谈谈音频信号处理中 CNN 的因果性
Posted 浩哥依然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谈谈音频信号处理中 CNN 的因果性相关的知识,希望对你有一定的参考价值。
本文对笔者关于 CNN 因果性的理解作以记录。如有表述不当之处欢迎批评指正。欢迎任何形式的转载,但请务必注明出处。
目录
1. 引言
音频信号处理已经进入了神经网络时代,而 CNN 由于其强大的建模能力,已被广泛地应用在了各种音频信号处理网络中,像最近几届 DNS Challenge 的冠军所提出的网络均大量使用了 CNN。与图像处理不同,音频信号处理在大多数应用场景下都需要满足实时性要求,比如在线会议场景,直播场景等。满足实时性一般需要满足以下两个条件:算法是因果的且计算复杂度要低。本文主要讨论如何控制 CNN 网络的因果性,并不对其计算复杂度做过多讨论。
从网络架构来说,以 CNN 为主的音频信号处理网络可以分为以下两大类:
- 只包含卷积的 Encoder 架构
- 即包含卷积又包含转置卷积的 Encoder-Decoder 架构
本文对上述两种网络架构均进行了讨论,并进一步讨论了在实际 coding 过程中应该怎么做以及可能遇到的一些问题。
2. 因果性
在讨论之前,先简单介绍下系统的因果性。因果性是指:当一个系统当前时刻的输出只依赖于当前时刻的输入以及(或)过去时刻的输入时,该系统就是因果的。与之相对应的,当一个系统当前时刻的输出会依赖未来时刻的输入时,该系统就是非因果的。
可见,在实时应用中,音频信号处理算法往往需要是因果的,以对当前时刻的输入信号作出及时的响应。
3. Encoder 架构
Encoder 架构主要由卷积网络构成, 该节先从最简单的一层卷积网络开始讨论,接着拓展到多层卷积网络的情况。
3.1. 一层卷积网络
考虑一个只包含了一层二维卷积的网络,该二维卷积在时间维度上的参数为:kernel = 3,stride = 1。
3.1.1. 网络的输入,输出以及 label
假设此时输入给网络一个时长为 5 帧的音频信号,那么输出信号的时长应该为 5 - kernel + 1 = 5 - 3 + 1 = 3 帧,网络的输出比输入少了 2 帧(这 2 帧作为音频信号的上下文信息被网络消耗掉了)。那么问题来了:输出信号只有 3 帧,但 label 信号和输入信号一样都是 5 帧,输出信号的时长不等于 label 信号的时长,该怎么计算 loss 函数那?
3.1.2. 决定网络的因果性
一个自然而然的想法就是:从 label 信号中选取 3 帧信号,保证 label 信号和输出信号的时长一样不就得了?没错,确实是这样做,而且正是该选取过程决定了卷积网络的因果性。
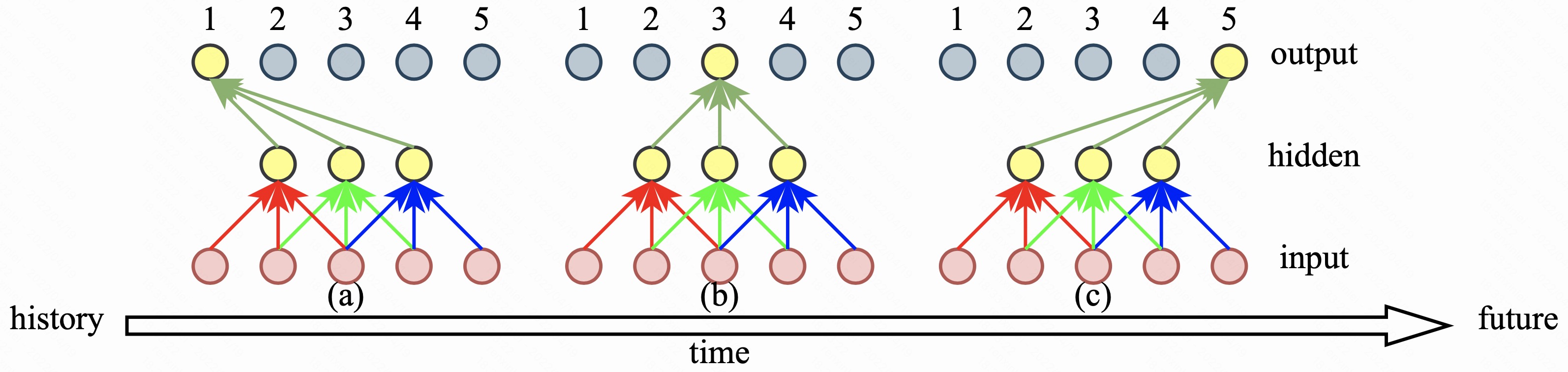
以目前所讨论的这个网络来说,有 3 种选取方案,如图1 所示。

- 图1(a) 选取 label 信号中的最后 3 帧,这种选取方式确定了该网络是因果的。因为从图中可以看出当前时刻的输出帧只利用了当前时刻的输入帧以及历史的两帧信息;
- 图1(b) 选取 label 信号中最中间的 3 帧,这种选取方式确定了该网络是非因果的。因为从图中可以看出当前时刻的输出帧除了利用当前时刻的输入帧以及历史的 1 帧信息外,还使用了未来的 1 帧信息;
- 图1(c) 选取 label 信号中最前面的 3 帧,这种选取方式确定了该网络是非因果的。因为从图中可以看出当前时刻的输出帧除了利用当前时刻的输入帧外,还使用了未来的 2 帧信息;
3.1.3. 补零操作
通过上述分析,相信读者已经熟悉该如何决定卷积网络的因果性,以及如何控制卷积网络的感受野。那么在实际 coding 的过程中,当拥有了输入数据和等时长的 label 数据之后,该怎么做,才能实现图1 所示的 3 种方式那?主要有以下两种方法:
- 丢 label 中的数据;
- 给输入数据补零。
丢 label 中的数据:这种实现方式其实就是直接根据 3.1.2. 小节所分析的来做的。丢弃 label 信号中的前两帧信号得到的就是图1(a) 所表示的;丢弃 label 信号中的第一帧和最后一帧信号得到的就是图1(b) 所表示的;丢弃 label 信号中的最后两帧信号得到的就是图1(c) 所表示的;
给输入数据补零:那么可不可以保持 label 数据不变,通过其他方法来实现那?当然可以!正所谓 “山不过来,我就过去”,既然要求 label 数据不变,那就变输入数据,给输入数据补零。相信读者在一些论文或者开源代码中也见过补零这种实现方式。补零相比上述实现方式有什么好处那?笔者考虑了一下,主要想出了以下两点说得过去的原因:
- 为了不浪费数据。从上述分析可以看到,当卷积网络在时间维度上的 kernel 大于 1 时,网络的输出时长会比输入时长少 kernel - 1 帧。而 kernel 越大,网络的输出时长就越小。为了能将辛辛苦苦生成的训练数据全部用上,可以给输入信号补 kernel - 1 帧的零,这样就能使得网络的输出时长等于输入时长(有效的输入时长,即补零之前的时长);
- 为了和实时推理代码保持一致。 考虑一个实时应用会遇到的一个场景:假设某个音频处理算法运行在时频域(其 STFT 的窗长和帧长均为 20ms,帧移为 10ms),当算法接收到第一帧 10ms 信号的时候,为了做 STFT,往往需要在前面补一帧 10ms 的零,凑足 20ms。在因果卷积网络中补零的原因之一也是为了和这种场景保持一致。
不同的补零方式会导致不同的因果关系,下面就详细说说,具体该怎么补零(读者可自行画图分析):
- 为了实现图1(a),可以在输入数据的最前面补两帧零;
- 为了实现图1(b),可以在输入数据的最前面和最后面各补一帧零;
- 为了实现图1(c),可以在输入数据的最后面补两帧零。
3.1.4. 总结
从对一层卷积网络的分析过程来看,可以得到以下两个重要结论:
- 从 label 信号中选取所需信号的过程决定了卷积网络的因果性和感受野;
- 在具体 coding 的过程中,可以通过给输入数据补零来实现不同的因果关系。
3.2. 多层卷积网络
本节考虑包含了两层二维卷积的网络,且每层二维卷积在时间维度上的参数均为:kernel = 3,stride = 1。类似于图1,现给出相应的两层 CNN 网络的因果性示例图,如图2 所示。
需要注意的是,图2 只给出了其中的三种输出结果,还有其余两种输出结果读者可自行分析。通过图2 可以看出:
- 图2(a) 表示的是非因果网络,因为输出帧除了利用当前时刻的输入帧外,还使用了未来的 4 帧信息;
- 图2(b) 表示的是非因果网络,因为输出帧除了利用当前时刻的输入帧以及历史的 2 帧信息外,还使用了未来的 2 帧信息;
- 图2(c) 表示的是因果网络,因为输出帧只利用了当前时刻的输入帧以及历史的 4 帧信息。
与 3.1. 节的分析过程一样,在实际 coding 过程中,该如何补零才能使得两层 CNN 网络实现图 2 中所示的因果性那?对于两层 CNN 网络来说,笔者能想到两种补零方式:输入层补零和逐层补零。下面就详细讨论下这两种方式,以及各自的优缺点。
3.2.1. 输入层补零
输入层补零其实就是把两层卷积网络等效于一层卷积网络。上述两层卷积网络可以等效于 kernel = 5,stride = 1 的一层卷积网络(只是从因果性和感受野角度来说是可以等效的)。从 3.1.3. 小节的分析可知:
- 给输入数据的最后面补四帧零,可以实现图2(a);
- 给输入数据的最前面和最后面各补两帧零,可以实现图2(b);
- 给输入数据的最前面补四帧零,可以实现图2(c)。
也就是说输入层补零只在输入数据上补零,网络隐藏层不需要补零;下面要讨论的逐层补零除了在输入层补零外也在网络隐藏层补零。
3.2.2. 逐层补零
具体来说,逐层补零在实际 coding 的过程中:
- 为了实现图2(a),可以在输入层和隐藏层的最后面分别补两帧零;
- 为了实现图2(b),可以在输入层和隐藏层的最前面和最后面分别补一帧零;
- 为了实现图2(c),可以在输入层和隐藏层的最前面分别补两帧零。
逐层补零只考虑当前层。以图2(a) 为例,输入层为 5 帧数据,为了使第一层 CNN 的输出也为 5 帧数据,并且保持只看当前帧和未来帧的因果性,需要给输入层的最后面补 kernel - 1 = 3 - 1 = 2 帧零。同样,为了使第二层 CNN 的输出也为 5 帧数据,并且保持只看当前帧和未来帧的因果性,需要给第一层 CNN 输出(隐藏层)的最后面补 kernel - 1 = 3 - 1 = 2 帧零。可以看出逐层补零保证每层 CNN 的输出时长都和 label 信号的时长保持一致。
3.2.3. 两种补零方式对比
两种不同的补零方式可以说体现出了两种不同的思维方式。
- 输入层补零:将多层 CNN 网络当成一个整体看待。先分析这个整体总共需要补多少零,需要怎么补,然后直接只在输入层操作就行;
- 逐层补零:将多层 CNN 网络中的每一层当成单独的个体看待。根据当前层的 kernel 和 stride 求出当前层需要补多少零,根据整个网络要满足的因果性和感受野确定当前层的零该怎么补,然后在当前层直接操作就行。 逐层补零能保证每层的输出时长和输入时长(有效的输入时长,即补零之前的时长)一致,继而保证整个网络的输出时长和输入时长一致。当前层只需要干好它自己要干的事就好,不必考虑其他层。层与层之间的关系可以用一句古语来概括 “各人自扫门前雪,莫管他人瓦上霜”。
下面再举个额外的例子,用以说明在实际 coding 过程中两种补零方式分别该怎么做。比如开发者要搭建一个两层 CNN 网络,且第一层 CNN 的参数配置为:kernel = 3,stride = 1,第二层 CNN 的参数配置为:kernel = 2,stride = 1。现在想要使这个网络的输出帧只能看未来一帧的输入信息。
输入层补零的做法
这个两层 CNN 网络可以等效为 kernel = 4,stride = 1 的一层 CNN 网络。因此,需要给输入数据补 kernel - 1 = 4 - 1 = 3 帧零。为了只看未来一帧的输入信息,需要将 2 帧零补在输入数据的最前面,1 帧零补在输入数据的最后面。
逐层补零的做法
可知输入层需要补 3 - 1 = 2 帧零,第一层 CNN 的输出需要补 2 - 1 = 1 帧零。接下来就是确定每层的零具体该怎么补。为了只看未来一帧的输入信息,可以有以下两种补零方案:
- 输入层需要补的 2 帧零全补在最前面,且第一层 CNN 的输出需要补的 1 帧零补在最后面;这种方式使得第一层 CNN 没利用未来的输入信息,而第二层 CNN 利用了未来一帧的输入信息。
- 输入层需要补的 2 帧零在最前面和最后面各补 1 帧,且第一层 CNN 的输出需要补的 1 帧零补在最前面;这种方式使得第一层 CNN 利用了未来一帧的输入信息,第二层 CNN 没有利用未来的输入信息。
可以看到,在具体 coding 的时候,输入层补零这种方式实现方法唯一,而逐层补零这种方式有多种实现方法。
3.2.4. 逐层补零需要注意的地方
假设一个这样的使用场景:1)模型是按照逐层补零的方式实现的因果模型;2)在验证模型效果的时候(即推理的时候)直接使用 load() 函数加载模型,而且按照线上运行的方式那样,每次给模型输入一帧数据,然后模型输出一帧数据;这个时候得到的输出结果很大概率上是不正确的。这是因为在训练模型的时候,模型的输入数据时长往往远远大于所补零的时长,除了输入数据中比较靠前的数据看到的历史信息是补的零之外,其余输入数据看到的历史信息基本都是有效的语音信息。而在推理过程中,每次只输入一帧数据,这导致输入的所有帧看到的历史信息都是补的零,而不是有效的语音信息。因此,输出结果大概率是不正确的。为了避免这种状况,1)只是为了验证模型效果的话,在推理的时候,可以增加模型的输入数据时长,而不是输入一帧数据;2)如果非要按照线上运行的方式那样,输入一帧数据输出一帧数据,那么就需要用 c/python 实现推理过程,与此同时需要维护好每层网络的输入 buffer。这是一项工作量较大的工程。
同样的场景,输入层补零的方式解决起来相对简单些,只需维护好输入层的 buffer 就行。
3.2.5. 总结
本节以二层卷积网络为例,分析了多层网络如何通过补零来实现不同的因果性。在实际 coding 过程中主要有输入层补零和逐层补零两种方式,可根据需要选择适合的补零方式。
3.3. 总结
对于 Encoder 架构而言,通过上述的分析可知,不管是一层卷积网络还是多层卷积网络,不管是输入层补零还是逐层补零,如果想要实现的网络是因果的,那么零应该全部补在最前面,如果想要实现的网络是非因果的,那么应该在最后面补零。在最前面补了几帧零,整个网络就使用了多少帧的历史信息。同理,在最后面补了几帧零,整个网络就使用了多少帧的未来信息。
4. Encoder-Decoder 架构
Encoder-Decoder 是一种对称的网络结构。其中,Encoder 包含的是卷积网络,Decoder 包含的是转置(或称之为反转/逆)卷积网络。而且一般 Decoder 中每个转置卷积网络层和与之对应的 Encoder 中的卷积网络层的参数配置(kernel,stride……)是完全一样的。本节先简单回顾下转置卷积,然后分析一层卷积(转置卷积)网络的因果性,最后分析多层卷积(转置卷积)网络的因果性。
4.1. 转置卷积
与卷积相反,转置卷积会增加输入特征的维度。本节以 kernel = 3,stride = 1 的一层转置卷积网络为例进行说明。
当给同等参数配置下的一层卷积网络输入 5 帧的音频信号时,它会输出 3 帧的音频信号。而如果将这 3 帧音频信号输入给一层转置卷积网络,那么将会输出 5 帧音频信号。图3 展示了该转置卷积网络的计算过程。
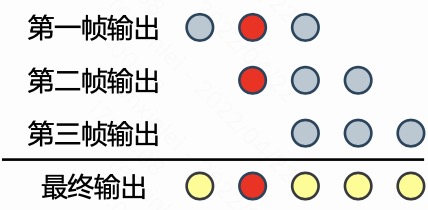
由于 kernel = 3,所以转置卷积网络每一帧输入所对应的输出都是 3 帧,将对应位置上的所有帧的输出相加得到转置卷积网络的最终输出。比如输出中的第二帧等于第一帧输出的第二个元素与第二帧输出的第一个元素之和,如图3 中红圈所示。
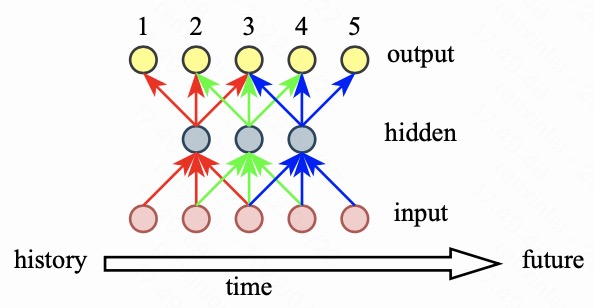
4.2. 一层卷积(转置卷积)网络
考虑一个 kernel = 3,stride = 1 的一层卷积(转置卷积)网络。假设网络的输入是时长为 5 帧的音频信号,那么经过卷积网络之后,时长变为 3 帧;接着,该 3 帧信号经过转置卷积网络之后,输出时长又变为 5 帧,与输入信号和 label 信号的时长是相等的。因此,此时可以正常计算 loss 函数。注意在此过程中,是没有额外的补零或者其他什么操作的。那么,此时网络的因果性和感受野是怎么样的那?可以通过图4 分析一下整个计算过程。以输出的第 3 帧为例,可以看出计算该帧的过程中,除了使用输入的当前帧和历史两帧信息外,还使用了未来两帧信息。其余输出帧所使用的输入帧信息可以通过图4 中的箭头走向分析得到。可以看到,此时网络是非因果网络,且使用了未来两帧的信息。
4.2.1. 控制网络的因果性和感受野
那么,在具体 coding 过程中,该怎么做才能得到一个因果网络,并且使得该网络输出的有效时长还是 5 帧那?答案是输入数据补零,输出数据丢帧。图5 展示了该计算过程。
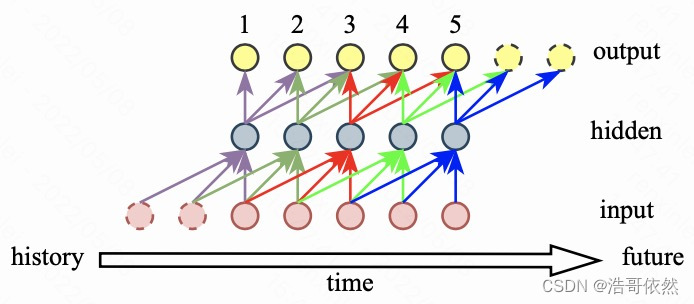
在输入数据的最前面补两帧零之后,网络的总体输入变为了 7 帧,经过卷积和转置卷积之后,网络的输出依然是 7 帧。但是 label 数据时长和补零前的输入数据时长一样,都是 5 帧。此时,为了计算 loss 函数,需要从输出的 7 帧数据中丢弃 2 帧数据。该丢弃过程在决定网络的因果性和感受野方面也起到了重要作用。
从图5 中的箭头走向可以分析出,为了得到因果网络,只能丢弃输出数据中的最后两帧;同样可以分析出,为了得到非因果网络,且使用未来一帧的输入信息,只能丢弃输出数据中的第一帧和最后一帧;为了得到非因果网络,且使用未来两帧的输入信息,只能丢弃输出数据中最前面的两帧。
4.2.2. 总结
本节介绍了如何通过给输入数据补零和丢弃输出数据来达到控制网络因果性和感受野的目的。本节给出的示例只是在输入数据的最前面补零,读者可按照同样的方法分析一下给输入数据最后面补零,或者最前面和最后面都补零会达到什么样的效果。
4.3. 多层卷积(转置卷积)网络
可使用 3.2. 小节中的分析方法,对多层卷积(转置卷积)网络的因果性和感受野进行分析。即,可以把多层卷积(转置卷积)网络当成一个整体,只在输入数据和输出数据上做相应的补零或丢帧操作。也可以把网络中的每一层当成一个单独的个体,在每一层上做相应的操作,通过控制每一层的因果性和感受野来控制整个网络的因果性和感受野。具体分析过程,此处不在赘述。
如果想要使 Encoder-Decoder 架构的网络在实际推理的过程中输入一帧数据输出一帧数据,那么,同样也会遇到 3.2.4. 小节所提到的问题。不管训练的时候采用的是哪种补零(或者丢帧)方式,都需要动手实现网络的推理过程,并维护好每一层的输入输出 buffer。
4.4. 总结
对于 Encoder-Decoder 架构的网络来说,为了控制网络的因果性和感受野,在实际 coding 的过程中,可以通过给输入数据补零,并且丢弃输出数据中的帧来实现。
5. 后记
前前后后历时一周,终于抽时间把这篇很久之前就想写的博客写完了。笔者是想到哪写到哪,有的点可能也没考虑到,如果读者感觉哪块写的不清楚或者有不同的意见和建议,欢迎提出,大家一起探讨。
“先把书读厚,再把书读薄”。再次感谢读者阅读到此处,和笔者一起经历了 “先把书读厚” 的过程。下面献上一张图片,大家一起 “再把书读薄”。
这幅图是 Ke Tan,DeLiang Wang 的论文 “A Convolutional Recurrent Neural Network for Real-time speech enhancement” 中的图,笔者就是根据这幅图理解的因果卷积。从下往上看,这幅图可以理解为 Encoder 的计算过程,从上往下看,这幅图可以理解为 Decoder 的计算过程。只要能完全理解这幅图片,什么 Encoder 架构,Encoder-Decoder 架构,什么输入层补零,逐层补零都不是问题,可以做到 “一图走天下”。
在 CNN 的基础上能构建的网络形式有很多,比如设置 stride>1,dilation>1,比如网络中加入残差链接等。在 coding 的过程中,需要认真分析搭建的网络结构,以正确地控制网络的因果性和感受野。
周末愉快!
2.4时序卷积网络TCN:因果膨胀卷积残差连接和跳过连接
对于序列问题(Sequence Modeling)的处理方法,通常采用RNN或者LSTM,例如处理一段视频/音频,往往会沿着时间方向(时序)进行操作。通常CNN网络都被认为适合处理图像数据而不适合处理sequence modeling问题,这主要由于其卷积核大小的限制,不能很好的抓取长时的依赖信息。而今年来,由于RNN及LSTM这类模型的瓶颈,越来越多的人开始发现其实CNN对于这种序列问题的处理是被大大低估了,CNN建立的model要比之前人们之前用的RNN要好很多,而且简洁。
时序卷积网络(TCN),是用于序列建模任务的卷积神经网络的变体,结合了 RNN 和 CNN 架构。对 TCN 的初步评估表明,简单的卷积结构在多个任务和数据集上的性能优于典型循环网络(如 LSTM),同时表现出更长的有效记忆。
TCN由因果膨胀卷积核残差块组成,实现没有从未来到过去的信息泄漏,并且网络查看非常远的过去以做出预测的能力,
问题描述
对音频进行生成,一个音频
x
=
{
x
1
,
…
,
x
T
}
\\mathbf{x}=\\left\\{x_{1}, \\ldots, x_{T}\\right\\}
x={x1,…,xT}的联合概率化为条件概率的乘积,如下:
p
(
x
)
=
∏
t
=
1
T
p
(
x
t
∣
x
1
,
…
,
x
t
−
1
)
(1)
\\large \\color{green}{p(\\mathbf{x})=\\prod_{t=1}^{T} p\\left(x_{t} \\mid x_{1}, \\ldots, x_{t-1}\\right)}\\tag{1}
p(x)=t=1∏Tp(xt∣x1,…,xt−1)(1)
因此,每个音频样本
x
t
x_{t}
xt都是基于之前所有时间步的样本。
条件概率分布是由一堆卷积层建模的。网络中没有池化层,模型的输出与输入具有相同的时间维度。该模型通过一个softmax层输出下一个值 x t x_{t} xt的分类分布,并对其进行优化,使数据的对数似然值最大化。由于对数似然是易于处理的,可以调整验证集上的超参数,并且可以很容易地测量模型是过拟合还是欠拟合。
因果卷积(causal Convolutions)
因果卷积可以解决序列问题。
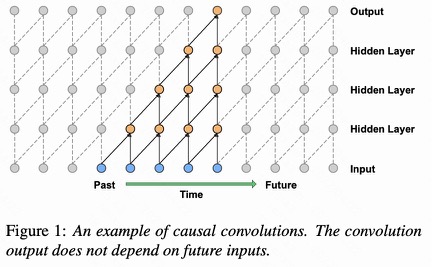
图
1
:
因
果
卷
积
层
堆
叠
的
可
视
化
\\large \\color{green}{图1:因果卷积层堆叠的可视化}
图1:因果卷积层堆叠的可视化
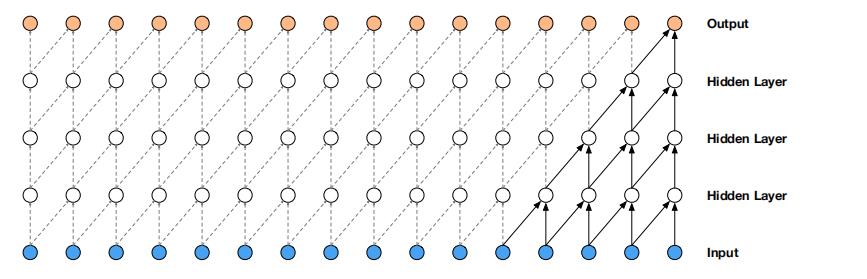
如图1所示,模型在时间步 t t t时发出的预测 p ( x t + 1 ∣ x 1 , … , x t ) p\\left(x_{t+1} \\mid x_{1}, \\ldots, x_{t}\\right) p(xt+1∣x1,…,xt) 不能依赖于任何未来的时间步 x t + 1 , x t + 2 , … , x T x_{t+1}, x_{t+2}, \\ldots, x_{T} xt+1,xt+2,…,xT。每一层的输出都是由前一层对应未知的输入及其前一个位置的输入共同得到,并且如果输出层和输入层之前有很多的隐藏层,那么一个输出对应的输入就越多,并且输入和输出离得越远。
对于图像,与因果卷积等价的是mask卷积,它可以通过构造mask张量并在应用它之前对该mask与卷积核进行逐项相乘来实现。对于文本等一维数据,可以通过将普通卷积的输出移动几个时间步来更容易实现这一点。
在训练时,对所有时间步长的条件预测可以并行进行,因为ground truth x \\mathrm{x} x的所有时间步长都已知。当模型测试时,预测是连续的:在每个样本被预测后,它被反馈到网络来预测下一个样本。
因果卷积通常比rnn训练得更快,特别是当应用于非常长的序列时。因果卷积的问题之一是,它们需要许多层,或大的filter来增加卷积的感受野。例如,在图1中,感受野仅为 5 ( = 5(= 5(= #layers + + + filter length − 1 ) . -1) . −1).。而卷积层数的增加就带来:梯度消失,训练复杂,拟合效果不好的问题。
所以就有了膨胀卷积,将感受野增加一个数量级。
膨胀因果卷积( dilated convolution)
膨胀卷积是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。等同于通过增加零来从原始filter中生成更大的filter。
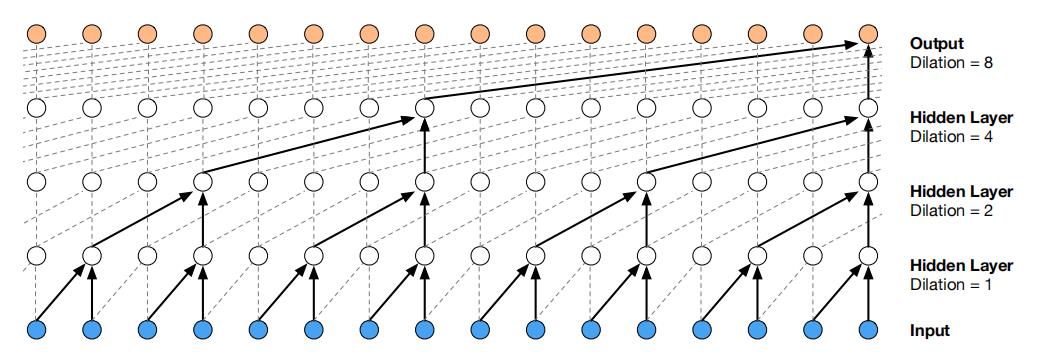
图
2
:
膨
胀
的
因
果
卷
积
层
堆
叠
的
可
视
化
\\color{green}{图2:膨胀的因果卷积层堆叠的可视化}
图2:膨胀的因果卷积层堆叠的可视化
图2描绘了膨胀1、2、4和8的膨胀因果卷积。
与普通卷积相比,膨胀卷积可以有效地使网络在更粗的尺度上运行。这类似于池化或跨越式卷积,但这里的输出与输入具有相同的大小。
一种特殊情况,膨胀系数1的膨胀卷积就是标准卷积了。堆叠膨胀卷积使网络仅用几层就能拥有非常大的感受野。训练过程,每一层的膨胀倍数达到一个极限,然后重复,即
1
,
2
,
4
,
.
.
.
,
512
,
1
,
2
,
4
,
.
.
.
,
512
,
1
,
2
,
4
,
.
.
.
,
512.
1, 2, 4, . . . , 512, 1, 2, 4, . . . , 512, 1, 2, 4, . . . , 512.
1,2,4,...,512,1,2,4,...,512,1,2,4,...,512.
看图3更清楚.

图 3 : 膨 胀 的 因 果 卷 积 训 练 过 程 \\color{green}{图3:膨胀的因果卷积训练过程} 图3:膨胀的因果卷积训练过程
门控激活
使用门控激活单元
z
=
tanh
(
W
f
,
k
∗
x
)
⊙
σ
(
W
g
,
k
∗
x
)
(2)
\\large \\color{green}{\\mathbf{z}=\\tanh \\left(W_{f, k} * \\mathbf{x}\\right) \\odot \\sigma\\left(W_{g, k} * \\mathbf{x}\\right)}\\tag{2}
z=tanh(Wf,k∗x)⊙σ(Wg,k∗x)(2)
其中
∗
*
∗表示卷积运算符,
⊙
\\odot
⊙表示元素级的乘法运算符,
σ
(
⋅
)
\\sigma(\\cdot)
σ(⋅)是sigmoid函数,
k
k
k是层索引,
f
f
f和
g
g
g分别表示卷积核和门,
W
W
W是可学习的参数。
残差连接和跳过连接
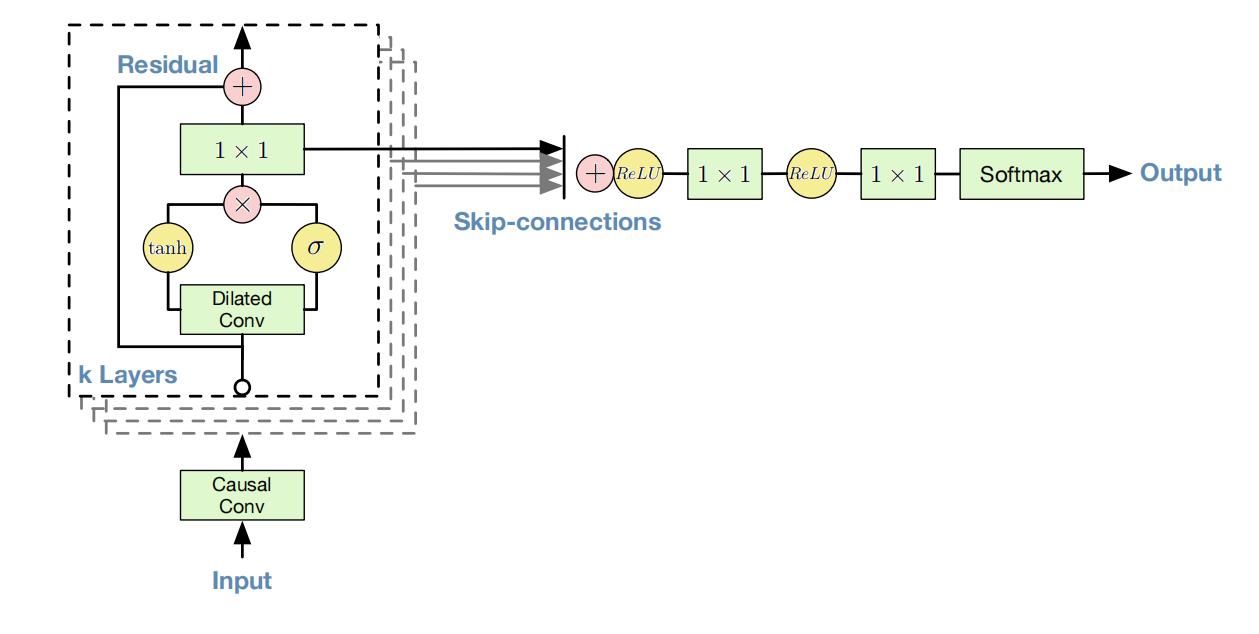
图 4 : 残 差 连 接 和 跳 过 连 接 \\color{green}{图4:残差连接和跳过连接} 图4:残差连接和跳过连接
残差连接和参数化跳过连接在整个网络中使用,保持网络稳定,以加快收敛速度,并能够训练更深入的模型。在图4中,展示了模型的残差块,它在网络中被多次堆叠。
条件生成
给定一个额外的输入
h
\\mathrm{h}
h, 可以模拟给定输入的音频的条件分布
p
(
x
∣
h
)
p(\\mathbf{x} \\mid \\mathbf{h})
p(x∣h)。Eq.(1)变成
p
(
x
∣
h
)
=
∏
t
=
1
T
p
(
x
t
∣
x
1
,
…
,
x
t
−
1
,
h
)
(3)
\\large \\color{green}{p(\\mathbf{x} \\mid \\mathbf{h})=\\prod_{t=1}^{T} p\\left(x_{t} \\mid x_{1}, \\ldots, x_{t-1}, \\mathbf{h}\\right)}\\tag{3}
p(x∣h)=t=1∏Tp(xt∣x1,…,xt−1,h)(3)
通过在模型上添加条件,引导网络生成具有所需特性的音频。例如,在多扬声器设置中,可以通过向模型提供扬声器标识作为额外输入来选择扬声器。类似地,对于TTS,提供关于文本的信息作为额外的输入。
以两种不同的方式对模型施加条件:全局条件作用和局部条件作用。全局条件反射的特征是一个单独的潜在表示
h
\\mathrm{h}
h,它影响所有时间步长的输出分布,例如,一个嵌入在TTS模型中的扬声器。Eq.(2)的激活函数现在为:
z
=
tanh
(
W
f
,
k
∗
x
+
V
f
,
k
T
h
)
⊙
σ
(
W
g
,
k
∗
x
+
V
g
,
k
T
h
)
(4)
\\large \\color{green}{\\mathbf{z}=\\tanh \\left(W_{f, k} * \\mathbf{x}+V_{f, k}^{T} \\mathbf{h}\\right) \\odot \\sigma\\left(W_{g, k} * \\mathbf{x}+V_{g, k}^{T} \\mathbf{h}\\right)}\\tag{4}
z=tanh(Wf,k∗x+Vf,kTh)⊙以上是关于谈谈音频信号处理中 CNN 的因果性的主要内容,如果未能解决你的问题,请参考以下文章