SQL中分组短语是啥
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL中分组短语是啥相关的知识,希望对你有一定的参考价值。
SQL中分组短语是:group by。
GROUP BY 语句
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
GROUP BY 语法
SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator valueGROUP BY column_name
Group By 的使用:
1、 Group By [Expressions]:
这个恐怕是Group By语句最常见的用法了,Group By + [分组字段](可以有多个)。在执行了这个操作以后,数据集将根据分组字段的值将一个数据集划分成各个不同的小组。比如有如下数据集,其中水果名称(FruitName)和出产国家(ProductPlace)为联合主键:
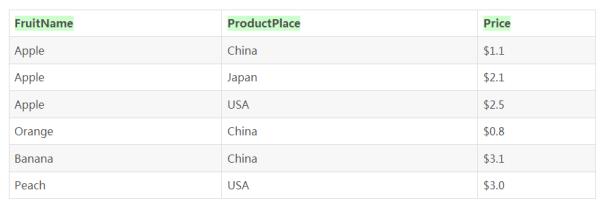
如果我们想知道每个国家有多少种水果,那么我们可以通过如下SQL语句来完成:
SELECT COUNT(*) AS 水果种类, ProductPlace AS 出产国FROM T_TEST_FRUITINFO
GROUP BY ProductPlace
这个SQL语句就是使用了Group By +
分组字段的方式,那么这句SQL语句就可以解释成“我按照出产国家(ProductPlace)将数据集进行分组,然后分别按照各个组来统计各自的记录数量。”很好理解对吧。这里值得注意的是结果集中有两个返回字段,一个是ProductPlace(出产国),
一个是水果种类。如果我们这里水果种类不是用Count(*),而是类似如下写法的话:
那么SQL在执行此语句的时候会报如下的类似错误:
 选择列表中的列 'T_TEST_FRUITINFO.FruitName' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
选择列表中的列 'T_TEST_FRUITINFO.FruitName' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
这就是我们需要注意的一点,如果在返回集字段中,这些字段要么就要包含在Group
By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。我们可以将Group By操作想象成如下的一个过程,首先系统根据SELECT
语句得到一个结果集,如最开始的那个水果、出产国家、单价的一个详细表。然后根据分组字段,将具有相同分组字段的记录归并成了一条记录。这个时候剩下的那些不存在于Group
By语句后面作为分组依据的字段就有可能出现多个值,但是目前一种分组情况只有一条记录,一个数据格是无法放入多个数值的,所以这里就需要通过一定的处理将这些多值的列转化成单值,然后将其放在对应的数据格中,那么完成这个步骤的就是聚合函数。这就是为什么这些函数叫聚合函数(aggregate functions)了。
2、 Group By All [expressions] :
Group By All + 分组字段, 这个和前面提到的Group By
[Expressions]的形式多了一个关键字ALL。这个关键字只有在使用了where语句的,且where条件筛选掉了一些组的情况才可以看出效果。在SQL
Server 2000的联机帮助中,对于Group By All是这样进行描述的:
 如果使用 ALL 关键字,那么查询结果将包括由 GROUP BY 子句产生的所有组,即使某些组没有符合搜索条件的行。没有 ALL 关键字,包含 GROUP BY 子句的 SELECT 语句将不显示没有符合条件的行的组。
如果使用 ALL 关键字,那么查询结果将包括由 GROUP BY 子句产生的所有组,即使某些组没有符合搜索条件的行。没有 ALL 关键字,包含 GROUP BY 子句的 SELECT 语句将不显示没有符合条件的行的组。
其中有这么一句话“如果使用ALL关键字,那么查询结果将包含由Group By子句产生的所有组...没有ALL关键字,那么不显示不符合条件的行组。”这句话听起来好像挺耳熟的,对了,好像和LEFT JOIN 和 RIGHT JOIN 有点像。其实这里是类比LEFT JOIN来进行理解的。还是基于如下这样一个数据集:
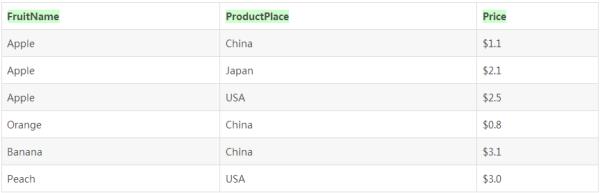
首先我们不使用带ALL关键字的Group By语句:
SELECT COUNT(*) AS 水果种类, ProductPlace AS 出产国
FROM T_TEST_FRUITINFO
WHERE (ProductPlace <> 'Japan')
GROUP BY ProductPlace
那么在最后结果中由于Japan不符合where语句,所以分组结果中将不会出现Japan。
现在我们加入ALL关键字:
SELECT COUNT(*) AS 水果种类, ProductPlace AS 出产国FROM T_TEST_FRUITINFO
WHERE (ProductPlace <> 'Japan')
GROUP BY ALL ProductPlace
重新运行后,我们可以看到Japan的分组,但是对应的“水果种类”不会进行真正的统计,聚合函数会根据返回值的类型用默认值0或者NULL来代替聚合函数的返回值。
3、 GROUP BY [Expressions] WITH CUBE | ROLLUP:
首先需要说明的是Group By All 语句是不能和CUBE 和 ROLLUP 关键字一起使用的。
首先先说说CUBE关键字,以下是SQL Server 2000联机帮助中的说明:
 指定在结果集内不仅包含由 GROUP BY 提供的正常行,还包含汇总行。在结果集内返回每个可能的组和子组组合的 GROUP BY 汇总行。GROUP BY 汇总行在结果中显示为 NULL,但可用来表示所有值。使用 GROUPING 函数确定结果集内的空值是否是 GROUP BY 汇总值。
指定在结果集内不仅包含由 GROUP BY 提供的正常行,还包含汇总行。在结果集内返回每个可能的组和子组组合的 GROUP BY 汇总行。GROUP BY 汇总行在结果中显示为 NULL,但可用来表示所有值。使用 GROUPING 函数确定结果集内的空值是否是 GROUP BY 汇总值。
 结果集内的汇总行数取决于 GROUP BY 子句内包含的列数。GROUP BY 子句中的每个操作数(列)绑定在分组 NULL 下,并且分组适用于所有其它操作数(列)。由于 CUBE 返回每个可能的组和子组组合,因此不论指定分组列时所使用的是什么顺序,行数都相同。
结果集内的汇总行数取决于 GROUP BY 子句内包含的列数。GROUP BY 子句中的每个操作数(列)绑定在分组 NULL 下,并且分组适用于所有其它操作数(列)。由于 CUBE 返回每个可能的组和子组组合,因此不论指定分组列时所使用的是什么顺序,行数都相同。
我们通常的Group By语句是按照其后所跟的所有字段进行分组,而如果加入了CUBE关键字以后,那么系统将根据所有字段进行分组的基础上,还会通过对所有这些分组字段所有可能存在的组合形成的分组条件进行分组计算。由于上面举的例子过于简单,这里就再适合了,现在我们的数据集将换一个场景,一个表中包含人员的基本信息:员工所在的部门编号(C_EMPLINFO_DEPTID)、员工性别(C_EMPLINFO_SEX)、员工姓名(C_EMPLINFO_NAME)等。那么我现在想知道每个部门各个性别的人数,那么我们可以通过如下语句得到:
FROM T_PERSONNEL_EMPLINFO
GROUP BY C_EMPLINFO_DEPTID, C_EMPLINFO_SEX
但是如果我现在希望知道:
1. 所有部门有多少人(这里相当于就不进行分组了,因为这里已经对员工的部门和性别没有做任何限制了,但是这的确也是一种分组条件的组合方式);
2. 每种性别有多人(这里实际上是仅仅根据性别(C_EMPLINFO_SEX)进行分组);
3. 每个部门有多少人(这里仅仅是根据部门(C_EMPLINFO_DEPTID)进行分组);那么我们就可以使用ROLLUP语句了。
SELECT C_EMPLINFO_DEPTID, C_EMPLINFO_SEX, COUNT(*) AS C_EMPLINFO_TOTALSTAFFNUMFROM T_PERSONNEL_EMPLINFO
GROUP BY C_EMPLINFO_DEPTID, C_EMPLINFO_SEX WITH CUBE
那么这里你可以看到结果集中多出了很多行,而且结果集中的某一个字段或者多个字段、甚至全部的字段都为NULL,请仔细看一下你就会发现实际上这些记录就是完成了上面我所列举的所有统计数据的展现。使用过SQL
Server 2005或者RDLC的朋友们一定对于矩阵的小计和分组功能有印象吧,是不是都可以通过这个得到答案。我想RDLC中对于分组和小计的计算就是通过Group By的CUBE和ROLLUP关键字来实现的。(个人意见,未证实)
CUBE关键字还有一个极为相似的兄弟ROLLUP, 同样我们先从这英文入手,ROLL
UP是“向上卷”的意思,如果说CUBE的组合是绝对自由的,那么ROLLUP的组合就需要有点约束了。我们先来看看SQL Server
2000的联机中对ROLLUP关键字的定义:
 指定在结果集内不仅包含由 GROUP BY 提供的正常行,还包含汇总行。按层次结构顺序,从组内的最低级别到最高级别汇总组。组的层次结构取决于指定分组列时所使用的顺序。更改分组列的顺序会影响在结果集内生成的行数。
指定在结果集内不仅包含由 GROUP BY 提供的正常行,还包含汇总行。按层次结构顺序,从组内的最低级别到最高级别汇总组。组的层次结构取决于指定分组列时所使用的顺序。更改分组列的顺序会影响在结果集内生成的行数。
那么这个顺序是什么呢?对了就是Group By 后面字段的顺序,排在靠近Group By的分组字段的级别高,然后是依次递减。如:Group
By Column1, Column2, Column3。那么分组级别从高到低的顺序是:Column1 > Column2 >
Column3。还是看我们前面的例子,SQL语句中我们仅仅将CUBE关键字替换成ROLLUP关键字,如:
FROM T_PERSONNEL_EMPLINFO
GROUP BY C_EMPLINFO_DEPTID, C_EMPLINFO_SEX WITH ROLLUP
和CUBE相比,返回的数据行数减少了不少。仔细看一下,除了正常的Group By语句后,数据中还包含了:
部门员工数;(向上卷了一次,这次先去掉了员工性别的分组限制)
所有部门员工数;(向上又卷了依次,这次去掉了员工所在部门的分组限制)。
在现实的应用中,对于报表的一些统计功能是很有帮助的。
这里还有一个问题需要补充说明一下,如果我们使用ROLLUP或者CUBE关键字,那么将产生一些小计的行,这些行中被剔除在分组因素之外的字段将会被设置为NULL,那么还存在一种情况,比如在作为分组依据的列表中存在可空的行,那么NULL也会被作为一个分组表示出来,所以这里我们就不能仅仅通过NULL来判断是不是小计记录了。下面的例子展示了这里说得到的情况。还是我们前面提到的水果例子,现在我们在每种商品后面增加一个“折扣列”(Discount),用于显示对应商品的折扣,这个数值是可空的,也就是可以通过NULL来表示没有对应的折扣信息。数据集如下所示:
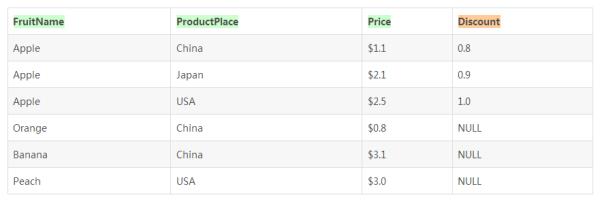
现在我们要统计“各种折扣对应有多少种商品,并总计商品的总数。”,那么我们可以通过如下的SQL语句来完成:
SELECT COUNT(*) AS ProductCount, DiscountFROM T_TEST_FRUITINFO
GROUP BY Discount WITH ROLLUP
好了,运行一下,你会发现数据都正常出来了,按照如上的数据集,结果如下所示:
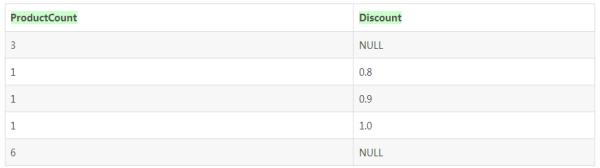
好了,各种折扣的商品数量都出来了,但是在显示“没有折扣商品”和“商品小计”的时候判断上确存在问题,因为存在两条Discount为Null的记录。是哪一条呢?通过分析数据我们知道第一条数据(3,
Null)应该对应没有折扣商品的数量,而(6,Null)应该对应所有商品的数量。需要判断这两个具有不同意义的Null就需要引入一个聚合函数Grouping。现在我们把语句修改一下,在返回值中使用Grouping函数增加一列返回值,SQL语句如下:
FROM T_TEST_FRUITINFOGROUP BY Discount WITH ROLLUP
这个时候,我们再看看运行的结果:
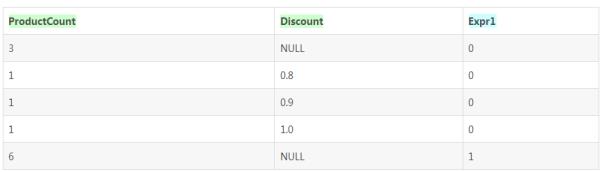
对于根据指定字段Grouping中包含的字段进行小计的记录,这里会标记为1,我们就可以通过这个标记值将小计记录从判断那些由于ROLLUP或者CUBE关键字产生的行。Grouping(column_name)可以带一个参数,Grouping就会去判断对应的字段值的NULL是否是由ROLLUP或者CUBE产生的特殊NULL值,如果是那么就在由Grouping聚合函数产生的新列中将值设置为1。注意Grouping只会检查Column_name对应的NULL来决定是否将值设置为1,而不是完全由此列是否是由ROLLUP或者CUBE关键字自动添加。
总结:Group By 和 Having, Where ,Order by语句的执行顺序:
最后要说明一下的Group By, Having, Where, Order by几个语句的执行顺序。一个SQL语句往往会产生多个临时视图,那么这些关键字的执行顺序就非常重要了,因为你必须了解这个关键字是在对应视图形成前的字段进行操作还是对形成的临时视图进行操作,这个问题在使用了别名的视图尤其重要。以上列举的关键字是按照如下顺序进行执行的:Where,
Group By, Having, Order
by。首先where将最原始记录中不满足条件的记录删除(所以应该在where语句中尽量的将不符合条件的记录筛选掉,这样可以减少分组的次数),然后通过Group
By关键字后面指定的分组条件将筛选得到的视图进行分组,接着系统根据Having关键字后面指定的筛选条件,将分组视图后不满足条件的记录筛选掉,然后按照Order
By语句对视图进行排序,这样最终的结果就产生了。在这四个关键字中,只有在Order By语句中才可以使用最终视图的列名,如:
SELECT FruitName, ProductPlace, Price, ID AS IDE, Discount
FROM T_TEST_FRUITINFO
WHERE (ProductPlace = N'china') ORDER BY IDE
这里只有在ORDER BY语句中才可以使用IDE,其他条件语句中如果需要引用列名则只能使用ID,而不能使用IDE。
以上就是Group By的相关使用说明。内容参考与网站CSDN中的“SQL语句Group By 语句小结“。
参考技术A推荐使用GROUP BY进行分组查询.
Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”。
它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理。
注意:group by 是先排序后分组;
举例说明如下:
select sex ,count(*) as 人数 from student group by sex
--注意点:为了保证完整性,系统约定俗成,在使用了聚合函数的查询语句中,除了聚合函数,可以在查询列表上,要出现其他字段,那么该字段就必须为分组字段,而且该字段一定要跟随在GROUP BY关键字后面。
--group by all
--如果使用 ALL 关键字,那么查询结果将包括由 GROUP BY 子句产生的所有组,即使某些组没有符合搜索条件的行。
--没有 ALL 关键字,包含 GROUP BY 子句的 SELECT 语句将不显示没有符合条件的行的组。
select DepartmentID,DepartmentName as '部门名称',
COUNT(*) as '个数' from BasicDepartment group by all DepartmentID,DepartmentName 参考技术B 分组:group by 参考技术C 关键字 group by 参考技术D group by
select ColumnName , count(*)
from TableName
group by ColumnName
在SQL中分组查询 Group by 的存在条件是啥
在select 语句中 Group by的存在条件是什么 为什么数据库总是报这样的错误:消息 8120,级别 16,状态 1,第 1 行选择列表中的列 'userinfo.UserName' 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。 请说的详细点,最好举个例子..谢谢
Group By子句Group By子句可以将表的行划分为不同的组。分别总结每个组,这样就可以控制想要看见的详细信息的级别。
语法:
[ Group By [ ALL ] Group_By_expression[ ,...n ]
[ WITH ] ]
参数说明:
ALL:包含所有组和结果集,甚至包含那些任何行都不满足WHERE子句指定的搜索条件的组和结果集。如果指定了ALL,将对组中不满足搜索条件的汇总列返回空值。不能用CUBE或ROLLUP运算符指定ALL。如果访问远程表的查询中有WHERE子句,则不支持Group By ALL操作。
Group_By_expression:对其执行分组的表达式。Group_By_expression也称为分组列。Group_By_expression可以是列或引用列的非聚合表达式。在选择列表内定义的列的别名不能用于指定分组列。对于不包含CUBE或ROLLUP的Group By子句,Group_By_ expression的项数受查询所涉及的Group By列的大小、聚合列和聚合值的限制。该限制从8060字节的限制开始,对保存中间查询结果所需的中间级工作表有8060字节的限制。如果指定了CUBE或ROLLUP,则最多只能有10个分组表达式。
CUBE:指定在结果集内不仅包含由Group By提供的正常行,还包含汇总行。在结果集内返回每个可能的组和子组组合的Group By汇总行。Group By汇总行在结果中显示为NULL,但可用来表示所有值。使用GroupING函数确定结果集内的空值是否是Group By汇总值。结果集内的汇总行数取决于Group By子句内包含的列数。Group By子句中的每个操作数(列)绑定在分组NULL下,并且分组适用于所有其他操作数(列)。由于CUBE返回每个可能的组和子组组合,因此,不论指定分组列所使用的是什么顺序,行数都相同。
ROLLUP:指定在结果集内不仅包含由Group By提供的正常行,还包含汇总行。按层次结构顺序,从组内的最低级别到最高级别汇总组。组的层次结构取决于指定分组列时所使用的顺序。更改分组列的顺序会影响在结果集内生成的行数。
使用Group By子句的注意事项。
(1)在SELECT子句的字段列表中,除了聚集函数外,其他所出现的字段一定要在Group By子句中有定义才行。例如“Group By A,B”,那么“SELECT SUM(A),C”就有问题,因为C不在Group By中,但是SUM(A)是可以的。
(2)SELECT子句的字段列表中不一定要有聚集函数,但至少要用到Group By子句列表中的一个项目。例如“Group By A,B,C”,则“SELECT A”是可以的。
(3)在SQL Server中text、ntext和image数据类型的字段不能作为Group By子句的分组依据。
(4)Group By子句不能使用字段别名。
1.按单列进行分组
Group By子句可以基于指定某一列的值将数据集合划分为多个分组,同一组内所有记录在分组属性上具有相同值。
示例:
把“student”表按照“性别”这个单列进行分组。在查询分析器中输入的SQL语句如下:
use student
select 性别
from student
Group By 性别
但仍然要强调SELECT子句必须与Group By后的子句或者是分组函数列相一致。
例如,由于下列查询中“姓名”列既不包含在Group By子句中,也不包含在分组函数中,所以是错误的。错误的SQL语句如下:
use student select 姓名,性别 from student Group By 性别
例如,在“grade”表中,按“学期”分组查询。SQL语句如下:
use studnet select 学期 from grade Group By 学期
2.按多列进行分组
Group By子句可以基于指定多列的值将数据集合划分为多个分组。
示例:
在“student”表中,按照“性别”和“年龄”列进行分组。在查询分析中输入的SQL语句如下:
use student
select 性别,年龄
from student
Group By 性别,年龄
在“student”表中,首先按照“性别”分组,然后再按照“年龄”分组。
再举一个例子,例如,在“grade”表中,按照“学号”和“课程代号”列进行分组。SQL语句如下:
use student
select 学号,课程代号 from grade Group By 学号,课程代号
按多列进行分组时有NULL组的是如何处理的。当表按多列进行分组时有NULL组,这时NULL被作为一个特定值处理,就像其他任何值一样。也就是说,如果在某个分组列中存在两个NULL,则按它们有相同的值那样处理,并将它们放在相同的组中。
示例:
在“grade”表中,按“学期”和“课程代号”列进行分组。在查询分析器中输入的SQL语句如下:
use student
select 学期,课程代号
from grade
Group By 学期,课程代号
3.与聚集函数一起使用
Group By子句是经常与聚集函数一起使用。如果SELECT子句中包含聚集函数,则计算每组的汇总值,当用户指定Group By时,选择列表中任一非聚集表达式内的所有列都应包含在Group By列表中,或者Group By表达式必须与选择列表表达式完全匹配。
示例:
在“student”表中,分别求男女生的平均年龄。在查询分析器中输入的SQL语句如下:
use student
select 性别,avg(年龄) as 平均年龄
from student
Group By 性别
例如,在“student”表中,分别求有多少个男生和女生。SQL语句如下:
use student
select 性别,count(性别) as 人数 from student Group By 性别
说明:关于聚合函数的详细讲解可参阅9.2.1节。
4.与HAVING子句一起使用
HAVING子句对Group By子句选择出来的结果进行再次筛选,最后输出符合HAVING子句中条件的记录。HAVING子句的语法与WHERE子句的语法相类似,惟一不同的是HAVING子句中可以包含聚合函数。
语法:
[HAVING <search_condition>]
参数说明:
<search_condition>:指定组或聚合应满足的搜索条件。当HAVING与Group By ALL一起使用时,HAVING 子句替代ALL。
示例:
在“student”表中,按“性别”分组求平均年龄,并且查询其平均年龄大于21的学生信息。在查询分析器中输入的SQL语句如下:
use student
select avg(年龄), 性别
from student
Group By 性别
having avg(年龄)>21
在“grade”表中,按“学期”分组求平均成绩,并且查询“平均成绩”大于93的课程信息。在查询分析器中输入的SQL语句如下:
use student
select 学期,avg(课程成绩) as 平均成绩
from grade
Group By 学期
having avg(课程成绩)>93
说明:HAVING查询条件是在进行分组操作之后才应用的;在HAVING子句中不能使用text、image和ntext 数据类型。
5.对统计结果进行排序
统计结果并不能保证结果集内记录按一定顺序排列,如果使用ORDER By子句,就可以使结果集中的结果按一定的顺序(升序、降序)排序。
示例:
在“student”表中,按“性别”和“年龄”列分组,并按“年龄”列降序排序。在查询分析器中输入的SQL语句如下:
use student
select 性别,年龄
from student
Group By 性别,年龄
order By 年龄 desc
例如,在“grade”表中,按“学号”分组,并按课程的“平均成绩”升序排序。SQL语句如下:
use student
select 学号,avg(课程成绩) as 平均成绩 from grade Group By 学号 order By 平均成绩
参考技术A 分组查询中:select后的字段必须是group by中包含的字段如下:
select userinfo.班级,count(userinfo.sex) from userinfo group by 班级,userinfo.sex;
语句的含义为:按照班级分组,统计每个班级的男、女总数本回答被提问者采纳 参考技术B 用group by时,当前查询语句中的select,只能包含分类的项和其他分类进行的聚合操作。
如果一个表里有,id,classid,money
数据有 1,101,34
2,101,23
1,102,39
应该用select classid ,sum(money) from table1 group by classid这样的。。如果在select 中加入id,那么一个101的classid对应2条数据,而求和后101应该只有一条数据,这本身就是个矛盾。 参考技术C 抱你sql语句贴出来看看分析下ok
以上是关于SQL中分组短语是啥的主要内容,如果未能解决你的问题,请参考以下文章