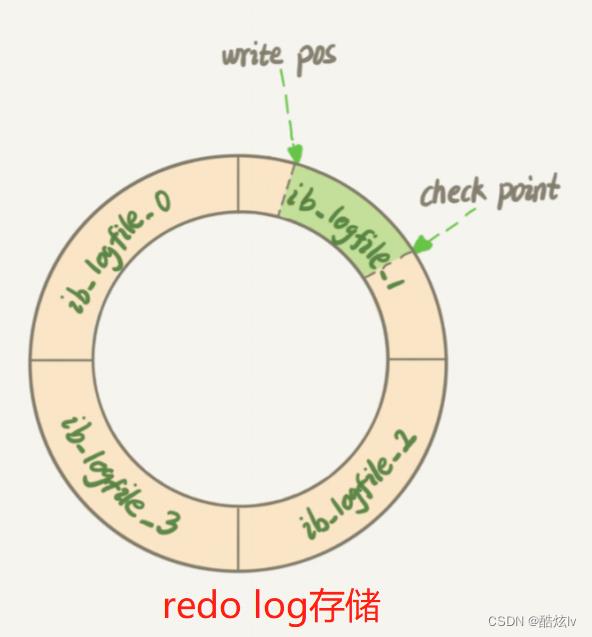
Mysql内建的复制功能是构建大型,高性能应用程序的基础。将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其他主机(slave)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接到主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
3个线程:
首先,slave开始一个工作线程-----I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。binlog dump process 从master的二进制日志中读取事件,如果已经跟上了master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其他Mysql的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制-----复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
https://dev.mysql.com/doc/refman/5.6/en/replication-implementation-details.html