360周鸿祎又“开炮”:GPT 6-8就将产生自主意识!我们来测算一下对错
Posted YMPzUELX3AIAp7Q
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了360周鸿祎又“开炮”:GPT 6-8就将产生自主意识!我们来测算一下对错相关的知识,希望对你有一定的参考价值。



数据智能产业创新服务媒体
——聚焦数智 · 改变商业
近日,360的周鸿祎放言“GPT6到GPT8人工智能将会产生意识,变成新的物种。未来,人工智能大语言模型有可能实现自我进化,自动更新系统和自我升级,或者指数级进化能力,人类将会面临不可预知的安全挑战。”
虽然360每况愈下,但周鸿祎作为“风口达人”,几乎每个风口都要掺和一脚。他的话有几分可信度,是要打一个大大问号的。
并且,周鸿祎只给出一个预测,但却没有给出自己的理由和推理逻辑。
作为主打行业深度的媒体,我们不能停留在标题党式的口号上,而要从更深层次来分析问题。
GPT会成长为一个通用人工智能模型么?如果会,这个过程可能需要多久时间?接下来,我们试图一起来探讨这个让人不安的问题。
要回答这个问题,我们就需要将GPT这类大模型“拆”开来,看看它内部是什么构造,是如何工作的。
“拆开”大模型的黑箱
大模型是指参数数量非常大的神经网络模型,通常用于处理复杂的自然语言处理、图像识别、语音识别等任务。大模型的核心要素主要是神经网络、层、神经元和参数。

数据猿制图
神经网络
神经网络是一种机器学习算法,它的灵感来源于人脑的神经系统。它由多个层组成,每个层都包含多个神经元,层之间的连接形成了神经网络。每个神经元都接收来自上一层神经元的输入,并根据其输入计算出输出,然后将其传递给下一层。
层
层是神经网络的组成部分,由多个神经元组成。每个层可以使用不同的激活函数、优化器等参数进行配置。通常,每一层都会对输入进行一些变换,然后将输出传递给下一层。常见的层包括全连接层、卷积层、池化层等,划分不同类型的层的依据主要是处理的数据类型、层的内部结构、层的功能等。比如,全连接层是神经网络中最简单的一种层,也是最常用的一种层。其核心功能是将上一层的所有神经元与本层的所有神经元相连接。这种连接方式允许神经网络学习到输入数据的复杂非线性关系。全连接层通常用于图像分类、语音识别、自然语言处理等任务;卷积层是卷积神经网络(CNN)中的核心层,用于处理具有空间结构的数据,例如图像。其核心功能是通过一组可学习的卷积核在输入数据上进行卷积操作,以提取输入数据的特征。卷积层的内部结构包括多个卷积核和一个偏置项,卷积层的输出通常被输入到池化层中。
神经元
神经元是神经网络中的基本单元,其主要功能是接受来自输入层或前一层神经元的信号,并产生输出信号。神经元的输入通过一组带权重的连接进行传输,并在神经元中被加权求和。然后,这个总和被输入到激活函数中进行非线性变换,产生神经元的输出。
神经元的核心是激活函数,激活函数是神经元处理输入信号的核心组成部分。神经元接收输入信号并对其进行加权求和,然后将其输入到激活函数中进行非线性变换。激活函数的作用是为神经元引入非线性因素,使神经元能够学习到非线性的模型,从而提高模型的表达能力。
参数
参数是指神经网络中的变量,它们会随着神经网络的训练而更新。每个神经元都有一个权重向量和一个偏置项,这些权重和偏置项通常被称为参数。这些参数的值在训练期间会被优化器更新,以使得神经网络的输出尽可能接近期望输出。
综上,神经元是层的组成部分,而层是神经网络的组成部分。参数被存储在神经元中,每个神经元都有一组参数(权重和偏置项)。在训练过程中,优化器会更新这些参数,以使得神经网络的输出尽可能接近期望输出。
那么,神经网络、层、神经元、参数是怎么系统工作的呢?
接下来,我们以GPT-4的训练过程为例,来说明大模型训练过程中不同元素的协同配合过程,具体来看:
1) 首先,随机初始化 GPT-4 模型的所有参数,包括神经网络中每个神经元的权重和偏差等。
2) 准备数据集,这些数据可以是经过标记的文本,如新闻文章、小说、论文、社交媒体帖子等。在训练之前,必须对数据进行预处理和清理,例如删除特殊字符、停用词和其他无关信息。
3) 训练数据会被划分成多个小批次(batch),通常每批次包含几百到几千个文本样本。将每个批次输入 GPT-4 模型中,模型将根据当前的参数计算输出,即预测下一个词的概率分布。
4) 计算模型的损失函数(loss function),损失函数可以反映模型在训练集上的性能。在语言模型的情况下,通常使用交叉熵作为损失函数。
5) 根据反向传播算法(backpropagation algorithm)计算参数的梯度,梯度反映了模型在某一点上的损失函数的变化率。然后使用优化器(optimizer)更新模型的参数,以减少损失函数。
6) 重复步骤 3-5 直到模型的性能达到预期或训练时间耗尽。
跟人脑有几分相似
从上面的分析可以看到,大模型是在尽力的去模拟人脑的工作机理。事实上,目前人类是唯一有智能的生物,要想大模型也有像人类一样的智能,“仿生”是最好的办法。
接下来,我们先简单梳理一下人脑的结构和人脑的工作机理,然后将大模型的结构、工作机理与人脑进行对比。
先来看看人类大脑的结构。
人的大脑是由数百亿个神经元组成的一个神经网络系统,神经元是神经网络的基本单元。每个神经元之间通过突触相互连接,这些突触是神经元之间传递信息的基本通道。
神经元的核心功能是接收、处理和传递信息。一个神经元通常由三部分组成:细胞体、树突和轴突。神经元接收来自其他神经元的信号通过树突传入细胞体,细胞体对这些信号进行处理,并产生输出信号,输出信号通过轴突传递给其他神经元。
神经元之间的连接通常是通过突触来实现的。突触分为化学突触和电突触两种。化学突触是通过神经递质来传递信号的,电突触则是直接通过电信号来传递信息。
人的大脑由大量神经元和突触组成,这些神经元和突触按照特定的规律连接在一起,形成不同的神经回路和神经网络。这些神经回路和神经网络共同协作,完成人体各种复杂的认知、感知、情感和行为等活动。
通过上面的分析,我们可以将人脑与大模型的各个元素来做个类比,如下表:

大模型中的层可以类比于人脑中的皮层。大模型的层是由若干个神经元组成的,每个神经元接收上一层的输出作为输入,并通过激活函数进行计算,产生本层的输出。而人脑皮层则是由神经元和突触组成的复杂网络,其中每个神经元也接收其他神经元的输出作为输入,并通过化学信号在突触处进行信息传递和处理。
大模型的神经元可以类比于人脑中的神经元,它们是网络中的基本计算单元,接收输入信号,并通过激活函数对其进行处理,产生输出信号。人脑神经元则是生物体中的基本计算单元,通过突触连接其他神经元,接收来自其他神经元的化学信号,并通过电信号产生输出信号。
大模型的参数可以类比于人脑中的突触权重,它们决定了神经元之间信息传递的强度和方式。人脑中的突触权重也起到类似的作用,它们决定了神经元之间的连接强度和突触处的信号传递方式。
大模型与人脑的定量对比
上面只是从定性角度,搞清楚的大模型、人脑的工作机理,并对他们核心元素做了类比。
量变引起质变,即使是结构上类似,但数量的差异,往往会导致巨大的不同。
接下来,我们来从数量角度,来对大模型和人脑进行对比。
下面是GPT-1到GPT-3.5模型的神经层总数、参数总量的近似值(没有披露神经元数量,GPT-4没有披露相关数据):
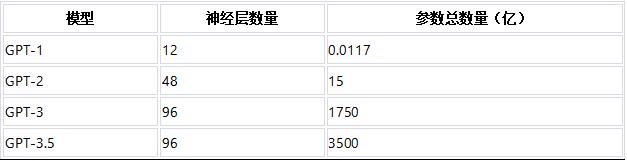
然后,我们来看看人类大脑的神经元和突触数量。为了让结果更有参考性,除了人类,我们还选取了猴子、海豚、猫、蚂蚁。具体结果如下表:

通过上面的分析我们知道,大模型的神经元可以类别人类的神经元,大模型的参数类别人脑的突触。但可惜业界的大模型很少披露神经元数量,一般披露参数规模。因此,我们将GPT系列大模型的参数规模,与人类、猴子、海豚、猫大脑的突触规模来进行比较:

从上表可知,单从数量规模来看,GPT-3.5的“智能”水平已经落在猴子的智力区间,离人类的智力水平还差285.7-2857倍。
另一方面,从GPT本身的演进速度来看,其前两次迭代过程,每次参数规模都能提升两个数量级,但GPT-3之后,参数规模提升的速度大幅度降低。假设以后每次迭代,GPT的参数规模增加5倍,那么迭代5次之后(5的5次方是3125),即到GPT-9,其“智力水平”也许可以赶上人类。
当然,以上的推论只是一个简单的模型,并有一个假设前提——智力水平跟突触(参数)规模正相关。但这个假设能否成立是需要打一个大大的问号的。
相对于突触,神经元才是度量智力水平更好的指标。从目前情况来看,大模型的激活函数,其信息处理能力是要远远弱于人脑神经元的。大模型神经元的激活函数较为简单,例如,Sigmoid激活函数的神经元在输出范围上具有较平滑的S形曲线,可以实现二元分类等任务,ReLU激活函数的神经元具有非线性的修正线性性质等。相对而言,人脑的神经元却是一个生物细胞,其信息处理能力肯定要远远超出一个简单的数学函数的。因此,即使大模型的神经元在数量上赶上人脑水平,达到上千亿规模(对应的参数规模超过1000万亿),其智力水平也无法跟人脑相比。
此外,大模型的神经网络可以类比于人脑的神经网络,但是它们的实现方式完全不同。大模型的神经网络是通过数学模型来模拟神经元之间的连接和信息传递,而人脑神经网络则是由神经元、突触等生物元素组成的复杂结构。另外,人脑神经网络中神经元之间的连接是非常复杂的,它们可以自由地建立、拆除和调整连接,而大模型的神经网络则是事先设定好的。
目前来看,人类还是比较“安全的”。但是,我们不要忘了,人脑的神经元规模几乎是不变的,而大模型的神经元、参数规模却在指数级的递增。按照这样的趋势,大模型的智能水平追上人类可能只是一个时间问题。
人工智能领域的大神级人物Hinton就表示,“通用人工智能的发展比人们想象的要快得多。直到不久前,我还以为大概需要20-50年,我们才能实现通用人工智能。而现在,通用人工智能的实现可能需要20年或更短的时间。”
面对通用人工智能甚至超级人工智能,人类的心理是复杂的。一方面,希望有更智能的系统来帮助人类完成更多的工作,解放生产力;另一方面,又怕打开了潘多拉魔盒,放出一个比核武器还恐怖的怪物。
但愿,即使我们造出了一个“神”,也是充满爱的神,而不是一个将人类视为蝼蚁的神!
文:一蓑烟雨 / 数据猿





MarioGPT自动生成“超级玛丽”;周鸿祎:ChatGPT可能产生意识;国内版ChatGPT复旦首发,但“非常不成熟”...

本周,AI业界又有哪些新鲜事?

ChatGPT
国内版ChatGPT首发被复旦“抢注”,但非常不成熟?
虽然各大厂如火如荼地备战国内版“GPT”,但谁也没抢到这个“首发”:2 月 20 日晚,复旦大学自然语言处理实验室发布了国内首个类 ChatGPT 模型 MOSS,并邀请公众参与内测(https://moss.fastnlp.top/#/)。

从 MOSS 项目主页来看,其定位是“一个类似 ChatGPT 的对话式语言模型”,能按照用户指示执行各种自然语言任务,包括回答问题、生成文本、总结文本和生成代码,等等。
不过,虽然 MOSS 的基本功能与 ChatGPT 类似,但复旦开发团队坦言它仍有许多不足:
· 由于训练数据中的多语言语料库有限,MOSS 在理解和生成英语以外的语言文本方面表现不佳。
· 由于模型容量相对较小,MOSS并不包含足够的世界知识,因此它生成的一些回答可能包含误导性或错误信息。
· 有时 ,MOSS 会以迂回的方式执行,甚至无法遵循指令。在这种情况下,用户可能需要重新生成几次或修改提示以获得满意的回答。
· 有时,MOSS 还会生成不道德或有害的回答。
对于服务器的意外崩溃以及陆续增多的质疑,复旦 MOSS 开发团队在其官网发布公告作为回应:
“MOSS 还是一个非常不成熟的模型,距离 ChatGPT 还有很长的路需要走。”
周鸿祎:“天马行空地想一想,ChatGPT可能会产生意识”
“天马行空地想一想,ChatGPT可能会在认知的基础上产生意识;不断自我进化,实现机器人制造机器人的前景等。”在2月24日举办的第三届上海数字创新大会主论坛上,360集团创始人周鸿祎如是表示。
关于人工智能是否会产生“意识”的讨论已经不是新话题了。但实际上,究竟什么是意识,是生命体才有能有的主观感受,还是天衣无缝的逻辑设定,这牵涉到哲学中唯心还是唯物的问题。
不过被教导物质和意识二元两分的我们来说,不太可能认同人工智能可以产生意识的说法,所以但凡有人这么设想才显得格外“离谱”。
MarioGPT:通过GPT自动生成游戏回忆童年
《超级玛丽》是很多人的童年回忆,在有了AIGC之后,我们可以通过GPT自动生成游戏来回忆童年。日前,来自哥本哈根信息技术大学等机构的研究人员发表了一篇名为《MarioGPT: 通过大型语言模型生成开放式文本二级语言模型》的论文。
论文地址:https://arxiv.org/pdf/2302.05981.pdf

一个智能体在玩MarioGPT生成的超级玛丽游戏
据论文介绍,大型语言模型(LLMs) 已经在许多不同的领域显示出令人难以置信的有效性,这些训练有素的LLMs可以被微调,重新使用信息并加速新任务的训练。MarioGPT经过微调的GPT2模型,被训练用来生成tile-based游戏关卡。

技术前沿
被AlphaGo 击败六年后,人类借助AI打败AI
据《金融时报》最新报道,近来一名人类棋手以 14:1 的比分,全面打败了顶级围棋 AI 系统 KataGo,即:人类战胜了 AI。
一般看到这种比分差距,我们会猜测两种可能:要么这位人类棋手太强,要么这个围棋 AI 系统 KataGo 太弱。然而,战胜 KataGo 的这个人,不是世界冠军,甚至不是职业棋手,他只是一位名叫 Kellin Pelrin 的美国业余棋手,结果与 AI 对战的 15 场比赛中,他赢了 14 场。
KataGo 也并不弱,它是一款很强大的开源围棋 AI,以 AlphaGo 和 AlphaZero 技术作为开发基础,由哈佛大学 AI 研究员 David J. Wu 研发,曾参与第 12 届 UEC 杯世界计算机围棋大会并获得第三名。
而之所以战胜 KataGo,主要因为Kellin Pelrin发现了它的弱点,准确来说,是FAR AI开发的一个软件程序,通过一百多万盘的对弈之后发现了KataGo的弱点。而Kellin Pelrin做的是对这些弱点进行了学习和理解。
对于借助AI打败AI,Kellin Pelrin表示说:“该软件所揭示的获胜策略不仅可行,而且也不是很难,差不多中等水平的棋手就可以用它来击败 AI。”
苹果手表即将实现无创血糖监测功能?
作为智能穿戴的佼佼者,智能手表是各科技巨头争抢的沙场。不过,苹果仍是这一领域的头号玩家。通过十多年的研发,苹果无创血糖监测仪取得了突破。
在人们的认知中,血糖检测一般需要验血,所以必然会有创口,而有创口就意味着疼痛。如果可以无创检测血糖而且精准的话,那无疑是里程碑式的创造。为此,苹果这项代号为E5的登月级项目尽管耗资巨大,却一直在进行。

具体来看,让这一突破从理论变为现实的两项重要技术是“硅光子学芯片”和“吸收光谱监测程序”。具体作用原理是,通过激光将特定波长的光线照射到皮下被葡萄糖渗透的组织液中,然后通过显示葡萄糖浓度的方式将信息传递回传感器,再以某种算法确定人体的血糖指标。
在实现了心跳、血压、血脂、血氧饱和度的监测之后,如果能进一步实现血糖监测,智能手表就更像一个小型的人体监测仪了。

产业界
罗技发布一款可在室内飙车的智能驾驶舱
想要体验飙车的快感,又碍于寒冬酷暑不想出门怎么办?赛车爱好者的福音来了,罗技与游戏配件产品厂商Playseat合作,制作出一款可在室内玩耍的开放的智能驾驶舱,看上去非常简约。

据罗技官方表示,开放的驾驶舱设计不会限制身体的运动,可以进行激烈的驾驶,不过建议"司机"的体重在44磅到360磅之间。

AI伦理
60多个国家签署军事中合规使用人工智能行动呼吁书
AIGC的火爆让人们对AI的讨论登上热度头条,但另一方面,对于人工智能作为工具有可能被错误应用,从而造成灾难后果的讨论也开始出现。日日前,荷兰主办了“军事领域负责任使用人工智能峰会(REAIM)”,来自60多个国家(包括中国)的代表参加了会谈。

除以色列外,所有与会者签署了行动呼吁书,各国承诺根据"国际法律义务,以不破坏国际安全、稳定和问责制的方式"发展和使用军事人工智能。
中国代表谈践在峰会上表示,各国应"反对通过人工智能寻求绝对的军事优势和霸权",并通过联合国开展工作。
签署国同意解决的其他问题还包括:军事人工智能的可靠性,其使用的意外后果,升级风险,以及人类需要参与决策过程的方式。

以上是关于360周鸿祎又“开炮”:GPT 6-8就将产生自主意识!我们来测算一下对错的主要内容,如果未能解决你的问题,请参考以下文章