Scala中的集合类型
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala中的集合类型相关的知识,希望对你有一定的参考价值。
本章主要介绍Scala中的集合类型,主要包括:Array, ListBuffer, Arraybuffer, Set, Map和Tuple。
一、序列
序列类型的对象中包含多个按顺序排列好的元素,可以访问其中特定位置的元素。序列类型主要包括List,Array, ListBuffer, ArrayBuffer 。
1、List
List在前一章已经介绍过,略。
2、Array
数组在很多编程语言中都会用到。下面代码中包括了如何定义一个Array类型变量,如何在定义Array变量时赋初始值,以及如何访问和更新特定位置的元素。
val fiveInts = new Array[Int](5) // 生成一个长度为5的数组
val fiveToOne = Array(5, 4, 3, 2, 1) // 生成一个长度为5的数组并初始化
fiveInts(0) = fiveToOne(4) // 访问指定位置上的元素并赋值
fiveInts 运行结果如下,
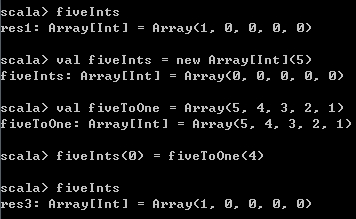
Scala中的数组和Java中的数组是相同的。
3、ListBuffer
ListBuffer类型的完整路径名为scala.collection.mutable.ListBuffer。
在ListBuffer对象的前面和后面增加新元素都非常的方便,使用+=方法在该对象后新增元素,使用+=:在该对象前新增元素。当元素添加完毕后,调
用toList方法将ListBuffer对象转化成List,使得构建List对象更加高效。
import scala.collection.mutable.ListBuffer
val buf = new ListBuffer[Int]
buf += 1
buf += 2
buf
3 +=: buf
buf.toList 结果如下,
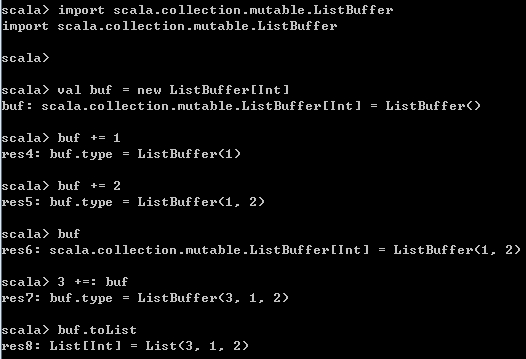
4、ArrayBuffer
ArrayBuffer的完整路径是scala.collection.mutable.ArrayBuffer。ArrayBuffer和Array类似,支持所有Array上的操作。
使用ArrayBuffer的好处是,定义时可以不指定长度。并且在ArrayBuffer的头部和尾部添加或移除元素更加便捷。
import scala.collection.mutable.ArrayBuffer
val buf = new ArrayBuffer[Int]()
buf += 12
buf += 15
buf
buf.length
buf(0) 运行结果如下,
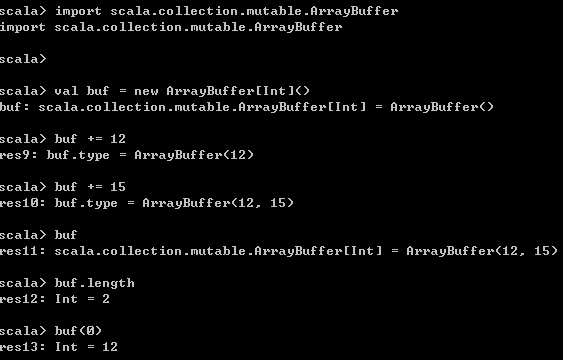
5、String
String对象本质上是字符序列。可以直接在String对象上进行遍历,遍历的内容就是该对象的每一个字符元素。
val a = "abcdefg"
a.foreach(println)
def hasUpperCase(s: String) = s.exists(_.isUpper)
hasUpperCase("Robert Frost")
hasUpperCase("e e cummings") 运行结果如下,

二、Set和Map
Scala中同时提供了mutable和immutable类型的Set和Map类型。有关Set和Map类型的类继承关系,如下图所示,
Map类继承关系:
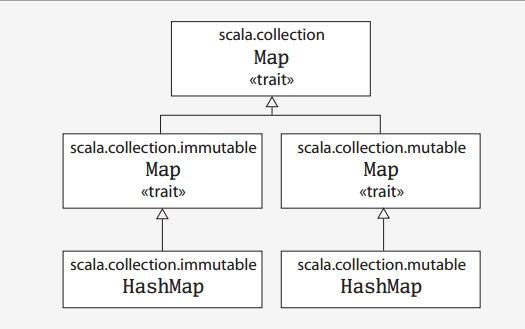
Set类继承关系:
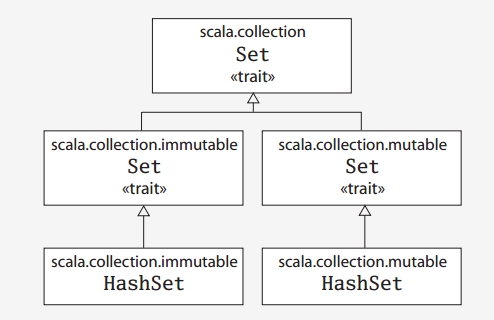
从上面两图可以看到,分别有三个Map和Set命名的trait,只不过这三个trait位于不同的package中。直接使用Map或者Set,在默认情况下,使用的是imutable这个。如果想要实现mutable类型的Set或Map需要显式的import。
下面分别介绍Set和Map类型。
1、Set
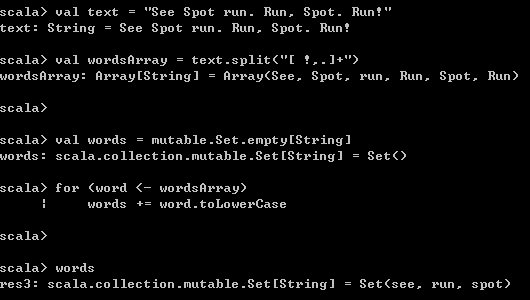
Set对象中不会包含重复元素。下面将一个String类型变量切割成单词,然后生成一个Set对象。
val text = "See Spot run. Run, Spot. Run!"
val wordsArray = text.split("[ !,.]+")
val words = mutable.Set.empty[String]
for (word <- wordsArray)
words += word.toLowerCase
words 运行结果如下,最终的Set对象中只包含了三个不重复的元素。
Set对象上的常用操作列表如下,注意区分哪些是mutable类型的Set,哪些是imutable类型的Set。
| 操作符 | 作用及结果 |
|---|---|
val nums = Set(1, 2, 3) | 生成一个新的Set对象,并初始化 |
nums + 5 | 新增一个元素,得到一个新的Set对象,结果为Set(1, 2, 3, 5) |
nums - 3 | 删除Set中的一个元素,结果为Set(1, 2, 5) |
nums ++ List(5, 6) | 将List中的元素全部增加到Set中,结果为Set(1, 2, 3, 5, 6) |
nums -- List(1, 2) | 去除Set中的包含在List中的元素,结果为Set(3) |
nums $ Set(1, 3, 5, 7) | 返回两个Set对象中共有的元素,结果为Set(1, 3) |
nums.size | 获取当前Set中的元素个数,结果为3 |
nums.contains(3) | 判断nums中是否包含指定元素,结果为true |
import scala.collection.mutable | 引入mutable类型的Set对象 |
val words = mutable.Set.empty[String] | 生成一个空的mutable.Set对象 |
words += "the" | 往words中增加元素,words的内容随之发生变化,结果为Set(the) |
words -= "the" | 从words中移除元素,此时words为空,结果为Set() |
words ++= List("do", "re", "mi") | 将List中的元素全部添加到words中,结果为Set(do, re, mi) |
words --= List("do", "re") | 将List中包含的元素从words中移除,结果为Set(mi) |
words.clear | 清空words,移除全部元素,结果为Set() |
2、Map
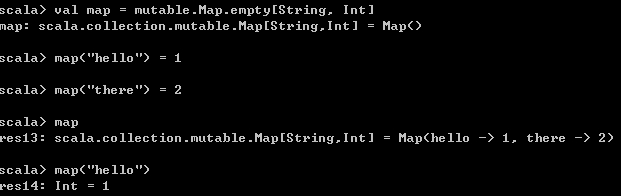
直接看示例,展示了如何新建Map对象,如何往Map对象中添加键值对,以及如何从Map对象中获取指定key的value值。
val map = mutable.Map.empty[String, Int]
map("hello") = 1
map("there") = 2
map
map("hello") 运行结果为,
Map上的常见操作如下,注意区分哪些是mutable类型的Map对象,哪些是imutable类型的Map对象。
| 操作符 | 作用及结果 |
|---|---|
val nums = Map("i" -> 1, "ii" -> 2) | 生成一个新的Map对象,并初始化 |
nums + ("vi" -> 6) | 新增一个元素,得到一个新的Map对象,结果为Map(i -> 1, ii -> 2, vi -> 6) |
nums - "ii" | 删除Map中的一个元素,结果为Map(i -> 1) |
nums ++ List("iii" -> 3, "v" -> 5) | 将List中的元素全部增加到Map中,结果为Map(i -> 1, ii -> 2, iii -> 3, v -> 5) |
nums -- List("i", "ii") | 去除Map中的key为包含在List中的元素,结果为Map() |
nums.size | 获取当前Map中的键值对个数,结果为2 |
nums.contains("ii") | 判断nums中是否包含指定key为ii的键值对,结果为true |
nums("ii") | 获取指定key的value值,结果为2 |
nums.keys | 获取当前nums对象中所有的key值 |
nums.keySet | 获取当前nums对象中所有的key值 ,以Set形式返回。结果为Set(i, ii) |
nums.values | 获取当前nums对象中所有的value值 |
nums.isEmpty | 判断nums是否为空,结果为false |
import scala.collection.mutable | 引入mutable类型的Map对象 |
val words = mutable.Map.empty[String, Int] | 生成一个空的mutable.Map对象 |
words += ("one" -> 1) | 往words中增加元素,words的内容随之发生变化,结果为Map(one -> 1) |
words -= "one" | 从words中移除元素,此时words为空,结果为Map() |
words ++= List("one" -> 1, "two" -> 2, "three" -> 3) | 将List中的键值对全部添加到words中,结果为Map(one -> 1, two -> 2, three -> 3) |
words --= List("one", "two") | 将List中包含的key从words中移除,结果为Map(three -> 3) |
3、TreeMap和TreeSet的其他子类
Map和Set还有其他形式的子类,比如TreeSet,TreeMap。
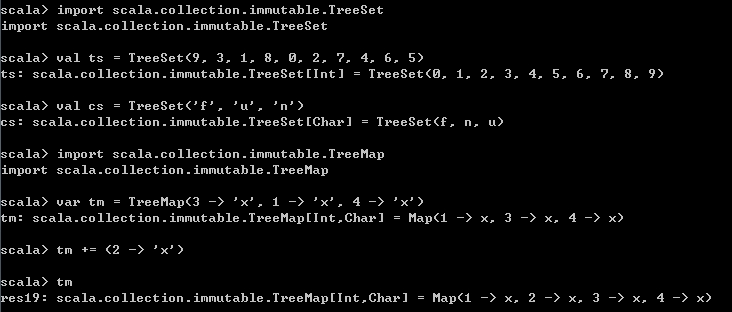
前面展示的Map和Set中的元素都是无序的,需要有序的Map和Set可以使用TreeMap和TreeSet类型。TreeSet是对其中的元素进行排序,TreeMap是对其中键值对的Key进行排序,底层使用的是红黑树。
import scala.collection.immutable.TreeSet
val ts = TreeSet(9, 3, 1, 8, 0, 2, 7, 4, 6, 5)
val cs = TreeSet('f', 'u', 'n')
import scala.collection.immutable.TreeMap
var tm = TreeMap(3 -> 'x', 1 -> 'x', 4 -> 'x')
tm += (2 -> 'x')
tm 运行结果如下,
三、初始化集合
在前面的示例代码中可以看到,一般是调用该类型伴生对象的工厂方法,并且传入初始参数值来初始化一个集合的对象。比如
List(1, 2, 3)
Set('a', 'b', 'c')
import scala.collection.mutable
mutable.Map("hi" -> 2, "three" -> 5)
Array(1.0, 2.0, 3.0) 运行结果如下,从结果可以看到,Scala编译器会根据传入初始参数的类型,推断出集合中的元素类型。

但是,对于mutable类型的集合对象来说,由于需要动态的增加新元素,最好在初始化集合对象时手动声明其类型,否则会出现以下报错情况。
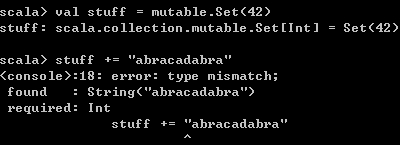
val stuff = mutable.Set(42)
stuff += "abracadabra" 报错如下,由于初始化时传入的是Int类型元素,Scala编译器会认为该Set对象中的元素必须是Int类型,当新增一个String类型元素时,就会报出类型不匹配的错。
正确的做法如下,
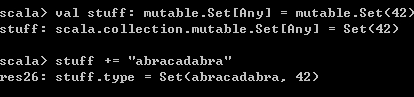
val stuff: mutable.Set[Any] = mutable.Set(42)
stuff += "abracadabra" 结果如下,
四、元组
Scala中提供一种特殊的类型,Tuple。Tuple中可以存储不同类型的元素,元组元素用圆括号包围。如下所示
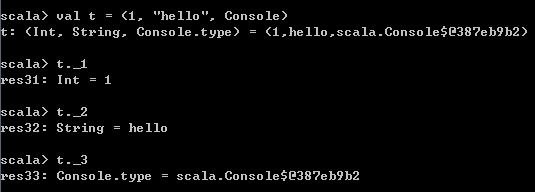
val t = (1, "hello", Console) 访问Tuple中的元素,使用_1表示第一个元素,_2表示第二个元素,以此类推。比如
t._1
t._2
t._3 运行结果如下,
也可以在生成Tuple对象时直接指定各元素对应的变量名,相当于同时声明并初始化多个元素。需要注意的是变量个数与元组中元素个数需要保持一致。
val (t1, t2, t3) = (1, "hello", Console) 结果如下,

以上是关于Scala中的集合类型的主要内容,如果未能解决你的问题,请参考以下文章