函数与闭包
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了函数与闭包相关的知识,希望对你有一定的参考价值。
当程序的代码量增大时,就需要对各功能模块进行分割,这些分割的小模块就是本文中接下来会进行分析的函数。接下来的部分会讲解包括函数嵌套,函数字面量,以及函数值等概念。
一、方法
一会函数一会方法的,是不是有点晕?严格来说,任何方法都是一个函数,只不过我们称呼那些写在类定义中的某个对象拥有的函数成员为方法。例如下面代码中的LongLines对象就定义了两个方法,可以用于打开指定文件名的文件并读取其中的内容,并且将其中一行的长度超过给定值的内容打印出来。
object LongLines
// 接收两个参数,一个文件名,一个长度
def processFile (filename: String , witdh: Int): Unit =
val source = Source.fromFile(filename)
for (line <- source.getLines())
processLine(filename , witdh, line)
private def processLine (filename: String , width: Int, line: String): Unit =
if (line.length > width)
println(filename + ": " + line.trim)
需要将上面这两个方法运行起来的话,再定义一个FindLongLines对象,代码如下
object FindLongLines
def main(args: Array[String])
val width = args(0).toInt
for (arg <- args.drop(1))
LongLines.processFile(arg, width)
在前面的博客中提到过,一个对象的main方法是程序运行的起点。这里将传入的文件名和长度参数传入LongLines.processFile方法。运行参数代码如下:
scala FindLongLines 45 LongLines.scala二、函数嵌套
在Scala中,可以在一个方法中定义其他的方法,比如下面的代码:
def processFile (filename: String, witdh: Int): Unit =
def processLine (filename: String , width: Int, line: String): Unit =
if (line.length > width)
println(filename + ": " + line.trim)
val source = Source.fromFile(filename)
for (line <- source.getLines())
processLine(filename, witdh , line)
那么此时processLine方法只能在processFile方法中被调用。
由于嵌套的子函数可以直接访问外层父函数的参数,所以上面的代码可以进行一些调整,proceddLine方法不再需要接受文件名和长度这两个参数了,可以直接从外层函数参数中获取。
def processFile(filename: String, width: Int)
def processLine(line: String)
if (line.length > width)
println(filename +": "+ line)
val source = Source.fromFile(filename)
for (line <- source.getLines())
processLine(line)
三、头等函数
在Scala中有一个头等函数的概念(first-class functions)。
在Scala中不仅可以定义一个函数,然后调用这个函数,也可以将函数写成一个匿名的表达式,然后赋值给一个变量,这个就称为函数字面量。函数字面量在编译时会转化成一个FunctionN类型的类,并且该类的apply方法的作用就是该匿名函数的功能。
1、函数字面量和函数变量
比如下面代码中定义了两个函数字面量,并分别赋值给变量f1和f2
object FunctionLiteral
val f1 = (x: Int) => x + 1
val f2 = (a: Int, b: Int, c: Int) => a + b + c
经过scalac命令编译后,查看反编译的代码,对应于f1,有一个如下类,并且其apply方法最终执行了x + 1的逻辑,
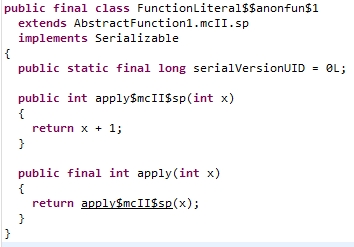
对应于f2,也有一个对应的类,这里的apply方法接收三个Int型参数,并计算三个传入参数的和。
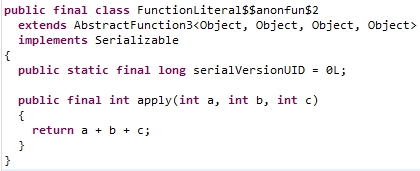
那么,函数字面量分别赋值给变量f1和f2的话,f1和f2就分别对应于上面两个类的具体实现对象了,反编译后的源代码如下所示
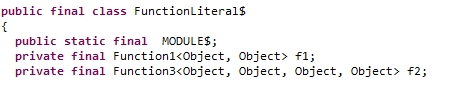
区分一下函数字面量和函数变量的区别。
上面提到,(x: Int) => x + 1就是一个函数字面量,反编译后对应一个类。而如果将其赋值给某个变量,比如f1 = (x: Int) => x + 1,那么可以称f1位一个函数变量,该函数变量对应于Scala编译器运行时生成的一个FunctionN类型的对象。所以,可以将函数字面量直接赋值给一个变量。
四、函数字面量的简化
对于上面定义的函数字面量,还可以按本节中的一些内容做进一步的简化。
当把函数字面量当参数时,在这种情况下,Scala编译器可以根据someNumbers中的元素类型,推断出下面代码中x的类型,所以在这种情况下,可以把x的类型省略不写
val someNumbers = List(-11, -10, -5, 0, 5, 10)
someNumbers.filter((x) => x > 0) 另外,对于上面这一行代码,如果x的类型可以由调用者推断出,那么可以进一步省略其参数外的圆括号,如下
someNumbers.filter(x => x > 0)五、占位符
这一部分将进一步对函数字面量进行简化。这里会使用到下划线_,可以把下划线理解为一个空格。那么对于下面这一行进一步简化的代码,_处将依次填入someNumbers中的元素,然后进行判断。
someNumbers.filter(_ > 0) 那么,_应该在什么时候使用?如果需要实现一个求和的函数,下面这样写会有什么现象发生?
val f = _ + _ 运行时会报错,编译器会提示无法确定这两个_的类型。

那么,手动给这两个_指定类型,就正常了,
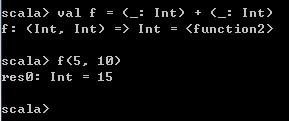
这里需要注意的是,_ + _这个表达式会解析成一个传入两个参数的Function2类型的类,那么f就对应该类的一个对象。在函数表达式中的_,每一个都代表该函数的一个输入参数,有多少个_就表示该函数需要输入多少个参数,并且,第一个_对应函数调用时传入的第一个参数,第二个_对应函数调用时传入的第二个参数,依此类推。
六、部分应用函数
第五节中使用下划线_替代每一个输入参数,其实也可以用一个下划线_来代替某个函数的所有输入参数。注意理解这一句话,这是区分部分应用函数的关键。
举个例子
someNumbers.foreach(println _)上面这行代码其实是下面这个的简写
someNumbers.foreach(x => println(x)) 其中的_代表的不是一个参数,而是一个代表所有参数的列表。那么你就要问了,_在这里明明代表的就是一个参数啊,只能说在这里_恰巧只代表了一个参数。因为someNumber中的每个元素刚好只有一个对应的Int值。
接下来举一个三个参数的例子你就明白了。
def sum(a: Int, b: Int, c: Int) = a + b + c 使用sum函数的结果如下

此时,再用一个_来代表sum方法需要的三个参数,并将其赋值给一个变量
val a = sum _ 可以看到,在这里变量a已经是一个Function3类型的对象了,并且可以调用a并传入三个参数。
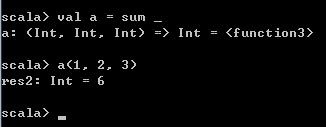
到这里,已经可以引申出部分应用函数的含义了。对一个函数,如果调用时不传入它需要的所有参数,由此得到的一个表达式就是一个部分应用函数。
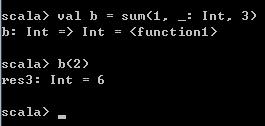
上面这个示例中一个参数都没有指定,其实也可以指定1个或两个参数,下面这段代码中,传入sum方法的第一个和最后一个参数。注意这里由于不是某个对象调用sum方法,Scala编译器无法解析出中间那个_的类型,所以需要手动指定。
val b = sum(1, _: Int, 3) 执行后,Scala编译器会生成一个Function1类型的对象,并赋值给变量b,表示b是一个函数参数。
当在函数名后用一个_替代所有参数时,甚至可以把这个_省略掉,进一步简化代码,如someNumbers.foreach(println)种形式只能用在需要传入一个函数当做参数的方法调用中。如果不是这种情况,比如下面这样,
val c = sum是会报错的

正确的用法如下

七、闭包
到这里,已经将函数字面量解释清楚了。有没有注意到,上面列举的所有函数的函数体中使用到的所有变量都是由调用函数时传入的参数决定的。如果在函数体中使用到一个非参数的变量,并且该变量由函数体外部来决定,这个概念就是闭包了。比如下面代码中的函数对象addMore就是被称为闭包。
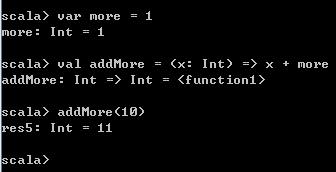
var more = 1
val addMore = (x: Int) => x + more
addMore(10) 这个例子的函数体中有一个未知参数more,并且该参数不是由函数参数决定的,在这里more是一个自由变量。从代码运行的结果可以看到,addMore是一个Function1类型的对象。并且调用该函数变量时,根据传入参数和前面定义的more的值,得到了最终结果。
将上面代码代码写入一个名为Closure的object中然后编译,addMore是Closure类的一个Function1类型的对象,more是Closure类的一个int类型的属性,并且more的值为1,addMore对应类的apply方法,将传入参数和more的值求和。
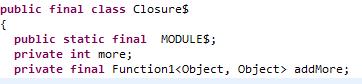
more的值
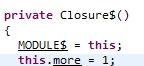
addMore函数变量的apply方法
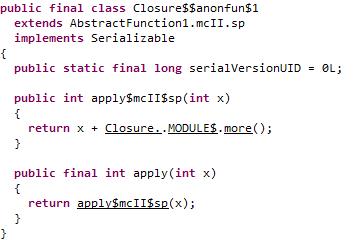
在闭包中,代码直接获取闭包变量的值,从上面的代码也可以看出,在运行时会根据闭包变量的值生成对应的函数变量。可以使用如下方式传入不同的闭包值
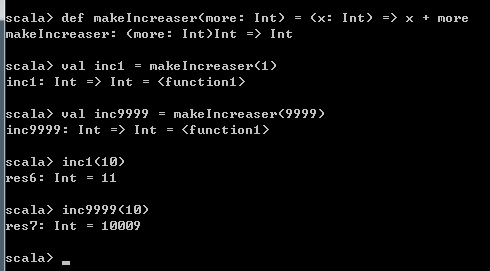
def makeIncreaser(more: Int) = (x: Int) => x + more
val inc1 = makeIncreaser(1)
val inc9999 = makeIncreaser(9999)
inc1(10)
inc9999(10)结果如下:
八、特殊的函数调用方式
前面举的例子中,基本上每一个函数最终参数的个数都是确定的。函数定义时规定了几个参数,在函数调用时也必须传入对应多的参数,并且需要一一对应才能正确的执行。
1、重复参数
在参数类型后面增加一个"*",表示该函数可以接收多个参数,比如下面的echo方法,就可以接收0个或多个输入的String类型参数
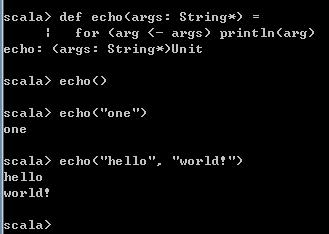
def echo(args: String*) =
for (arg <- args) println(arg)
echo()
echo("one")
echo("hello", "world!")运行结果如下
实际上,上面这段代码中的args参数,是一个String类型的数组,即Array[String]。但是如果直接给该函数传入一个String数组参数,会报错,需要特殊处理一下,如下所示
val arr = Array("What's", "up", "doc?")
echo(arr)
echo(arr: _*)结果如下:
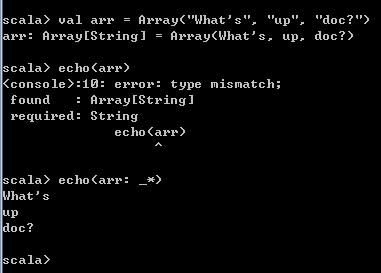
_*在运行时会通知Scala编译器,将arr数组中的每一个元素传入该函数,而不是将整个arr对象当作一个参数传入。从上图中也能看到,echo方法接收的是String类型参数,但是传入的是一个Array[String]类型
2、带参数名的参数
一般来说,调用函数时传入的参数,会与函数定义时的参数顺序一一对应。但是在这里也可以不按照顺序,而按照参数名进行匹配。比如下面这段代码
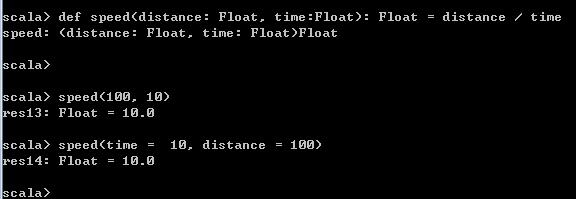
def speed(distance: Float, time:Float): Float = distance / time
speed(100, 10)
speed(time = 10, distance = 100)结果如下,当指定参数名时,就会优先根据参数名去匹配函数参数
3、参数默认值
有时候希望调用函数时,给某些参数一个默认值,这里可以结合上一节一起使用,比如
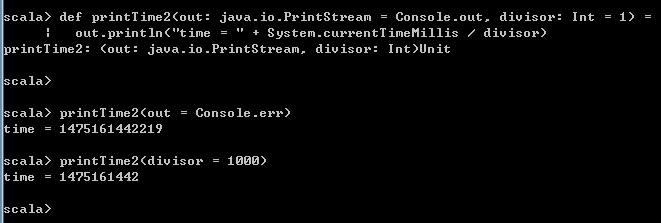
def printTime2(out: java.io.PrintStream = Console.out, divisor: Int = 1) =
out.println("time = " + System.currentTimeMillis / divisor)
printTime2(out = Console.err)
printTime2(divisor = 1000)运行结果如下
九、尾递归
以一个示例开始分析递归。下面的代码中显示的方法用于对传入参数作调整,直到该参数调整至最优值。
def approximate(guess: Double): Double =
if (isGoodEnough(guess)) guess
else approximate(improve(guess)) 首先判断传入参数是否足够好,如果已经达到足够好的条件,approximate方法就返回该参数,否则调用improve方法调整一下该参数,然后递归调用approximate方法。
如果将上面的递归写成while循环,则如下面代码所示,其中的guess变量是var类型的。
def approximateLoop(initialGuess: Double): Double =
var guess = initialGuess
while (!isGoodEnough(guess))
guess = improve(guess)
guess
对比上面两种形式,按照函数式编程风格来说,应该优先选第一种。不过,印象中我们知道递归的代码一般会比循环的代码执行效率低,因为递归代码在每一次递归处都要在栈中保留一些信息。在Scala中,其实这两种写法的执行效率是差不多的。这是由于Scala编译器在处理这种尾递归的代码时会做一个优化操作。
那么,什么是尾递归?在第一段代码中,递归调用approximate方法发生在该方法体中最后一行,这种在方法中最后一个动作是递归调用该方法自身的递归称为尾递归。Scala编译器遇到尾递归时,和while循环类似,直接跳转到函数的开头。所以,在Scala中遇到上面这两种情况都可以表示的代码时,应该首选尾递归的形式。
1、尾递归函数的执行过程
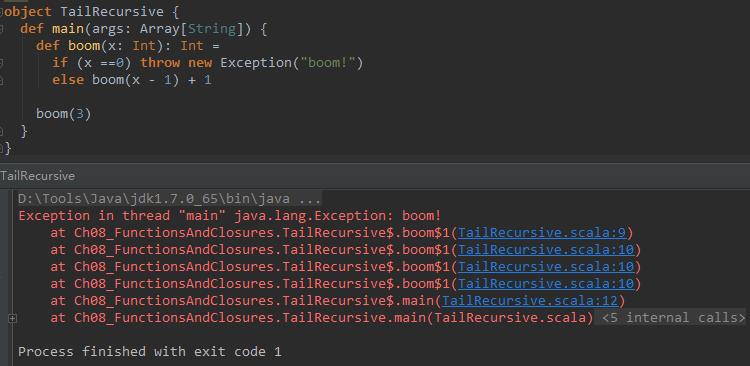
前面分析过,尾递归函数执行时不会在每一次跳转时新建一个栈帧用来保存递归调用处的信息,尾递归函数的所有过程都是在一个栈帧中执行的。例如下面这段代码所示,下面这段代码的函数体中最后一个执行操作并不是递归调用函数本身,所以不是一个尾递归。
def bom(x: Int): Int =
if (x == 0) throw new Exception("boom!")
else boom(x - 1) + 1
boom(3) 看一下执行结果,
再看一个尾递归函数的执行过程
def bang(x: Int): Int =
if (x == 0) throw new Exception("bang!")
else bang(x - 1) 执行结果如下:
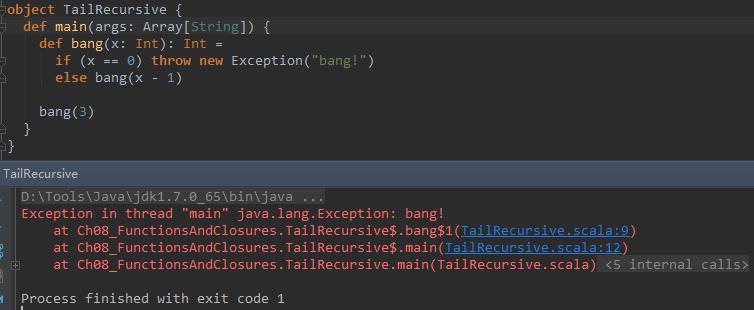
对比上面两个执行结果,可以看到非尾递归的情况下,函数调用经过了三个栈帧,而尾递归时仅有一个栈帧。
2、尾递归的注意点
在Scala中,尾递归发生的两个条件是:
(1)在递归函数的函数体中最后一处代码是递归调用
(2)递归调用的该函数本身
比如下面这种情况,定义两个函数互相调用,这种情况下就不是尾递归。
def isEven(x: Int): Boolean =
if (x == 0) true else isOdd(x - 1)
def isOdd(x: Int): Boolean =
if (x == 0) false else isEven(x - 1)并且,下面这种情况中,将部分应用函数当做一个函数值赋值给一个函数变量,然后在函数体中调用该函数变量,这种情况也不是尾递归。
val funValue = nestedFun _
def nestedFun(x: Int)
if (x != 0) println(x); funValue(x - 1)
以上是关于函数与闭包的主要内容,如果未能解决你的问题,请参考以下文章