3.21面试题
Posted 今天你学Java了吗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.21面试题相关的知识,希望对你有一定的参考价值。
常见面试题
选择题+简答题+代码编写题
简答题
-
JDK、JRE、JVM的区别
- JDK是Java开发工具包,是Java的核心,包括JRE+编译运行的命令工具
- JRE是Java运行环境,是运行Java程序所必须的环境集合,包括JVM+Java系统类库
- JVM是Java虚拟机,是Java实现跨平台的最核心部分,能够运行Java语言所开发的程序
-
java的八种基本数据类型
八种基本类型包括:
- 整型:byte、short、int、long
- 浮点型:float、double
- 布尔型:boolean
- 字符型:char
其中:
-
byte是字节,字节型,专门用于存储整数,只占用1个字节,范围是-128~127之间
-
short是短整型,也是用于存储整数,占用2个字节,范围-32768~32767
-
int是最常用的整型,用于存储整数,占用4个字节,范围-231~231-1
-
long是长整型,用于存储较大的整数,占用8个字节,范围是-263~263-1
//表示3 byte: 00000011 short:00000000 00000011 int:00000000 00000000 00000000 00000011 long:00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000011 -
float是单精度浮点型,用于存储小数的类型,占用4个字节,不能表示精确的值
-
double是双精度浮点型,最常用的存储小数的类型,占用8个字节,不能表示精确的值,15、16位
-
boolean是布尔型,专门用于存储true和false,占用1个字节
-
char是字符型,采用Unicode字符编码格式。用于存储单个字符,占用2个字节
-
switch可以作用于那些数据类型
- byte、short、int 、char、String、枚举(Enum)上,其他类型都不允许
选择题
-
下面程序的运行结构(A)
int a,b; for(a=1,b=1;a<=100;a++) if(b>=10) break; if(b%2==1) b+=2; continue; //当前处于循环最后一句,可省略 System.out.println(a); A:6 B:5 C:7 D:8 //b 3 a 2 //b 5 a 3 //b 7 a 4 //b 9 a 5 //b 11 a 6 -
下面程序的运行结构(A)
int x = 0,y = 10; do y--; ++x; while(x<6); System.out.println(x); System.out.println(y); A:6,4 B:5,4 C:4,5 D:5,5 //y 9 x 1 //... //y 5 x 5 //y 4 x 6
吐血整理50家企业真实大数据面试题!!学长实测,真实面试!!快收藏!
文章目录
前言
第二波面试题来了,上一波是BAT超大厂面试题,这波50+企业,真的珍贵!!!收藏收藏!!
学长们都要面疯了
上一篇BAT大厂面试题链接:https://blog.csdn.net/weixin_48143996/article/details/118081994?spm=1001.2014.3001.5501
京东面试题
学长1
1)笔试部分
(1)列举几种数据倾斜的情况,并解释为什么会倾斜,以及如何解决?
(2)解释一下sql运行步骤,是否有优化空间,如果有,如何优化:
SELECT a.id, b.name FROM a LEFT OUTER JOIN b ON a.id = b.id WHERE a.dt = ‘2016-01-01’ AND b.dt = ‘2016-01-01’;
(3)已知表a是一张内部表,如何将它转换成外部表?请写出相应的hive语句
(4)用select做查询是,用哪个函数给值喂null的数据设置默认值?
(5)Hive中,建的表为压缩表,但是输入文件为非压缩格式,会产生怎样的现象或者结果?
(6)订单详情表ord_det(order_id订单号,sku_id商品编号,sale_qtty销售数量,dt日期分区)任务计算2016年1月1日商品销量的Top100,并按销量降级排序
(7)某日志的格式如下:
pin|-|request_tm|-url|-|sku_id|-|amount
分隔符为‘|-|’,
数据样例为:
张三|-|q2013-11-23 11:59:30|-|www.jd.com|-|100023|-|110.15
假设本地数据文件为sample.txt,先将其导入到hive的test库的表t_sample中,并计算每个用户的总消费金额,写出详细过程包括表结构
(8)test.log日志中内容如下左列所示,使用awk输出右列4行数据
10-3-jd-dv
2-4-jd-dv10-4-jd-dv
5-7-pv-click5-7-pv-click
36-24-pv-uv
37-24-pv-uv37-24-pv-uv
24-3-uv-mq24-3-uv-mq
(9)storm的分组策略有哪些?
学长2
1)笔试部分
(1)hiveSQL语句中select from where group by having order by的执行顺序
(2)hive中mapjoin的原理和实际应用
(3)写出你常用的hdfs命令
(4)使用Linux命令查询file1里面空行的所在行号
(5)有文件chengji.txt内容如下:
张三 40
李四 50
王五 60
请使用Linux命令计算第二列的和并输出
(6)在Linux环境下有文件/home/dim_city.txt如何加载dim_city外部表中,HDFS路径/user/dim/dim_city
(7)请列出正常工作的hadoop集群中hadoop都分别需要启动哪些进程,他们的作用分别是什么,尽可能写的全面些
(8)数据仓库的整体架构是什么,其中最重要的是哪个环节
学长3
1)笔试部分(京东金融)
1)数据按照业务含义可以分为时点数和时期数,在一般情况下,下列哪些数据属于时点数?
A.昨天的订单量B.昨天的库存量
C.昨天的点击量D.昨天的访问次数
2)About hadoop map/reduce,The right answer is?
A.reduce的数量必须大于零
B.reduce总是在所有map完成之后再执行
C.combiner过程实际也是reduce 过程
D.Mapper的数量由输入的文件个数决定
3)Hive中的元数据不包括?
A.表的名字B.表的外键
C.表的列D.分区及其属性
4)Hive中如何限制查询条数?
A、TOP B、limitC、rownumD、only
5)关于hivesql以下说法正确的是:
A.cluster by不会对字段进行排序
B.order by只保证每个reducer的输出有序,不保证全局有序
C .sortby是全局有序
D .distribute by制定规则字段,将相同组数据分发到同一reducer
6)下面sql的运行结果是什么?
Select a.id,b.name from (select id from table_id) a left semi join (select id, name from table_nm) b on 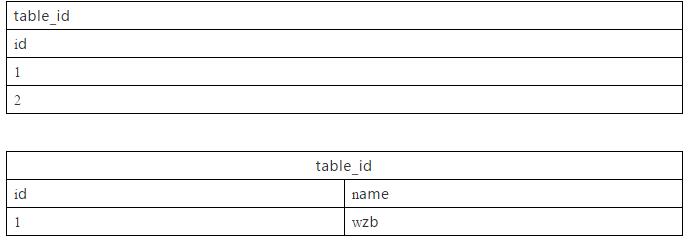
A 、(a,ok) B、(2,null) C、(1,ok & & 2,null) D、以上结果均不对
7、你处理过的最大数据量是多少?处理时是否遇到问题,采取了哪些优化的方案?
8、列举Hive几种数据倾斜的场景以及解决方案?
学长4
1)技术部分
(1)你们spark哪个版本
(2)sparkStreaming如何和Kafka对接
(3)Kafka消费过的消息如何再消费
(4)redis版本多少
(5)cdh版本多少
(6)集群怎么部署的
(7)数据倾斜怎么处理
(8)mr和spark的shuffle的区别
(9)mr环形数组怎么设置最大能设置多大
(10)redis分布式锁怎么实现
(11)rdd和dateset的区别
(12)说说Scala伴生对象
(13)解释Scala的模式匹配
(14)谈谈Scala隐士转换
(15)yarn的组件说说他们的功能
(16)spark一个excutor给多大内存
(17)spark几种部署模式还有他们的区别
(18)你运行程序是client还是cluster 为什么
(19)说出git的几个常用命名
(20)git如何切换分支
(21)对hive的理解做过哪些优化
4)算法部分
(1)用idea写快速排序
5)手写代码部分
(1)手写Spark WordCount
6)项目部分
(1)整个业务数据的流向
7)场景部分
(1)现有两张大表所有字段都得保留不能再过滤了join操作就发生oom怎么解决
(2)Session日志分析如何求出用户访问的Page路径
(3)三表的join求销量,order——id的统计(记得不了)就是三表join求统计吧
学长5
一面
1.hdfs,mr,yarn的理解
2.mr的wordcount简单描述
3.kafka快的原因,零拷贝的原理
4.redis的数据类型
5.kafka的isr队列
6.spark的运行模式,wc的简单描述
基本上是简历的东西
二面
基本上和简历无关,问的算法,我不懂,没办法整理
学长6
京东数科二面
1.最近一两年内你做过感觉最有趣或者让你记忆深刻的项目,挑一个说一说。我说的是SparkStreaming实时计算(李老师讲的在线教育那个项目,我给稍微改了改成电商项目了)。
2.有关于spark、kafka、MySQL的项目你感觉那个比较熟练一点。我回答我的是对spark比较感兴趣。
3.做这个项目用的是spark的哪个版本?
4.这个版本里用kafka用的是那种消费方式。
5.可以简单讲一下direct大概的一个设计套路。
6.如果说我每隔一百条或者一千条,记录偏移量,如果跑到八百条宕掉了,有可能重复消费,针对receiver优势能不能解决这一点?
7.如果dsteam方式去拉取reduce拉取出去,那有多少个线程从kafka里拖数据?
8.平时除了用spark比较多,用hive也不少,平时会涉及到调参优化方面有哪些?
9.你能介绍一下flume的架构或者设计。
10.用代码实现一个类似于flink水位线的机制。
11.有做过依赖调解的工作吗?比如说有没有碰到问题说引用自己一个依赖,但是在别的地方用了一个其他的依赖由于版本不统一,不能兼容该怎么办
12.最近为什么会想到说换一个工作。(离职原因)
13.你有什么想问我们的。
58面试题
学长1
1)笔试部分(基础题)
(1)请用图形的方式表示出Java运行时数据区
(2)以上哪些数据区在空间不足的情况下会抛出异常?
(3)Java工程出现内存泄露如何排查?请写出你知道的排查工具以及方法
(4)以下代码的输出结果是什么?
String str1=new StringBuilder(“58”).append(“ganji”).toString();
System.out.println(str1.intern == str1);
String str2=new StringBuilder(“ja”).append(“va”).toString();
System.out.println(str2.intern == str2);
(5)在scala中有一种函数其参数可以为参数,这样的函数称为高阶函数,请参照scala中常见map函数实现一个名为mymap的高阶函数,mymap接收两个参数值,第一个函数(x:Int)=>3*x,第二个为Int型数据。在mymap函数体内将第一个参数作用于第二个参数。
2)笔试部分(算法)
(1)给定两个只含有0和1字符的字符串,实现二进制加法。如:
String str1 = “101”
String str2 = “11”
实现binarySum(String s1,String s2),使得输入以上字符时返回字符串"1000"。
(2)给定一个整型数组array(没有重复元素),再给出一个目标值target,数组array中有两个元素的加和等于target,要求返回这两个元素的下标。如array = {1,2,4,6,3} target = 8,则返回[1,3]。
3)笔试部分(大数据相关)
(1)现有一张hive表,表里面有两个字段uuid和ts,分隔符为\\001分别表示用户唯一标识和用户来访的时间戳。
有如下需求
(a)要求计算每个用户的最后一次来访时间,用mapreduce实现(写完整的代码)
(b)你所写的代码有没有优化的空间?如果有,请写出优化方法。
(2)用spark实现WordCount。
(3)spark-streaming+kafka实现实时计算这种方案中通过什么方式保证数据的准确性?
(4)分别列举hadoop和spark中的文件缓存方式。
(5)HDFS的一致性是指什么?有几种语义?
(6)基于yarn的推测执行是怎么实现的?描述其大致算法。
QUESTION NO:1
publicclass Test1{
public static void changeStr(String str){
str=“welcome”;
}
public static void main(String[] args)(
String str=“1234”;
changeStr(str);
System. out. println(str);
}
}
输出结果:
QUESTION NO:2
public class Test2{
static boolean foo(char c){
System out print©;
return true;
}
public static void main(String[] argv){
int i=0;
for(foo(‘A’);foo(‘B’) &&(i< 2);foo(‘C’)){
i++;
foo(‘D’);
输出结果:
学长2
6.2.1 一面(学长面)
1)技术部分
(1)HashMap如何遍历。(这个忘了,百度了一下是用EntrySet)
(2)SparkStreaming窗口操作的3个时段设定分别是什么,问到倍数这块(第二轮也问到了)
2)项目部分
(1)讲了一下推荐项目怎么回事
(2)因为是招数仓这块的,所以三轮数仓都问了(第二轮的数仓问题比较偏,我写到第二轮总结里)
3)算法部分
(1)快排或冒泡排序,我讲的是快排
4)情景部分
(1)设定了一个情景,手写SQL,比较简单吧
二面
1)技术部分
(1)flatMap和map的区别
(2)A表joinB表,用MR是如何处理的(这个真没看过,百度了之后才知道的)
(3)Yarn的资源调度
(4)Hbase有put方法,那如何批量put数据进hbase里,用什么方法(这个也没答上,面试的时候想不起来了)
(5)NameNode的HA,一台挂掉之后,另一台会丢失数据吗,挂掉之前有一部分日志为更新(这个我答的是edits会保存下来,和之前的镜像一起加载,所以不会丢)
(6)问了kafka的消费速度(这个我说的几十兆每秒,群里已经发了,是1G每秒,可自由发挥)
(7)Kafka分区(我说的5个,有点多了,应该说2个或者3个吧)
(8)问了HDFS的块你们设置的是多大(我说的128M,他有疑惑,我说默认是128M,他也表示疑惑)
(9)问了Spark版本,说一直是这个版本吗(我说现在用的是2.0,之前用的1.6)
(10)Sparksql什么时候不能读到Hive的数据(这个也没答上来)
2)项目部分
(1)你们数仓之间的数据是怎么调度的(我说直接写sql,他就问说你怎么知道你的数据已经存储成功了,当时尬了一会,我说用crontab调度的,他问我这用crontab合适吗,我说那设置Oozie可以设置一段程序执行完再执行下一条程序,这块基本就聊炸了吧,我不知道hive内部数据调度还需要这样调,我以为直接读)
3)情景部分
(1)设置了一个情景,让写SQL,也相对简单吧
6.2.3 三面(项目组负责人)
(1)要招数仓和算法的,所以主要问了数仓。
(2)数仓的DM为何不由数据组来设计封装(因为我说的是指负责设计下面三层,然后由不同的业务组区数仓里调数据),你觉得是数据组封装有什么不妥吗
(3)HBase里面你们都存了具体哪些业务数据(这个我说了大概的存哪类型的数据,他问的非常深,必须说出存的具体是什么数据,我后来说每个商品的点击次数统计,实时更新,),他说这些数据我觉得存到redis或者mysql中也行呀,为什么要非要用HBase(我说HBase查的块,他说我觉得这样的数据量redis,mysql查的也不慢吧),然后问了我你认为多少的数据量适合用HBase(我说的几百万)
(4)结合你这个HBase里存储的数据,说一下你们的rowkey怎么设计的(这块说的不好,因为前面说的不好,感觉这边说就强行设计了)
学长3
1)技术部分
(1)对hadoop各组件之间通信Rpc协议了解
(2)Hadoop的读数据流程
(3)传输过程中DataNode挂掉怎么办
(4)Hbase源码
(5)Hbase构建二级索引如何保证索引与数据的一致
(6)JVM架构,堆内存,GC算法,问平时会不会调GC算法
(7)-Xms和-Xmx设置一个和设置两个而且两个设置的都是一样有什么区别吗
(8)查看当前java内存各个代的内存比例
(9)查看线程堆栈的命令
(10)查看java进程里边对象的大小,
(11)堆内存泄露怎么看,除了Dump出来用MAT还有什么简单的方法
(12)Java进程用户反馈请求服务很慢,但是代码不是你开发的你怎么排查问题,
(13)多线程,实现线程同步的方法
2)算法部分
(1)问对数据结构和算法了解吗,堆栈和链表什么的
新浪面试题
学长1
一面
1)自我介绍
叫什么名字,来自哪里,本科哪个学校,硕士哪个学校,大数据做了多长时间,对Hadoop生态圈以及Spark生态圈中的哪些技术比较了解(很简单的一句就带过了),说完大概2min
2)技术部分
(1)让我介绍下sqoop,说他没见过
我说sqoop我用的不熟,知道怎么用,可以简单地给他介绍一下。然后就说sqoop是hdfs、关系型数据、hbase它们三者之间传输数据用的,很方便。
(2)让我介绍MapReduce的运行过程
二话不说要笔要纸,手绘MapReduce从InputFormat到OutputFormat的流程,一边画图一边说。
3)项目部分
(1)让我介绍项目我都是给他要笔要纸,手绘架构图。
离线:data->flume->kafka->hdfs->hadoop/spark->mysql->前端展示
实时:data->flume->kafka->Spark Streaming->mysql->前端展示
kafka到hdfs是自定义的consumer
(2)为什么要使用kafka,可不可以用flume直接将数据放在hdfs上
我说可以用flume将数据直接放在hdfs上,但是很少有人这么干,为什么要用kafka我没有深入研究过(当时没想到咋说)
(3)让我介绍下项目中的指标,都是怎么实现的
我就挨个把我写上的项目指标说了下是什么意思,是怎么实现的(我简历上每个项目就写了几个指标,我感觉比较熟的),最后我说还有其他的很多指标,我做的就这些。
4)手写算法部分
(1)让我写链表的反转
我说链表没咋接触过,老师换个吧
(2)接下来让我手写单例
分分钟写了个双端检测单例
5)是否有问题问面试官
(1)最后说有没有问题要问他
问1:我就问他们大数据是做什么,一天的数据量有多大
答1:他给我说他们是做反垃圾的,一天的数据量上T了
问2:我就又问他们怎么定义的垃圾数据
答2:他就给我说一切影响用户体验的数据都是垃圾数据,比如说在用户的评论下面打广告之类的
然后我就说暂时没有了,他就让我在那等着了
二面
1)自我介绍
还是一面那一套
2)技术部分
(1)介绍MapReduce的运行过程
还是上面的一套。不过在我一边画图一边说的时候有人给他发消息,貌似挺着急,然后我就停下来了,他说不好意思他回个消息,我就说不着急,等您忙完咱再聊。
3)项目部分
(1)项目框架介绍
老一套
(2)问我写的公司做什么的
我说做电商的
(3)他又问具体都卖什么
我说什么都卖,就跟京东和淘宝似的,只不过规模小很多
(4)问我上家公司做大数据的有多少人
我说十多个吧
(5)问我公司在哪
我说在丰台
(6)问我一天的数据量有多大
我说APP端有十多个G,将近20多个G,浏览器端大概有四五十G
(7)又问我一天的访问量有多少
我当时心里就按照费老师说的10w个人1G的量大概算了下,说了个数
4)手写算法部分
(1)手写二分查找
二分是基于一个排好序的数组,我就问他数组排序用不用写,他说不用,然后就分分钟写完,最后我还说用不用手写MapReduce的WordCount以及Spark的WordCount的,一点问题没有。
(2)让我用shell写一个脚本,对文本中无序的一列数字排序
我说shell简单的我可以,比如说写个脚本,crontab周期性调度一下,复杂的我得查下资料,也就没写
5)是否有问题问面试官
(1)最后说他没问题了,我有什么要问他的没
我说要我不,他笑了,然后他说除了这个
(2)我当时也没想到什么问题,就问了嘴他们的集群有多大
他说成千上万台
三面
1)自我介绍
(1)自我介绍
老一套
(2)问我哪一年毕业的,公司有多少人
我实话实说,说还没有毕业就去实习了,我说二三百人
2)技术部分
(1)问我kafka用的那个版本
0.11
(2)问我ZooKeeper的常用命令
我说status(基本全忘了,就这个记得很清楚),他说还有呢,我说ls,然后我又说忘的差不多了,但是我知道它的命令和Linux命令差不多,都是那一套,那老师也就没再问。
(3)问我myisam和innodb的区别
我就按照阳哥讲的,先说了下myisam不支持主外键,不支持事物,它是表锁,不适合高并发,而innodb则不是,然后他又问我还有没,我说了解就这么多,他也没再问
(4)他又问我一句如果单线程访问,myisam和innodb那个性能好一点
我说myisam吧,因为它不支持事物,要快一些
然后他又问我一个问题,我没答上来,我忘了那个问题是啥了
(5)问我redis常用的命令
我顿了一两秒甩了一句keys*,他笑着说可以可以
(6)问我为什么要用redis
我就说redis是内存型数据库,以前访问量没那么大的时候关系型数据库完全可以胜任,但是在高并发的情况下访问量一大,关系型数据就不行了,所以就有了redis
(7)问我了解hbase不
我说了解不多,就知道它是一个非关系型数据库,它也就没再问
(8)然后问我机械硬盘和SSD硬盘的差别了解不
我说SSD读写快,然后他说是,他又问我底层了解不,为什么SSD读写快,我没答出来,他又说从硬盘读取数据首先要干什么,我说寻址(然后突然一下子好像明白了,就跟他扯了扯)
(9)然后他又问我机械硬盘每秒读取次数多少知道不
我说我不知道,没研究这么深,但是我说我知道我们大数据读取数据的时候寻址不超过10ms(我当时心里这样想的,这些东西我没接触过,我要往大数据上靠,要引导他去问我大数据的东西),结果他说知道这个能算出来机械硬盘1秒能读多少次,然后我好想明白了,就1s/10ms呗,他说是,也就100来次
3)项目部分
(1)问我一天的数据量有多大
我还是按照原来的那个说的,他说不到100G单机就能搞定吧,我说公司就这么定的,然后尴尬不失礼貌地笑了笑(跟尽际老师学的)
然后就看着简历问了一些问题
(2)问我Azkaban一天调度多少个任务
我说三五百个吧
(3)然后他问我这么一个问题,他说你做这些项目需要埋点日志的对吧,然后说如果后台的人不愿意给你加这个埋点,嫌麻烦,你怎么办
我愣了一会,随口说了句,吃顿饭,那老师当场笑了,然后他说这算是个办法,他又说如果这个人没时间,没工夫跟你吃饭,你怎么办,我当时傻笑了两下,没回答。
4)场景题,手写SQL
场景1:是这样的,一张表三个字段,分别是学生名字、科目名字、科目得分,让我用sql把总分最高的找出来
我说我数据掌握不太好,试着写写。
我用了个子查询,先按学生分组,然后求每个学生的总分数
然后在外部查询中求最大的
我一开始在子查询中直接对用聚合函数求的sum_score排序了,他看了以后说能这么做么,我说我忘了,然后我又说子查询不行的话咱们就在外部查询排序呗,然后反问他可以吧,他说可以的
5)平时学习习惯
CSDN、博客园、Apache官网
6)是否有问题问面试官
(1)最后他说他差不多了,我有什么要问他的没
我问了下他业务方面的一些,也没想到啥,随便问的
(2)最后我又问他,他刚才问我埋点日志后台的人不给加怎么办
他给我说这个需要各个组协调好,不然别干活了,就扯了一会
四面
1)自我介绍
老一套
2)技术部分
(1)介绍MapReduce的运行流程
本来我说给他手画的,他不让,说介绍就行。我就从InputFormat开始到OutputFormat给他说了一遍
然后他就说按着简历来问
(2)让我说下myisam和innodb的区别
老一套
(3)然后看着简历说你知道HDFS的存储过程,我说需不需要我说一下
然后我就把海哥hadoop存储过程那几个图给他说了一遍
3)项目部分
让我介绍下我写的三个项目都是干啥的,我就没画图,给他介绍了下每个项目具体是做啥的,怎么做的(什么领导层要看指标啊啥的)
4)平时学习习惯
还是CSDN、博客园、Apache官网,说都是晚上和周六周天自己学的
(1)问我喜不喜欢技术
我说很喜欢,我说了以后他说为什么喜欢,我就说我搭建起来一个集群很有成就感,能在我女朋友面前炫耀一番。。。
(2)问我喜欢跟人打交道还是喜欢跟机器打交道
我按照实际情况说了下,说比较宅,比较喜欢跟机器打交道,还说从小就比较喜欢玩小霸王游戏机之类的。。。
五面HR
教训:和HR接触不要激动,不要表现的很倾向来她们公司,因为后面工资可能不好谈,要不到理想的价位。
1)自我介绍
老一套
2)人事高频问题
(1)有没有别的offer,面试几家了
我说这周一开始投的简历,在等百度的offer,上午面试的58到家,但是58到家做Hive比较多,我了解不多
(2)问我什么时候辞职的
我说十一月初
(3)问我为什么现在才找工作
说回家一趟,大半年没回家了,这两天刚回来
(4)上家薪资多少
我就按照我心里的想法和马老师说的大概说了个数
然后说什么他们很严格,如果不行会马上辞退啥的,最后说看我能力可以,问我啥时候可以上班,让我准备下薪资流水和离职证明
学长2
1)技术部分
(1)Kafka吞吐量怎么优化
(2)Hive底层,SQL、表关联、窗口函数、聚合函数、一堆场景题
(3)Join对应的MR
(4)一张小表Join一张大表 在MR上怎么JOIN
(5)map()阶段聚合
(6)spark job流程
2)项目部分
(1)上个月用户访问次数最大的IP
(2)topN
(3)日活实时统计
(4)SparkStreaming的活动窗口大小,数据重复怎么办?
(5)数据仓库ODS-》DWD 用什么写的脚本?
3)算法部分
(1)二分查找
(2)字符串反转
学长3
1)技术部分
(1)hdfs的小文件处理。
(2)Hive调优,数据倾斜问题
(3)spark任务提交流程
(4)mr任务提交yarn流程
(5)HDFS的读写流程,Shuffle流程,Shuffle过程的归并排序具体怎么做。
(6)是否用了currenthashmap,高并发问题就高枕无忧了
(7)线程池了解吗?
(8)怎么判断一个kafka消费者挂了
(9)了解redis,mysql吗,mysql的索引了解吗?
(10)select。。。for update是什么锁?
(11)mysql底层文件存储
(12)读过哪些框架的源码?
(13)JVM底层原理
(14)Spark的distinct()算子底层
(15)布隆过滤器
(16)zookeeper的作用,zookeeper单独的事务,nginx的作用,只做收集数据吗?
(17)说一下kafka的架构,描述hw leo,kafka的优化,怎么做幂等,你们做业务幂等性,为什么消费者怎么看到hw。消息的一致性能解决什么问题,kafka事务怎么理解。
(18)Spark的shuffle过程
(19)hbase怎么预分区
(20)redis有多少曹,redis的持久化,你们在项目中怎么用redis的,如何防止雪崩。
(21)mysql update一条语句,需要走那些流程。
(22)了解es吗?
(23)yarn执行一个任务用了多少core
(24)produce给kafka的一个topic发送消息,topic的一个分区挂掉,他的副本也全部挂掉,这个topic还能用吗
(25)有没有用javaapi去读kafka的数据
(26)spark读取kafka数据的方式?
(27)hive的内表和外表的区别,hive为什么要做分区,hive的元数据存在哪?
(28)列式存储和关系型数据库的区别
(29)java中正则表达式用到哪些类?
(30)unlock和synchronzed的区别?
(31)编写sparksql的步骤?
2)项目部分
(1)写实时项目遇到了哪些问题
(2)拉链表的创建,连续三天登陆
(3)你们公司日活,月活,留存多少?你们团队多少人?
(4)为什么加最后一层flume,不能直接flume到hdfs吗?
(5)分析指标,对app有什么影响。提升了百分之多少?
(6)有没有访问kafka的所有topic的权限
(7)有没有做Hive表的权限管理。
3)算法部分
(1)归并排序
(2)删除单链表的一个节点
4)情景题:
(1)Spark:如果消费Kafka中的数据时,某个分区内数据因为种种原因丢失了一条(也可理解成因为某些条件被过滤了),现在需要重新把这条数据纳入计算结果中。怎么解决?
(2)a left join b on a.id = b.id and b.age = 20
a left join b on a.id = b.id where b.age = 20
的结果有什么区别
5)平时学习习惯
(1)你最近在研究什么?
学长4
1、介绍一下项目,你主要负责哪部分,最精通什么
2、hdfs读写机制,DataNode怎么保证数据可靠性,原理是什么(答副本,说不对)
2、MR的过程详细说一下
3、使用MR写出join过程
4、日常开发哪里用到java多线程,怎么写
5、说一下并发和同步,单例必须加同步锁么?为什么
6、说一下MR的底层源码,你研究了哪部分?
7、说说spark的底层源码吧
搜狐面试题
1)笔试部分
(1)hdfs原理,以及各个模块的职责
(2)MR的工作原理
(3)shell脚本里如何检查文件是否存在,如果不存在该如何处理?Shell里如何检查一个变量是否是空?
(4)Shell脚本里如何统计一个目录下(包含子目录)有多少个java文件?如何取得每一个文件的名称(不包含路径)
(5)哪个程序同城与nn在一个节点启动?哪个程序和DN在一个节点?如果一个节点脱离了集群应该怎么处理?
(6)列出几个配置文件优化hadoop,怎么做数据平衡?列出步骤
(7)有序数组的二分查找
(8)编写快速排序(QuickSort)或者归并排序(MergeSort)
(9)整数数组寻找满足条件的点对
(10)给定整数数组A[N],求两个下标(i, j)且0<=i<j=N-1, 注意:数组中有正整数或者负整数或者0。
(11)该(i, j),使得A[i] + A[i] + … + A[j] 最大
(12)要求:时间复杂度尽量低,空间复杂度O(1)
(13)请:1.写出思路的简要描述 2.用你熟悉的语言,定义函数,完成编码和测试用例
2)项目部分
搜狐面试的小伙伴注意,广告变现的业务,会问到flume监控的问题,必问,二面理论比较强,居然问缓慢变化维,我问一下数据仓库有拉链表么?
360面试题
学长1
1)技术部分
(1)常用的linux命令,shell的awk、sed、sort、cut是用来处理什么问题的?
(2)Hive有自带的解析json函数,为什么还要自定义UDF、UDTF
(3)Json的格式,json存的具体数据
(4)MapReduce过程
(5)Shuffle源码?其中reduce的分区是怎么设置的,针对每个key,怎么把它放到对应的分区中?
(6)你了解的hadoop生态圈的框架,及其大概在怎样的一个位置?
(7)mapreduce、tez和spark的区别?
(8)Spark读取文件如果内存不够的话,怎么处理?
2)手写部分
(1)自己写过MapReduce吗?怎么写的?
(2)最近七天连续三天活跃用户怎么实现的?手写一个各区域top10商品统计程序?
(3)平时遇到的数据倾斜的问题,怎么解决的?
(4)大表join大表怎么解决?
(5)每一层大概有多少张表?表的字段也需要记
(6)UDF、UDTF、UDAF区别?
3)算法部分
(1)二叉树的前中后序遍历?
(2)排序算法了解过吗?
(3)快排的时间空间复杂度?快排原理
(4)冒泡的时间空间复杂度?原理
4)情景部分
写一个程序获取ip(123.123.123.123)的地理位置信息,读取配置文件,返回结果ip \\t loc_nation \\t loc_pro \\t loc_city
ip_num_start ip_num_end loc_nation loc_pro loc_city ISP
1910946943 1910946945 中国 辽宁 沈阳 联通
1910946947 1910946949 中国 辽宁 沈阳 联通
1910946950 1910946950 中国 辽宁 鞍山 联通
1910946951 1910946953 中国 辽宁 沈阳 联通
1910946959 1910946965 中国 辽宁 沈阳 联通
1910946966 1910946966 中国 辽宁 盘锦 联通
1910946967 1910946985 中国 辽宁 沈阳 联通
1910946986 1910946986 中国 辽宁 大连 联通
1910946995 1910947033 中国 辽宁 沈阳 联通
sc.read(“input/.txt”)
.mapPartition(data=>{
val splitdata = data.split("\\t")
ip_num_start = splitdata(0)
ip_num_end = splitdata(1)
loc_nation = splitdata(2)
loc_pro = splitdata(3)
loc_city = splitdata(4)
ISP = splitdata(5)
(ip_num_start, ip_num_end, loc_nation, loc_pro, loc_city)
})
.map(data=>{
if(ip ){
(data.loc_nation,data.loc_pro,data.loc_city)
}
})
针对上面代码的一些问题:
(1)上面那段代码中,如果文件是一个很大的文件,spark读取的时候用一个任务处理(单机),怎样可以让它读取的效率更高一点?
(2)MapPartition的原理是什么?
学长2
1、常用的linux命令,shell的awk、sed、sort、cut是用来处理什么问题的?
2、hive有自带的解析json函数,为什么还要自定义UDF、UDTF
3、json的格式,json存的具体数据
4、写一段代码:
写一个程序获取ip(123.123.123.123)的地理位置信息,读取配置文件,返回结果ip \\t loc_nation \\t loc_pro \\t loc_city
ip_num_start ip_num_end loc_nation loc_pro loc_city ISP
1910946943 1910946945 中国 辽宁 沈阳 联通
1910946947 1910946949 中国 辽宁 沈阳 联通
1910946950 1910946950 中国 辽宁 鞍山 联通
1910946951 1910946953 中国 辽宁 沈阳 联通
1910946959 1910946965 中国 辽宁 沈阳 联通
1910946966 1910946966 中国 辽宁 盘锦 联通
1910946967 1910946985 中国 辽宁 沈阳 联通
1910946986 1910946986 中国 辽宁 大连 联通
1910946995 1910947033 中国 辽宁 沈阳 联通
sc.read(“input/.txt”)
.mapPartition(data=>{
val splitdata = data.split("\\t")
ip_num_start = splitdata(0)
ip_num_end = splitdata(1)
loc_nation = splitdata(2)
loc_pro = splitdata(3)
loc_city = splitdata(4)
ISP = splitdata(5)
(ip_num_start, ip_num_end, loc_nation, loc_pro, loc_city)
})
.map(data=>{
if(ip ){
(data.loc_nation,data.loc_pro,data.loc_city)
}
})
针对上面代码的一些问题:
1、 上面那段代码中,如果文件是一个很大的文件,spark读取的时候用一个任务处理(单机),怎样可以让它读取的效率更高一点?
答:提高并行度?
2、 MapPartition的原理是什么?
5、mapreduce过程
6、自己写过mapreduce吗?怎么写的?
7、shuffle源码?其中reduce的分区是怎么设置的,针对每个key,怎么把它放到对应的分区中?
8、你了解的hadoop生态圈的框架,及其大概在怎样的一个位置?
9、mapreduce、tez和spark的区别?
10、spark读取文件如果内存不够的话,怎么处理?
11、最近七天连续三天活跃用户怎么实现的?手写一个各区域top10商品统计程序?
12、平时遇到的数据倾斜的问题,怎么解决的?
13、大表join大表怎么解决?
14、每一层大概有多少张表?表的字段也需要记
15、UDF、UDTF、UDAF区别?
16、二叉树的前中后序遍历?
17、排序算法了解过吗?
18、快排的时间空间复杂度?快排原理
19、冒泡的时间空间复杂度?原理
学长3
1、常用的linux命令,shell的awk、sed、sort、cut是用来处理什么问题的?
作用:— 截取文本字符串,获取某些内容
— 写脚本
2、hive有自带的解析json函数,为什么还要自定义UDF、UDTF
3、json的格式,json存的具体数据
4、写一段代码:
写一个程序获取ip(123.123.123.123)的地理位置信息,读取配置文件,返回结果ip \\t loc_nation \\t loc_pro \\t loc_city
ip_num_start ip_num_end loc_nation loc_pro loc_city ISP
1910946943 1910946945 中国 辽宁 沈阳 联通
1910946947 1910946949 中国 辽宁 沈阳 联通
1910946950 1910946950 中国 辽宁 鞍山 联通
1910946951 1910946953 中国 辽宁 沈阳 联通
1910946959 1910946965 中国 辽宁 沈阳 联通
1910946966 1910946966 中国 辽宁 盘锦 联通
1910946967 1910946985 中国 辽宁 沈阳 联通
1910946986 1910946986 中国 辽宁 大连 联通
1910946995 1910947033 中国 辽宁 沈阳 联通
sc.read(“input/.txt”)
.mapPartition(data=>{
val splitdata = data.split("\\t")
ip_num_start = splitdata(0)
ip_num_end = splitdata(1)
loc_nation = splitdata(2)
loc_pro = splitdata(3)
loc_city = splitdata(4)
ISP = splitdata(5)
(ip_num_start, ip_num_end, loc_nation, loc_pro, loc_city)
})
.map(data=>{
if(ip ){
(data.loc_nation,data.loc_pro,data.loc_city)
}
})
针对上面代码的一些问题:
1、 上面那段代码中,如果文件是一个很大的文件,spark读取的时候用一个任务处理(单机),怎样可以让它读取的效率更高一点?
答:提高并行度?
2、 MapPartition的原理是什么?
5、mapreduce过程
6、自己写过mapreduce吗?怎么写的?
7、shuffle源码?其中reduce的分区是怎么设置的,针对每个key,怎么把它放到对应的分区中?
8、你了解的hadoop生态圈的框架,及其大概在怎样的一个位置?
9、mapreduce、tez和spark的区别?
10、spark读取文件如果内存不够的话,怎么处理?
Spark并不是完全基于内存,当内存不够的话,会将一部分数据进行落盘
11、最近七天连续三天活跃用户怎么实现的?手写一个各区域top10商品统计程序?
12、平时遇到的数据倾斜的问题,怎么解决的?
13、大表join大表怎么解决?
1.空KEY过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
2.空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以把a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。
14、每一层大概有多少张表?表的字段也需要记
Ods:start_log,event_log
Dwd:事件日志基础表、11张事件表、启动日志表
Dws:日周月活表、每日新增、用户留存、沉默用户、本周回流、流式用户、最近3周连续活跃的用户、最近7天内连续3天活跃用户数等指标+宽表
Ads:对应dws
15、UDF、UDTF、UDAF区别?
16、二叉树的前中后序遍历?
17、排序算法了解过吗?
18、快排的时间空间复杂度?快排原理
19、冒泡的时间空间复杂度?原理
小米面试题
学长1
大家可以投一下小米的推荐算法。
一面:问两个有序大数组合并成一个数组的最佳方法,还有快排,问了所有项目。
二面:是问推荐算法的业务实现,还有如果你自己做一个推荐,你会怎么选择模型、算法。
三面:数据结构的查找,新增,删除的时间复杂度、还有各种数学问题,然后写了二叉树的查找、还有根据算法题写了一个递归,差不多就这样就过了
1)技术部分
(1)Java8的新特性?
(2)Java8的hashMap为什么采用数组+链表+红黑树?
(3)垃圾回收的算法,CMS和G1的比较,用什么监控JVM?
(4)Kafka对接sparkstreaming?
(5)线程池好处是什么,什么场合用?
(6)zookeeper的选举机制,以及我们还可以用zookeeper做些什么?
(7)flume采集数据的优缺点,还有什么可以代替它,也可以通过自己公司的业务情况自己开发。
(8)spark streaming和storm,Flink的比较,以及各自的优势?
(9)怎么从10亿条数据中计算TOPN?
学长2
面试地点:小米6期
面试时长:共2个半小时
一面(下午3点30分到4点10分):
自我介绍
Spark Streaming和Flink区别
MR和Spark引擎的区别
引起Shuffle的算子有哪些?
Flink+Kafka保证精确一次消费相关问题(记不清了):我说的两阶段提交
Zookeeper的应用
Java中HashMap和TreeMap区别(记不清是不是这个问题了)
SparkStreaming保证精确一次消费
给出数据倾斜解决方案
被问到任务划分的源码(DAGScheduler划分)
给一个整形数组,找出最大的连续子集
给一个数组,一个值,找出第一次出现的两个数的和等于这个值的下标并存入List中(好像Letcode第一道题,双层for循环)
Spark中划分宽窄依赖的底层原理:只说shuffle划分stage没用
二面(下午4点25分到5点10分):
自我介绍
手写SQL:(看着你写,注意)
表t1
页面id 点击 浏览 日期
page_id view visiable date
00/10/1
10/10/1
…
表t2
品类id 页面id
border_id page_id
a0
b 1
a 3
a4
b 0
…
找出各个border_id的view,visable个数 (join group by where count(if)…)
JVM内存和调优
Redis数据类型,事务(凭印象说的multi,exec,watch),持久化方式和区别,redis中zset底层实现是什么?
Redis问的很细
跑任务用的什么(Azkaban)?定点定时跑还是周期性跑?
手画星座模型
业务过程,维度,事实
手写单例模式
实时统计过的指标
如何从0到1搭建数据平台?
三面(下午5点10分到5点30分):
自我介绍
B+树和B树底层,与二叉树的区别(手画) 不太会
给你两个矩阵(txt文件,以\\t分隔),让你用MapReduce实现两个矩阵相加并输出(每行打行号标记)
… …
四面:(下午5点35分到5点50分)
了解上家公司情况
入职相关事情
学长3
笔试:
1、链表两两反转(搞定)
2、验证二叉树是否符合以下条件:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。(我说我对二叉树不咋熟悉)
3、求一个序列中的最长上升子序列的长度(搞定)
面试:
1、flink的状态后端
2、说说rockdb状态后端,rockdb做状态后端有啥好处和缺点
3、说说hdfs状态后端,它是怎么存储的状态的
4、说说flink中的keystate包含哪些数据结构
5、redis常用数据类型
6、sparkstreaming是如何处理数据积压的,说说反压机制的令牌桶算法
7、简单谈谈jvm辣鸡处理的算法,了解多少,分别是什么
8、谈谈jvm内存的分布,方法区中都存些什么
学长4
第一部分 语言基础:
1:String类可以被继承吗?为什么?
2:HashMap,HashTable,ConcurrentHashMap的异同?
3:Java单例模式 Scala语言如何实现?
4:实现快速排序算法
5:设计4个线程,其中两个线程每次对j增加1,另外两个线程对j每次减少1。写出程序。
第二部分 Hive
1:把每科最高分前三名统计出来 --成绩表Score(student_name,student_no,subject_no,score)
2:找出单科成绩高于该科平均成绩的同学名单(无论该学生有多少科,只要有一科满足即可) --成绩表Score(student_name,student_no,subject_no,score)
3:一个表 test(name,price),构建一个新表,将name相同的,price所有价格合并到一个字段里面
4:如何将题3中price合并后的prices 字段再拆分为多条记录?
第三部分 Spark
1:用户访问日志文件有两列,分别为日期和用户ID:(date,user_id),使用Spark统计每天的访问的记录数和用户数。
2:在spark中,代码的执行位置:
dstream.foreachRDD { rdd =>
val where1 = “执行位置1”
rdd.foreachPartition { partition =>
val where2= “执行位置2”
partition.foreach { record =>
val where2 = “执行位置3”
}
}
}
学长5
1月10号:
面试地点:小米6期
面试时长:共2个半小时
一面(下午3点30分到4点10分):
自我介绍
Spark Streaming和Flink区别
MR和Spark引擎的区别
引起Shuffle的算子有哪些?
Flink+Kafka保证精确一次消费相关问题(记不清了):我说的两阶段提交
Zookeeper的应用
Java中HashMap和TreeMap区别(记不清是不是这个问题了)
SparkStreaming保证精确一次消费
给出数据倾斜解决方案
被问到任务划分的源码(DAGScheduler划分)
给一个整形数组,找出最大的连续子集
给一个数组,一个值,找出第一次出现的两个数的和等于这个值的下标并存入List中(好像Letcode第一道题,双层for循环)
Spark中划分宽窄依赖的底层原理:只说shuffle划分stage没用
二面(下午4点25分到5点10分):
自我介绍
手写SQL:(看着你写,注意)
表t1
页面id 点击 浏览 日期
page_id view visiable date
00/10/1
10/10/1
…
表t2
品类id 页面id
border_id page_id
a0
b 1
a 3
a4
b 0
…
找出各个border_id的view,visable个数 (join group by where count(if)…)
JVM内存和调优
Redis数据类型,事务(凭印象说的multi,exec,watch),持久化方式和区别,redis中zset底层实现是什么?
Redis问的很细
跑任务用的什么(Azkaban)?定点定时跑还是周期性跑?
手画星座模型
业务过程,维度,事实
手写单例模式
实时统计过的指标
如何从0到1搭建数据平台?
三面(下午5点10分到5点30分):
自我介绍
B+树和B树底层,与二叉树的区别(手画) 不太会
给你两个矩阵(txt文件,以\\t分隔),让你用MapReduce实现两个矩阵相加并输出(每行打行号标记)
… …
四面:(下午5点35分到5点50分)
了解上家公司情况
入职相关事情
学长6
笔试:
语言基础:
1:String类可以被继承吗?为什么?
2:HashMap,HashTable,ConcurrentHashMap的异同?
3:Java单例模式 Scala语言如何实现?
4:实现快速排序算法
5:设计4个线程,其中两个线程每次对j增加1,另外两个线程对j每次减少1。写出程序。
Hive
1:把每科最高分前三名统计出来 --成绩表Score(student_name,student_no,subject_no,score)
2:找出单科成绩高于该科平均成绩的同学名单(无论该学生有多少科,只要有一科满足即可) --成绩表Score(student_name,student_no,subject_no,score)
3:一个表 test(name,price),构建一个新表,将name相同的,price所有价格合并到一个字段里面
4:如何将题3中price合并后的prices 字段再拆分为多条记录?
Spark
1:用户访问日志文件有两列,分别为日期和用户ID:(date,user_id),使用Spark统计每天的访问的记录数和用户数。
2:在spark中,代码的执行位置:
dstream.foreachRDD { rdd =>
val where1 = “执行位置1”
rdd.foreachPartition { partition =>
val where2= “执行位置2”
partition.foreach { record =>
val where2 = “执行位置3”
}
}
}
面试:
1.Scala中以下几个的区别
-
spark UDF与 hive UDF区别
-
spark广播出去的信息可以修改吗?比如我广播的是配置信息,怎么改呢。
顺丰面试题
学长1
第一面是做实时推荐同事,针对项目和知识点来问,特别喜欢问spark,因为他用kafka和spark多,认真准备一下这关好过。
第二面是大数据这块的女总监,光跟你怼spark,全是细节,细致到你传了那些参数
学长2
1)技术部分
(1)Kafka原理,数据怎么平分到消费者
(2)flume hdfs sink小文件处理
(3)flink与spark streaming的差异,具体效果
(4)spark背压机制具体原理实现
(5)spark执行内存如何分配,执行任务时给多大内存
(6)sparksql做了哪些功能
(7)讲一下Flink
(8)状态编程有哪些应用
(9)端到端exactly-once如何保证
(10)flink checkpoint机制
(11)Yarn调度策略
2)项目部分
(1)离线指标、数据量、用户量
(2)介绍一下实时项目,哪些指标,怎么算的
(3)SparkStreaming遇到什么问题,如何解决
(4)sparkstreaming实现什么指标,怎么算的
(5)实时当天日活怎么累加
(6)集群规模
(7)一天的指标会用SparkSQL吗
(8)Spark手动设置偏移量,如果数据处理完后,offset提交失败,造成重复计算怎么办
(9)项目中ES做了哪些工作、es实现原理、es倒排索引怎么生成
(10)任务调度
(11)讲一下Hbase、项目中哪些地方用了Hbase、Hbase写入流程、不同列族之间文件怎么划分
(12)kerberos安全认证过程
学长3
问一下,数仓建模有没有更详细的文档说明?
还有hbase的rowkey在生产环境下怎么设计?
三个原则 唯一性 长度原则 散列原则
hbase表做预分区 评估半年到一年的数据量
一年之内不能自动切分 (10g数据)
求出分区数量
最后再设计自己的分区键值 01| 02| 03|
rowkey前缀(分区号) 01_ 02_ 03_
后面拼接常用字段 或者 时间戳
在一个分区内 先查询什么字段,就要把那个字段拼接到前面 分区号_要查询的字段_时间戳(保证唯一性)
电商 分区号—订单号-时间戳
OPPO面试题
学长1
OPPO -实时处理工程师。一面试官陈泉,他拿了多个人的简历,边翻边问。
1)技术部分
(1)sparkstreaming消费方式及区别,spark读取hdfs的数据流程
(2)Kafka高性能
(3)Hive调优,数据倾斜
(4)Zookeeper怎么避免脑裂,什么是脑裂。
(5)Redis的基本类型,并介绍一下应用场景
(6)最后会问一些linux常用命令,比如怎么查进程,查io运行内存等。还真有人问啊
2)项目部分
(1)Hive的分层设计
(2)还有一些flume和kafka的问题,为什么要把离线和实时搞在一起,可以做成两套系统。
学长2
1.介绍你做的所有项目
2.在项目中你负责什么
3.数仓的数据量是多少
4.MapReduce的shuffle过程
5.Spark与Flink的区别
6.平常会自己去学一些技术吗
7.你们公司的大数据组的人员配置
8.你为什么离职
9.工作中遇到哪些困难
10.怎么使用Redis实现分布式锁
11.Zookeeper的HA原理?
12.两个业务有关联,某个业务的数据量有可能暴增崩溃,怎么保证另外的业务数据不受影响?
13.MapReduce怎么去实现Hive中的mapjoin?
14.sparkStreaming中Kafka的offset保存到MySQL中去实现的精准一次性消费,假如业务逻辑处理完,在提交offset时程序崩溃,处理完的数据怎么解决?
学长3
1、讲一讲什么是CAP法则?Zookeeper符合了这个法则的哪两个?
答:强一致性、高可用性、分区容错性;z
以上是关于3.21面试题的主要内容,如果未能解决你的问题,请参考以下文章