机器学习笔记:特征缩放(sklearn实现)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记:特征缩放(sklearn实现)相关的知识,希望对你有一定的参考价值。
1 特征缩放介绍
对于有些模型来说,特征缩放是很重要的,举几个例子:
- 神经网络——进行梯度下降时,如果有一个方向数值特别大,那么梯度肯定是向着这个方向走的
- PCA——需要计算类内和类间的variance
- KNN和K-Means——需要计算点与点之间的距离
所以在送入模型之前,进行特征缩放是很重要的
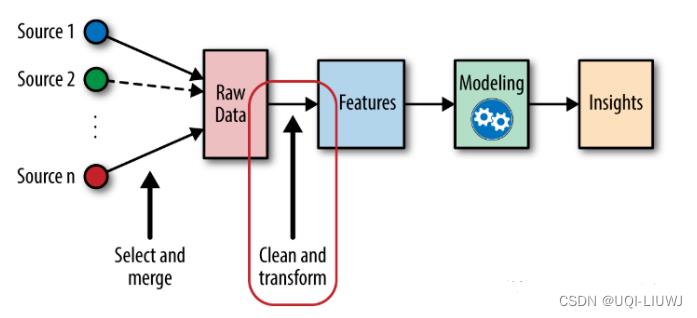
2 标准化 standardization
- 标准化是将数据按比例缩放,使之落入一个小的特定区间,把数据转换为统⼀的标准。
- 最常用的标准化是z-score标准化,即零-均值标准化
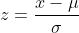
- 标准化缩放后,特征就变为具有标准正态分布了
2.1 sklearn 实现
from sklearn.preprocessing import StandardScaler
X = np.array([[0, 0, 0],
[0, 1, 1],
[1, 0, 1],
[1, 1, 1]])
stand_x=StandardScaler().fit_transform(X)
stand_x
'''
array([[-1. , -1. , -1.73205081],
[-1. , 1. , 0.57735027],
[ 1. , -1. , 0.57735027],
[ 1. , 1. , 0.57735027]])
'''每一列进行标准化
3 规范化(归一化)normalization
把数据变为(0,1)之间的小数,可以使处理过程更加便捷、快速。
常见的规范化为 min-max缩放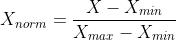
3.1 sklearn实现
from sklearn.preprocessing import MinMaxScaler
X = np.array([[0, 1, 2],
[0, 2, 3],
[1, 4, 9],
[1, 1, 1]])
stand_x=MinMaxScaler().fit_transform(X)
stand_x
'''
array([[0. , 0. , 0.125 ],
[0. , 0.33333333, 0.25 ],
[1. , 1. , 1. ],
[1. , 0. , 0. ]])
'''4 标准化和规范化的区别
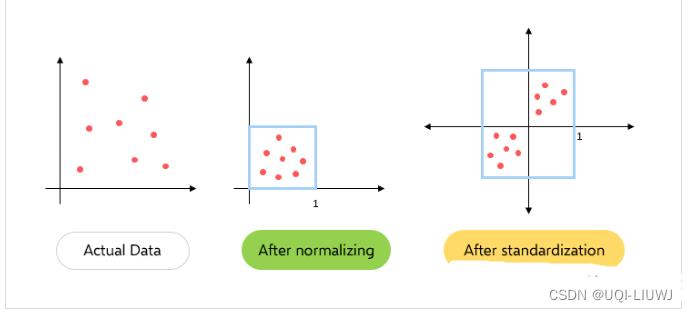
-
在规范化中只更改数据的范围,而在标准化中会更改数据分布的形状。
-
规范化将这些值重新缩放到[0,1]的范围内。在所有参数都需要具有相同的正刻度的情况下是非常有效的。但是数据集中的异常值会丢失。
-
而在标准化中,数据被缩放到平均值(μ)为0,标准差(σ)为1(单位方差)。
-
规范化在0到1之间缩放数据,所有数据都为正。标准化后的数据以零为中心的正负值。
参考内容:特征工程中的缩放和编码的方法总结
以上是关于机器学习笔记:特征缩放(sklearn实现)的主要内容,如果未能解决你的问题,请参考以下文章