kubernetes和kubersphere的关系
Posted 羌俊恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kubernetes和kubersphere的关系相关的知识,希望对你有一定的参考价值。
一、概要
我们都知道kubernetes(k8s)是容器的一个编排解决方案,kubersphere是容器的云化管理平台;那这2者的关系是怎么样的呢?有什么前世今生,纠葛呢?
Kubernetes(K8s)是Google公司开源的一个容器(Container)编排与调度管理框架,该项目最初是Google内部面向容器的集群管理系统,而现在是由Cloud Native Computing Foundation(CNCF,云原生计算基金会)托管的开源平台,由Google、AWS、Microsoft、IBM、Intel、Cisco和Red Hat等主要参与者支持,其目标是通过创建一组新的通用容器技术来推进云原生技术和服务的开发。作为领先的容器编排引擎,Kubernetes提供了一个抽象层,使其可以在物理或虚拟环境中部署容器应用程序,提供以容器为中心的基础架构。Kubernetes系统还拥有一个庞大而活跃的开发人员社区,这使其成为历史上增长最快的开源项目之一。它是GitHub上排名前10的项目,也是Go语言最大的开源项目之一,主要特点:
可移植:支持公有云、私有云、混合云、多重云(Multi-cloud)。
可扩展:模块化、插件化、可挂载、可组合。
自动化:自动部署、自动重启、自动复制、自动伸缩/扩展。
Kubernetes系统用于管理分布式节点集群中的微服务或容器化应用程序,并且其提供了零停机时间部署、自动回滚、缩放和容器的自愈(其中包括自动配置、自动重启、自动复制的高弹性基础设施,以及容器的自动缩放等)等功能。k8s支持众多云原生组件和应用,庞大而复杂;主要面向研发人员,使其更专注与业务,而这对于最终用户来管理就有些困难;下图是一些基于k8s的众多发行版:

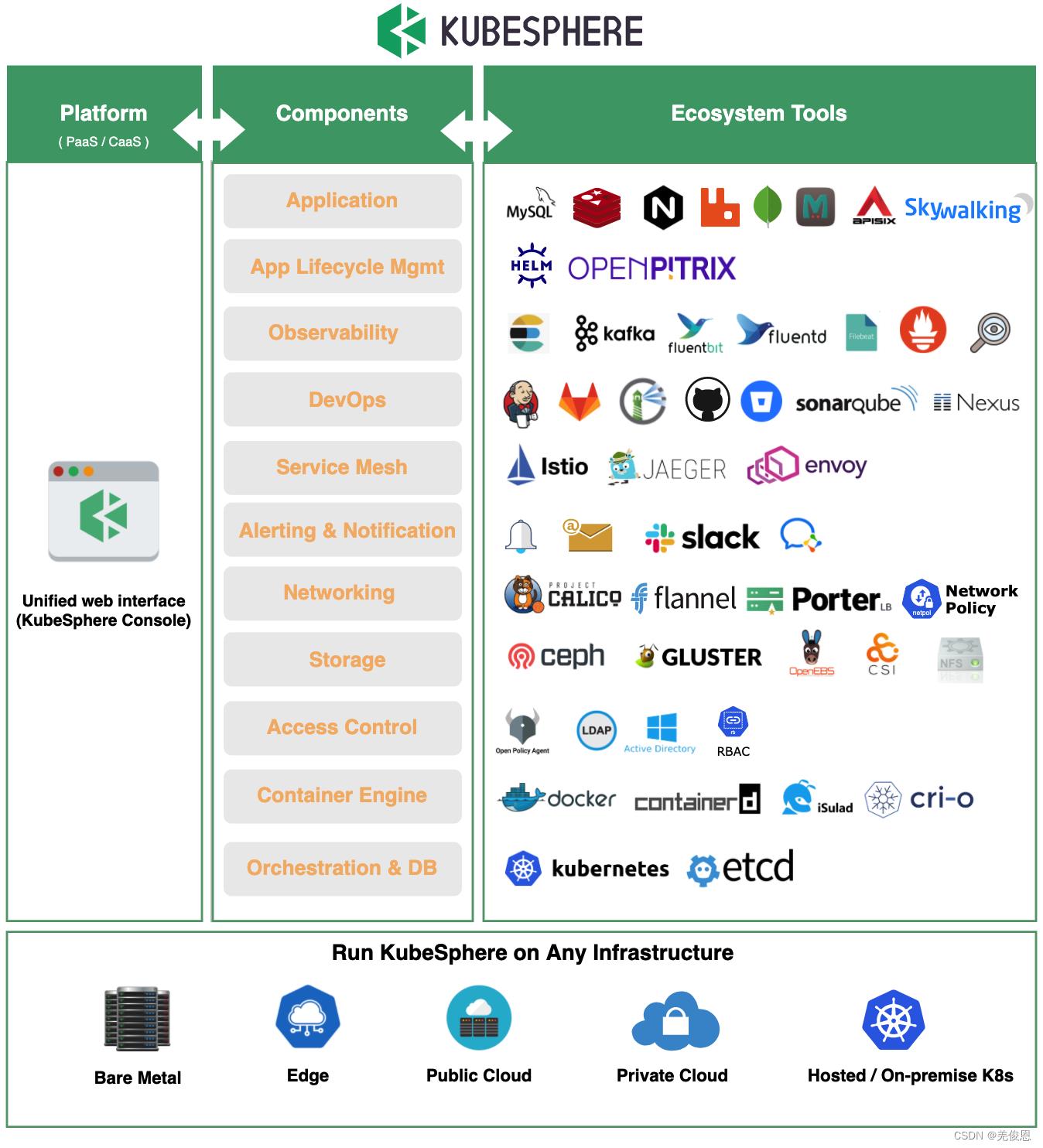
KubeSphere 是国内一家青云(QingCloud)公司在 Kubernetes 之上构建的面向云原生应用的容器混合云,支持多云与多集群管理,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。2020年6月30日,青云QingCloud正式推出KubeSphere 3.0。KubeSphere是以Kubernetes为基础,管理云原生应用的一种分布式操作系统。它提供可插拔的开放式架构,可以很方便地与云原生生态进行即插即用(plug-and-play)的集成,让第三方应用可以无缝对接进来,让用户使用KubeSphere第三方应用,同时也跟KubeSphere原生应用一样,使用起来非常平滑。
目前,KubeSphere适配了大部分主流的云平台和容器平台,如阿里云、AWS、腾讯云,自己的青云QingCloud;容器平台如OpenShift、Rancher等。它也是CNCF的一员;KubeSphere 旨在解决 Kubernetes 在构建、部署、管理和可观测性等方面的痛点,提供全面的服务和自动化的应用供应、伸缩和管理,让研发更专注于代码编写。
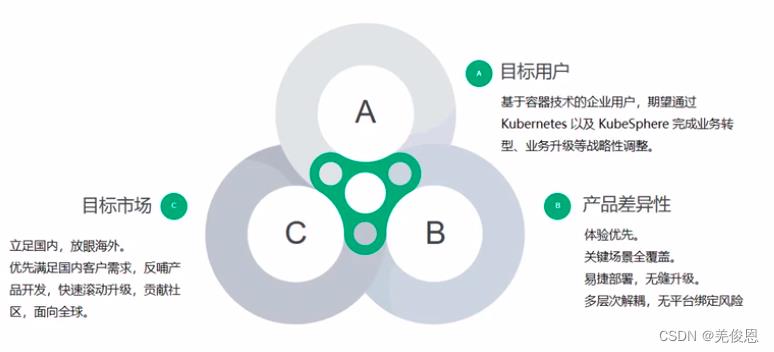
kubersphere也是一个灵活的轻量级容器 PaaS 平台; 对不同云生态系统的支持非常友好,对原生 Kubernetes 本身无任何的侵入 (Hack)。即KubeSphere 可以部署并运行在任何基础架构以及所有版本兼容的 Kubernetes 集群之上,包括虚拟机、物理机、数据中心、公有云和混合云等。
国际官网:https://kubesphere.io/;国内:https://kubesphere.com.cn/
项目地址:https://github.com/kubesphere/kubesphere
最新版为3.2.1,发行说明:https://kubesphere.com.cn/docs/release/release-v320/
二、架构
2.1 k8s架构:C/S架构
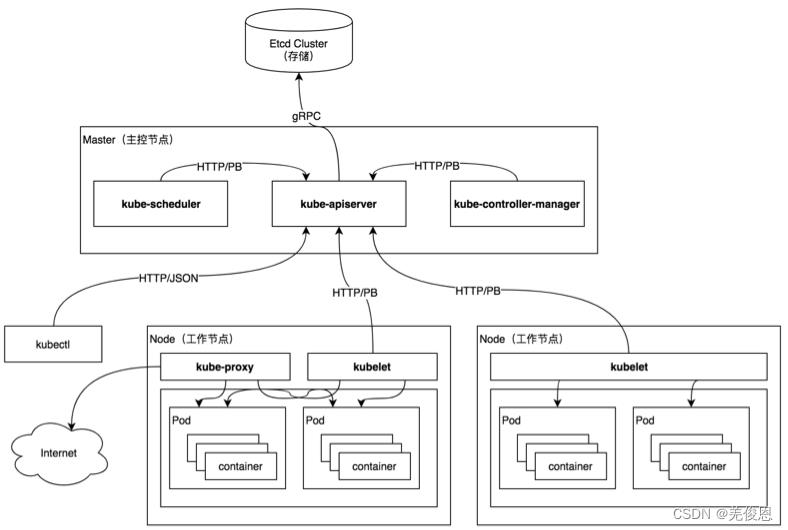
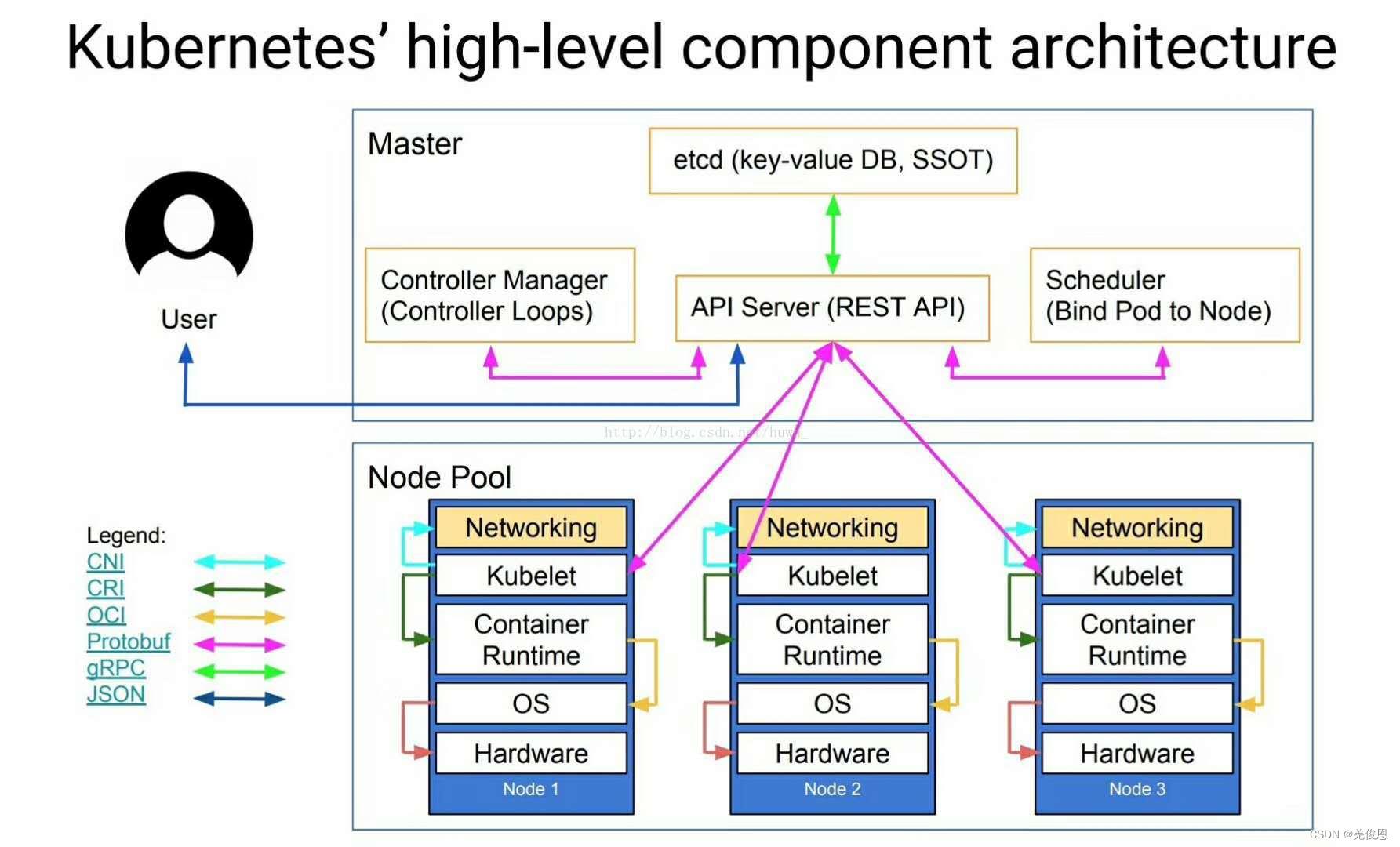
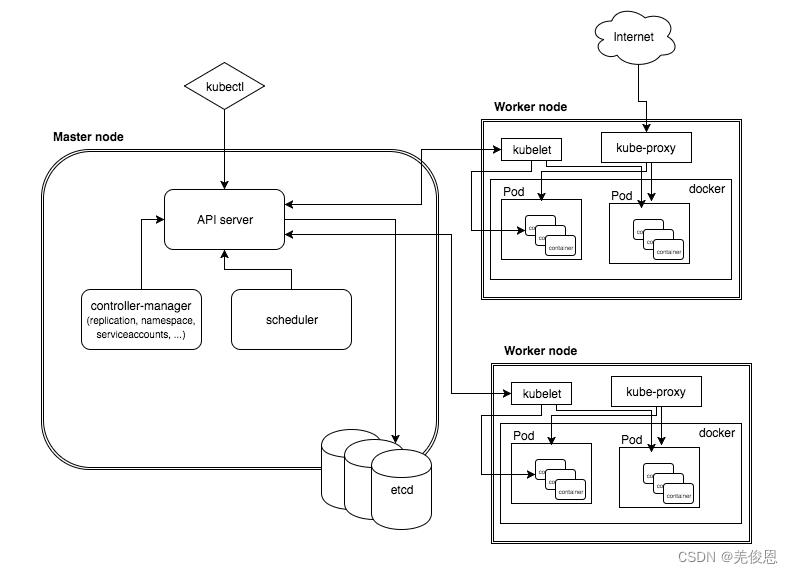
架构详解参看:kubernetes介绍
k8s配置资料:kubernetes资料 ;
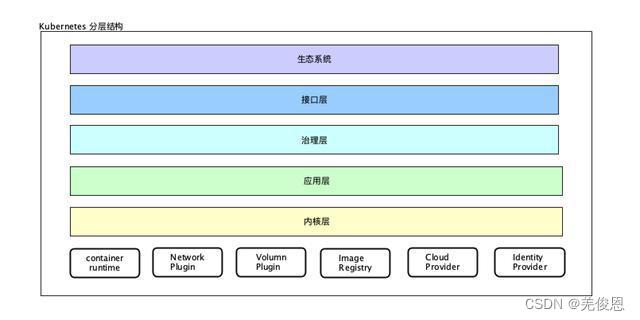
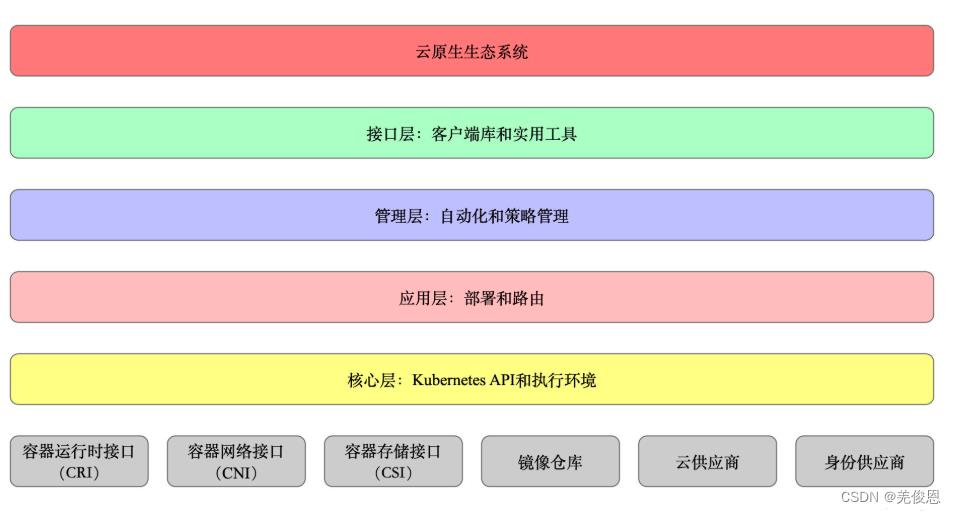
核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境;
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)、Service Mesh(部分位于应用层);
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)、Service Mesh(部分位于管理层);
接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦;
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴;
Kubernetes 外部:日志、监控、配置管理、CI/CD、Workflow、FaaS、OTS 应用、ChatOps、GitOps、SecOps 等;
Kubernetes 内部:CRI、CNI、CSI、镜像仓库、Cloud Provider、集群自身的配置和管理等;
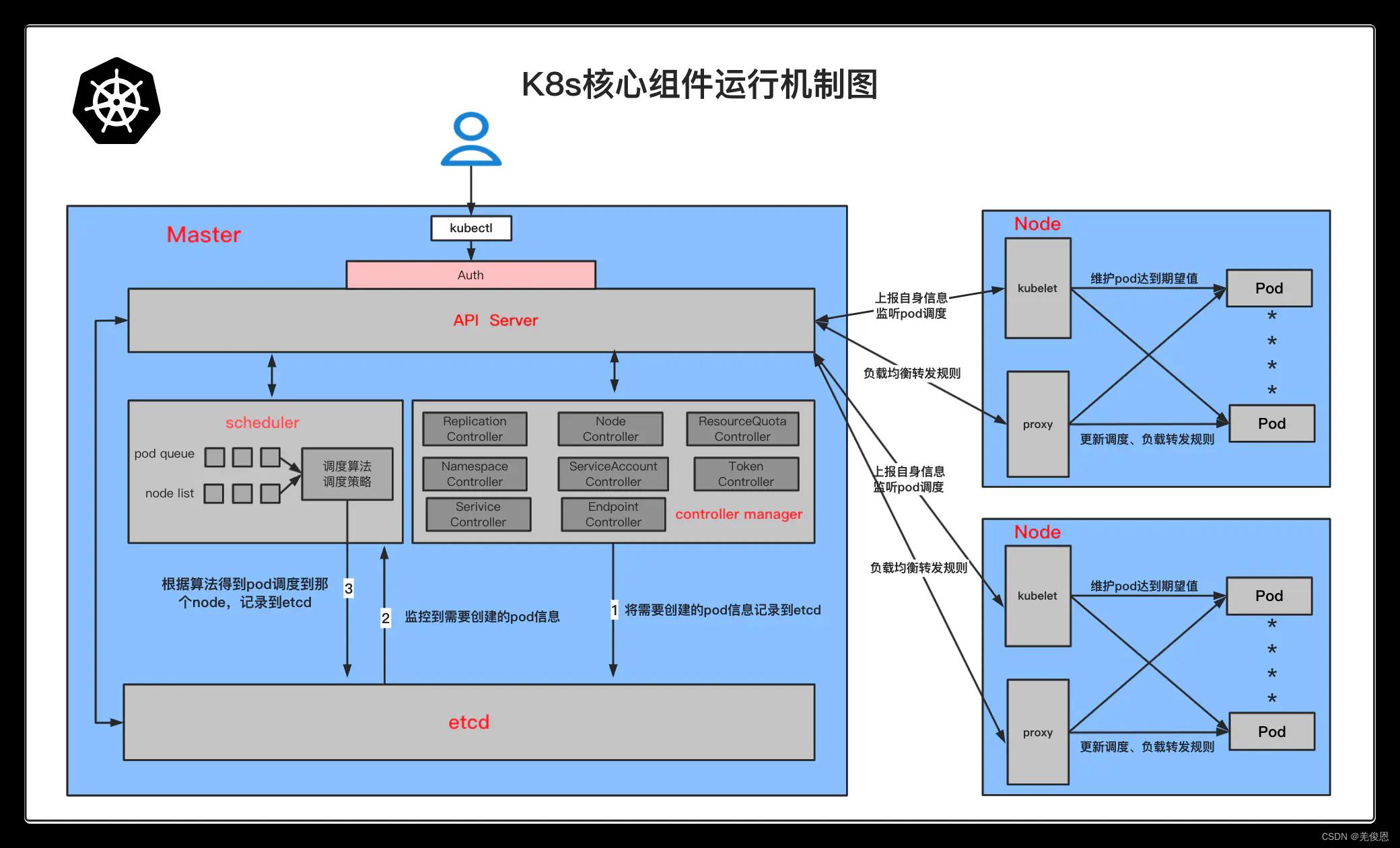
K8S工作流程:
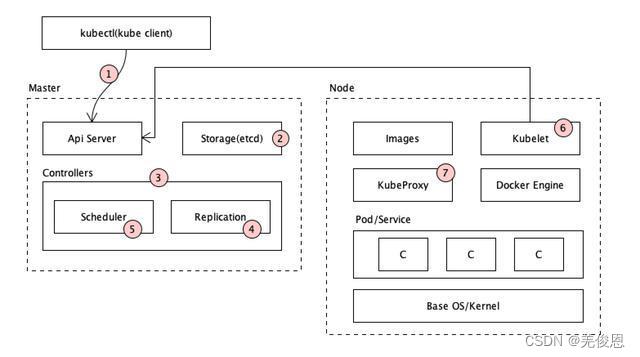
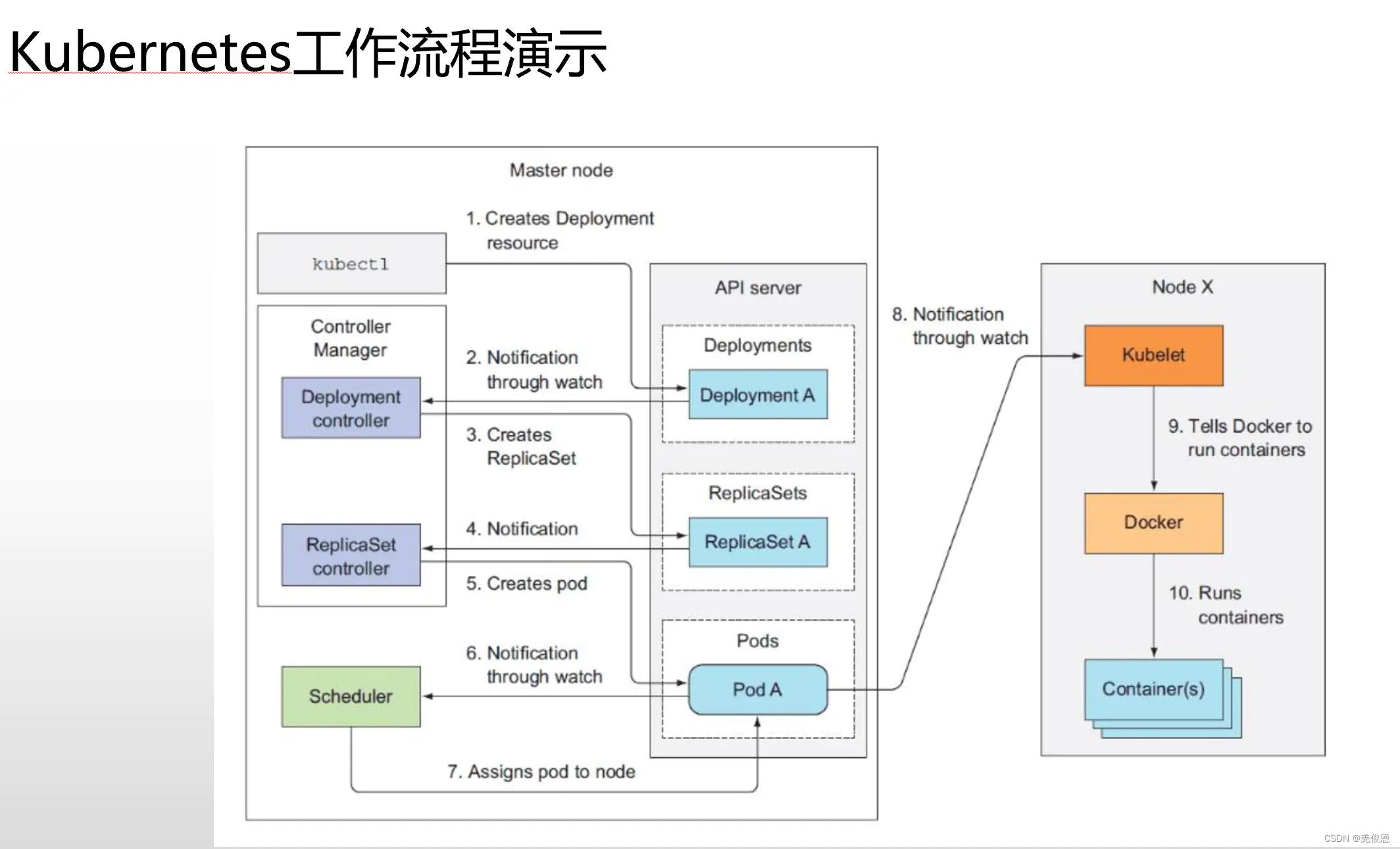
Pod创建时序图:
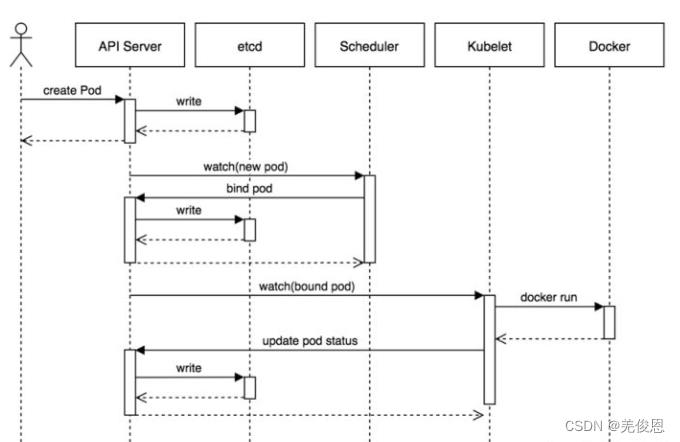
kubeproxy:为Service提供cluster内部的服务发现和负载均衡。它运行在集群各个主机上
管理网络通信,服务发现,负载均衡(使用轮询调度算法将请求发送到集群中的多个实例);当有数据发送到主机时,其将路由到正确的pod或容器;对于主机上发出的数据,基于请求地址发现远程服务器并将数据正确路由;
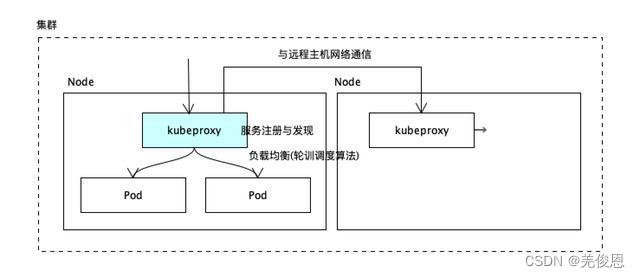
Api Server的工作流程:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
Controller的工作流程:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
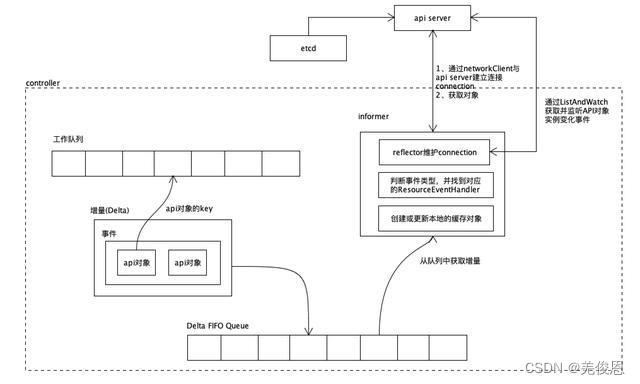
2.2 kubersphere生态及架构
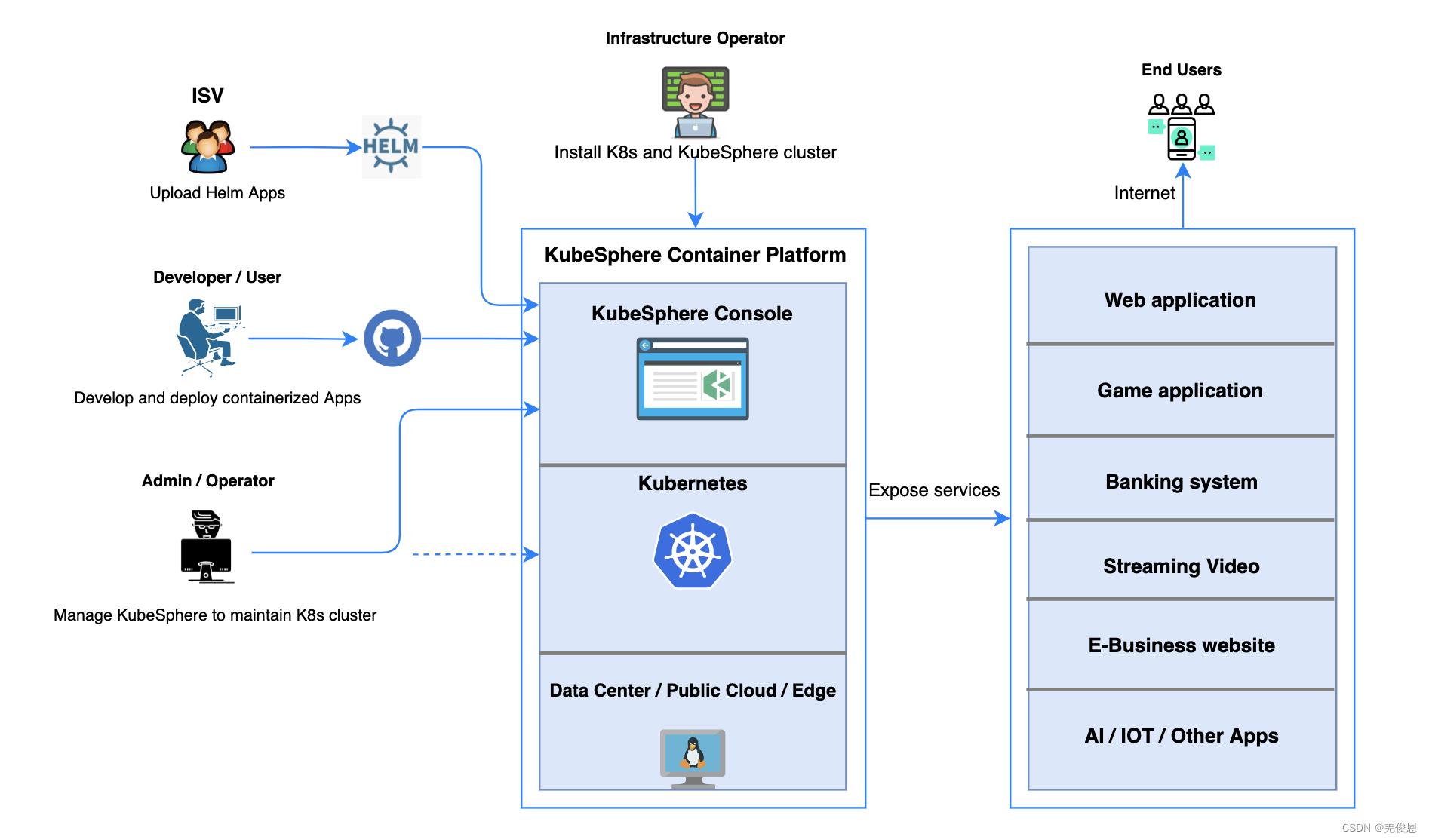
KubeSphere 将 前端 与 后端 分开,实现了面向云原生的设计,后端的各个功能组件可通过 REST API 对接外部系统。KubeSphere 无底层的基础设施依赖,可以运行在任何 Kubernetes、私有云、公有云、VM 或物理环境(BM)之上。 此外,它可以部署在任何 Kubernetes 发行版上。软件架构:
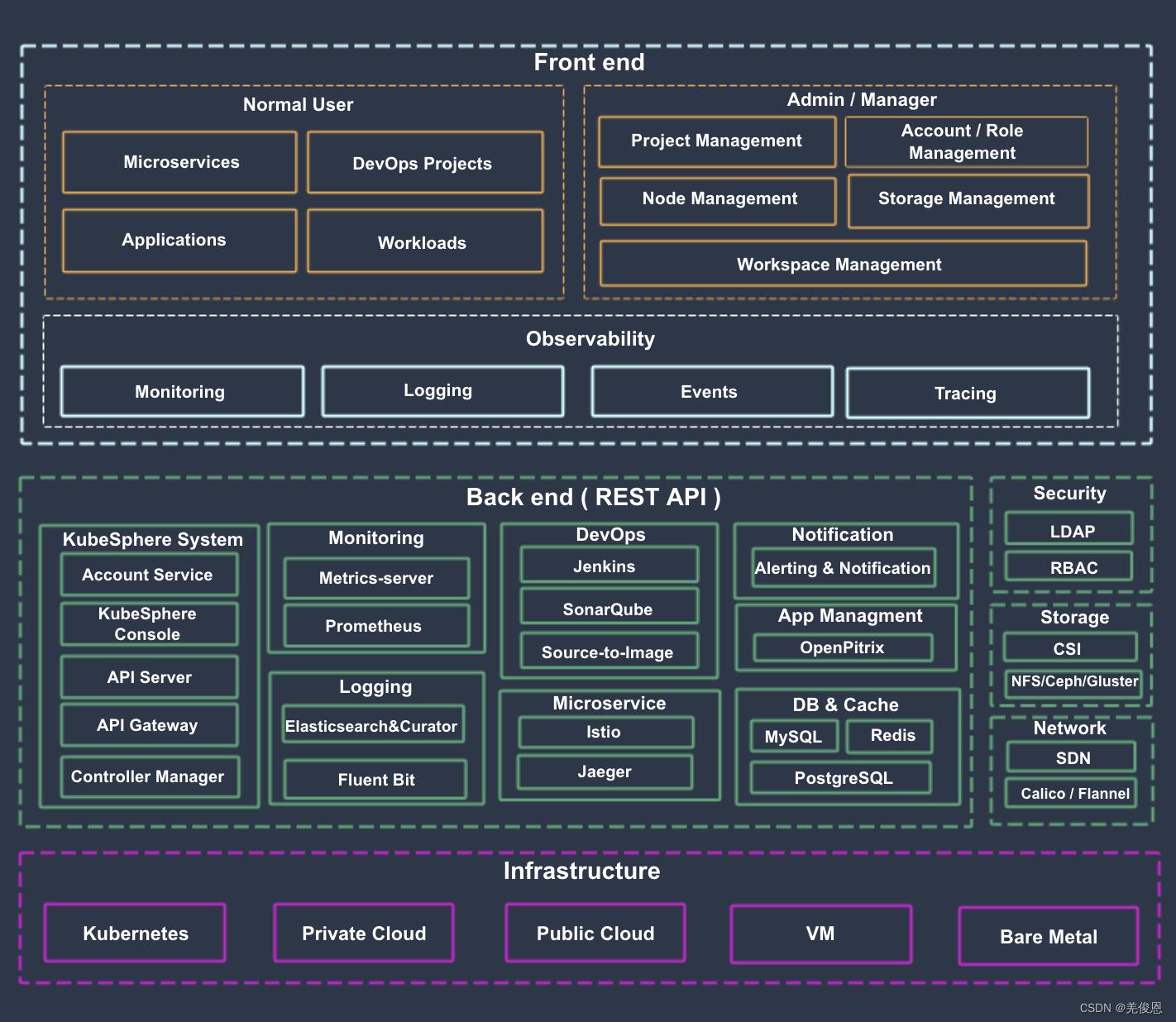
kube-API架构:KubeSphere 把用户对原生 Kubernetes 资源的请求通过 API Server 转发到 Kubernetes API Server 对原生资源进行操作和管理。
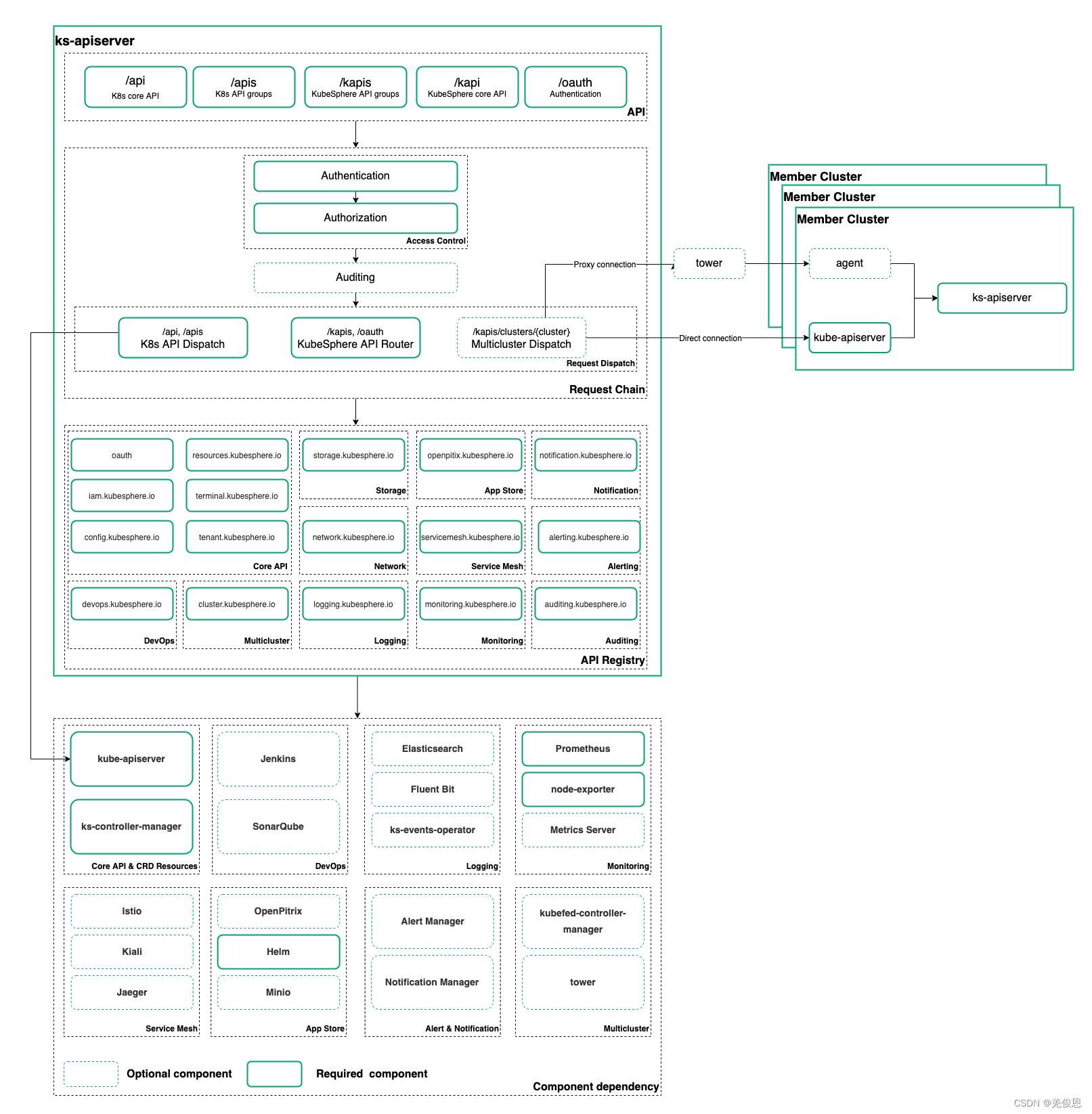
架构组件说明参看:官方文档和kubersphere组件;
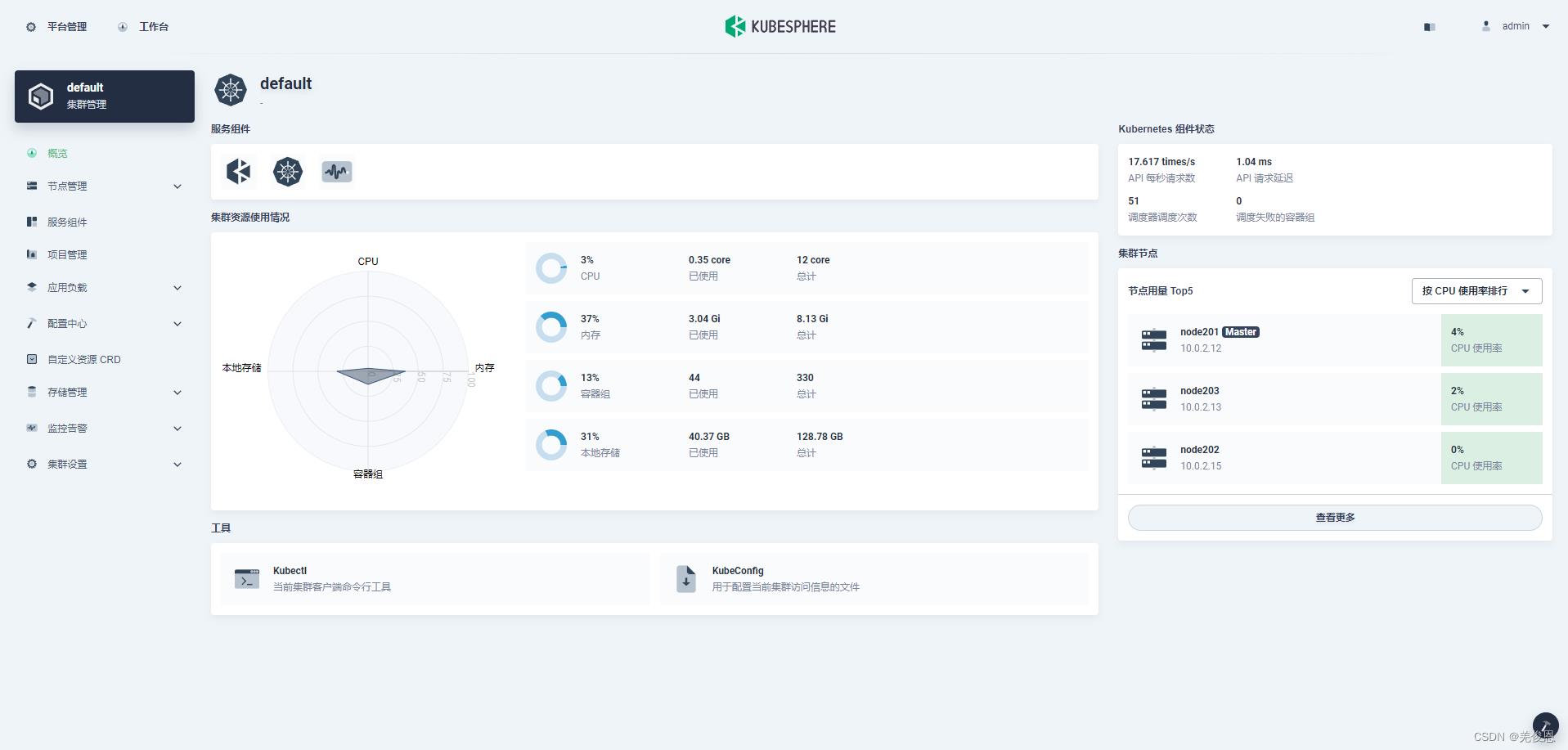
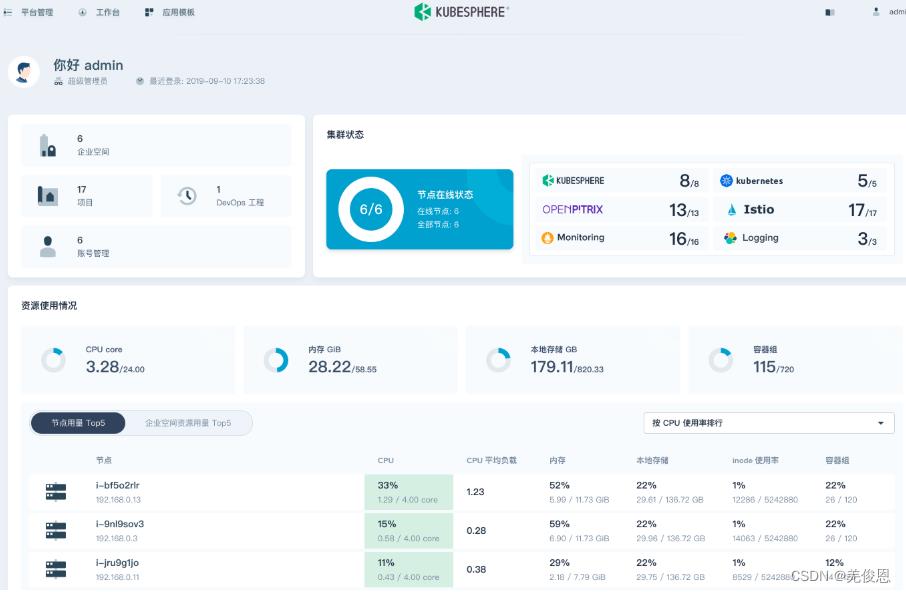
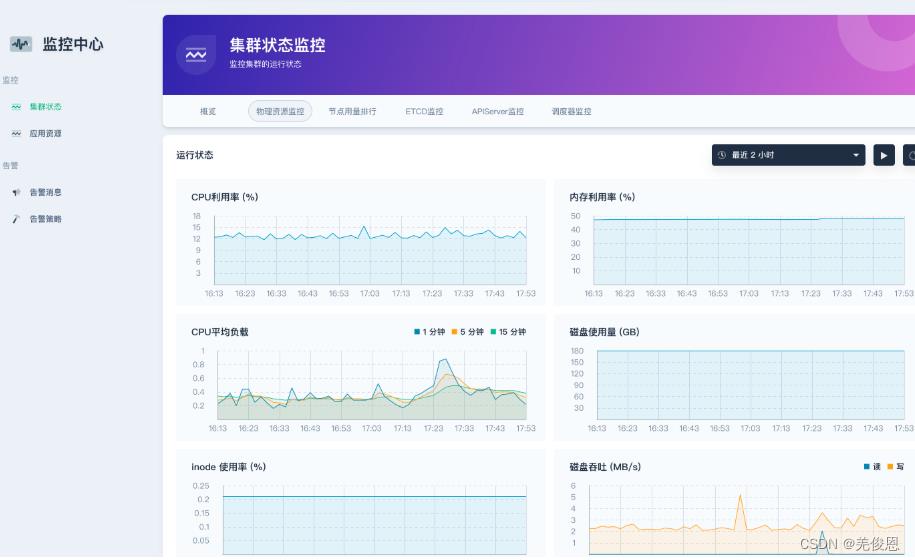
平台预览:

附录
1)软件系统中框架和引擎的概念区分
● 框架(framework):一般指为了实现某个业界标准或完成特定基本任务的软件组件规范,而软件组件是物理层面对软件架构的区分(比如常见nginx-Tomcat-redis-mysql),与其相对的模块则是从逻辑成名对软件系统功能的划分;软件框架也指为了实现某个软件组件规范时,提供规范所要求的基础功能的软件产品;它关注的重点是规范。框架是一种特殊的软件,它并不能提供完整无缺的解决方案,而是为你构建解决方案提供良好的基础。框架是半成品。典型地,框架是系统或子系统的半成品;框架中的服务尅被最终应用系统直接调用,而框架中的扩展点是供应用开发人员定制的“可变化点”。
比如k8s框架里的就要求该框架下的组件需要符合云原生特性(某种架构原则);
1、服务化原则
随着规模和业务的压力挑战,需重构应用,通过模块化与组件化的手段分离关注点,降低应用的复杂度,突破垂直扩展(Scale Up)的瓶颈,并将其转化为支撑水平扩展(Scale Out)的能力,将单体应用进一步拆分,按业务边界重新划分成分布式应用,使应用与应用之间不再直接共享数据,而是通过约定好的协议/接口进行通信,提高扩展性,提升软件的开发效率,降低维护成本。
服务化架构采用的是面向接口编程方式,增加了软件的复用程度,增强了水平扩展的能力。服务化设计原则还强调在架构层面抽象化业务模块之间的关系,从而帮助业务模块实现基于服务流量(而非网络流量)的策略控制和治理,而无须关注这些服务是基于何种编程语言开发的。比如,Netflix公司的 Eureka、Zuul、Hystrix 等出色的微服务组件。国内阿里 Apache Dubbo、Nacos、Sentinel、Seata、Chaos Blade 等开源项目;这种环境下要求应用启动更快、应用与应用之间无强依赖关系、应用能够在不同规格的节点之间随意调度等。
2、弹性原则
系统部署规模可以随着业务量变化自动调整大小,而无须根据事先的容量规划准备固定的硬件和软件资源,更好地支持业务规模的爆发式扩张,不再因为软硬件资源储备不足而错失机会和无效应对。这一点在移动互联网和游戏行业中显得尤为突出。要想构建弹性的系统架构,需要遵循如下四个基本原则:
1>按功能切割应用
一个大型的复杂系统可能由成百上千个服务组成,架构师在设计架构时,需要遵循的原则是:将相关的逻辑放到一起,不相关的逻辑拆解到独立的服务中,各服务之间通过标准的服务发现(Service Discovery)找到对方,并使用标准的接口进行通信。各服务之间松耦合,这使得每一个服务能够各自独立地完成弹性伸缩,从而避免服务上下游关联故障的发生。
2>支持水平切分
按功能切割应用并没有完全解决弹性的问题。一个应用被拆解为众多服务后,随着用户流量的增长,单个服务最终也会遇到系统瓶颈。可以设计每个服务都具备可水平切分的能力,将服务切分为不同的逻辑单元,由每个单元处理一部分用户流量,从而使服务自身具备良好的扩展能力。这其中最大的挑战在于数据库系统,因为数据库系统自身是有状态的,所以合理地切分数据并提供正确的事务机制将是一个非常复杂的工程。不过,在云原生时代,云平台所提供的云原生数据库服务可以解决大部分复杂的分布式系统问题,如果企业是通过云平台提供的能力来构建弹性系统,使用云数据库系统也就具备自带弹性能力。
3>自动化部署
业务系统突发流量通常是无法预计的,常用的解决方案是,通过事先人工扩容系统的方式,使系统具备支持更大规模用户访问的能力,但也同时造成资源的浪费。因此在完成架构拆分之后,弹性系统还需要具备自动化部署能力,以便根据既定的规则或者外部流量突发信号触发系统的自动化扩容功能,满足系统对于缩短突发流量影响时长的及时性要求,同时在峰值时段结束后自动缩容系统,降低系统运行的资源占用成本。
4>支持服务降级
弹性系统需要提前设计异常应对方案,比如,对服务进行分级治理,在弹性机制失效、弹性资源不足或者流量峰值超出预期等异常情况下,系统架构需要具备服务降级的能力,通过降低部分非关键服务的质量,或者关闭部分增强功能来让出资源,并扩容重要功能对应的服务容量,以确保产品的主要功能不受影响。随着云原生技术的发展,FaaS、Serverless 等技术生态逐步成熟,构建大规模弹性系统的难度逐步降低。当企业以 FaaS、Serverless 等技术理念作为系统架构的设计原则时,系统就具备了弹性伸缩的能力,企业也就无须额外为“维护弹性系统自身”付出成本。
3、可观测原则
在云计算这样的分布式系统中,主动通过日志、链路跟踪和度量等手段,让一次 App 点击所产生的多次服务调用耗时、返回值和参数都清晰可见,甚至可以下钻到每次第三方软件调用、SQL 请求、节点拓扑、网络响应等信息中。可观测性更强调主动性,运维、开发和业务人员通过这样的主动观测能力可以实时掌握软件的运行情况,并获得前所未有的关联分析能力,以便不断优化业务的健康度和用户体验。在微服务架构中,各服务之间松耦合的设计方式使得版本迭代更快、周期更短;基础设施层中的 Kubernetes 等已经成为容器的默认平台;服务可以通过流水线实现持续集成与部署。这些变化可将服务的变更风险降到最低,提升了研发的效率。在微服务架构中,系统的故障点可能出现在任何地方,针对可观测性进行体系化设计,可以有效降低 MTTR(故障平均修复时间)。
4、韧性原则
韧性是指当软件所依赖的软硬件组件出现异常时,软件所表现出来的抵御能力。这些异常通常包括硬件故障、硬件资源瓶颈(如 CPU 或网卡带宽耗尽)、业务流量超出软件设计承受能力、影响机房正常工作的故障或灾难、所依赖软件发生故障等可能造成业务不可用的潜在影响因素。当这些非正常场景出现时,业务需要尽可能地保证服务质量,满足当前以联网服务为代表的“永远在线”的要求。
韧性原则的实践与常见架构主要包括:服务异步化能力、重试 / 限流 / 降级 / 熔断 / 反压、主从模式、集群模式、多 AZ(Availability Zone,可用区)的高可用、单元化、跨区域(Region)容灾、异地多活容灾等。比如:可以在接入层通过流量清洗实现安全策略,防御黑产攻击;通过精细化限流策略确保峰值流量稳定,从而保障后端工作正常进行。通过单元化机制实现了跨区域多活容灾,通过同城容灾机制实现同城双活容灾,提升全局的高可用能力;在同一 IDC 内通过微服务和容器技术实现业务的无状态迁移;通过多副本部署提高高可用能力;通过消息完成微服务间的异步解耦以降低服务的依赖性,同时提升系统吞吐量。设置降级开关,并通过故障演练不断强化系统健壮性。
5、所有过程自动化原则
IaC、GitOps、OAM、Operator 和大量自动化交付工具在 CI/CD(持续集成 /持续交付)流水线中的实践,企业可以标准化企业内部的软件交付过程,也可以在标准化的基础上实现自动化,即通过配置数据自描述和面向终态的交付过程,实现整个软件交付和运维的自动化。要想实现大规模的自动化,需要遵循如下四个基本原则:
1>标准化
实施自动化,首先要通过容器化、IaC、OAM 等手段,标准化业务运行的基础设施,并进一步标准化对应用的定义乃至交付的流程。只有实现了标准化,才能解除业务对特定的人员和平台的依赖,实现业务统一和大规模的自动化操作。
2>面向终态
面向终态是指声明式地描述基础设施和应用的期望配置,持续关注应用的实际运行状态,使系统自身反复地变更和调整直至趋近终态的一种思想。面向终态的原则强调应该避免直接通过工单系统、工作流系统组装一系列过程式的命令来变更应用,而是通过设置终态,让系统自己决策如何执行变更。
3>关注点分离
自动化最终所能达到的效果不只取决于工具和系统的能力,更取决于为系统设置目标的人。在描述系统终态时,要将应用研发、应用运维、基础设施运维这几种主要角色所关注的配置分离开来,各个角色只需要设置自己所关注和擅长的系统配置,以便确保设定的系统终态是合理的。
4>面向失败设计
要想实现全部过程自动化,一定要保证自动化的过程是可控的,对系统的影响是可预期的。我们不能期望自动化系统不犯错误,但可以保证即使是在出现异常的情况下,错误的影响范围也是可控的、可接受的。因此,自动化系统在执行变更时,同样需要遵循人工变更的最佳实践,保证变更是可灰度执行的、执行结果是可观测的、变更是可快速回滚的、变更影响是可追溯的。通过标准的声明式配置,描述应用健康的探测方法和应用的启动方法、应用启动后需要挂载和注册的服务发现以及配置管理数据库(Configuration Management Data Base,CMDB)信息。通过这些标准的配置,云平台可以反复探测应用,并在故障发生时执行自动化修复操作。另外,为了防止故障探测本身可能存在的误报问题,应用的运维人员还可以根据自身容量设置服务不可用实例的比例,让云平台能够在进行自动化故障恢复的同时保证业务可用性。
6、零信任原则
在基于边界模型的传统安全架构设计中,通常是在可信和不可信的资源之间架设一道墙来分隔安全域;这种安全架构设计模式下,一旦入侵者渗透到边界内,就能够随意访问边界内的资源了。如今,边界不再是由组织的物理位置来定义,而是已经扩展到了需要访问组织资源和服务的所有地方,传统的防火墙和 VPN 已经无法可靠且灵活地应对这种新边界。因此,我们需要一种全新的安全架构,来灵活适应云原生和移动时代环境的特性,不论员工在哪里办公,设备在哪里接入,应用部署在哪里,数据的安全性都能够得到有效保护。如果要实现这种新的安全架构,就要依托零信任模型。传统安全架构认为防火墙内的一切都是安全的,而零信任模型假设防火墙边界已经被攻破,且每个请求都来自于不可信网络,因此每个请求都需要经过验证。简单来说,“永不信任,永远验证”。在零信任模型下,每个请求都要经过强认证,并基于安全策略得到验证授权。与请求相关的用户身份、设备身份、应用身份等,都会作为核心信息来判断请求是否安全。如果我们围绕边界来讨论安全架构,那么传统安全架构的边界是物理网络,而零信任安全架构的边界则是身份,这个身份包括人的身份、设备的身份、应用的身份等。
>1. 显式验证
对每个访问请求都进行认证和授权。认证和授权需要基于用户身份、位置、设备信息、服务和工作负载信息以及数据分级和异常检测等信息来进行。对于企业内部应用之间的通信,不能简单地判定来源 IP是内部 IP 就直接授权访问,而是应该判断来源应用的身份和设备等信息,再结合当前的策略授权。
>2. 最少权限
对于每个请求,只授予其在当下必需的权限,且权限策略应该能够基于当前请求上下文自适应。例如,HR 部门的员工应该拥有访问 HR相关应用的权限,但不应该拥有访问财务部门应用的权限。
>3. 假设被攻破
假设物理边界被攻破,则需要严格控制安全爆破半径,将一个整体的网络切割成对用户、设备、应用感知的多个部分。对所有的会话加密,使用数据分析技术保证对安全状态的可见性。从传统安全架构向零信任架构演进,会对软件架构产生深刻的影响,具体体现在如下三个方面。
第一,不能基于 IP 配置安全策略。在云原生架构下,不能假设 IP 与服务或应用是绑定的,这是由于自动弹性等技术的应用使得 IP 随时可能发生变化,因此不能以 IP 代表应用的身份并在此基础上建立安全策略。
第二,身份应该成为基础设施。授权各服务之间的通信以及人访问服务的前提是已经明确知道访问者的身份。在企业中,人的身份管理通常是安全基础设施的一部分,但应用的身份也需要管理。
第三,标准的发布流水线。在企业中,研发的工作通常是分布式的,包括代码的版本管理、构建、测试以及上线的过程,都是比较独立的。这种分散的模式将会导致在实际生产环境中运行的服务的安全性得不到有效保证。如果可以标准化代码的版本管理、构建以及上线的流程,那么应用发布的安全性就能够得到集中增强。
7、架构持续演进原则云原生架构本身也应该且必须具备持续演进的能力,而不是一个封闭式的、被设计后一成不变的架构。因此在设计时除了要考虑增量迭代、合理化目标选取等因素之外,还需要考虑组织(如:架构控制委员会)层面的架构治理和风险控制规范以及业务自身的特点,特别是在业务高速迭代的情况下,更应该重点考虑如何保证架构演进与业务发展之间的平衡。
更多参见:阿里巴巴云原生;
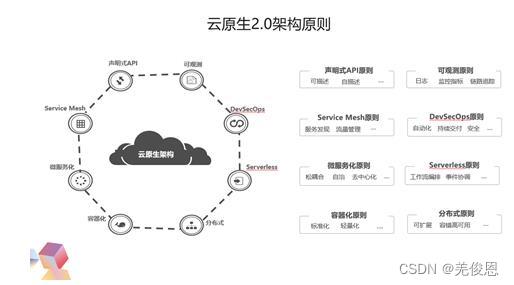
另外,华为云也曾提出云原生2.0八大架构原则,具体包括:容器化原则、分布式原则、微服务化原则、Serverless原则、Service Mesh架构原则、DevSecOps原则、声明式API原则和可观测性原则。在云原生领域,华为云贡献首个云原生智能边缘项目KubeEdge和批量计算项目Volcano,开源云原生多云容器编排项目 Karmada
● 软件架构(software architecture):指软件系统的的“基础结构”及创建这些结构的准则和对这些结构的描述,是组成软件系统的一系列相关的抽象模式,用于指导大型软件系统各个方面的设计,是一个系统的草图,描述的对象是直接构成系统的抽象组件。各个组件之间的连接明确细致的描述组件之间的通讯。相对框架对规范的关注,架构关注的是系统的结构;架构是顶层的设计,框架是面向编程/配置的半成品,组件是从逻辑上技术角度基于复用的分离设计(也可看做框架中可复用的某一个实例),模块是从业务逻辑上职责功能的划分,系统是相互协同运行的实体。
架构不是软件,而是关于软件如何设计的重要策略。软件架构决策设计到如何将软件系统分解成不同的部分、各部分之间的静态结构关系和动态交互关系等。经过完整的开发过程之后,这些架构决策将体现在最终开发出的软件系统中;当然,引入软件架构之后,整个开发过程变成了“分两步走”,而架构决策往往会体现在框架之中。而代码不能就等同于是软件架构,软件架构是比具体代码高一个抽象层次的概念。架构势必被代码所体现和遵循,但任何一段具体的代码都代表不了架构。
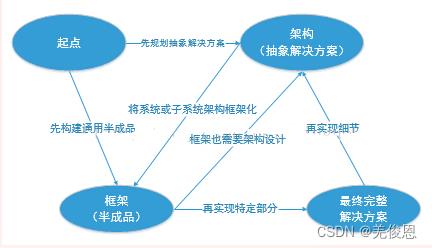
框架和架构的关系可总结为:
(1)为了尽早验证架构设计,或者处于支持产品线开发的目的,可以将关键的通用机制甚至整个架构以框架的方式进行实现;
(2)业界(及公司内部)可能存在大量可供重用的框架,这些框架或者已经实现了软件架构所需的重要架构机制,或者为未来系统的某个子系统提供了可扩展的半成品,所以最终的软件架构可以借助这些框架构造。
更多参看架构和框架的区别,也可参看《统一软件开发过程》.pdf这本书,其中有对架构有很具体的描述。
参看2:一篇文章带你彻底吃透Spring ;
2)mvc和mvvm
mvc是model,view,controller,mvvm是model(数据模型:即后端数据),view,view-model(后端数适配视图化处理的可被前端易用的数据)
3)DOM和虚拟Dom
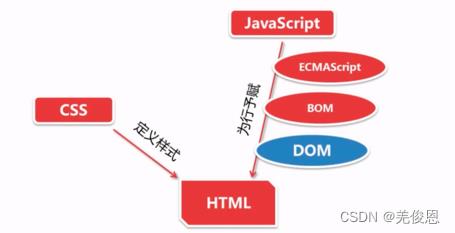
javascript基础分为三个部分:
ECMAScript:JavaScript的语法标准。包括变量、表达式、运算符、函数、if语句、for语句等。
DOM:文档对象模型(Document object Model),操作网页上的元素的API。比如让盒子移动、变色、轮播图等。
BOM:浏览器对象模型(Browser Object Model),操作浏览器部分功能的API。比如让浏览器自动滚动。
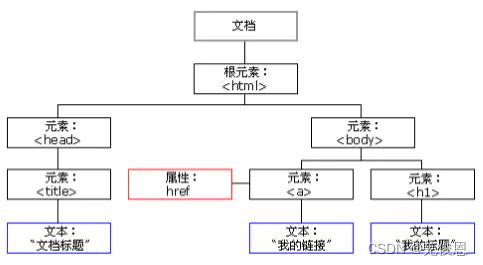
DOM的全称是Document Object Model,即文档对象模型,它允许脚本控制Web页面、窗口和文档。如果没有DOM,JavaScript将是另外一种脚本语言;而有了DOM,它将成为制作动态页面的强有力工具。DOM不是JavaScript语言的一部分,而是内置在浏览器中的一个应用程序接口。当然,我们可以简单的理解为一种用于html和XML文档的编程接口,也可简单理解DOM就是html操作的对象。它给文档提供了一种结构化的表示方法,可以改变文档的内容和呈现方式。DOM实际就是一组用来描述脚本(JavaScript)怎样与结构化文档进行交互和访问的web标准, 定义了访问 HTML 和 XML 文档的标准,其中HTML DOM 是关于如何获取、修改、添加或删除 HTML 元素的标准。目的其实就是为了能让js操作html元素而制定的一个规范。
DOM定义了一系列对象、方法和属性,用于访问、操作和创建文档中的内容、结构、样式以及行为。DOM可把浏览器支持的文档(包括HTML XML XHTML)当作一个对象来解析。DOM实际上是一个操作文档里面所包含的内容的一个编程的API,允许开发人员从文档中读取、搜索、修改、增加和删除数据。DOM是与平台和语言无关的,也就是说只要是支持DOM的平台和编程语言,你都可以用来编写文档。每一个网页元素(一个HTML标签)都对应着一个对象;网页上的标签是一层层嵌套的,最外面的一层是,文档对象模型也这样一层层嵌套着的,类似于树形结构(DOM树)。树根是window或document对象,相当于最外层的标签的外围,也就是整个文档。树根之下是子一级的对象,子对象也有它自己的子对象,除了根对象以外,所有的对象都有自己的父对象,同一对象的子对象之间就是兄弟的关系。一个典型的解析过程:HTML加载完毕,渲染引擎会在内存中的HTML文档,生成一个DOM树,getElementById是获取内中DOM上的元素节点。然后操作的时候修改的是该元素的属性。
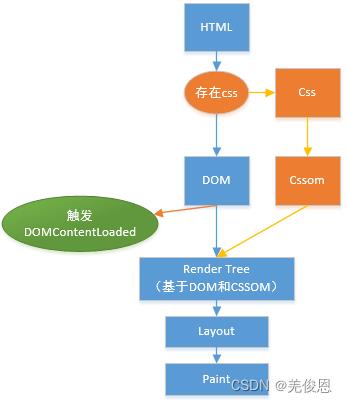
浏览器的渲染机制:
解析HTML标签,构建DOM树
解析cSS标签,构建CSSOM树
把DOM和CSSOM组合成渲染树(render tree)
在渲染树的基础上进行布局,计算每个节点的几何结构
把每个节点绘制到屏幕上(painting)
DOM实际上是以面向对象方式描述的文档模型。DOM定义了表示和修改文档所需的对象、这些对象的行为和属性以及这些对象之间的关系。可以把DOM认为是页面上数据和结构的一个树形表示,不过页面当然可能并不是以这种树的方式具体实现。通过JavaScript,可以重构整个 HTML 文档。可以添加、移除、改变或重排页面上的项目。 要改变页面的某个东西,JavaScript 就需要获得对 HTML 文档中所有元素进行访问的入口。这个入口连同对 HTML 元素进行添加、移动、改变或移除的方法和属性,都是通过文档对象模型来获得的。我们用JavaScript对网页进行的所有操作都是通过DOM进行的;当访问DOM中的对象时,先是父对象名,后面接着是子对象名,使用圆点隔开。
DHTML:动态的HTML技术,是将html + css + dom +javascript 配合使用,来做动态html页面。
HTML—负责提供标签,同时用标签封装数据
CSS—-负责显示样式
dom—-把整个页面中的标签、属性和文字内容封装成对象。
js—–提供程序设计语言,for,while,if
虚拟DOM是在内存中生成与真实DOM对应的数据结构部,这个内存中生成的结构就称之为虚拟DOM,它是最早react提出来的,用于当数据发生变化是,能够只能计算出重新渲染组件的最小代价并应用到DOM操作上,减少直接操作DOM的次数,加快渲染,从而降低资源重复渲染的资源消耗。例如vue中可采用一个简洁的模板进行声明式的调用,将数据渲染进DOM,初始化实例后,Vue就自动将数据绑定在DOM模板上。
更多参看:DOM知识简易梳理;
在kubernetes中部署kubersphere
活动地址:毕业季·进击的技术er
在kubernetes中部署kubersphere
一、检查本地kubernetes环境
[root@k8s-master ~]# kubectl get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master Ready control-plane,master 16h v1.23.1 192.168.3.201 <none> CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 containerd://1.6.6
k8s-node01 Ready <none> 16h v1.23.1 192.168.3.202 <none> CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 containerd://1.6.6
k8s-node02 Ready <none> 16h v1.23.1 192.168.3.203 <none> CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 containerd://1.6.6
二、安装nfs
1.安装nfs包
yum install -y nfs-utils
2.创建共享目录
mkdir -p /nfs/data
3.配置共享目录
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
4.启动相关服务
systemctl enable rpcbind
systemctl enable nfs-server
systemctl start rpcbind
5.使配置生效
exportfs -r
6.查看nfs
[root@k8s-master nfs]# exportfs
/nfs/data <world>
7.两台从节点挂载nfs
①从节点检查nfs
[root@k8s-node01 ~]# showmount -e 192.168.3.201
Export list for 192.168.3.201:
/nfs/data *
②创建挂载目录
mkdir -p /nfs/data
③挂载nfs
mount 192.168.3.201:/nfs/data /nfs/data
④检查nfs挂载情况
[root@k8s-node01 ~]# df -hT |grep nfs
192.168.3.201:/nfs/data nfs4 18G 12G 6.3G 65% /nfs/data
8.showmount命令错误故障处理
service rpcbind stop
service nfs stop
service rpcbind start
service nfs start
三、配置默认存储
1.编辑sc.yaml文件
[root@k8s-master kubersphere]# cat sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "true" ## 删除pv的时候,pv的内容是否要备份
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2
# resources:
# limits:
# cpu: 10m
# requests:
# cpu: 10m
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.3.201 ## 指定自己nfs服务器地址
- name: NFS_PATH
value: /nfs/data ## nfs服务器共享的目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.3.201
path: /nfs/data
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
2.应用sc.yaml
[root@k8s-master kubersphere]# kubectl apply -f sc.yaml
storageclass.storage.k8s.io/nfs-storage created
deployment.apps/nfs-client-provisioner created
serviceaccount/nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
3.查看sc
[root@k8s-master kubersphere]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-storage (default) k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 43s
4.测试安装pv
①编写pv.yaml
[root@k8s-master kubersphere]# cat pv.ymal
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Mi
②运行pv
[root@k8s-master kubersphere]# kubectl apply -f pv.ymal
persistentvolumeclaim/nginx-pvc created
③查看pvc和pv
[root@k8s-master kubersphere]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-92610d7d-9d70-4a57-bddb-7fffab9a5ee4 200Mi RWX Delete Bound default/nginx-pvc nfs-storage 73s
[root@k8s-master kubersphere]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
nginx-pvc Bound pvc-92610d7d-9d70-4a57-bddb-7fffab9a5ee4 200Mi RWX nfs-storage 78s
四、安装metrics-server组件
1.编辑metrics.yaml文件
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
name: metrics-server
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
# 跳过TLS证书验证
- --kubelet-insecure-tls
image: jjzz/metrics-server:v0.4.1
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
periodSeconds: 10
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir:
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
2.应用metrics.ymal文件
[root@k8s-master kubersphere]# kubectl apply -f metrics.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
3.查看安装后pod
[root@k8s-master kubersphere]# kubectl get pod -A |grep metric
kube-system metrics-server-6988f7c646-rt6bz 1/1 Running 0 86s
4.检查安装后效果
[root@k8s-master kubersphere]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master 221m 5% 1360Mi 17%
k8s-node01 72m 1% 767Mi 9%
k8s-node02 66m 1% 778Mi 9%
五、安装KubeSphere
1.下载kubesphere组件
wget https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
wget https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/cluster-configuration.yaml
2.执行安装——最小化安装
[root@k8s-master kubersphere]# kubectl top nodes^C
[root@k8s-master kubersphere]# kubectl apply -f kubesphere-installer.yaml
customresourcedefinition.apiextensions.k8s.io/clusterconfigurations.installer.kubesphere.io created
namespace/kubesphere-system created
serviceaccount/ks-installer created
clusterrole.rbac.authorization.k8s.io/ks-installer created
clusterrolebinding.rbac.authorization.k8s.io/ks-installer created
deployment.apps/ks-installer created
[root@k8s-master kubersphere]# kubectl apply -f cluster-configuration.yaml
clusterconfiguration.installer.kubesphere.io/ks-installer created
3.查看pod
[root@k8s-master kubersphere]# kubectl get pods -A |grep ks
kubesphere-system ks-installer-5cd4648bcb-vxrqf 1/1 Running 0 37s
5.查看安装进度
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath=‘.items[0].metadata.name’) -f
***********************KuberSphere 添加新 Node 节点