面试官说,听说你了解Redis,手写一个LRU算法吧
Posted Java小果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官说,听说你了解Redis,手写一个LRU算法吧相关的知识,希望对你有一定的参考价值。
LRU是什么
缓存命中率是缓存系统的非常重要指标,如果缓存系统的缓存命中率过低,将会导致查询回流到数据库,导致数据库的压力升高。
LRU(Least Recently Used) 即最近最少使用的数据需要被淘汰,属于典型的内存淘汰机制。也就是说,内存中淘汰那些最近最少使用的数据。
LRU算法实现思路
根据LRU算法的理念,我们需要:
一个参数来作为容量阈值
一种数据结构来存储数据,同时希望插入、读取、删除操作的时间复杂度都是O(1)。
所以,我们用到的数据结构是:Hashmap+双向链表。
1.利用hashmap的get、put方法O(1)的时间复杂度,快速取、存数据。
2.利用doublelinkedlist的特征(可以访问到某个节点之前和之后的节点),实现O(1)的新增和删除数据。
如下图所示:
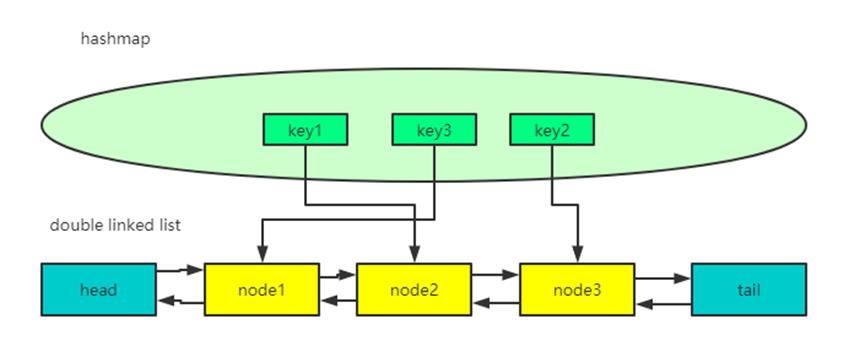
LRU的简单实现
节点node,存放key、val值、前节点、后节点
class Node
public int key;
public int val;
public Node next;
public Node previous;
public Node()
public Node(int key, int val)
this.key = key;
this.val = val;
双向链表,属性有size、头节点、尾节点。
提供api:
- addFirst(): 头插法入链表
- remove(): 删除最后一个节点
- remove(Node node):删除特定节点
- size():获取链表长度
class DoubleList
private int size;
private Node head;
private Node tail;
public DoubleList()
this.head = new Node();
this.tail = new Node();
size = 0;
head.next = tail;
tail.previous = head;
public void addFirst(Node node)
Node temp = head.next;
head.next = node;
node.previous = head;
node.next = temp;
temp.previous = node;
size++;
public void remove(Node node)
if(null==node|| node.previous==null|| node.next==null)
return;
node.previous.next = node.next;
node.next.previous = node.previous;
node.next=null;
node.previous=null;
size--;
public void remove()
if(size<=0) return;
Node temp = tail.previous;
temp.previous.next = temp.next;
tail.previous = temp.previous;
temp.next = null;
temp.previous=null;
size--;
public int size()
return size;
LRU算法实现类
API
- get(int key): 为null返回-1
- put(int key, int value)
- 若map中有,删除原节点,增加新节点
- 若map中没有,map和链表中新增新数据。
public class LRUCache
Map<Integer,Node> map;
DoubleList cache;
int cap;
public LRUCache(int cap)
map = new HashMap<>();
cache = new DoubleList();
this.cap = cap;
public int get(int key)
Node node = map.get(key);
return node==null? -1:node.val;
public void put(int key, int val)
Node node = new Node(key,val);
if(map.get(key)!=null)
cache.remove(map.get(key));
cache.addFirst(node);
map.put(key,node);
return;
map.put(key,node);
cache.addFirst(node);
if(cache.size()>cap)
cache.remove();
public static void main(String[] args)
//test, cap = 3
LRUCache lruCache = new LRUCache(3);
lruCache.put(1,1);
lruCache.put(2,2);
lruCache.put(3,3);
//<1,1>来到链表头部
lruCache.put(1,1);
//<4,4>来到链表头部, <2,2>被淘汰。
lruCache.put(4,4);
LRU应用场景
- 底层的内存管理,页面置换算法
- 一般的缓存服务,memcache\\redis之类
- 部分业务场景
LRU 算法劣势在于对于偶发的批量操作,比如说批量查询历史数据,就有可能使缓存中热门数据被这些历史数据替换,造成缓存污染,导致缓存命中率下降,减慢了正常数据查询。
扩展
1.LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
LRU-K具有LRU的优点,同时还能避免LRU的缺点,实际应用中LRU-2是综合最优的选择。由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多。
2.Two queue
Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。 当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
新访问的数据插入到FIFO队列中,如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;如果数据在FIFO队列中再次被访问到,则将数据移到LRU队列头部,如果数据在LRU队列中再次被访问,则将数据移动LRU队列头部,LRU队列淘汰末尾的数据。
3.MySQL InnoDB LRU
将链表拆分成两部分,分为热数据区,与冷数据区。
- 访问数据如果位于热数据区,与之前 LRU 算法一样,移动到热数据区的头结点。
- 插入数据时,若缓存已满,淘汰尾结点的数据。然后将数据插入冷数据区的头结点。
- 处于冷数据区的数据每次被访问需要做如下判断:
若该数据已在缓存中超过指定时间,比如说 1 s,则移动到热数据区的头结点。
若该数据存在在时间小于指定的时间,则位置保持不变。
对于偶发的批量查询,数据仅仅只会落入冷数据区,然后很快就会被淘汰出去。热门数据区的数据将不会受到影响,这样就解决了 LRU 算法缓存命中率下降的问题。
阿里Leader叫我手写LRU,我写完淡淡地说我还能手撕LFU呢!!!
前言
就目前情况而言,只要你简历上敢写Redis,大厂面试官就一定敢叫你手写LRU,但对于手写LFU相对而言还是比较少见,但如果,你写完LRU还能对面试官说你还掌握LFU算法,那么即使你写不出来只说出个大概,那么在面试官心中也是大大加分的!!!
那么,今天就让我来帮助大家掌握这个高频考点吧!!!
温馨提示:主要理解思路在注释中
注释有点浅,大家可以复制到自己的编译器中好好看看
大厂面试题专栏,里面有更多更优质的大厂面试题,可以来看一看瞅一瞅哦!!!
手撕LRU
LRU总体上还是比较简单的,只要你掌握概念,即使长时间没写也还能记得!
LRU总体上思路:最近使用的放在最近的位置(最左边),那么保证了这个最少使用的就自然而然离你远了(往右边去了)
所以说使用双向链表来实现,但光有这还不够,我们还需要使用Map来将key映射到对应的节点
在双向链表中,使用虚拟头节点和尾节点来作为节点,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
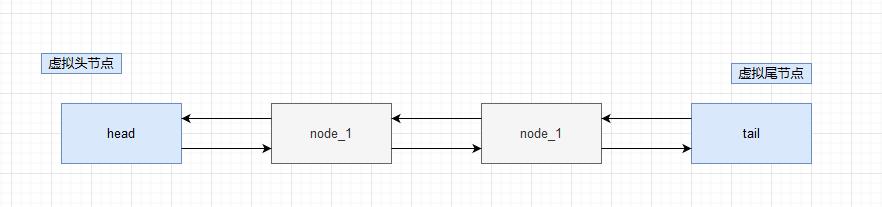
public class Main {
//定义双向链表
class DoubleLinkedList {
private int key;
private int value;
private DoubleLinkedList next;
private DoubleLinkedList prev;
public DoubleLinkedList() {
}
public DoubleLinkedList(int key, int value) {
this.key = key;
this.value = value;
}
}
//虚拟头节点,尾节点
private DoubleLinkedList head,tail;
//存放映射的HashMap
private Map<Integer,DoubleLinkedList> map = new HashMap<>();
//容量
private int capacity;
//实际元素个数
private int size;
//数据初始化
public Main(int capacity) {
this.capacity = capacity;
head = new DoubleLinkedList();
tail = new DoubleLinkedList();
head.next = tail;
tail.prev = head;
this.map = new HashMap<>();
}
//对外暴露的get方法
public int get(int key) {
//如果不存在key,则返回-1
if (!map.containsKey(key)) {
return -1;
}
//来到这,说明有这个key,那么就给put出来
DoubleLinkedList node = map.get(key);
//因为使用过了该节点,那么就需要将其移动到头节点
moveToHead(node);
//返回value值
return node.value;
}
//对外暴露的put方法
public void put(int key,int value) {
//如果存在该key
if (map.containsKey(key)) {
//那么get出来,替换value值,因为使用过,所以移动到头节点
DoubleLinkedList node = map.get(key);
node.value = value;
moveToHead(node);
}else {
//因为不存在该key
//所以创建新的节点
DoubleLinkedList newNode = new DoubleLinkedList(key, value);
//将节点加入到map中去,并将其添加到头节点,元素总数量加1
map.put(key,newNode);
addHead(newNode);
size++;
//如果元素总数量大于最大容量
if (size > capacity) {
//那么删除最后一个节点,也就是最少使用的节点
removeLastNode();
}
}
}
//删除末尾节点
private void removeLastNode() {
//tail为虚拟尾节点,所以它前面的节点就是最后一个节点
DoubleLinkedList lastNode = tail.prev;
//删除节点
removeNode(lastNode);
map.remove(lastNode.key);
size--;
}
//移动节点到头节点
private void moveToHead(DoubleLinkedList node) {
removeNode(node);
addHead(node);
}
//添加节点到头节点
private void addHead(DoubleLinkedList node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
//删除节点
private void removeNode(DoubleLinkedList node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
}
手撕LFU
LFU就不像是LFU那样根据最近使用之类的来编排
LFU是根据使用的频次,简单来说是根据使用的次数来编排(在保证次数的情况下,根据最近使用来排),所以对于链表节点需要多定义一个使用的次数count
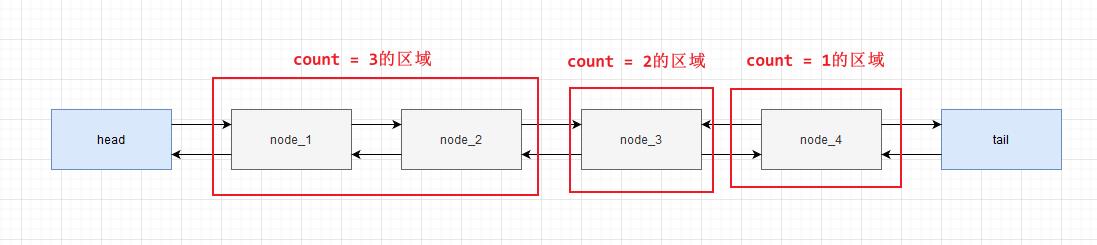
public class Main {
//定义链表
class Node {
private int key;
private int value;
private int count;
private Node next;
private Node prev;
public Node() {
}
public Node(int key, int value,int count) {
this.key = key;
this.value = value;
this.count = count;
}
}
//key与对应的Node节点映射
private Map<Integer,Node> keyMap;
//频次与其对应区域首节点的映射
private Map<Integer,Node> cntMap;
//虚拟头节点、尾节点
private Node head,tail;
//最大容量
private int capacity;
//元素实际个数
private int size;
//初始化
public Main(int capacity) {
this.capacity = capacity;
this.head = new Node();
this.tail = new Node();
head.next = tail;
tail.prev = head;
keyMap = new HashMap<>();
cntMap = new HashMap<>();
}
//对外暴露get方法
public int get(int key) {
//容量为0,或者不存在key则返回-1
if (capacity == 0 || !keyMap.containsKey(key)) {
return -1;
}
//去除key对应的节点
Node node = keyMap.get(key);
//更新使用频次
updateNode_fre(node);
//返回value
return node.value;
}
//更新节点使用频次
private void updateNode_fre(Node node) {
//旧的使用频次
int oldCnt = node.count;
//新的使用频次
int newCnt = node.count + 1;
//需要保存在哪个节点前插入的
//因为插入的位置可能是区域的首节点,也可能不是
Node next = null;
//如果当前节点是该使用频次的首节点
if (cntMap.get(oldCnt) == node) {
//如果当前区域还有下一个节点,那么直接把当前区域的首节点设置为下一节点就好了
if (node.next.count == node.count) {
cntMap.put(oldCnt,node.next);
}else {
//如果没有下一个节点了,那么就需要删除此区域了。因为该节点频次要更新了
cntMap.remove(oldCnt);
}
//如果不存在新区域
if (cntMap.get(newCnt) == null) {
//那么创建新区域,并将该节点设置为首节点
cntMap.put(newCnt,node);
//频次要更新
node.count++;
//不需要后续操作了
return;
}else {
//如果存在,那么就需要删除该节点,将next设置为新区域首节点
removeNode(node);
next = cntMap.get(newCnt);
}
}else {
//如果不是,那么删除节点
removeNode(node);
//如果存在新使用频次的区域则 next就等于新使用区域频次的首节点
//如果没有,那么在当前使用频次前面插入就ok了
if (cntMap.get(newCnt) == null) {
next = cntMap.get(oldCnt);
}else {
next = cntMap.get(newCnt);
}
}
//能来到这的node,频次都是没有更新的,所以更新频次
node.count++;
//更新频次映射
cntMap.put(newCnt,node);
//在指定节点前插入
addNode(node,next);
}
//对外暴露put方法
public void put(int key,int value) {
//如果容量为0,则不能put键值对
if (capacity == 0) return;
//如果存在key
if (keyMap.containsKey(key)) {
//取出节点,替换value,更新
Node node = keyMap.get(key);
node.value = value;
updateNode_fre(node);
}else {
//如果元素个数等于了最大容量
if (size == capacity) {
//那么就需要删除莫尾节点
deleteLastNode();
}
//创建新节点,默认使用次数为1
Node newNode = new Node(key, value,1);
//因为是新节点,所以插入到count=1区域的首部
Node next = cntMap.get(1);
//但如果没有这个区域,那么直接插入到
if (next == null) {
next = tail;
}
//插入、更新
addNode(newNode,next);
keyMap.put(key,newNode);
cntMap.put(1,newNode);
size++;
}
}
//添加节点
private void addNode(Node node, Node next) {
node.next = next;
node.prev = next.prev;
next.prev.next = node;
next.prev = node;
}
//删除末尾节点
private void deleteLastNode() {
Node lastNode = tail.prev;
//如果该节点是此区域的唯一一个节点,那么需要将此区域删除
if (cntMap.get(lastNode.count) == lastNode) {
cntMap.remove(lastNode.count);
}
removeNode(lastNode);
keyMap.remove(lastNode.key);
size--;
}
//删除节点
private void removeNode(Node node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.next = null;
node.prev = null;
}
}
尾言
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以点赞和关注我哦,感谢支持,我们下次再见~~~
分享大纲
更多精彩内容分享,请点击 Hello World (●’◡’●)
以上是关于面试官说,听说你了解Redis,手写一个LRU算法吧的主要内容,如果未能解决你的问题,请参考以下文章