近期论文总结
Posted yizhi_hao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了近期论文总结相关的知识,希望对你有一定的参考价值。
文章目录
- 1. (NeurIPS2021) TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
- 2. (NeurIPS2021) Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
- 3. (ICCV2021) Adaptive Focus for Efficient Video Recognition
- 4. (CVPR2022) Deformable Video Transformer
- 5. (CVPR2022) Stand-Alone Inter-Frame Attention in Video Models
1. (NeurIPS2021) TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
动机说明
在视觉领域应用Transformer,往往将图像或者视频帧分割成一系列的patch,即通过将图像均匀的分成多个片段来形成标记(token),在这种方式下,视觉标记的质量和数量决定了 Vision Transformer 的整体质量,因此Vision Transformer 架构的主要挑战是它们通常需要太多的token才能获得合理的结果。
从而引出了一个问题:是否真的有必要在每一层处理那么多令牌?
在tokenlearner中,通过自适应生成的较少数量的token,而不是依赖于通过统一分割形成的token来学习视觉特征。
方法简述

如上图,首先使用卷积或者MLP计算空间注意力图,以突出重要区域,然后将这种空间注意力图应用于输入以对每个区域进行不同的加权(同时丢弃不必要的区域),并将结果空间池化以生成最终的学习标记,并行重复多次,从原始输入中产生少量的几个(8或16)标记。这个过程也可以看做是根据权重值执行像素的软选择,再进行全局平均池化。具体过程如下:
- 目标为从Xt学习到一个长度为S的token序列Zt=[zi], i=1…S
- tokenlearner:基于空间attention机制。具体而言,首先模型会基于Xt学习到一个空间权重矩阵αi(Xt),尺寸为H×W,然后再乘以Xt,然后通过全局池化得到最终的zi
- tokenfuser:tokenfuser融合所有token的信息,并将融合后的特征重新映射到原始特征尺寸。
2. (NeurIPS2021) Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
动机说明
vanilla TRM中存在的问题:
- 传统的Video TRM对时空维度的处理方式相同,这对时间维度是不妥当的,在第t帧的一个位置成像的物理点可能与在第t+k帧的该位置发现的完全无关,故应该对时间相关性建模,以便于了解动态场景;
- 视频相邻帧之间包含大量的冗余的空间信息,在视频中应用原生注意力,会比较在所有可能的空间位置和帧中提取的成对图像块。这会导致它关注冗余的空间信息,而不是时间信息。
总结以上两点,现有模型在整个3D时空特征体上汇集信息,或者在时间维度上轴向汇集信息,忽略了物体点在时间维度上运动的轨迹。
如上图所示,球所占的区域最多跨越了四个patch,这些patch包含前景(球)和背景对象的混合,至少有两种不同的运动,注意力机制可以从所有相关的“球区域”集合运动特征,但是视觉Transformer是在图像patch上运行的,因此不能假定对应于单个的3D点是沿着简单的一维轨迹移动的。
此外,上图共有5×5=25个patch,在前两帧中,object-relative patch占有不到1/3,在后两帧中占比可达到1/2左右,如上面所说,空间上信息量较大的patch占比较小,这种情况下“平等”地对待所有的时空patch,显然是不合适的。
方法简述
https://blog.csdn.net/qq_41533576/article/details/125544590
不足
轨迹注意力的计算方式类似TimesFormer中的joint-spatial-temporal-attention,尤其是计算轨迹token时,会对大量的时空token进行注意力计算,这种方式仍是具有二次复杂度 O ( S 2 T 2 ) O(S^2T^2) O(S2T2)的。
3. (ICCV2021) Adaptive Focus for Efficient Video Recognition
动机说明

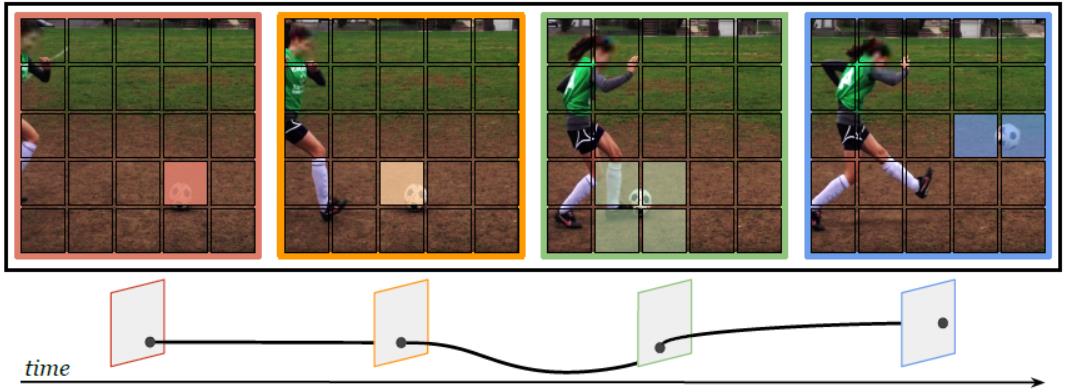
观察上图从数据集中一个视频提取的视频帧信息,可以看到展示的四帧图像中,第2、3帧所包含的信息对最终分类结果(diving)的重要性明显高于其他两帧。
图(b)是现在较多模型的做法,选择若干信息帧进行处理,这种方式能够捕捉到大部分的信息,但难以寻找和重点处理视频帧中最关键的图像区域。
从图(c)的观察中可以得出,视频每一帧中信息量最大的区域通常是一个小的图像块,它在帧之间平滑移动,故选择定位图像空间上最具信息量的区域(informative region),重点关注这部分区域对于分类识别结果是非常重要的。
方法简述
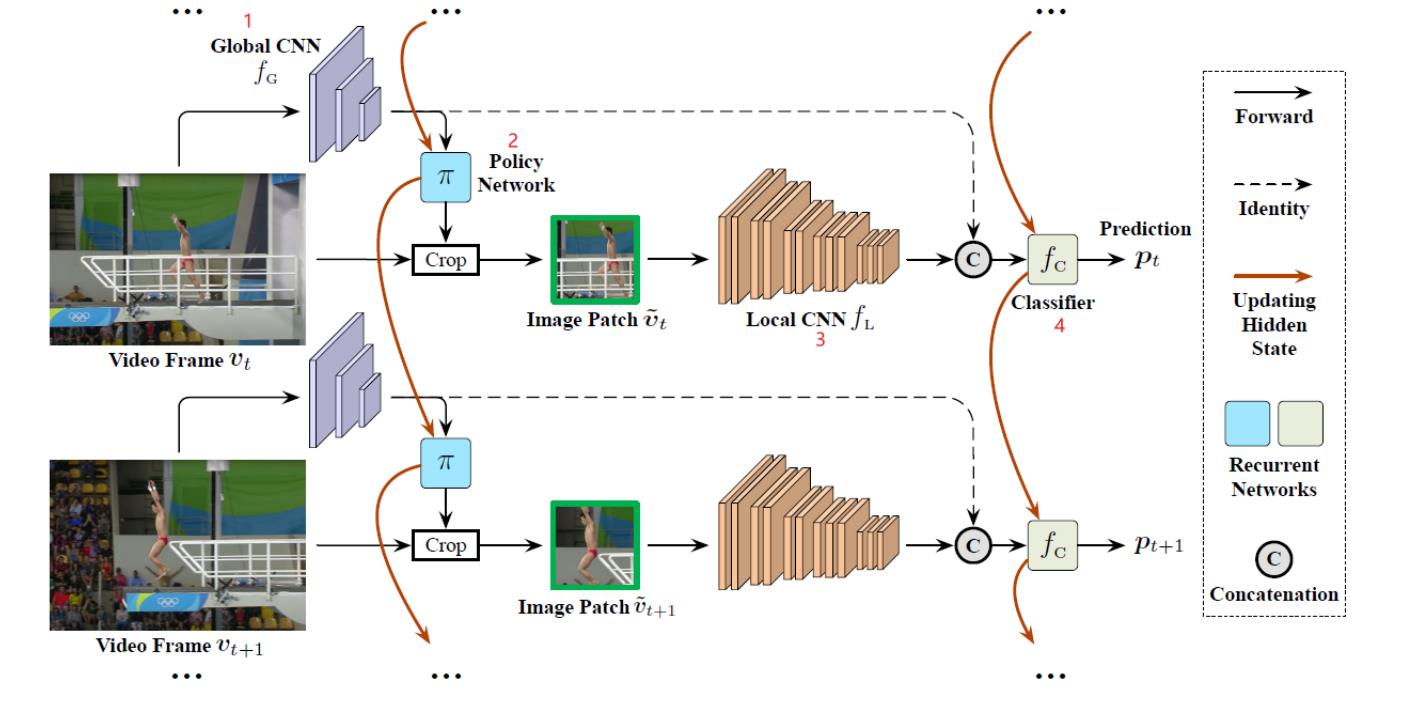
网络由四部分顺序组成:
- 首先,使用轻量化的CNN网络 F G F_G FG对每一帧进行快速“浏览”,以获取粗略的全局信息;
- 在 F G F_G FG的基础上,使用RNN网络π (Policy Network),用以选择聚焦的图像区域 V t V_t Vt;
- 使用高容量的CNN F L F_L FL用于处理上一步选定的区域 V t V_t Vt,这些区域的面积一般较小,因此可节省可观的计算;
- 递归分类器跨帧聚合特征以获得预测值。
不足
Policy Network π文中描述使用强化学习策略,但对此的解释不够,且整体结构需要三阶段的训练,训练过程较为繁琐。
4. (CVPR2022) Deformable Video Transformer
动机说明
以往的TRM仅关注不同帧对应空间位置的做法并不可靠,因为摄像机和物体的移动,投影到第t帧上的场景与第t’帧相同位置的场景可能完全无关。如下图,第一行的视频帧与第二行视频帧做对比,在不同时间点,原有位置上的物体位置发生偏移,此时若还是仅关注对应空间位置的关系已然意义不大。

方法简述
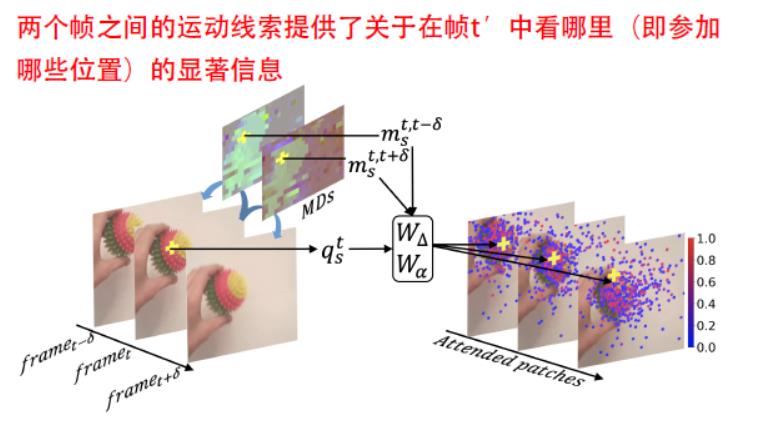
摒弃以往固定的、在预定位置比较patch的注意力策略,转而根据query patch的appearance及其估计的motion动态地决定每一帧中的“查看位置”。利用额外的运动线索(motion cues)来识别一组稀疏的时空位置,以参与每个查询,使得每个query在每帧内关注N个位置,而不是单个位置。
5. (CVPR2022) Stand-Alone Inter-Frame Attention in Video Models
动机说明
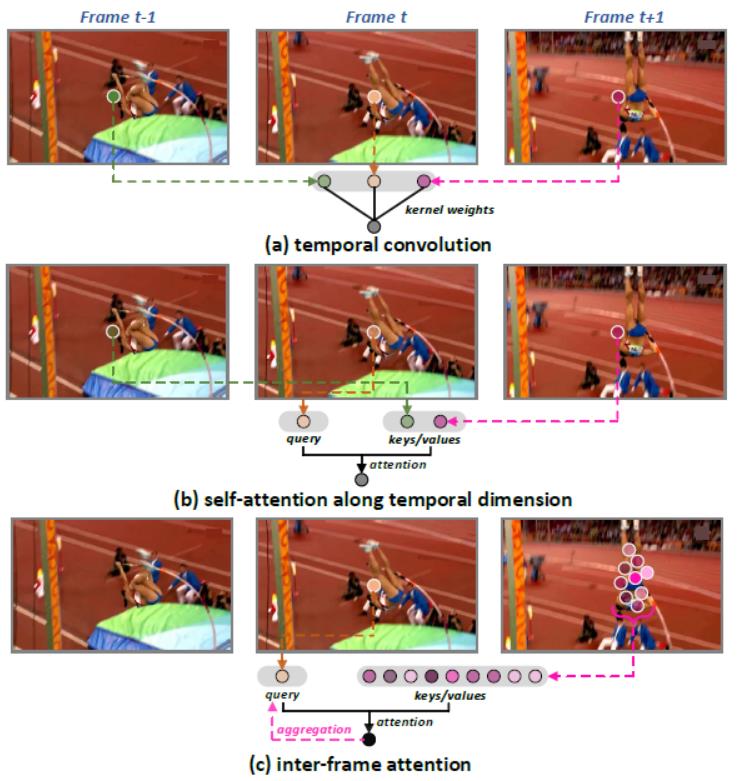
(a)利用时序卷积捕捉聚合时序特征,使用相同卷积核在时间维度上平移获取特征信息;
(b)利用自注意力,按照预定的计算策略,比较不同时序相同空间位置的token序列。
a、b方式背后的理论支撑是跨帧之间的特征映射是应该是对齐的,但实际并非如此。
本文作者提出独立帧间注意力机制——(c)利用局部区域内的帧间相关性进行注意力学习,通过注意力聚集相邻帧局部区域内的所有时间邻域,以增强每帧特征。
方法简述
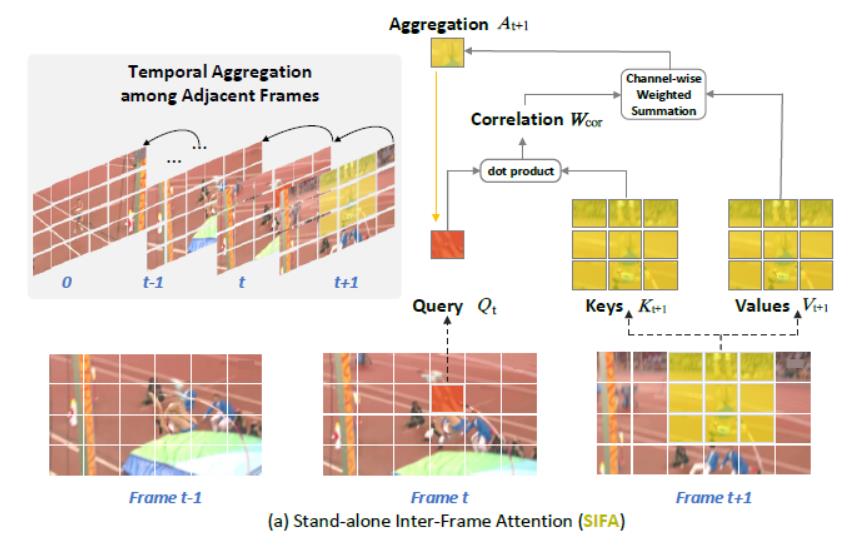
将当前帧中的每个空间位置作为Query,将下一帧中的局部可变形邻域作为Key与Value,SIFA计算Q和K之间的相似性,作为对时间聚合值加权平均的独立关注。
以上是关于近期论文总结的主要内容,如果未能解决你的问题,请参考以下文章