TriCore架构多核多线程锁探究(TC264双核互斥锁)
Posted 穹之韵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TriCore架构多核多线程锁探究(TC264双核互斥锁)相关的知识,希望对你有一定的参考价值。
序言
现在TriCore架构已经是一个十分成熟的架构,并广泛用于新能源行业各类控制器。从TC1.3.1开始有了很多重大的调整。新增了几个指令,有了全流水线结构的浮点单元等。大家想详细了解也可以去翻阅数据手册中Summary of functional changes from TC1.3.1一节。其中有一个新的克隆指令——CMPSWAP.W。这一更改也引出了新的方法来实现TriCore架构的多核多线程锁。
一、问题起因
在开发TC264的双核程序的时候突然思考起了一个问题。在学习线程锁的过程中我们讨论的总是单核,可是单核毕竟在一个时间片下只能处理一个线程的指令,而在多核的情况下每一个核心都可以独立执行一个线程,所以多核是真正实现多线程并行的。按照那时这样简单的考虑来说那作为全局变量的线程锁对于两个核心上的线程来说不也成了公共资源?而线程锁都成了公共资源,那抢锁的行为不也是会产生冲突的?
二、后续的理论补全
1、数据总线
数据总线的一些基本概念这里就不提出来再讲了。有一个细节是在总线上同一时刻只能有一个主设备控制总线传输操作。而对于多核来说也是如此,他们需要互相争抢总线的使用权,而这一现象又能帮助我们实现一些原子操作。
2、总线操作
使用总线对数据进行操作的时候并不是全部都能一次完成的,有时候可能需要多个操作才能实现我们编程中看似简单的操作,而在找个时候就不一定能满足我们的原子性了。
三、官方库的解决办法
在官方库的/Cpu/Std文件夹我们能找的IFxCpu.c的文件,其中给出了抢锁的代码(使用方法在.h文件的注释中有,这里就不再做解释了)
boolean IfxCpu_acquireMutex(IfxCpu_mutexLock *lock)
boolean retVal;
volatile uint32 spinLockVal;
retVal = FALSE;
spinLockVal = 1UL;
spinLockVal =
(uint32)__cmpAndSwap(((unsigned int *)lock), spinLockVal, 0);
/* Check if the SpinLock WAS set before the attempt to acquire spinlock */
if (spinLockVal == 0)
retVal = TRUE;
return retVal;
这段代码的逻辑及其简单,就是去查找我们lock变量的值是否为0,如果为0便把它赋值为1,并且返回成功抢到锁的信息。而有一个操作是值得关注的。__cmpAndSwap() 这一操作为什么能保证原子性并且能做到对变量进行加锁的呢?
进入定义我们能看见
/** \\brief This function is a implementation of a binary semaphore using compare and swap instruction
* \\param address address of resource.
* \\param value This variable is updated with status of address
* \\param condition if the value of address matches with the value of condition, then swap of value & address occurs.
*
*/
IFX_INLINE unsigned int Ifx__cmpAndSwap (unsigned int volatile *address,
unsigned int value, unsigned int condition)
unsigned long long reg64
= value | (unsigned long long) condition << 32;
__asm__ __volatile__ ("cmpswap.w [%[addr]]0, %A[reg]"
: [reg] "+d" (reg64)
: [addr] "a" (address)
: "memory");
return reg64;
这里使用了汇编语言对芯片进行操作,而cmpswap.w操作正是我们在数据手册中找到的新指令。而正如注释说这一个指令能比较两个地址中的值是否相同,并完成交换。
可是这并没有解决我们对原子性的疑问。并且我们又有了新的疑问。为什么不用赋值,而使用交换呢?
而代码到这里已经结束了,我们需要进入数据手册深入查找原因。
四、深入数据手册解决疑问
在数据手册的Atomicity of Data Accesses一节中我们找到了答案。非外围空间的对齐规则一表中有一栏是这样的
| Access type | Access size | Alignment of address in memory | Min/Max number of SRI bus transactions |
|---|---|---|---|
| Load, Store Data Register | Word | 2 bytes (2H) | 1/2* |
| SWAP.W, LDMST, CMPSWAP.W, SWAPMSK.W | Word | 4 bytes (4H) | 1/1 |
而加了*号的在后面也有解释
In the case where a single access leads to multiple bus transactions (marked as “*” in the above tables) then atomicity needs to be considered. In these accesses it is possible for another bus master to read or write the target memory location between the bus transactions required to complete the access.
这里就已经提示我们在出现这种情况的时候数据的原子性是无法保证的,另外一个核心可能会在这两个总线操作之间获得总线的控制权,需要我们去考虑。
这就解释了为什么不是直接对内存经行赋值操作,而是进行交换。cmpswap.w在保证原子性的同时既实现比较,又实现了交换,保证抢锁的过程中不会导致多核多线程同时抢到锁。
五、总结
在解决问题的过程中我也询问了操作系统等方向的老师。在我们现在已经习以为常的多核多线程的调度并不是只是简单的软件层面在实现。这是一个硬件与操作系统共同完成的精妙工程。感谢前人为我们铺下的基础,让我们简单到只用使用一个函数,定义一个变量,就能完成茫茫历史上的一个壮举。
若理解有误,欢迎有大佬对其指正
英飞凌-AURIX-TC3XX-内核架构:AURIX TriCore 1.6P
目录
英飞凌-AURIX-TC3XX-内核架构:AURIX TriCore 1.6P
1、AURIX TC1.6P内核简介及特点
TC3XX 系列属于AURIX™ 2G 系列,AURIX™ 2G 系列系列单片机采用的是TC1.6.E和TC1.6P的核心组合。使用的是32位哈弗架构,将程序指令存储和数据存储分开。具有如下特点:
①、地址范围达到
4GB,分为16段,每段256MB;②、使用的16位和32位指令可减少代码大小,大多数指令能够在1个周期内执行;
③、数据、内存以及
CPU寄存器在单片机中是小端对齐方式;④、具有多种寻址方式:绝对、循环、位反转、长+短、基+偏移量;
⑤、多种指令类型:算术、地址算术、比较、地址比较、逻辑、MAC、移位、协处理器、位逻辑等;
⑥、通用寄存器组(
GPRS)包括16个32位数据寄存器、16个32位地址寄存器以及3个32位状态和程序计数器(PSW/PC/PCXI)。⑦、具有宽内存接口,用于快速上下文切换;
⑧、调试支持(
OCDS):Level 1需要CPS模块支持,Level 3则仅支持带有ED芯片的单片机;⑨、灵活的内存保护系统:具有18个数据存储器及10个代码存储器保护范围,分为6组。
⑩、时间保护系统,允许有时间限制的实时操作。
2、AURIX TC1.6P系统组成及框架
2.1、AURIX TC1.6P CPU 具体实现图如下:

处理器核心连接到以下内存和总线接口:DSPR、PSPR、DCache、PCache、DLMU、LPB、SRI主机、SRI从机(x2)、SPB主机。
分析:
· LMU存储器的一部分(DLMU)分布在处理器之间,以提供对全局SRAM的高性能访问;
· PFlash存储器分布在处理器之间,以提供对本地PFlash库(LPB)的高性能访问;
· 增强的内存保护:保护集数量增加到6个(原为4个)PSW,代码保护范围的数量增加到10(原为8),数据保护范围数量增加到18(原为16);
· 临时保护系统得到扩展,以提供专用的异常计时器;
· 实现了独立的内核重置,可以根据需要独立重置单个内核;
· 存储缓冲区数据合并功能得到扩展,可以将连续的半字合并为字,将连续的字合并为双字;
· 安全保护系统以及扩展得到扩展,可以将连续的半字合并为字,将连续的字合并为双字;
· 安全保护系统已经扩展到涵盖对本地DSPR/PSPR 和 DIMU 的读取和写入访问,以及对LPB的读取访问;
· CPUID已更改为 0x00C0C020。
2.2、AURIX TC1.6P CPU 系统框架
中央处理单元(CPU)包括指令获取单元、执行单元、通用寄存器文件(GPR)、CPU从机接口(CPS)和浮点单元(FPU)。系统框架图如下:
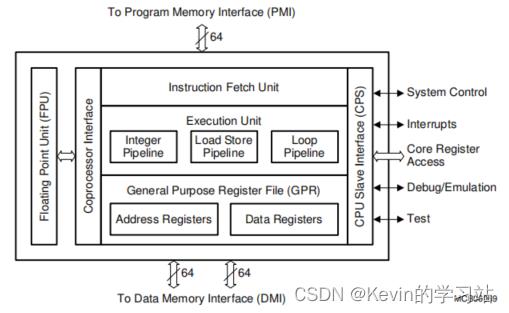
上方为程序存储器接口,具有指令缓存区,通过64位宽度的总线将指令传送到取指单元。取指单元根据指令的特点,分别把指令传送给整型流水线、循环流水线以及转载存储流水线。经过各个流水线处理后的结构分别传送至通用地址寄存器和数据寄存器中。
2.2.1、指令获取单元- Instruction Fetch Unit

指令获取单元的流程:
①。取值单元从64位宽的程序存储器接口(PMI)传入的指令进行预取指操作并对齐;
②、指令在处理单元的fifo中按预测的程序顺序放置,处理单元fifo最大缓冲6条指令,并将指令分发到不同的流水线中;
③、指令保护单元检查是针对PMI的访问有效性以及从PMI提取的传入指令的完整性;
④、分支单元检测提取的指令的分支条件,根据先前的分支行为预测最可能的执行通道;
⑤、程序计数器单元(PC)负责更新计数器。
2.2.2、执行单元-Execution Unit
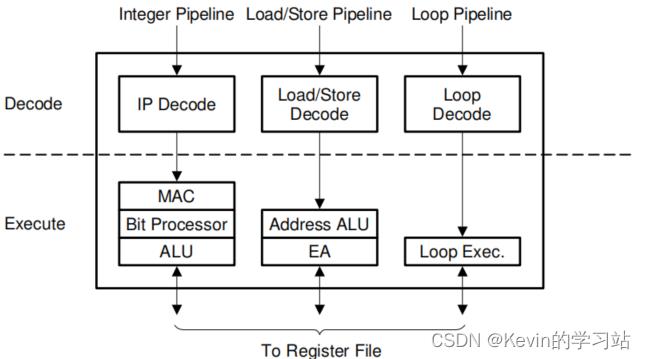
如上图执行单元流程:执行单元包括整数流水线、加载/存储流水线和循环流水线。
①、三条流水线并行运行,允许在一个时钟周期内执行多达三条指令;
②、在执行单元中,所有指令毒药经过一个解码阶段,然后执行与写回操作;
③、通过流水线之间使用转发路径,可将流水线危害降到最低,从而是一条指令的结果在结果可用时立即被下一条指令使用。
2.2.3、通用寄存器- General Purpose Register File
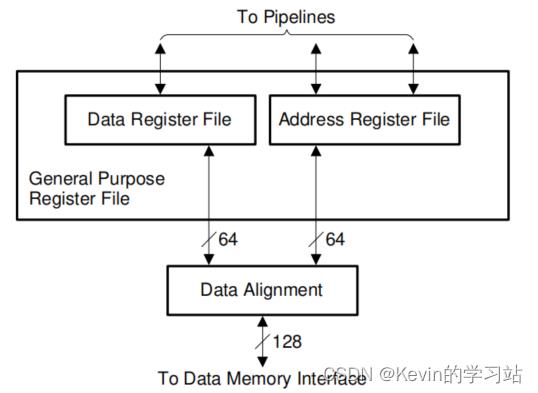
CPU具有通用寄存器(GPR)文件,该文件分为地址寄存器文件(寄存器A0-A15)和数据寄存器文件(D0-D15)。通过地址寄存器文件控制发布到加载/储存流水线的指令的数据流,通过数据寄存器文件控制向整数流水线发出的指令或从整数流水线发出的指令以及向装载/存储流水线发出的数据加载/存储指令的数据流。
以上是关于TriCore架构多核多线程锁探究(TC264双核互斥锁)的主要内容,如果未能解决你的问题,请参考以下文章