Prometheus监控实战系列七:任务与实例
Posted 唐僧骑白马
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus监控实战系列七:任务与实例相关的知识,希望对你有一定的参考价值。
1、功能概述
任务与实例,是Prometheus监控中经常会提到的词汇。在其术语中,每一个提供样本数据的端点称为一个实例(instance),它可以是各种exporter,如node-exporter、mysql-exporter,也可以是你自己开发的一个服务。只要提供符合prometheus要求的数据格式 ,并允许通过HTTP请求获取信息的端点都可称为实例。而对于实例数据的采集,则是通过一个个任务(job)来进行管理,每个任务会管理一类相同业务的实例。
在前面"配置介绍“一文中,我们对Prometheus的配置文件promehteus.yml进行过讲解,其中scrape_configs模块即是管理任务的配置。
如下是Prometheus默认配置的Job,用于获取Prometheus自身的状态信息,这是一个格式最精简的Job。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
当Job生效后,我们可以在Prometheus的Targets页面看到相关的任务实例,其中Endpoint项代表该实例的采集地址;State项为实例状态,状态为UP表示可正常采集;Labels为实例所拥有的标签 ,标签会包含在获取到的所有时间序列中。

2、配置参数
Job_name(任务名称)
Job_name定义了该job的名称,这会生成一个标签job="xxx",并插入到该任务所有获取指标的标签列中。如上面的Prometheus任务指标,我们可以在表达式浏览器中查询 job="prometheus",即可看到与该job相关的指标。
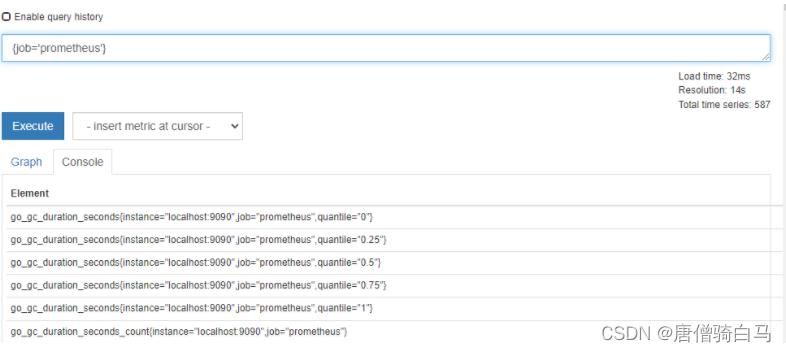
此外,Job也支持自定义标签的方式。如下所示,将在该Job获取的指标中添加group=“dev”的标签。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
labels:
group: 'dev'
配置完成后,重启Prometheus可看到标签 已生效。

注意:修改Job后,只对新获取数据生效,原有数据不会有变化 。
static_configs(静态配置)
static_configs为静态配置,需要手动在配置文件填写target的目标信息,格式为域名/IP + 端口号。当有多个目标实例时,书写格式如下 :
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets:
- '192.168.0.1:9100'
- '192.168.0.2:9100'
- '192.168.0.3:9100'
Prometheus对于监控实例的加载,除了静态配置,还可以使用文件配置的方式。操作方式很简单,只需要在一个文件中填好相关的实例信息,然后在Job中加载该文件即可,文件的格式必须是yaml或json格式。
如:
[root@server prometheus]# cat agent.yml
- targets:
- '192.168.75.162:9100'
配置Job加载该文件
# 被监控机器
- job_name: 'agent1'
file_sd_configs:
- files:
- /usr/local/prometheus/agent.yml
scrape_interval和scrape_timeout
scrape_interval代表抓取间隔,scrape_timeout代替抓取的超时时间,它们默认继承来global全局配置的设置。但如果有特殊需求,也可以对单个Job单独定义自己的参数。
示例:
scrape_configs:
- job_name: 'myjob'
scrape_interval:15s
scrape_timeout: 10s
static_configs:
- targets: ['192.168.0.1:9100']
注意:scrape_timeout时间不能大于scrape_interval,否则Prometheus将会报错。

metric_path
指定抓取路径,可以不配置,默认为/metrics。
示例:
scrape_configs:
- job_name: 'myjob'
metric_path:/metrics
static_configs:
- targets: ['192.168.0.1:9100']
scheme
指定采集使用的协议,http或者https,默认为http。
示例:
scrape_configs:
- job_name: 'myjob'
scheme: http
static_configs:
- targets: ['192.168.0.1:9100']
params
某些特殊的exporter需要在请求中携带url参数,如Blackbox_exporter ,可以通过params进行相关参数配置。
示例:
scrape_configs:
- job_name: 'myjob'
params:
module: [http_2xx]
static_configs:
- targets: ['192.168.0.1:9100']
basic_auth
默认情况下,exporter不需要账号密码即可获取到相关的监控数据。在某些安全程度较高的场景下,可能验证通过后才可获取exporter信息,此时可通过basic_auth配置Prometheus的获取exporter信息时使用的账密。
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets: ['192.168.0.1:9100']
basic_auth:
username: admin
password: mypassword
上一篇:Prometheus监控实战系列六:PromQL语法(下)
下一篇:Prometheus监控实战系列八:标签重写
Prometheus监控运维实战十七: 高可用与扩展性
在上篇的Prometheus远程存储方案中,我们解决了数据持久化和大数据量存储/查询的需求。但是,在大规模的监控环境中,除了存储方面的问题外,Prometheus实例在处理大量的监控任务时,也可能会成为性能瓶颈。另外,还有高可用的问题,应该如何来保证监控的可靠性。
本篇我们将就这些问题进行探讨研究。
一. Prometheus高可用
在Prometheus的官方推荐方案中,对于高可用的处理是通过部署两套Prometheus,配置同样的任务实例来实现的。在这个方案中,两套Prometheus会获取相同的监控指标,并且触发同样的告警规则,而对于警报的去重工作则由Alertmanager来负责。

但此方案也存在着缺点,比如当某个Prometheus出现故障或中断时,那么该节点将会出现数据丢失的情况,并与另一个节点存在数据差异。当在该节点上进行查询操作时,就会遇到这个问题。
对此,我们可以与远程存储方案结合起来,将Prometheus的读写放到远程存储端,通过高可用 +远程存储的方式来解决上面的问题。

此优化方案在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当某个Promthues 节点发生宕机的情况时,由于还有另一个节点在获取数据,这样可以保证在查询时不会遇到数据丢失的问题。
该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时确保Promthues服务高可用性的场景。
二. 联邦模式
在大规模的监控环境中,当单个Prometheus无法处理大量的监控采集任务时,我们可以基于联邦的模式将采集任务划分到不同的Prometheus实例中,再由顶层的Prometheus进行数据的统一管理。

在此方案中,工作节点的Prometheus根据拆分原则,负责指定实例的数据采集及规则告警工作,而主节点则通过/federate接口从工作节点获取数据指标,并写入到远程存储中,同时对接Grafana实现监控展示。
1. 任务拆分
在任务的拆分上,我们可以从两个维度来考虑,一种是按功能进行拆分,一种则是水平的拆分。
功能拆分
功能拆分可按资源类型或区域等维度,将不同的任务划分到不同的Prometheus节点上,如下图所示

这种方式简单且易于理解,在此架构中每个Prometheus都有明确的目标实例且配置独立,当监控的实例指标出现故障时,用户可以清楚定位到相应的Prometheus节点。通过功能拆分的方式,可以有效分散Prometheus的负载压力,提升监控系统的整体容量规模。
不过在某些场景下,通常是大规模的部署环境中,功能拆分依然会出现瓶颈。例如:在一个存在着上万台主机的环境中,要是通过单个Prometheus去监控主机参数的话,无疑是难以支持的。而如果要靠人为来划分多个Prometheus监控对应的主机节点,则会给运维人员增加很多工作量和复杂性。在这种场景下,我们可以考虑水平拆分的方式。
水平拆分
在水平拆分的场景下,多个Prometheus节点配置相同的实例信息,Prometheus通过HASH规则的方式,计算自身负责的目标实例,从而实现横向的扩展。

配置示例:
scrape_configs
job_namenode
file_sd_configs
files
/etc/prometheus/node/*.yml
relabel_configs
source_labels__address__
modulus2
target_label__tmp_hash
actionhashmod
source_labels__tmp_hash
regex^0$
actionkeep
注释:本示例中我们负责抓取监控指标的工作节点为两台,所以在modulus处标记数量为2,并根据每个实例的[__address__]标签值 ,生成一个临时标签[__tmp_hash]及对应的值,该值内容包含0或1。然后根据正则匹配机制,保留符合正则表达则的实例。在两个工作节点中,regex处分别配置为^0$和^1$。如果后续工作节点的数量增加,则需要修改modulus值为新的节点数量 ,并在新的节点中配置对应的regex。
在每个Worker节点的配置中,可以插入一个worker:<value>的标签,这样方便在主节点处可以知道相关指标来源于哪个worker。
global
external_labels
worker0
2. 主节点配置
在worker配置完成正常运行后,我们可以开始配置主节点的任务,用于抓取工作节点的时间序列。集群中的工作节点都是我们Targets的目标地址,本示例为两个worker节点,相关配置如下 :
scrape_config
job_namenode-workers
honor_labelstrue
metrics_path/federate
params
match[]
{job="node"}
static_configs
targets
worker-0:9090
worker-1:9090
注释 :honor_labels需配置为true,这样可保证主节点不会覆盖工作节点的序列标签;metrics_path指定federate API路径;params指定match[]参数,匹配我们想要获取的特定时间序列,可以指定多个条件,Prometheus将返回所有条件的并集;targets指定工作节点的目标地址。
如下所示,在任务正常启动后,我们就可以在主节点的上查询到Worker节点收集的监控指标。


结语:
目前Prometheus在集群与扩展性方面的功能并不算强大,通过分级联邦的方式虽然可以解决扩展性的问题,但依然存着的一些不足之处 。例如:多层结构使得Prometheus之间的网络变得复杂,我们不止要关注工作节点和目标之间的连接,也要关注主节点与工作节点的连接;工作节点根据设定的间隔获取目标指标,而主节点对于工作节点数据的抓取也存在着时间间隔,这可能导致主节点出现数据延迟的情况;最后,当所有的指标汇总到主节点时,可能会对其造成较大的压力,在资源的调配上需做好分配,以免引起主节点的崩溃。
基于以上的短板,在采用分级联邦时,建议尽量遵循下列的规范:
1. 将告警的规则配置在worker节点,而不是主节点。
2. 在主节点抓取worker节点指标时,通过match参数筛选过滤指标。
3. 整体分层架构最多不要超过三层。
4. 将分级联邦模式做为最后的选择,只有在大规模的环境中才考虑使用。
以上是关于Prometheus监控实战系列七:任务与实例的主要内容,如果未能解决你的问题,请参考以下文章