SQL查询语句之查询数据
Posted 程序员超时空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL查询语句之查询数据相关的知识,希望对你有一定的参考价值。
目录
2、group by 关键字与 group_concat()函数一起使用
查询数据是指从数据库中获取所需要的数据。查询数据是数据库操作中最常用,也是最重要的操作。用户可以根据自己对数据的需求,使用不同的查询方式。通过不同的查询方式,可以获得不同的数据。在mysql 中是使用SELECT语句来查询数据的。
1、基本查询语句
查询数据是数据库操作中最常用的操作。通过对数据库的查询,用户可以从数据库中获取需要的数据。数据库中可能包含着无数的表,表中可能包含着无数的记录。因此,要获得所需的数据并非易事。MySQL中可以使用SELECT 语句来查询数据。根据查询的条件的不同,数据库系统会找到不同的数据。通过SELECT语句可以很方便地获取所需的信息。
MysQL中,SELECT的基本语法形式如下:
select 属性列表
from 表名和视图列表
[where 条件表达式1]
[group by 属性名1 [having 条件表达式2]]
[order by 属性名2 [asc | desc]]
其中,“属性列表”参数表示需要查询的字段名;“表名和视图列表”参数表示从此处指定的表或者视图中查询数据,表和视图可以有多个;“条件表达式1”参数指定查询条件;“属性名1”参数指按该字段中的数据进行分组;“条件表达式2”参数表示满足该表达式的数据才能输出;“属性名2”参数指按该字段中的数据进行排序,排序方式由ASC和 DESC两个参数指出;ASC参数表示按升序的顺序进行排序,这是默认参数;DESC参数表示按降序的顺序进行排序。
升序表示值按从小到大的顺序排列。例如,1,2,3这个顺序就是升序。降序表示值按从大到小的顺序排列。例如,3,2,1这个顺序就是降序。对记录进行排序时,如果没有指定是ASC还是DESC,默认情况下是ASC。
如果有WHERE子句,就按照“条件表达式1”指定的条件进行查询;如果没有WHERE子句,就查询所有记录。
如果有GROUP BY子句,就按照“属性名1”指定的字段进行分组;如果GROUP BY子句后带着HAVING关键字,那么只有满足“条件表达式2”中指定的条件的才能够输出。GROUP BY子句通常和COUNTO、SUM()等聚合函数一起使用。
如果有ORDER BY子句,就按照“属性名2”指定的字段进行排序。排序方式由“ASC”和“DESC”两个参数指出。默认的情况下是“ASC”。
下面是一个简单 SELECT语句来查询 employee表。SELECT 语句的代码如下:
【一个小插曲】在创建employee表并插入数据的过程中,出现了错误。
经向度娘了解,是因为插入的数据中有中文,而默认latin1的编码方式不太支持,所以这里的解决方法是将创建好的employee表删除,更改数据库编码方式 alter database 库名charset = 编码方式,再创建表,插入数据,没有报错。


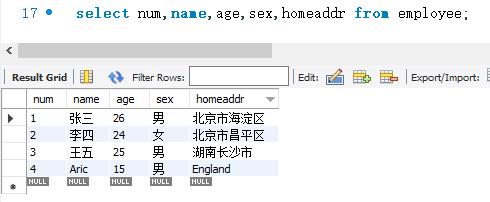
语句执行后,从 employee表中查询出num、name、age、sex和 homeaddr等5个字段的所有记录。因为没有WHERE子句来控制查询条件,默认情况下显示了所有记录。因为没有GROUP BY子句和ORDER BY子句,记录按照employee表中存储的顺序显示。
下面是一个包含WHERE子句和ORDER BY子句的SELECT 语句。SELECT语句的代码如下:
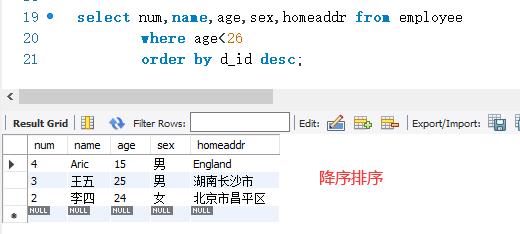
2、单表查询
单表查询是指从一张表中查询所需要的数据。查询数据时,可以从一张表中查询数据,也可以从多张表中同时查询数据。两者的查询方式上有一定的区别。因为单表查询只在一张表上进行操作,所以查询比较简单。
2.1 查询所有字段
查询所有字段是指查询表中所有字段的数据。这种方式可以将表中所有字段的数据都查询出来。MySQL中有两种方式可以查询表中所有的字段。
1、列出表中的所有字段
MySQL中,可以在SELECT语句的“属性列表”中列出所要查询的表中的所有的字段。
下面用SELECT语句查询 employee表中的所有字段的数据。
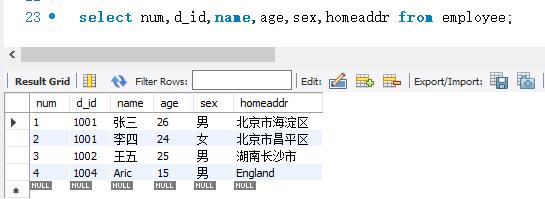
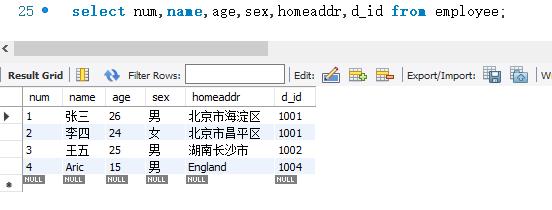
查询结果显示,已经成功查询了employee表的所有字段的数据。这个方式比较灵活,可以改变字段显示的顺序。例如,可以将d_id字段显示为最后一列。代码执行如下:
2、使用 ‘* ’ 查询所有字段
在 MySQL中,SELECT语句的“属性列表”中可以为“*”。其基本语法形式为:
select * from 表名;
“*”可以表示所有的字段。这样就不用列出表中所有字段的名称了。但是,使用这种方式查询时,只能按照表中字段的顺序进行排列,不能改变字段的排列顺序。
下面用SELECT语句来查询employee表的所有字段的数据,此处用“*”来代替“属性列表”。SELECT语句的代码如下:
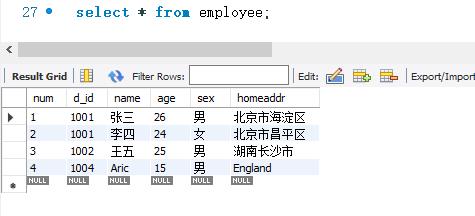
虽然列出表的所有字段的方式比较灵活,但是查询所有字段时通常使用“SELECT* FROM 表名”。使用这种方式比较简单。尤其是表中的字段很多的时候,这种方式的优势就更加明显。当然,如果需要改变字段显示的顺序,就选择列表的所有字段。
2.2 查询指定字段
查询数据时,可以在SELECT语句的“属性列表”中列出所要查询的字段。这种方式可以指定需要查询的字段,而不需要查询出所有的字段。
下面查询employee表中 num、name、sex和 homeaddr等4个字段的数据。SELECT语句的代码如下:
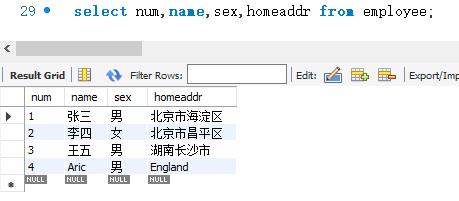
2.3 查询指定记录
SELECT 语句中可以设置查询条件。用户可以根据自己的需要来设置查询条件,按条件进行查询。查询的结果必须满足查询条件。例如,用户需要查找d_id为 1001的记录,那么可以设置“d_id=1001”为查询条件。这样查询结果中的记录就都会满足“d_id=1001”这个条件。WHERE子句可以用来指定查询条件。其语法规则如下:
where 条件表达式
其中,“条件表达式”参数指定SELECT语句的查询条件。
下面查询employee表中d_id为1001的记录。SELECT 语句的代码如下:
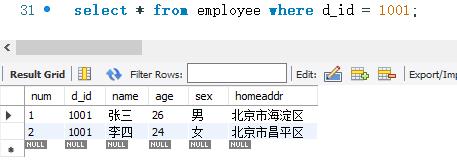
下面查询employee表中d_id.为1005的记录。代码执行如下:
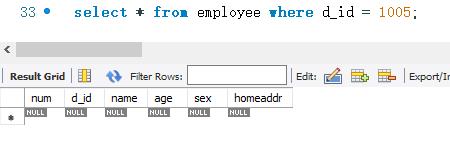
因为,employee表中没有满足“d_id=1005”的记录,所以结果显示“Empty set”。
WHERE子句常用的查询条件有很多种:

表中,“>”表示不等于,其作用等价于“!=”;“!>”表示不大于,等价于“<=”;“!长<”表示不小于,等价于“>=”;BETWEEN AND指定了某字段的取值范围;“IN”指定了某字段的取值的集合;IS NULL用来判断某字段的取值是否为空;AND和OR用来连接多个查询条件。
!!!条件表达式中设置的条件越多,查询出来的记录就会越少。因为,设置的条件越多,查询语句的限制就更多,能够满足所有条件的记录就更少。为了使查询出来的记录正是自己想要查询的记录,可以在WHERE语句中将查询条件设置得更加具体。
2.4 带 in 关键字的查询
IN关键字可以判断某个字段的值是否在指定的集合中。如果字段的值在集合中,则满足查询条件,该记录将被查询出来;如果不在集合中,则不满足查询条件。其语法规则如下:
[not] in (元素1,元素2,...,元素n)
其中,“NOT”是可选参数,加上NOT表示不在集合内满足条件;“元素n”表示集合中的元素,各元素之间用逗号隔开,字符型元素需要加上单引号。
下面使用IN关键字进行查询。SELECT语句的代码如下:
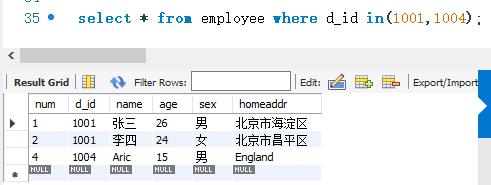
结果显示,d_id字段的取值为1001或1004的记录都被查询出来。如果集合中的元素为字符时,须加上单引号。
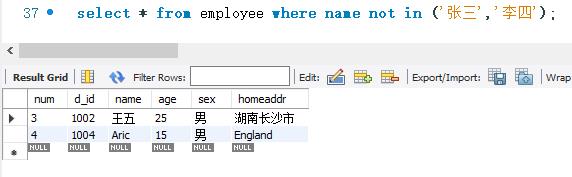
下面使用NOT IN 关键字进行查询,而且集合的元素为字符型数据。SELECT语句的代码如下:
2.5 带 between and 的范围查询
BETWEEN AND关键字可以判读某个字段的值是否在指定的范围内。如果字段的值在指定范围内,则满足查询条件,该记录将被查询出来。如果不在指定范围内,则不满足查询条件。其语法规则如下:
[not] between 取值1 and 取值2
其中,“NOT”是可选参数,加上 NOT 表示不在指定范围内满足条件;“取值1”表示范围的起始值;“取值2”表示范围的终止值。
下面使用BETWEEN AND关键字进行查询,查询条件是age字段的取值从15~25。SELECT语句的代码如下:
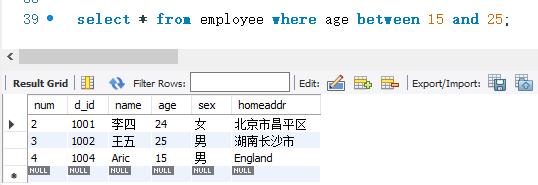
结果显示,age字段的取值是大于等于15,且小于等于25。由此可以知道,BETWEEN AND的范围是大于等于“取值1”,而小于等于“取值2”的。
NOT BETWEEN AND的取值范围是小于“取值1”,而大于“取值2”。
下面使用NOT BETWEEN AND关键字查询employee表。查询条件是age字段的取值不在15~25之间。SELECT语句的代码如下:
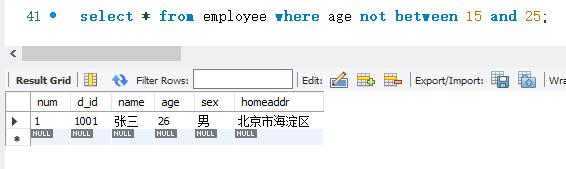
BETWEEN AND和NOT BETWEENAND关键字在查询指定范围的记录时很有用。例如,查询学生表的年龄段、分数段等。还有查询员工的工资水平时也可以使用这两个关键字。
2.6 带 like 的字符匹配查询
LIKE关键字可以匹配字符串是否相等。如果字段的值与指定的字符串相匹配,则满足查询条件,该记录将被查询出来。如果与指定的字符串不匹配,则不满足查询条件。其语法规则如下:
[not] like '字符串'
其中,“NOT" 是可选参数,加上NOT表示与指定的字符串不匹配时满足条件:“字符串”表示指定用来匹配的字符串,该字符串必须加单引号或者双引号。“字符串” 参数的值可以是一-个完整的字符串,也可以是包含百分号(%)或者下划线(_ )的通配字符。但是%和_有很大的差别:
- “%” 可以代表任意长度的字符串,长度可以为0。例如,b%k 表示以字母b开头,以字母k结尾的任意长度的字符串。该字符串可以代表bk、buk、 book、break、bedrock等字符串。
- “_”只能表示单个字符。例如,b_ k表示以字母b开头,以字母k结尾的3个字符。中间的“_”可以代表任意一一个字符。字符串可以代表bok、bak和buk等字符串。
下面使用 LIKE关键字来匹配- -个完整的字符串’Aric’。SELECT 语句的代码如下:
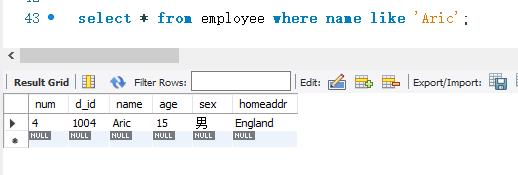
=
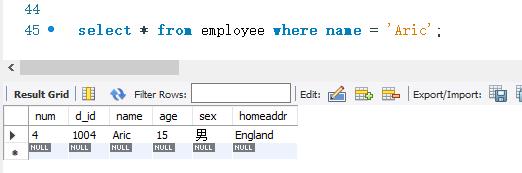
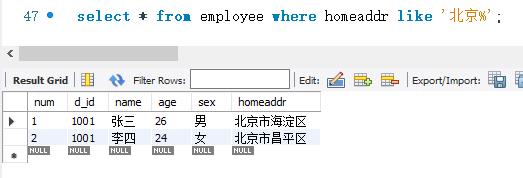
下面使用LIKE关键字来匹配带有通配符‘%’的字符串“北京%'。SELECT语句的代码如下:
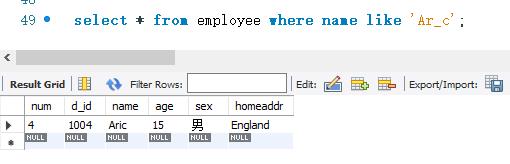
下面使用LIKE关键字来匹配带有通配符’的字符串‘Ar_ c’。 SELECT语句的代码如下:
!!!需要匹配的字符串需要加引号。可以是单引号,也可以是双引号。如果要匹配姓张且名字只有两个字的人的记录,“张” 字后面必须有两个“”符号。因为一个汉字是两个字符,而一个“_”符号只能代表一个字符。因此,匹配的字符串应该为“张_ _”,必须是两个“_”符号。
NOT LIKE表示字符串不匹配的情况下满足条件。
下面使用NOT LIKE关键字来查询不是姓张的所有人的记录。SELECT语句的代码如下:
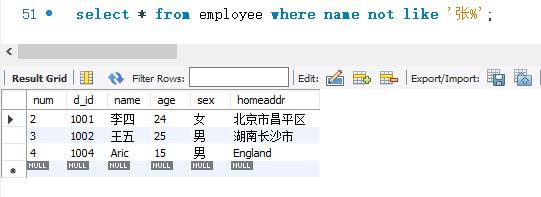
2.7 查询空值
IS NULL关键字可以用来判断字段的值是否为空值(NULL)。如果字段的值是空值,则满足查询条件,该记录将被查询出来。如果字段的值不是空值,则不满足查询条件。其语法规则如下:
is [not] null
其中,“NOT" 是可选参数,加上NOT表示字段不是空值时满足条件。
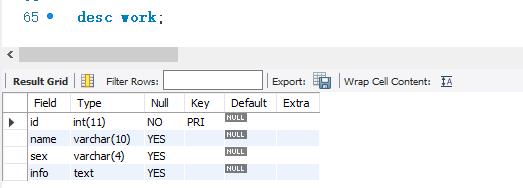
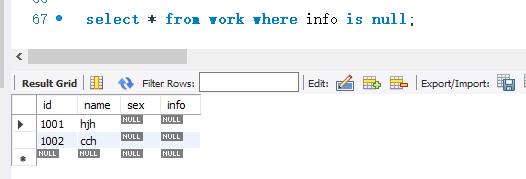
下面使用ISNULL关键字来查询work表中info字段为空值的记录。SELECT语句的代码如下:
首先查看work表结构:
!!!IS NULL是一个整体,不能将IS换成“=”。如果将IS换成“=”将不能查询出任何结果,数据库系统会出现“Empty set (0.00 sec)”这样的提示。同理,IS NOT NULL中的IS NOT不能换成“!=”或“<”。
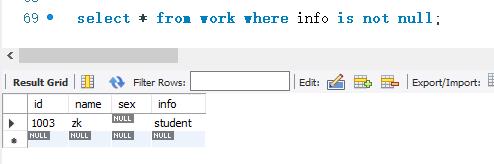
如果使用IS NOT NULL关键字,将查询出该段的值不为空的所有记录。
下面使用IS NOT NULL关键字来查询work表中info字段不为空值的记录。SELECT语句的代码如下:
2.8 带 and 的多条件查询
AND关键字可以用来联合多个条件进行查询。使用AND关键字时,只有同时满足所有查询条件的记录会被查询出来。如果不满足这些查询条件的其中-一个,这样的记录将被排除掉。AND关键字的语法规则如下:
条件表达式1 and 条件表达式2 [.. and 条件表达式n]
其中,AND可以连接两个条件表达式。而且,可以同时使用多个AND关键字,这样可以连接更多的条件表达式。
下面使用 AND关键字来查询employee表中d_ id 为1001,而且sex为‘男’的记录。SELECT语句的代码如下:
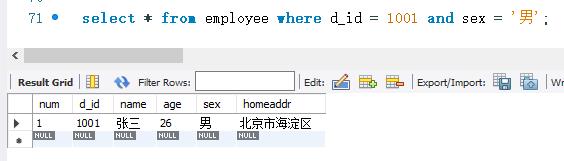
下面在employee表中查询d_ id 小于1004,age小于26,而且sex为“男”的记录。SELECT语句的代码如下:
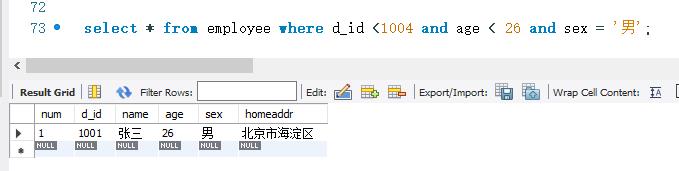
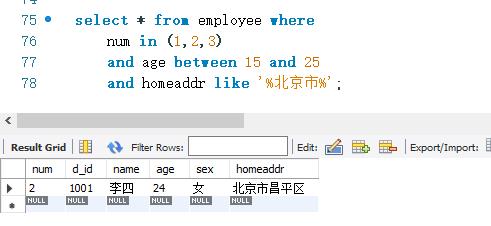
下面使用AND关键字查询employee表中的记录。查询条件为num取值在(1,2,3)这个集合中,age 范围从15~25,而且,homeaddr 的取值中包含“北京市’。
2.9 带 or 的多条件查询
OR关键字也可以用来联合多个条件进行查询,但是与AND关键字不同。使用OR关键字时,只要满足这几个查询条件的其中-一个,这样的记录将会被查询出来。如果不满足这些查询条件中的任何-一个, 这样的记录将被排除掉。OR关键字的语法规则如下:
条件表达式1 or 条件表达式2 [ .. 条件表达式n]
其中,OR可以用来连接两个条件表达式。而且,可以同时使用多个OR关键字,这样可以连接更多的条件表达式。
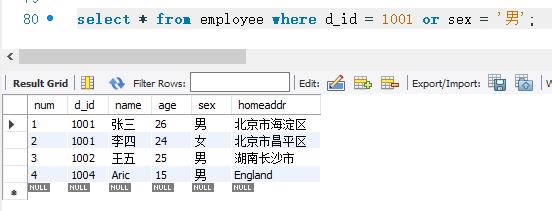
下面使用OR关键字来查询employee表中d_ id为1001,或者sex为男’的记录。SELECT语句的代码如下:
下面使用OR关键字查询employee表中的记录。查询条件为num取值在(1,2,3)这个集合中,或者age从24~25这个范围,或者homeaddr的取值中包含“北京市’。
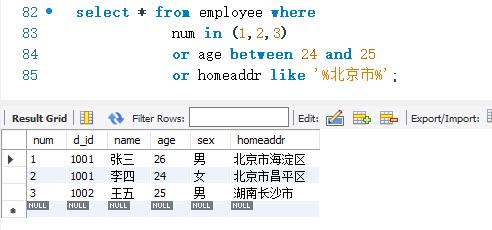
OR可以和AND一起使用。当两者-起使用时,AND要比OR先运算。
下面同时使用OR和AND关键字查询employee表中的记录。
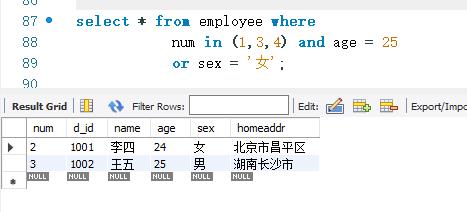
根据查询结果可知,“ num IN (1,3,4) AND age=25”这个两个条件确定了num=3 这条记录。而“sex='女”这个条件确定了num=2这条记录。
如果将条件的顺序换一下 ,将SELECT语句变成如下情况:
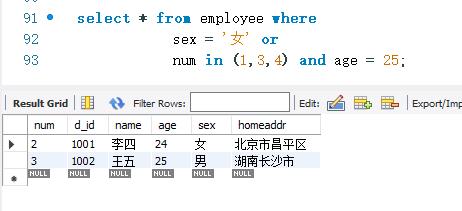
执行结果与前面的SELECT语句的执行结果是一样的。这说明AND关键字前后的条件先结合,然后再与OR关键字的条件结合。也就是说,AND要比OR先运算。
!!!AND和OR关键字可以连接条件表达式。这些条件表达式中可以使用“=”、“>”等操作符,也可以使用IN、BETWEEN AND和LIKE等关键字。而且,LIKE关键字匹配字符串时可以使用“%”和“”等通配字符。
2.10 查询结果不重复
如果表中的某些字段.上没有唯一性约束,这些字段可能存在着重复的值。例如,employee表中的d_ id字段就存在着重复的情况。
employee表中有两条记录的d_ id的值为1001。SELECT 语句中可以使用DISTINCT关键字来消除重复的记录。其语法规则如下:
select distinct 属性名
下面使用DISTINCT关键字来消除d_ id 字段中的重复记录。带DISTINCT关键字的SELECT语句如下:
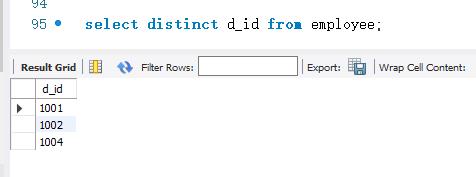
DISTINCT关键字非常有用,尤其是重复的记录非常多时。例如,需要从消息表中查询有哪些消息。但是,这个表中可能有很多相同的消息,将这些相同的消息都查询出来显然是没有必要的。那么,这就需要DISTINCT关键字消除相同的记录。
2.11 对查询结果排序
从表中查询出来的数据可能是无序的,或者其排列顺序不是用户所期望的顺序。为了使查询结果的顺序满足用户的要求,可以使用ORDER BY关键字对记录进行排序。其语法规则如下:
order by 属性名 [ asc | desc]
其中,“属性名” 参数表示按照该字段进行排序; ASC参数表示按升序的顺序进行排序: DESC参数表示按降序的顺序进行排序。默认的情况下,按照ASC方式进行排序。
下面查询employee表中所有记录,按照age字段进行排序。带ORDER BY关键字的SELECT语句如下:
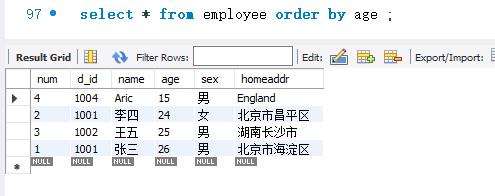
下面查询employee表中所有记录,按照age字段的降序方式进行排序。SELECT语句如下:
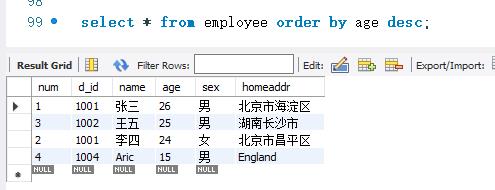
!!!如果存在一条记录age字段的值为空值(NULL)时,这条记录将显示为第一条记录。因为,按升序排序时,含空值的记录将最先显示。可以理解为空值是该字段的最小值。而按降序排列时,age字段为空值的记录将最后显示。
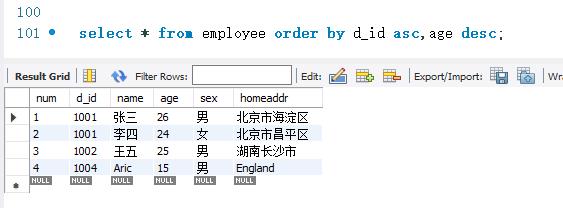
MySQL中,可以指定按多个字段进行排序。例如,可以使employee表按照d_ id 字段和age字段进行排序。排序过程中,先按照d_ id 字段进行排序。遇到d_ id 字段的值相等的情况时,再把d_ id 值相等的记录按照age字段进行排序。
下面查询employee表中所有记录,按照d_id字段的升序方式和age字段的降序方式进行排序。SELECT语句如下:
2.12 分组查询
GROUP BY关键字可以将查询结果按某个字段或多个字段进行分组。字段中值相等的为一组。其语法规则如下:
group by 属性名 [having 条件表达式] [with rollup]
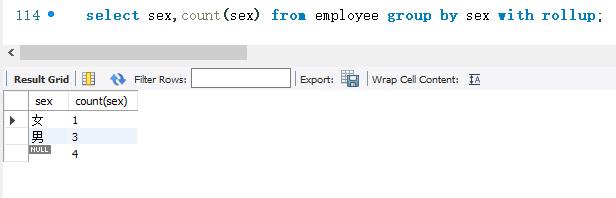
其中,“属性名”是指按照该字段的值进行分组;“HAVING条件表达式”用来限制分组后的显示,满足条件表达式的结果将被显示; WITH ROLLUP关键字将会在所有记录的最后加上一条记录。该记录是上面所有记录的总和。
GROUP BY关键字可以和GROUP _CONCAT()函数一起使用。GROUP_ CONCAT(函数会把每个分组中指定字段值都显示出来。同时,GROUP BY关键字通常与集合函数-起使用。集合函数包括COUNT()、SUM()、AVG()、MAX()和MIN()。其中,COUNT()用来统计记录的条数: SUM()用来计算字段的值的总和; AVG()用来计算字段的值的平均值;MAX()用来查询字段的最大值; MIN(用来查询字段的最小值。如果GROUPBY不与上述函数一起使用,那么查询结果就是字段取值的分组情况。字段中取值相同的记录为一组,但只显示该组的第一条记录。
1、单独使用group by关键字来分组
如果单独使用GROUP BY关键字,查询结果只显示一个分组的一条记录。
下面按employee表的sex字段进行分组查询,语句执行如下:
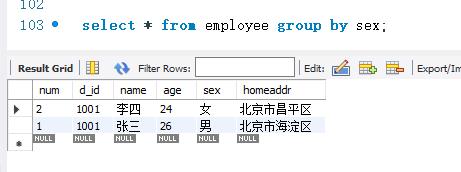
结果中只显示了两条记录。这两条记录的sex字段的值分别为“女”和“男”。查询结果进行比较,GROUP BY关键字只显示每个分组的一条记录。这说明,GROUP BY关键字单独使用时,只能查询出每个分组的一条记录。这样使用的意义不大。因此,一般在使用集合函数时才使用GROUP BY关键字。
2、group by 关键字与 group_concat()函数一起使用
GROUP BY关键字与GROUP_ CONCAT()函数一起使用时, 每个分组中指定字段值都显示出来。
下面按employee表的sex字段进行分组查询。使用GROUP _CONCAT()函数将每个分组的name字段的值显示出来。SELECT语句的代码如下:
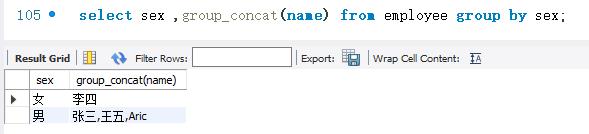
结果显示,查询结果分为两组。sex 字段取值为“女”的记录是一组,取值为“男”的记录为一组。而且,每一组中所有人的名字都被查询出来。该例说明,使用GROUP_ CONCAT(函数可以很好的把分组情况表示出来。
3、group by 关键字与集合函数一起使用
GROUPBY关键字与集合函数一起使用时,可以通过集合函数计算分组中的总记录、最大值、最小值等。
下面按employee表的sex字段进行分组查询。sex字段取值相同的为一组。然后对每一组使用集合函数COUNT(进行计算,求出每一组的记录数。SELECT语句的代码如下:
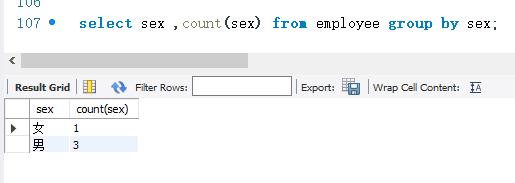
结果显示,查询结果按sex字段取值进行分组。取值为“女”的记录是一组,取值为“男”的记录是一组。COUNT(sex)计算出了sex 字段不同分组的记录数。第一组只有1条记录,第二组共有3条记录。
通常情况下,GROUPBY关键字与集合函数一起使用。集合函数包括COUNT()、SUM()、AVG()、MAX()和MIN()。通常先使用GROUP BY关键字将记录分组,然后每组都使用集合函数进行计算。在统计时经常需要使用GROUP BY关键字和集合函数。
4、group by 关键字与having一起使用
如果加上“HAVING条件表达式”,可以限制输出的结果。只有满足条件表达式的结果才会显示。
下面按employee表的sex字段进行分组查询。然后显示记录数大于等于3的分组。SELECT语句的代码如下:
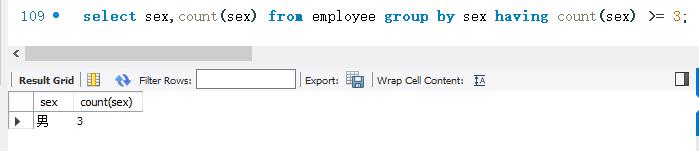
【区别】“HAVING条件表达式”与“WHERE 条件表达式”都是用来限制显示的。但是,两者起作用的地方不一样。“WHERE 条件表达式”作用于表或者视图,是表和视图的查询条件。“HAVING 条件表达式”作用于分组后的记录,用于选择满足条件的组。
5、按多个字段进行分组
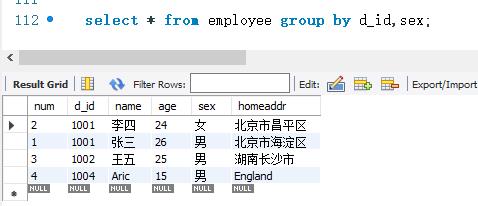
MySQL中,还可以按多个字段进行分组。例如,employee 表按照d_ id 字段和sex字段进行分组。分组过程中,先按照d_ jid 字段进行分组。遇到d_ id字段的值相等的情况时,再把d_ id值相等的记录按照sex字段进行分组。
下面employee 表按照d_ id 字段和sex字段进行分组。SELECT语句如下:
6. GROUP BY关键与WITH ROLLUP一起使用
使用WITH ROLLUP时,将会在所有记录的最后加上一条记录。 这条记录是上面所有
记录的总和。.
下面按employee表的sex字段进行分组查询。使用COUNT()函数来计算每组的记录数。并且加上WITH ROLLUP。SELECT 语句如下:
2.13 用 limit 限制查询结果的数量
查询数据时,可能会查询出很多的记录。而用户需要的记录可能只是很少的一部分。这样就需要来限制查询结果的数量。LIMIT是MySQL中的一个特殊关键字。其可以用来:指定查询结果从哪条记录开始显示。还可以指定一共显示多少条记录。LIMIT 关键字有两种使用方式。这两种方式分别是不指定初始位置和指定初始位置。
1、不指定初始位置
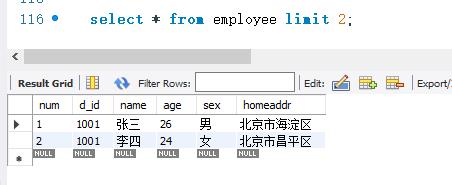
LIMIT关键字不指定初始位置时,记录从第一条 记录开始显示。显示记录的条数有LIMIT关键字指定。其语法规则如下:
limit 记录数
其中,“记录数”参数表示显示记录的条数。如果“记录数”的值小于查询结果的总记录数,将会从第一条记录开始,显示指定条数的记录。如果“记录数”的值大于查询结果的总记录数,数据库系统会直接显示查询出来的所有记录。
下面查询employee 表的所有记录。但只显示前两条。SELECT语句如下:
下面查询employee 表的所有记录,但只显示前6条。SELECT语句如下:
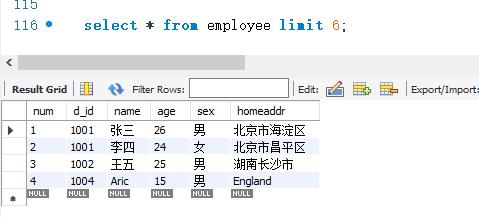
结果中只显示了4条记录。虽然LIMIT关键字指定了显示6条记录。但是查询结果中只有4条记录。因此,数据库系统就将这4条记录全部显示出来。
2、指定初始位置
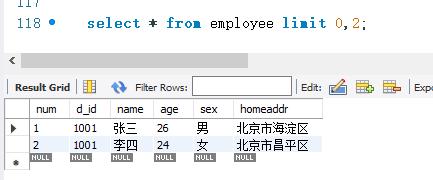
LIMIT关键字可以指定从哪条记录开始显示,并且可以指定显示多少条记录。其语法规则如下:
limit 初始位置, 记录数
其中,“初始位置”参数指定从哪条记录开始显示;“记录数”参数表示显示记录的条数。第一条记录的位置是0,第二条记录的位置是1。后面的记录依次类推。
下面查询employee 表的所有记录,显示前两条记录。SELECT语句如下:
下面查询employee表的所有记录。从第二条记录开始显示,共显示两条记录。SELECT语句如下
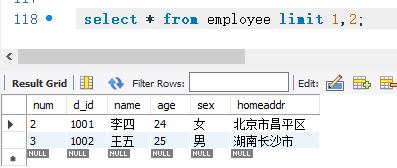
LIMIT关键字是MySQL中所特有的。LIMIT关键字可以指定需要显示的记录的初始位置,0表示第一条记录。如果需要查询成绩在前十名的学生的信息,可以使用ORDER BY关键字将记录按照分数的降序排列,然后使用LIMIT关键字指定只查询前10条记录。
3、使用集合函数查询
集合函数包括COUNT()、SUM()、AVG()、MAX()和MIN()。其中,COUNT()用来统计记录的条数; SUM()用来计算字段的值的总和; AVG()用来计算字段的值的平均值; MAX()用来查询字段的最大值; MIN()用来查询字段的最小值。当需要对表中的记录求和、求平均值、查询最大值和查询最小值等操作时,可以使用集合函数。例如,需要计算学生成绩表中的平均成绩,可以使用AVG()函数。GROUPBY关键字通常需要与集合函数一起使用。
3.1 count() 函数
COUNT()函数用来统计记录的条数。如果要统计employee 表中有多少条记录,可以使用COUNT()函数。如果要统计employee 表中不同部门的人数,也可以使用COUNT()函数。
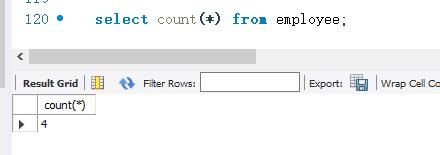
下面使用COUNT()函数统计employee表的记录数。SELECT语句如下:
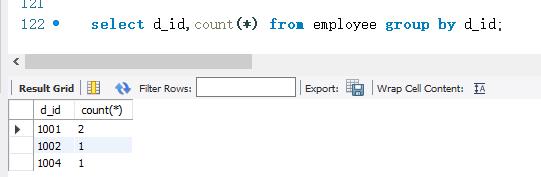
下面使用COUNT)函数统计employee 表中不同d_ id值的记录数。COUNT()函数与GOUPE BY关键字一起使用。SELECT语句如下:
3.2 sum() 函数
SUM()函数是求和函数。使用SUM()函数可以求出表中某个字段取值的总和。例如,可以用SUM()函数来求学生的总成绩。
下面使用SUM()函数统计grade表中学号为1001 的同学的总成绩。SELECT语句如下:
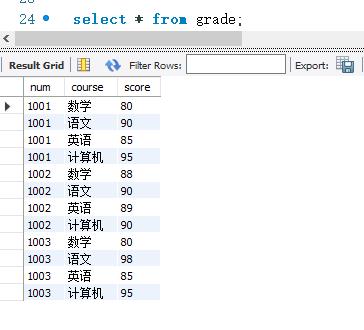
首先查看grade表中的数据:
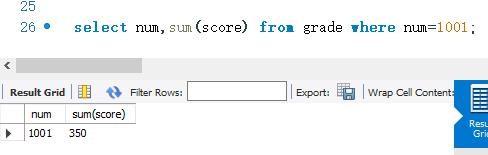
SUM() 函数通常和GROUP BY关键字一起使用。 这样可以计算出不同分组中某个字段取值的总和。
下面将 grade表按照num字段进行分组。然后,使用SUM() 函数统计各分组的总成绩。SELECT 语句如下:
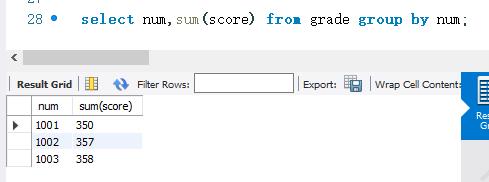
!!!SUM() 函数只能计算数值类型的字段。包括INT类型、FLOAT类型、DOUBLE类型、DECIMAL类型等。字符类型的字段不能使用SUM()函数进行计算。使用SUM() 函数计算字符类型字段时,计算结果都为0.
3.3 avg() 函数
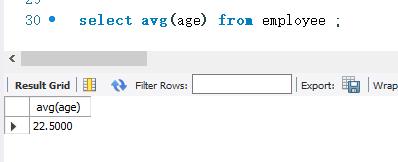
AVG() 函数是求平均值的函数。使用AVG() 函数可以求出表中某个字段取值的平均值。例如,可以用AVG() 函数来求平均年龄,也可以使用AVG() 函数来求学生的平均成绩。
下面使用AVG()函数计算employee表中平均年龄(age) 。SELECT语句如下:
下面使用AVG()函数计算grade表中不同科目的平均成绩。SELECT语句如下:
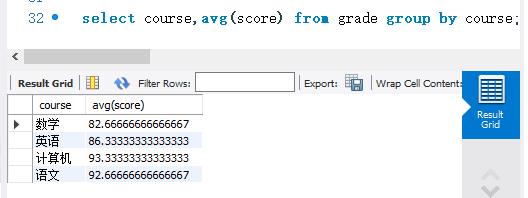
使用GROUPBY关键字将grade表的记录按照course字段进行分组。然后计算出每组的平均成绩。本例可以看出,AVG0)函数与GROUP BY关键字结合后可以灵活的计算平均值。通过这种方式可以计算各个科目的平均分数,还可以计算每个人的平均分数。如果按照班级和科目两个字段进行分组,还可以计算出每个班级不同科目的平均分数。
3.4 max() 函数
MAX() 函数是求最大值的函数。使用MAX() 函数可以求出表中某个字段取值的最大值。例如,可以用MAX() 函数来查询最大年龄,也可以使用MAX() 函数来求各科的最高成绩。
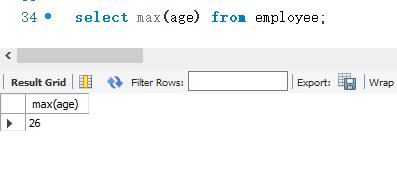
下面使用MAX ()函数查询employee表中的最大年龄(age)。SELECT语句如下:
下面使用MAX() 函数查询grade表中不同科目的最高成绩。SELECT语句如下:
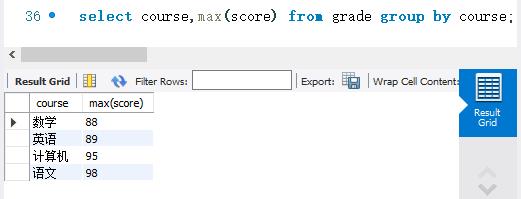
先将grade 表的记录按照course字段进行分组。然后查询出每组的最高成绩。可以看出,MAX()函数与GROUP BY关键字结合后可以查询出不同分组的最大值。通过这种方式可以计算各个科目的最高分。如果按照班级和科目两个字段进行分组,还可以计算出每个班级不同科目的最高分。
MAX() 不仅仅适用于数值类型,也适用于字符类型。
下面使用MAX() 函数查询work表中name字段的最大值。SELECT语句如下:
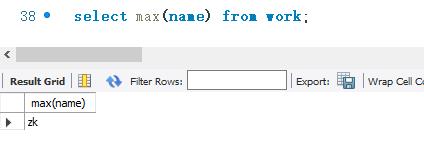
结果显示,name 字段中zk是最大值。说明,MAX() 可以计算字符和字符串的最大值。MAX() 函数是使用字符对应的ASCII码进行计算的。
在MySQL表中,字母a最小,字母z最大。因为,a的ASCII码值最小。在使用MAX() 函数进行比较时,先比较第一个字母。如果第一个字母相等时,再继续往下一个字母进行比较。例如,hhe和hhz只有比较到第3个字母时才能比出大小。
3.5 min() 函数
MIN() 函数是求最小值的函数。使用MIN() 函数可以求出表中某个字段取值的最小值。例如,可以用MIN()函数来查询最小年龄,也可以使用MIN() 函数来求各科的最低成绩。
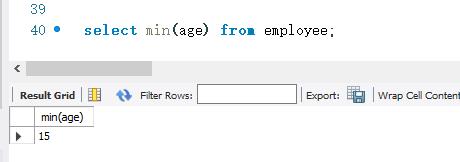
下面使用MIN() 函数查询employee表中的最小年龄。SELECT 语句如下:
MIN() 函数经常与GROUP BY字段一起使用, 来计算每个分组的最小值。
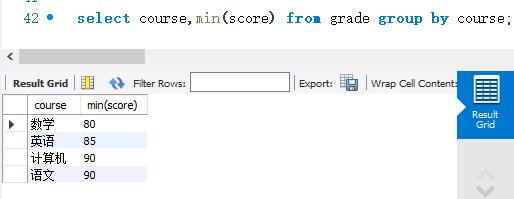
下面使用MIN)函数查询grade表中不同科目的最低成绩。SELECT语句如下:
4、连接查询
连接查询是将两个或两个以上的表按某个条件连接起来,从中选取需要的数据。连接查询是同时查询两个或两个以上的表时使用的。当不同的表中存在表示相同意义的字段时,可以通过该字段来连接这几个表。例如,学生表中有course_ id 字段来表示所学课程的课程号,课程表中有num字段来表示课程号。那么,可以通过学生表中的course_ id 字段与课程表中的num字段来进行连接查询。连接查询包括内连接查询和外连接查询。
4.1 内连接查询
内连接查询是一种最常用的连接查询。内连接查询可以查询两个或两个以上的表。当两个表中存在表示相同意义的字段时,可以通过该字段来连接这两个表;当该字段的值相等时,就查询出该记录。
两个表中表示相同意义的字段可以是指父表的主键和子表的外键。例如, student表中id字段表示学生的学号,并且id字段是student 表的主键。grade 表的stu_ id字段也表示学生的学号。而且,stu_id字段是grade表的外键。stu_ id 字段依赖于student表的id字段。那么,这两个字段有相同的意义。
下面使用内连接查询的方式查询employee表和department。在执行内连接查询之前,先分别查看employee表和department表中的记录,以便进行比较。查询结果如下:
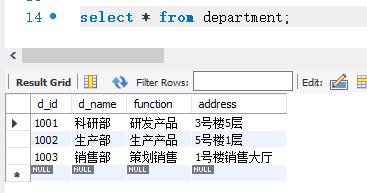
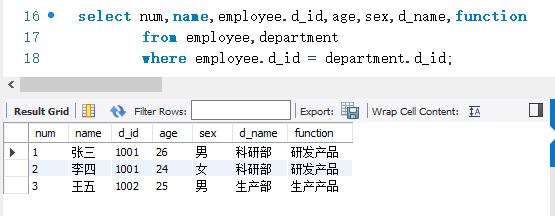
查询结果共显示了3条记录。这3条记录的数据是从employee表和department表中取出来的。这3条记录的d_ id字段的取值分别为1001 和1002。employee表中d_ id 字段取值为1004的记录没有被查询,因为department表中没有d_id等于1004的记录。而department表中d_ id字段取值为1003的记录没有被查询,因为employee 表中没有d_ id等于1003的记录。可以看出,只有表中有意义相同的字段时才能进行连接。而且,内连接查询只查询出指定字段取值相同的记录。
4.2 外连接查询
外连接查询可以查询两个或两个以上的表。外连接查询也需要通过指定字段来进行连接。当该字段取值相等时,可以查询出该记录。而且,该字段取值不相等的记录也可以查询出来。外连接查询包括左连接查询和右连接查询。其基本语法如下:
select 属性名列表
from 表名1 left | right join 表名2
on 表名1.属性名1 = 表名2.属性名2;
其中,“ 属性名列表”参数表示要查询的字段的名称,这些字段可以来自不同的表:“表名1”和“表名2”参数表示将这两个表进行外连接;LEPT参数表示进行左连接查询;RIGHT参数表示进行右连接查询; ON后面接的就是连接条件:‘“属性名1”参数是“表名1"中的一个字段,用“.”符号来表示字段属于哪个表;“属性名2”参数是“表名2”中的一个字段。
1、左连接查询
进行左连接查询时,可以查询出“表名1” 所指的表中的所有记录。而“表名2”所指的表中,只能查询出匹配的记录。
下面使用左连接查询的方式查询employee表和department。两表通过d_ id字段进行连接。左连接的SELECT语句如下:
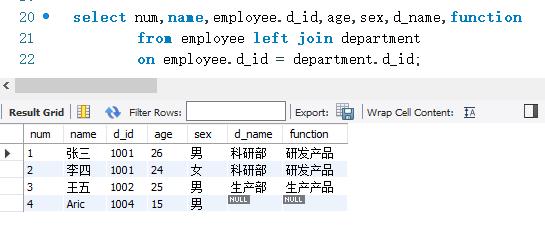
查询结果共显示了4条记录。这4条记录的数据是从employee表和department表中取出来的。因为employee表和department表中都包含d_ id 值为1001和1002的记录,所有这些记录都能查询出来。但查询结果中比内查询多出了d_id等于1004的记录。因为department表中没有d_ id 等于1004的记录,所以该记录只从employee表中取出了相应的值。而对应需要从department表中取的值都是空值(NULL)。
2、右连接查询
进行右连接查询时,可以查询出“表名2”所指的表中的所有记录。而“表名1”所指的表中,只能查询出匹配的记录。
下面使用右连接查询的方式查询employee表和department。两表通过d_ id字段进行连接。右连接的SELECT语句如下:
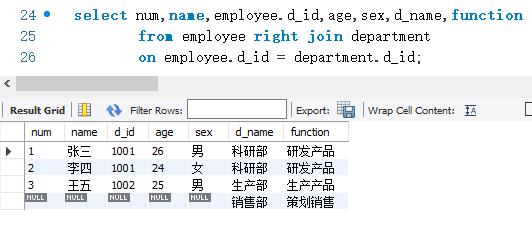
查询结果也显示了4条记录。因为employee表和department表中都包含了d_ id值为1001和1002的记录,所有这些记录都能查询出来。但查询结果中比内查询多出了d_id等于1003的记录。因为employee表中没有d_ id 等于1003的记录,所以该记录只从department表中取出了相应的值。而对应需要从employee表中取的值都是空值(NULL)。
4.3 复合条件连接查询
在连接查询时,也可以增加其他的限制条件。通过多个条件的复合查询,可以使查询结果更加准确。例如,employee 表和department表进行连接查询时,可以限制age字段的取值必须大于24。这样,可以更加准确的查询出年龄大于24岁的员工的信息。
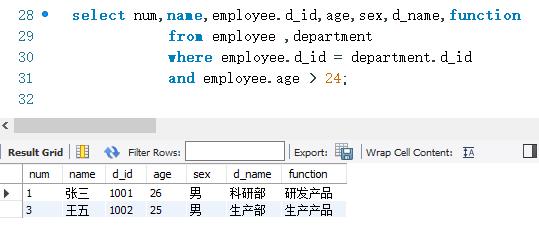
下面使用内连接查询的方式查询employee表和department。并且employee表中的age字段的值必须大于24。内连接的SELECT语句如下:
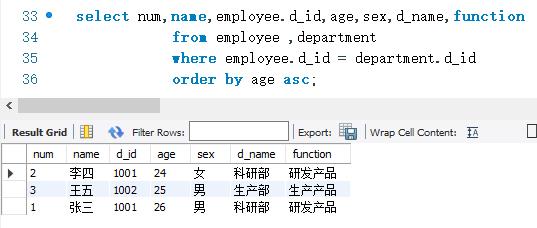
下面使用内连接查询的方式查询employee表和department。并且以age字段的升序方式显示查询结果。SELECT 语句如下:
连接查询中使用最多的内连接查询。而外连接查询中的左连接查询和右连接查询使用的频率比较低。连接查询时可以加上一些限制条件,这样只会对满足限制条件的记录进行连接操作。还可以将连接查询的结果排序。
5、子查询
子查询是将一个查询语句嵌套在另一个查询语句中。内层查询语句的查询结果,可以为外层查询语句提供查询条件。因为在特定情况下,一个查询语句的条件需要另一个查询语句来获取。例如,现在需要从学生成绩表中查询计算机系学生的各科成绩。那么,首先就必须知道哪些课程是计算机系学生选修的。因此,必须先查询计算机系学生选修的课程,然后根据这些课程来查询计算机系学生的各科成绩。通过子查询,可以实现多表之间的查询。子查询中可能包括IN、NOT IN、ANY、ALL、EXISTS 和NOT EXISTS等关键字。子查询中还可能包含比较运算符,如“=”、“!=”、“>”和“<”等。
5.1 带 in 关键字的子查询
一个查询语句的条件可能落在另一个SELECT语句的查询结果中。这可以通过IN关键字来判断。例如,要查询哪些同学选择了计算机系开设的课程。先必须从课程表中查询出计算机系开设了哪些课程。然后再从学生表中进行查询。如果学生选修的课程在前面查询出来的课程中,则查询出该同学的信息。这可以用带IN关键字的子查询来实现。
下面查询employee 表中的记录。这些记录的d_ id字段的值必须在department表中出现过,SELECT 语句如下:
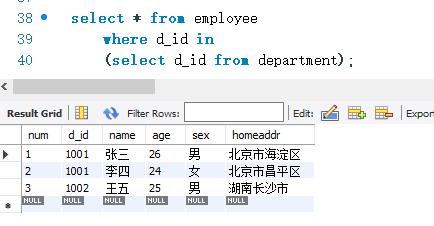
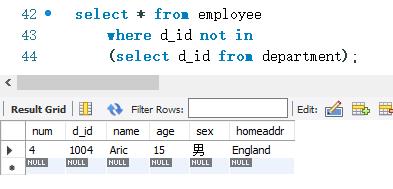
下面查询employee表中的记录。这些记录的d_ id 字段的值必须没有在department表中出现过。SELECT 语句如下:
5.2 带比较运算符的子查询
子查询可以使用比较运算符。这些比较运算符包括=、!=、>、>=. <、<=和<>等。其中,<>与!=是等价的。比较运算符在子查询时使用的非常广泛。如查询分数、年龄、价格和收入等。
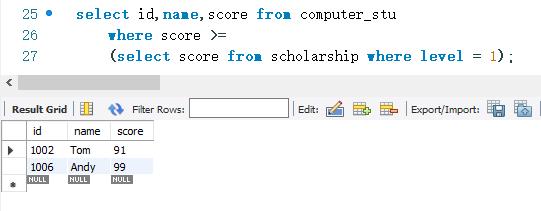
下面从computer_stu 表中查询获得一等奖学金的学生的学号、姓名和分数。各个等级的奖学金的最低分存储在scholarship表中。
下面在department表中查询哪些部门没有年龄为24岁的员工。员工的年龄存储在employee表中。
