Linux中的fork()和clone()函数
Posted 贺二公子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux中的fork()和clone()函数相关的知识,希望对你有一定的参考价值。
原文地址:https://blog.csdn.net/qq_42837885/article/details/101950162
fork函数
在linux中fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);
返回值:
- 子进程中返回0
- 父进程返回子进程id
- 出错返回-1
那么为什么要这样设返回值呢?
- 将子进程id返回给父进程:原因很简单,一个父亲可以有多个儿子,所以儿子很容易就能找到父亲(调用getppid()),但父亲很难找到所有的儿子,没有一个函数使一个进程可以获得所有子进程的Id。
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程。
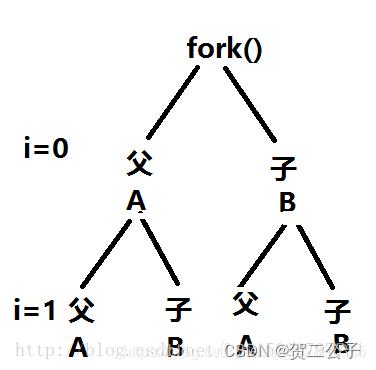
int main()
int i;
for(i=0;i<2;i++)
if(fork()==0)
printf("A\\n");
else
printf("B\\n");
fork 之后会产生父子进程,相当于父进程拷贝了一份给子进程,其中包括缓冲区中的数据。对于fork之后的代码会继续执行.。所以结果是三个A,三个B。
int main()
int i;
for(i=0;i<2;i++)
if(fork()==0)
printf("A");
else
printf("B");
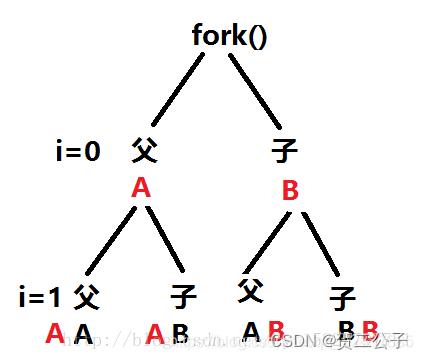
- fork之后,i=0,产生父子进程,没有遇到\\n,程序也没有结束,那么父进程得到的A和子进程得到的B都会在缓冲区先呆着,i=1时,又fork一次,父子进程会把自己的在拷贝一份给他们各自的子进程,那么拷贝的时候就包含了呆在缓冲区里的东西,所以i=2,程序结束,输出缓冲区里的东西,就是4个A,4个B
- fork之后父子进程谁先执行完全由调度器来决定。
- 注意: 第二个代码中的printf 语句中没有了\\n,这涉及到printf输出缓冲区的问题,缓冲区中的数据只有在以下几种可能会输出:
- ① 遇到\\n
- ② fflush(stdout)刷新缓冲区
- ③程序结束(exit或return)
- ④ 缓冲区满。(注意:_exit 程序结束时不刷新缓冲区)
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。(类似C++String类中的写时拷贝)
fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
clone函数
- clone是Linux为创建线程设计的(虽然也可以用clone创建进程)。所以可以说clone是fork的升级版本,不仅可以创建进程或者线程,还可以指定创建新的命名空间(namespace)、有选择的继承父进程的内存、甚至可以将创建出来的进程变成父进程的兄弟进程等等。
- clone函数功能强大,带了众多参数,它提供了一个非常灵活自由的常见进程的方法。因此由他创建的进程要复杂。clone可以让你有选择性的继承父进程的资源,你可以和父进程共享一个虚存空间,从而使创造的是线程,你也可以不和父进程共享,你甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系。
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
- fn为函数指针,此指针指向一个函数体,即想要创建进程的静态程序(我们知道进程的4要素,这个就是指向程序的指针,就是所谓的“剧本", );
- child_stack为给子进程分配系统堆栈的指针(在linux下系统堆栈空间是2页面,就是8K的内存,其中在这块内存中,低地址上放入了值,这个值就是进程控制块task_struct的值);
- arg就是传给子进程的参数一般为(0);
- flags为要复制资源的标志,描述你需要从父进程继承那些资源(是资源复制还是共享,在这里设置参数:
- 下面是flags可以取的值
| 标志 | 含义 |
|---|---|
| CLONE_PARENT | 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子” |
| CLONE_FS | 子进程与父进程共享相同的文件系统,包括root、当前目录、umask |
| CLONE_FILES | 子进程与父进程共享相同的文件描述符(file descriptor)表 |
| CLONE_NEWNS | 在新的namespace启动子进程,namespace描述了进程的文件hierarchy |
| CLONE_SIGHAND | 子进程与父进程共享相同的信号处理(signal handler)表 |
| CLONE_PTRACE | 若父进程被trace,子进程也被trace |
| CLONE_VFORK | 父进程被挂起,直至子进程释放虚拟内存资源 |
| CLONE_VM | 子进程与父进程运行于相同的内存空间 |
| CLONE_PID | 子进程在创建时PID与父进程一致 |
| CLONE_THREAD | Linux 2.4中增加以支持POSIX线程标准,子进程与父进程共享相同的线程群 |
| 下面的例子是创建一个线程(子进程共享了父进程虚存空间,没有自己独立的虚存空间不能称其为进程)。父进程被挂起当子线程释放虚存资源后再继续执行。 |
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sched.h>
#define FIBER_STACK 8192
int a;
void * stack;
int do_something()
a=10;
printf("This is son, the pid is:%d, the a is: %d\\n", getpid(), a);
free(stack);
exit(1);
int main()
void * stack;
a = 1;
stack = malloc(FIBER_STACK);//为子进程申请系统堆栈
if(!stack)
printf("The stack failed\\n");
exit(0);
printf("creating son thread!!!\\n");
clone(&do_something, (char *)stack + FIBER_STACK, CLONE_VM|CLONE_VFORK, 0);//创建子线程
printf("This is father, my pid is: %d, the a is: %d\\n", getpid(), a);
exit(1);
-
运行的结果:
son的PID:10692;
father的PID:10691;
parent和son中的a都为10;所以证明他们公用了一份变量a,是指针的复制,而不是值的复制。 -
问题:clone和fork的区别:
- clone和fork的调用方式很不相同,clone调用需要传入一个函数,该函数在子进程中执行。
- clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。 (void *child_stack,)也就是第二个参数,需要分配栈指针的空间大小,所以它不再是继承或者复制,而是全新的创造。
以上是关于Linux中的fork()和clone()函数的主要内容,如果未能解决你的问题,请参考以下文章