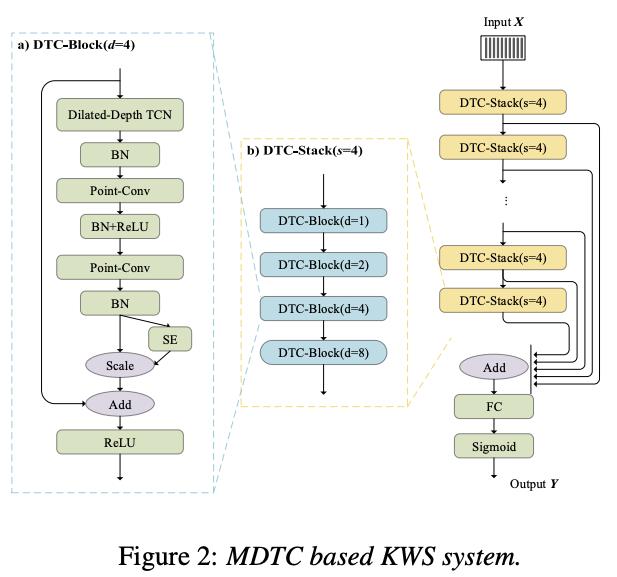
有了这个训练方式,我们直接地对唤醒词进行端到端的建模,具体模型可以采取 RNN-based、CNN-based 和 Attention-based 可对音频特征序列建模的模型。PaddleSpeech 中的 examples/hey_snips 采用了
Multi-scale Dilated Temporal Convolutional 模型,通过 Max-Pooling Loss 的训练方法实现了在 Snips 数据集上的训练和评估。
3. 实践:KWS模型训练和评估
PaddleSpeech 提供了 MDTC 模型在 Snips 数据集上的从训练到评估的全流程脚本,在此章节中将对一些重要步骤做讲解,如需完整执行训练和评估,可以根据 example 中的文档提示运行脚本,详情请参考:examples/hey_snips/kws0
3.1 环境准备
下载 PaddleSpeech 代码并安装所需依赖:
本教程要求paddlepaddle >= 2.2.2的环境,并需要 Clone PaddleSpeech Repo的代码(因网络访问问题可能需要等待较长时间,此处直接提供 PaddleSpeech r1.0 分支的代码压缩包):
!unzip work/PaddleSpeech-r1.0.zip
额外依赖:
!pip install scipy resampy soundfile tqdm colorlog pathos dtaidistance sklearn yacs loguru matplotlib
进入 example 目录:
%cd PaddleSpeech-r1.0/examples/hey_snips/kws0/
3.1 数据集准备
Snips 数据集需要用户自行申请下载:keyword-spotting-research-datasets
该数据集包含不同英语口音的约 11,000 “Hey Sinips” 的关键词的音频和 86,500(约96小时) 的其他发音的负样本。正负样本的音频均在相同的说话人、录音设备和环境噪音等条件下录制的,防止模型在训练的过程中关注非关键词相关的特征。数据集的切分和具体数量由下表所示:
| Train | Dev | Test | ||
|---|---|---|---|---|
| Positive | Utterances | 5,876 | 2,504 | 25,88 |
| Speakers | 1,179 | 516 | 520 | |
| max / speaker | 10 | 10 | 10 | |
| Negative | Utterances | 45,344 | 20,321 | 20,821 |
| Speakers | 3,330 | 1,474 | 1,469 | |
| max / speaker | 30 | 30 | 30 |
数据集下载完成后,解压至/PATH/TO/DATA/hey_snips_research_6k_en_train_eval_clean_ter目录。
3.2 训练
修改conf/mdtc.yaml中的data_dir为'/PATH/TO/DATA/hey_snips_research_6k_en_train_eval_clean_ter' ,只想数据集目录,配置CUDA_VISIBLE_DEVICES启动 CPU/单卡/多卡训练。
CUDA_VISIBLE_DEVICES=0,1 ./run.sh conf/mdtc.yaml
3.3 指标
针对使用场景和训练样本不均衡问题,通常对 KWS 模型通常关注 False Reject 和 False Alarm 指标。在测试集中,通过对不同的唤醒得分阈值下,对模型的指标进行考察。得到每个阈值的样本判别结果后,可以绘制 DET(Detection Error Tradeoff) 曲线:
在此 example 中,我们考察模型在 False Reject 为每小时1次的前提下,False Alarm 的情况,该数值越小则表示模型越好。在下图的结果中,可以确定唤醒阈值为 0.83,此时的 False Alarm Rate为 0.003559(数据由 example 中训练后的模型得到,重新跑后可能会有细微不同):
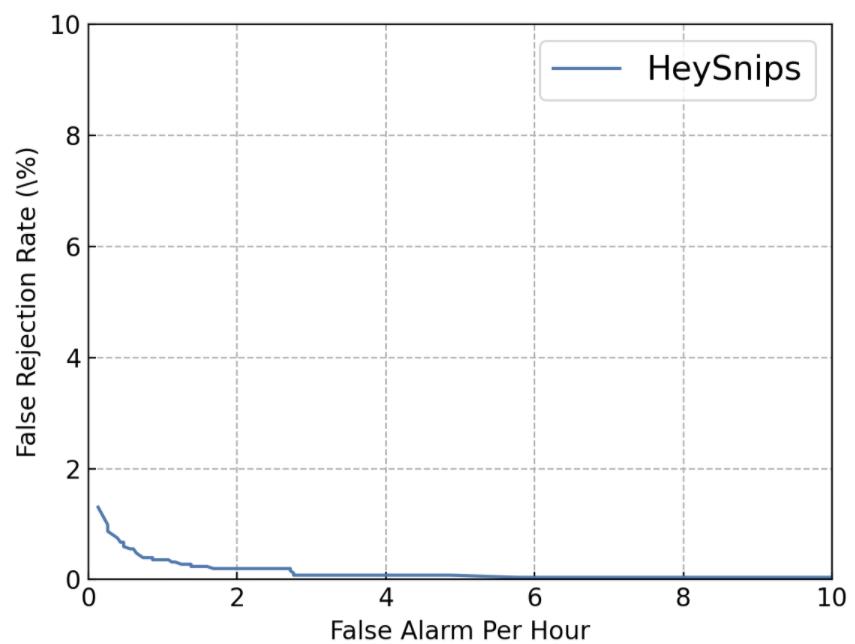
通过上述的训练后得到模型的 checkpoint,并确定了唤醒阈值为 0.83,在此通过正负样本两段音频的输入进行预测,感兴趣的朋友也可以尝试自己提供录音音频进行预测(采样率为 16000 的单通道 wave 文件)。
3.4.1 音频预览
keyword.wav: 正样本,包含唤醒词 Hey Snips 的发音。non-keyword.wav: 负样本。
import IPython
IPython.display.Audio('/home/aistudio/work/keyword.wav')
IPython.display.Audio('/home/aistudio/work/non-keyword.wav')
3.4.2 模型加载
加载从上述训练过程中得到的模型参数文件,完成预测模型的加载。
加入 Python Package 的搜索路径。
import os
import sys
sys.path.insert(0, os.path.abspath('../../..'))
sys.path.insert(0, os.path.abspath('../../../audio'))
加载 MDTC 模型,模型结构的参数与 /examples/hey_snips/kws0/conf/mdtc.yaml 保持一致。
import paddle
from paddlespeech.kws.models import MDTC
from paddlespeech.kws.models.mdtc import KWSModel
# Model
backbone = MDTC(
stack_num=3,
stack_size=4,
in_channels=80,
res_channels=32,
kernel_size=5,
)
model = KWSModel(backbone=backbone, num_keywords=1)
kws_checkpoint = '/home/aistudio/work/kws.pdparams'
model.set_state_dict(paddle.load(kws_checkpoint))
model.eval()
3.4.3 获取预测结果
通过对测试音频进行特征提取和模型前向计算,获取唤醒得分,并通过对比唤醒阈值得到判别结果。
特征提取的参数与 /examples/hey_snips/kws0/conf/mdtc.yaml 保持一致。
音频加载和特征计算:
import paddleaudio
from paddleaudio.compliance.kaldi import fbank
feat_func = lambda waveform, sr: fbank(
waveform=paddle.to_tensor(waveform).unsqueeze(0),
sr=sr,
frame_shift=10,
frame_length=25,
n_mels=80)
keyword_feat = feat_func(
*paddleaudio.load('/home/aistudio/work/keyword.wav'))
non_keyword_feat = feat_func(
*paddleaudio.load('/home/aistudio/work/non-keyword.wav'))
print(keyword_feat.shape, non_keyword_feat.shape)
获取音频的预测得分:
keyword_logits = model(keyword_feat.unsqueeze(0))
keyword_score = paddle.max(keyword_logits).numpy().item()
print(keyword_score)
non_keyword_logits = model(non_keyword_feat.unsqueeze(0))
non_keyword_score = paddle.max(non_keyword_logits).numpy().item()
print(non_keyword_score)
从阈值( 0.83)和音频的预测得分的比较重容易看出,keyword.wav 判别为唤醒,而 non-keyword.wav 为非唤醒。
4. 参考文献
[1] https://machinelearning.apple.com/research/hey-siri
[2] Chen, Guoguo et al. “Small-footprint keyword spotting using deep neural networks.” 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2014): 4087-4091.
[3] Wang, Zhiming et al. “Small-footprint Keyword Spotting Using Deep Neural Network and Connectionist Temporal Classifier.” ArXiv abs/1709.03665 (2017): n. pag.
[4] Coucke, Alice et al. “Efficient Keyword Spotting Using Dilated Convolutions and Gating.” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2019): 6351-6355.
[5] Hou, Jingyong et al. “The NPU System for the 2020 Personalized Voice Trigger Challenge.” ArXiv abs/2102.13552 (2021): n. pag.
[6] Sun, Ming et al. “Max-pooling loss training of long short-term memory networks for small-footprint keyword spotting.” 2016 IEEE Spoken Language Technology Workshop (SLT) (2016): 474-480.
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
5. 关注 PaddleSpeech
请关注我们的 Github Repo,非常欢迎加入以下微信群参与讨论:
- 扫描二维码
- 添加运营小姐姐微信
- 通过后回复【语音】
- 系统自动邀请加入技术群

P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
飞桨PaddleSpeech语音技术课程— 语音合成
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
『听』和『说』
人类通过听觉获取的信息大约占所有感知信息的 20% ~ 30%。声音存储了丰富的语义以及时序信息,由专门负责听觉的器官接收信号,产生一系列连锁刺激后,在人类大脑的皮层听区进行处理分析,获取语义和知识。近年来,随着深度学习算法上的进步以及不断丰厚的硬件资源条件,文本转语音(Text-to-Speech, TTS) 技术在移动、虚拟娱乐等领域得到了广泛的应用。
"听"书
使用 PaddleOCR 直接获取书籍上的文字。
# download demo sources
!mkdir download
!wget -P download https://paddlespeech.bj.bcebos.com/tutorial/tts/ocr_result.jpg
!wget -P download https://paddlespeech.bj.bcebos.com/tutorial/tts/ocr.wav
!wget -P download https://paddlespeech.bj.bcebos.com/tutorial/tts/tts_lips.mp4
import IPython.display as dp
from PIL import Image
img_path = 'download/ocr_result.jpg'
im = Image.open(img_path)
dp.display(im)
使用 PaddleSpeech,阅读上一步识别出来的文字。
dp.Audio("download/ocr.wav")
具体实现代码详见 Story Talker
偶像开口说话
元宇宙来袭,构造你的虚拟人! 看看 PaddleGAN 怎样合成唇形,让WiFi之母——海蒂·拉玛说话。
from IPython.display import HTML
html_str = '''
<video controls width="600" height="360" src="">animation</video>
'''.format("download/tts_lips.mp4")
dp.display(HTML(html_str))
具体实现代码请参考 Metaverse。
下面让我们来系统地学习语音方面的知识,看看怎样使用 PaddleSpeech 实现基本的语音功能,以及怎样结合光学字符识别(Optical Character Recognition,OCR)、自然语言处理(Natural Language Processing,NLP)等技术“听”书、让名人开口说话。
前言
背景知识
为了更好地了解文本转语音任务的要素,我们先简要地回顾一下文本转语音的发展历史。如果你对此已经有所了解,或希望能尽快使用代码实现,请直接跳至实践。
定义
文本转语音,又称语音合成(Speech Sysnthesis),指的是将一段文本按照一定需求转化成对应的音频,这种特性决定了的输出数据比输入输入长得多。文本转语音是一项包含了语义学、声学、数字信号处理以及机器学习的等多项学科的交叉任务。虽然辨识低质量音频文件的内容对人类来说很容易,但这对计算机来说并非易事。
按照不同的应用需求,更广义的语音合成研究包括:语音转换,例如说话人转换、语音到歌唱转换、语音情感转换、口音转换等;歌唱合成,例如歌词到歌唱转换、可视语音合成等。
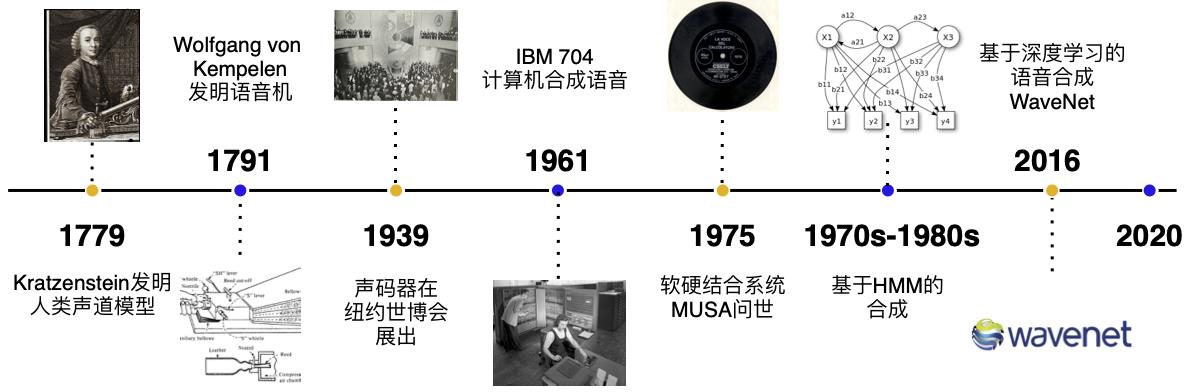
发展历史
在第二次工业革命之前,语音的合成主要以机械式的音素合成为主。1779年,德裔丹麦科学家 Christian Gottlieb Kratzenstein 建造了人类的声道模型,使其可以产生五个长元音。1791年, Wolfgang von Kempelen 添加了唇和舌的模型,使其能够发出辅音和元音。贝尔实验室于20世纪30年代发明了声码器(Vocoder),将语音自动分解为音调和共振,此项技术由 Homer Dudley 改进为键盘式合成器并于 1939年纽约世界博览会展出。
第一台基于计算机的语音合成系统起源于20世纪50年代。1961年,IBM 的 John Larry Kelly,以及 Louis Gerstman 使用 IBM 704 计算机合成语音,成为贝尔实验室最著名的成就之一。1975年,第一代语音合成系统之一 —— MUSA(MUltichannel Speaking Automation)问世,其由一个独立的硬件和配套的软件组成。1978年发行的第二个版本也可以进行无伴奏演唱。90 年代的主流是采用 MIT 和贝尔实验室的系统,并结合自然语言处理模型。
主流方法
当前的主流方法分为基于统计参数的语音合成、波形拼接语音合成、混合方法以及端到端神经网络语音合成。基于参数的语音合成包含隐马尔可夫模型(Hidden Markov Model,HMM)以及深度学习网络(Deep Neural Network,DNN)。端到端的方法保函声学模型+声码器以及“完全”端到端方法。
基于深度学习的语音合成技术
语音合成基本知识
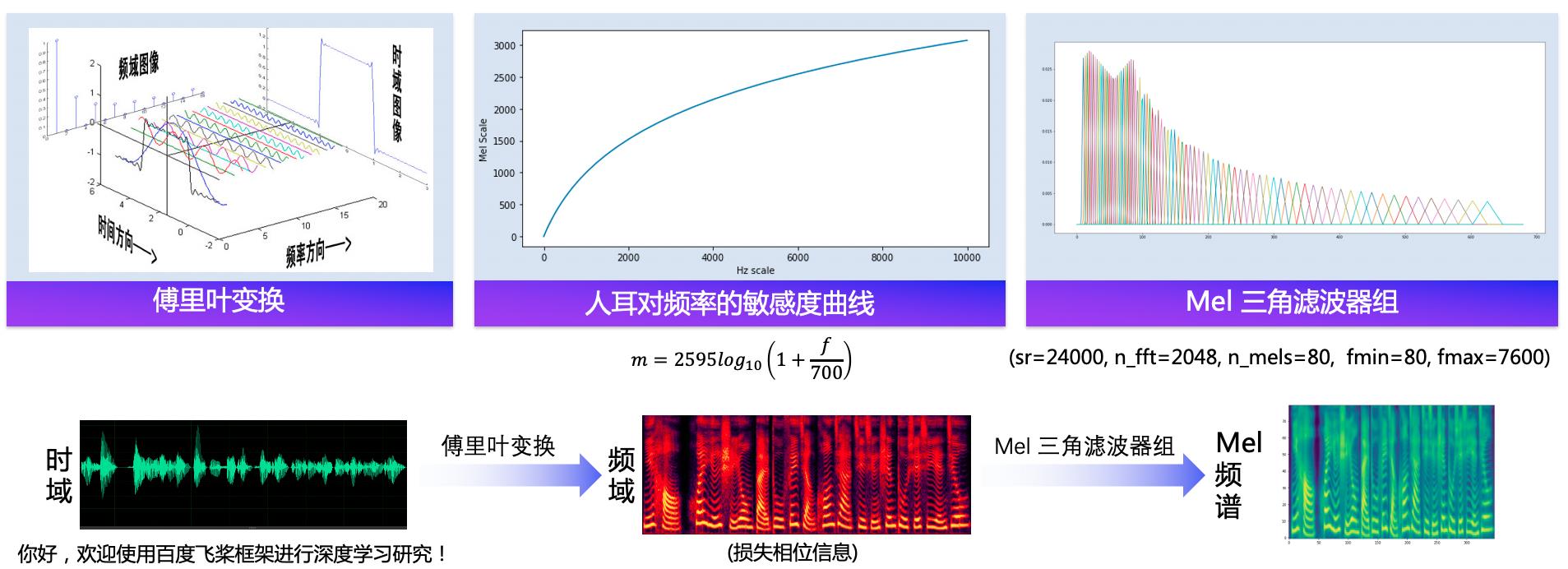
语音合成流水线包含 文本前端(Text Frontend) 、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块:
- 通过文本前端模块将原始文本转换为字符/音素。
- 通过声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等。
- 通过声码器将声学特征转换为波形。
实践
安装 paddlespeech
!pip install paddlespeech
数据及模型准备
获取PaddlePaddle预训练模型
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/pwgan/pwg_baker_ckpt_0.4.zip
!unzip -o -d download download/pwg_baker_ckpt_0.4.zip
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip
!unzip -o -d download download/fastspeech2_nosil_baker_ckpt_0.4.zip
!tree download/pwg_baker_ckpt_0.4
!tree download/fastspeech2_nosil_baker_ckpt_0.4
导入 Python 包
# 本项目的依赖需要用到 nltk 包,但是有时会因为网络原因导致不好下载,此处手动下载一下放到百度服务器的包
!wget https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf nltk_data.tar.gz
# 设置 gpu 环境
%env CUDA_VISIBLE_DEVICES=0
import logging
import sys
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
import argparse
import os
from pathlib import Path
import IPython.display as dp
import matplotlib.pyplot as plt
import numpy as np
import paddle
import soundfile as sf
import yaml
from paddlespeech.t2s.frontend.zh_frontend import Frontend
from paddlespeech.t2s.models.fastspeech2 import FastSpeech2
from paddlespeech.t2s.models.fastspeech2 import FastSpeech2Inference
from paddlespeech.t2s.models.parallel_wavegan import PWGGenerator
from paddlespeech.t2s.models.parallel_wavegan import PWGInference
from paddlespeech.t2s.modules.normalizer import ZScore
from yacs.config import CfgNode
设置预训练模型的路径
fastspeech2_config = "download/fastspeech2_nosil_baker_ckpt_0.4/default.yaml"
fastspeech2_checkpoint = "download/fastspeech2_nosil_baker_ckpt_0.4/snapshot_iter_76000.pdz"
fastspeech2_stat = "download/fastspeech2_nosil_baker_ckpt_0.4/speech_stats.npy"
pwg_config = "download/pwg_baker_ckpt_0.4/pwg_default.yaml"
pwg_checkpoint = "download/pwg_baker_ckpt_0.4/pwg_snapshot_iter_400000.pdz"
pwg_stat = "download/pwg_baker_ckpt_0.4/pwg_stats.npy"
phones_dict = "download/fastspeech2_nosil_baker_ckpt_0.4/phone_id_map.txt"
# 读取 conf 配置文件并结构化
with open(fastspeech2_config) as f:
fastspeech2_config = CfgNode(yaml.safe_load(f))
with open(pwg_config) as f:
pwg_config = CfgNode(yaml.safe_load(f))
print("========Config========")
print(fastspeech2_config)
print("---------------------")
print(pwg_config)
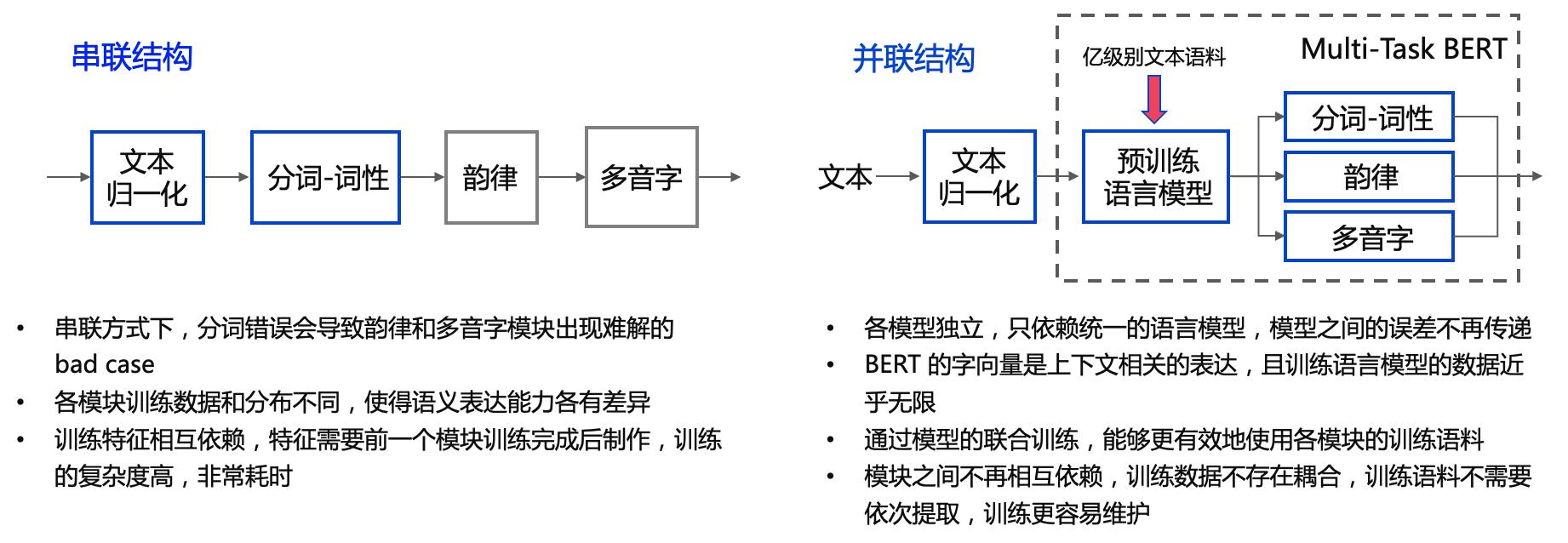
文本前端(Text Frontend)
一个文本前端模块主要包含:
- 分段(Text Segmentation)
- 文本正则化(Text Normalization, TN)
- 分词(Word Segmentation, 主要是在中文中)
- 词性标注(Part-of-Speech, PoS)
- 韵律预测(Prosody)
- 字音转换(Grapheme-to-Phoneme,G2P)
(Grapheme: 语言书写系统的最小有意义单位; Phoneme: 区分单词的最小语音单位)- 多音字(Polyphone)
- 变调(Tone Sandhi)
- “一”、“不”变
- 三声变调
- 轻声变调
- 儿化音
- 方言
- …
(输入给声学模型之前,还需要把音素序列转换为 id)
其中最重要的模块是 文本正则化 模块和 字音转换(TTS 中更常用 G2P 代指) 模块。
各模块输出示例:
• Text: 全国一共有112所211高校
• Text Normalization: 全国一共有一百一十二所二一一高校
• Word Segmentation: 全国/一共/有/一百一十二/所/二一一/高校/
• G2P(注意此句中“一”的读音):
quan2 guo2 yi2 gong4 you3 yi4 bai3 yi1 shi2 er4 suo3 er4 yao1 yao1 gao1 xiao4
(可以进一步把声母和韵母分开)
q uan2 g uo2 y i2 g ong4 y ou3 y i4 b ai3 y i1 sh i2 er4 s uo3 er4 y ao1 y ao1 g ao1 x iao4
(把音调和声韵母分开)
q uan g uo y i g ong y ou y i b ai y i sh i er s uo er y ao y ao g ao x iao
0 2 0 2 0 2 0 4 0 3 ...
• Prosody (prosodic words #1, prosodic phrases #2, intonation phrases #3, sentence #4):
全国#2一共有#2一百#1一十二所#2二一一#1高校#4
(分词的结果一般是固定的,但是不同人习惯不同,可能有不同的韵律)
文本前端模块的设计需要结合很多专业的语义学知识和经验。人类在读文本的时候可以自然而然地读出正确的发音,但是这些先验知识计算机并不知晓。
例如,对于一个句子的分词:
我也想过过过儿过过的生活
我也想/过过/过儿/过过的/生活
货拉拉拉不拉拉布拉多
货拉拉/拉不拉/拉布拉多
南京市长江大桥
南京市长/江大桥
南京市/长江大桥
或者是词的变调和儿化音:
你要不要和我们一起出去玩?
你要不(2声)要和我们一(4声)起出去玩(儿)?
不好,我要一个人出去。
不(4声)好,我要一(2声)个人出去。
(以下每个词的所有字都是三声的,请你读一读,体会一下在读的时候,是否每个字都被读成了三声?)
纸老虎、虎骨酒、展览馆、岂有此理、手表厂有五种好产品
又或是多音字,这类情况通常需要先正确分词:
人要行,干一行行一行,一行行行行行;
人要是不行,干一行不行一行,一行不行行行不行。
佟大为妻子产下一女
海水朝朝朝朝朝朝朝落
浮云长长长长长长长消
PaddleSpeech Text-to-Speech的文本前端解决方案:
构造文本前端对象
传入phones_dict,把相应的phones转换成phone_ids。
# 传入 phones_dict 会把相应的 phones 转换成 phone_ids
frontend = Frontend(phone_vocab_path=phones_dict)
print("Frontend done!")
调用文本前端
文本前端对输入数据进行正则化时会进行分句,若merge_sentences设置为False,则所有分句的 phone_ids 构成一个 List;若设置为True,input_ids["phone_ids"][0]则表示整句的phone_ids。
# input = "我每天中午12:00起床"
# input = "我出生于2005/11/08,那天的最低气温达到-10°C"
input = "你好,欢迎使用百度飞桨框架进行深度学习研究!"
input_ids = frontend.get_input_ids(input, merge_sentences=True, print_info=True)
phone_ids = input_ids["phone_ids"][0]
print("phone_ids:%s"%phone_ids)
用深度学习实现文本前端
声学模型(Acoustic Model)
声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等,声学特征以 “帧” 为单位,一般一帧是 10ms 左右,一个音素一般对应 5~20 帧左右, 声学模型需要解决的是 “不等长序列间的映射问题”,“不等长”是指,同一个人发不同音素的持续时间不同,同一个人在不同时刻说同一句话的语速可能不同,对应各个音素的持续时间不同,不同人说话的特色不同,对应各个音素的持续时间不同。这是一个困难的“一对多”问题。
# 卡尔普陪外孙玩滑梯
000001|baker_corpus|sil 20 k 12 a2 4 er2 10 p 12 u3 12 p 9 ei2 9 uai4 15 s 11 uen1 12 uan2 14 h 10 ua2 11 t 15 i1 16 sil 20
声学模型主要分为自回归模型和非自回归模型,其中自回归模型在 t 时刻的预测需要依赖 t-1 时刻的输出作为输入,预测时间长,但是音质相对较好,非自回归模型不存在预测上的依赖关系,预测时间快,音质相对较差。
主流声学模型发展的脉络:
- 自回归模型:
- Tacotron
- Tacotron2
- Transformer TTS
- 非自回归模型:
- FastSpeech
- SpeedySpeech
- FastPitch
- FastSpeech2
- …
在本教程中,我们使用 FastSpeech2 作为声学模型。
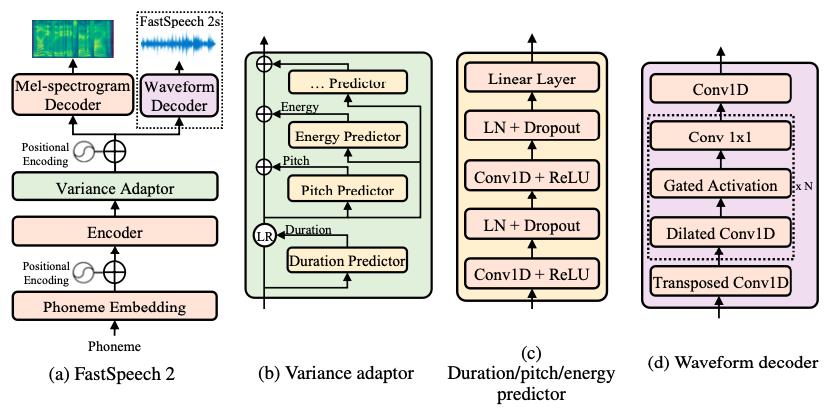
PaddleSpeech TTS 实现的 FastSpeech2 与论文不同的地方在于,我们使用的的是 phone 级别的 pitch 和 energy(与 FastPitch 类似),这样的合成结果可以更加稳定。
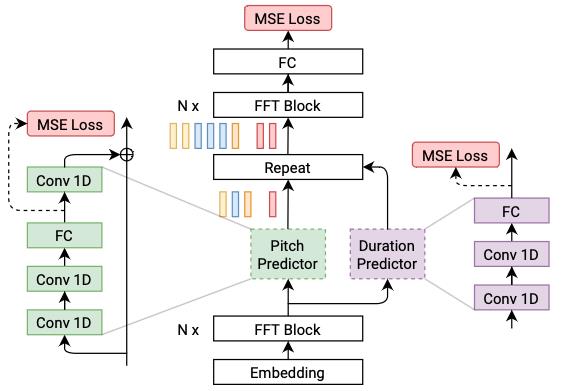
更多关于语音合成模型的发展及改进。
初始化声学模型 FastSpeech2
with open(phones_dict, "r") as f:
phn_id = [line.strip().split() for line in f.readlines()]
vocab_size = len(phn_id)
print("vocab_size:", vocab_size)
odim = fastspeech2_config.n_mels
model = FastSpeech2(
idim=vocab_size, odim=odim, **fastspeech2_config["model"])
# 加载预训练模型参数
model.set_state_dict(paddle.load(fastspeech2_checkpoint)["main_params"])
# 推理阶段不启用 batch norm 和 dropout
model.eval()
stat = np.load(fastspeech2_stat)
# 读取数据预处理阶段数据集的均值和标准差
mu, std = stat
mu, std = paddle.to_tensor(mu), paddle.to_tensor(std)
# 构造归一化的新模型
fastspeech2_normalizer = ZScore(mu, std)
fastspeech2_inference = FastSpeech2Inference(fastspeech2_normalizer, model)
fastspeech2_inference.eval()
print("FastSpeech2 done!")
声码器(Vocoder)
声码器将声学特征转换为波形。声码器需要解决的是 “信息缺失的补全问题”。信息缺失是指,在音频波形转换为频谱图的时候,存在相位信息的缺失,在频谱图转换为 mel 频谱图的时候,存在频域压缩导致的信息缺失;假设音频的采样率是16kHZ, 一帧的音频有 10ms,也就是说,1s 的音频有 16000 个采样点,而 1s 中包含 100 帧,每一帧有 160 个采样点,声码器的作用就是将一个频谱帧变成音频波形的 160 个采样点,所以声码器中一般会包含上采样模块。
与声学模型类似,声码器也分为自回归模型和非自回归模型, 更细致的分类如下:
- Autoregression
- WaveNet
- WaveRNN
- LPCNet
- Flow
- WaveFlow
- WaveGlow
- FloWaveNet
- Parallel WaveNet
- GAN
- WaveGAN
- Parallel WaveGAN
- MelGAN
- Style MelGAN
- Multi Band MelGAN
- HiFi GAN
- VAE
- Wave-VAE
- Diffusion
- WaveGrad
- DiffWave
PaddleSpeech TTS 主要实现了百度的 WaveFlow 和一些主流的 GAN Vocoder, 在本教程中,我们使用 Parallel WaveGAN 作为声码器。
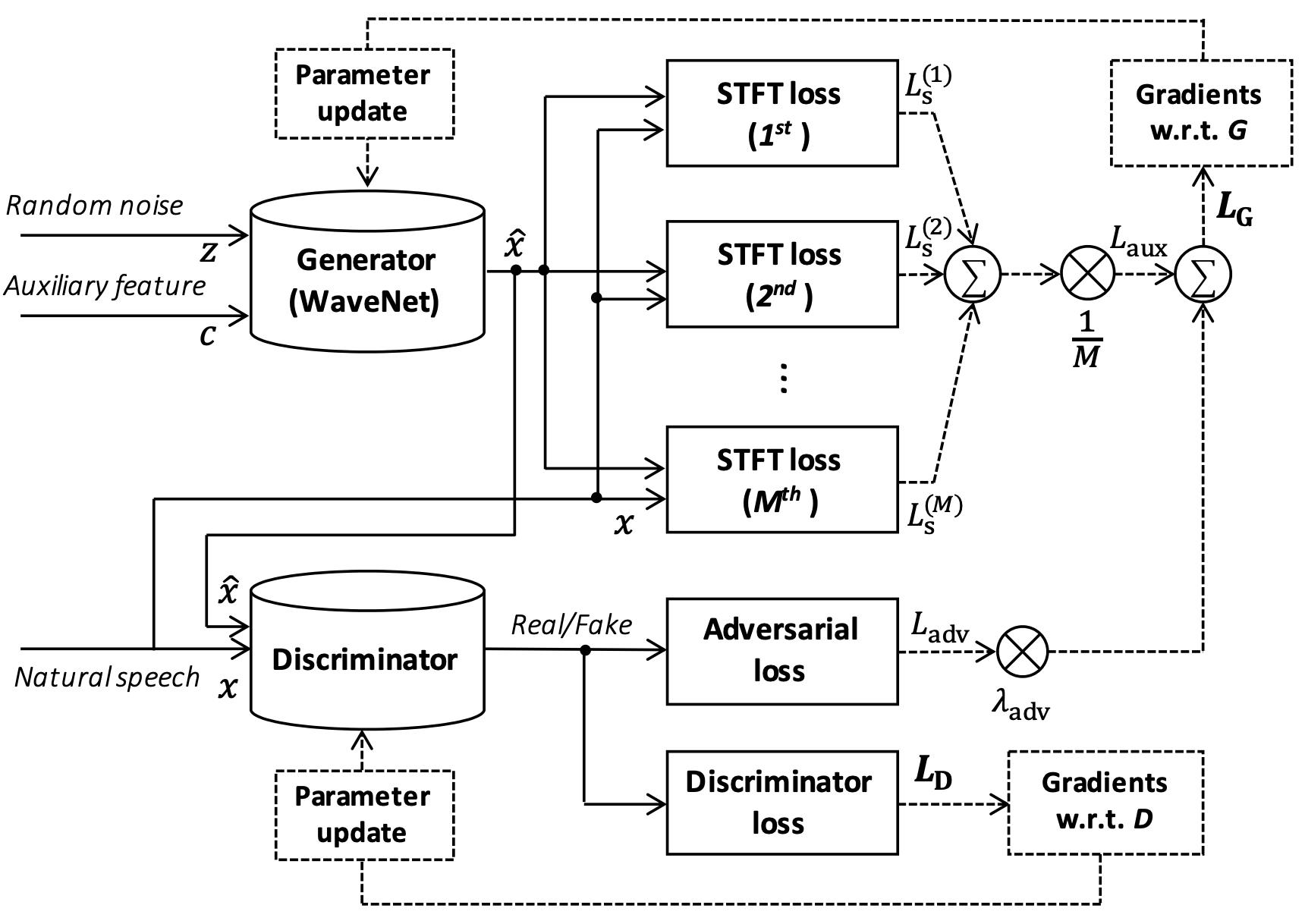
各 GAN Vocoder 的生成器和判别器的 Loss 的区别如下表格所示:
| Model | Generator Loss | Discriminator Loss |
|---|---|---|
| Mel GAN | adversial loss Feature Matching | Multi-Scale Discriminator |
| Parallel Wave GAN | adversial loss Multi-resolution STFT loss | adversial loss |
| Multi-Band Mel GAN | adversial loss full band Multi-resolution STFT loss sub band Multi-resolution STFT loss | Multi-Scale Discriminator |
| HiFi GAN | adversial loss Feature Matching Mel-Spectrogram Loss | Multi-Scale Discriminator Multi-Period Discriminator |
初始化声码器 Parallel WaveGAN
vocoder = PWGGenerator(**pwg_config["generator_params"])
# 模型加载预训练参数
vocoder.set_state_dict(paddle.load(pwg_checkpoint)["generator_params"])
vocoder.remove_weight_norm()
# 推理阶段不启用 batch norm 和 dropout
vocoder.eval()
# 读取数据预处理阶段数据集的均值和标准差
stat = np.load(pwg_stat)
mu, std = stat
mu, std = paddle.to_tensor(mu), paddle.to_tensor(std)
pwg_normalizer = ZScore(mu, std)
# 构建归一化的模型
pwg_inference = PWGInference(pwg_normalizer, vocoder)
pwg_inference.eval()
print("Parallel WaveGAN done!")
调用声码器
with paddle.no_grad():
wav = pwg_inference(mel)
print("shepe of wav (time x n_channels):%s"%wav.shape)
# 绘制声码器输出的波形图
wave_data = wav.numpy().T
time = np.arange(0, wave_data.shape[1]) * (1.0 / fastspeech2_config.fs)
fig, ax = plt.subplots(figsize=(16, 6))
plt.plot(time, wave_data[0])
plt.title('Waveform')
plt.xlabel('Time (seconds)')
plt.ylabel('Amplitude (normed)')
plt.tight_layout()
播放音频
dp.Audio(wav.numpy().T, rate=fastspeech2_config.fs)
保存音频
!mkdir output
sf.write(
"output/output.wav",
wav.numpy(),
samplerate=fastspeech2_config.fs)
进阶 —— 个性化调节
FastSpeech2 模型可以个性化地调节音素时长、音调和能量,通过一些简单的调节就可以获得一些有意思的效果。
例如对于以下的原始音频"凯莫瑞安联合体的经济崩溃,迫在眉睫"。
原始音频
点击播放
speed x 1.2
点击播放
speed x 0.8
点击播放
pitch x 1.3(童声)
点击播放
robot
点击播放
具体实现代码请参考 Style FastSpeech2。
用 PaddleSpeech 训练 TTS 模型
PaddleSpeech 的 examples 是按照 数据集/模型 的结构安排的:
examples
├── aishell3
│ ├── README.md
│ ├── tts3
│ └── vc0
├── csmsc
│ ├── README.md
│ ├── tts2
│ ├── tts3
│ ├── voc1
│ └── voc3
├── ...
└── ...
我们在每个数据集的 README.md 介绍了子目录和模型的对应关系, 在 TTS 中有如下对应关系:
tts0 - Tactron2
tts1 - TransformerTTS
tts2 - SpeedySpeech
tts3 - FastSpeech2
voc0 - WaveFlow
voc1 - Parallel WaveGAN
voc2 - MelGAN
voc3 - MultiBand MelGAN
基于 CSMCS 数据集训练 FastSpeech2 模型
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
cd examples/csmsc/tts3
根据 README.md, 下载 CSMCS 数据集和其对应的强制对齐文件, 并放置在对应的位置
./run.sh
run.sh 中包含预处理、训练、合成、静态图推理等步骤:
#!/bin/bash
set -e
source path.sh
gpus=0,1
stage=0
stop_stage=100
conf_path=conf/default.yaml
train_output_path=exp/default
ckpt_name=snapshot_iter_153.pdz
# with the following command, you can choice the stage range you want to run
# such as `./run.sh --stage 0 --stop-stage 0`
# this can not be mixed use with `$1`, `$2` ...
source $MAIN_ROOT/utils/parse_options.sh || exit 1
if [ $stage -le 0 ] && [ $stop_stage -ge 0 ]; then
# prepare data
bash ./local/preprocess.sh $conf_path || exit -1
fi
if [ $stage -le 1 ] && [ $stop_stage -ge 1 ]; then
# train model, all `ckpt` under `train_output_path/checkpoints/` dir
CUDA_VISIBLE_DEVICES=$gpus ./local/train.sh $conf_path $train_output_path || exit -1
fi
if [ $stage -le 2 ] && [ $stop_stage -ge 2 ]; then
# synthesize, vocoder is pwgan
CUDA_VISIBLE_DEVICES=$gpus ./local/synthesize.sh $conf_path $train_output_path $ckpt_name || exit -1
fi
if [ $stage -le 3 ] && [ $stop_stage -ge 3 ]; then
# synthesize_e2e, vocoder is pwgan
CUDA_VISIBLE_DEVICES=$gpus ./local/synthesize_e2e.sh $conf_path $train_output_path $ckpt_name || exit -1
fi
if [ $stage -le 4 ] && [ $stop_stage -ge 4 ]; then
# inference with static model
CUDA_VISIBLE_DEVICES=$gpus ./local/inference.sh $train_output_path || exit -1
fi
基于 CSMCS 数据集训练 Parallel WaveGAN 模型
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
cd examples/csmsc/voc1
根据 README.md, 下载 CSMCS 数据集和其对应的强制对齐文件, 并放置在对应的位置
./run.sh
run.sh 中包含预处理、训练、合成等步骤:
#!/bin/bash
set -e
source path.sh
gpus=0,1
stage=0
stop_stage=100
conf_path=conf/default.yaml
train_output_path=exp/default
ckpt_name=snapshot_iter_5000.pdz
# with the following command, you can choice the stage range you want to run
# such as `./run.sh --stage 0 --stop-stage 0`
# this can not be mixed use with `$1`, `$2` ...
source $MAIN_ROOT/utils/parse_options.sh || exit 1
if [ $stage -le 0 ] && [ $stop_stage -ge 0 ]; then
# prepare data
./local/preprocess.sh $conf_path || exit -1
fi
if [ $stage -le 1 ] && [ $stop_stage -ge 1 ]; then
# train model, all `ckpt` under `train_output_path/checkpoints/` dir
CUDA_VISIBLE_DEVICES=$gpus ./local/train.sh $conf_path $train_output_path || exit -1
fi
if [ $stage -le 2 ] && [ $stop_stage -ge 2 ]; then
# synthesize
CUDA_VISIBLE_DEVICES=$gpus ./local/synthesize.sh $conf_path $train_output_path $ckpt_name || exit -1
fi
FAQ
- 需要注意的问题
- 经验与分享
- 用户的其他问题
作业
在 CSMSC 数据集上利用 FastSpeech2 和 Parallel WaveGAN 实现一个中文 TTS 系统。
关注 PaddleSpeech
请关注我们的 Github Repo,非常欢迎加入以下微信群参与讨论:
- 扫描二维码
- 添加运营小姐姐微信
- 通过后回复【语音】
- 系统自动邀请加入技术群

P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
以上是关于飞桨PaddleSpeech语音技术课程— 语音唤醒的主要内容,如果未能解决你的问题,请参考以下文章