SpringBatch 批处理框架
Posted 小飞机爱旅游
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBatch 批处理框架相关的知识,希望对你有一定的参考价值。
一、批处理特点
1.程序幕后的过程,无需用户交互 即可运行。
2.在固定的数据集(eg: mysql,oracle等)上执行,直到获取全部预期的数据集。
3.可以结合定时任务使用。
二、使用场景
1.报表数据统计
通常我们会获取一段时间的数据,进行数据清洗、整合,最后形成一个可视化的报表,那么这个背后离不开批处理。
2.数据交换
例如我们将mysql的数据导入到oracle,同时我们还需要进行一些数据的筛选,梳理,那么我们也可以用到批处理。
三、SpringBatch (介绍:来自官网)
简介:一个轻量的、广泛的批处理框架,该框架的设计目的是为了支持对企业系统日常运营至关重要的批处理应用程序的开发。
Spring Batch提供了处理大量记录时必不可少的可重用功能,包括日志/跟踪、事务管理、作业处理统计、作业重启、跳过和资源管理。它还提供了更高级的技术服务和特性,通过优化和分区技术支持超大容量和高性能批处理作业。无论简单还是复杂,大容量批处理作业都可以以高度可伸缩的方式利用该框架处理大量信息。
优势:
1.状态管理:框架存储了全部job执行的相关状态数据,我们可以很方便的看到job的启动时间,job的失败原因等。
2.使用方便: 提供了开箱即用的组件去集成当下主流的数据库。
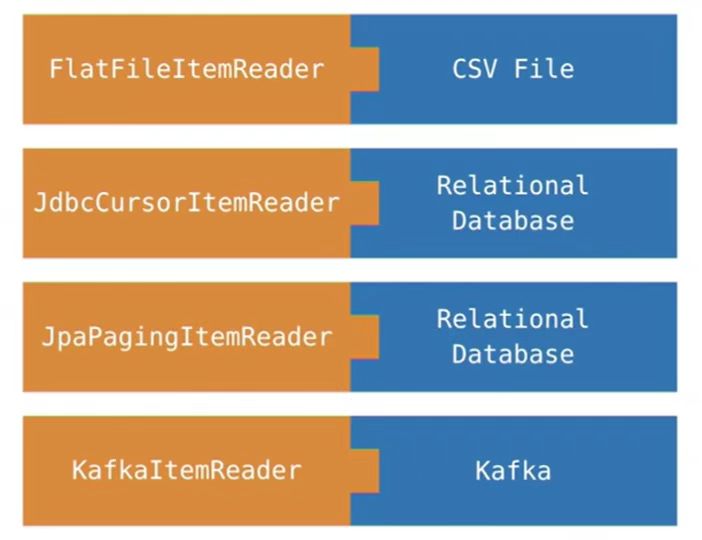
四、利用spring官网创建一个springBatch项目
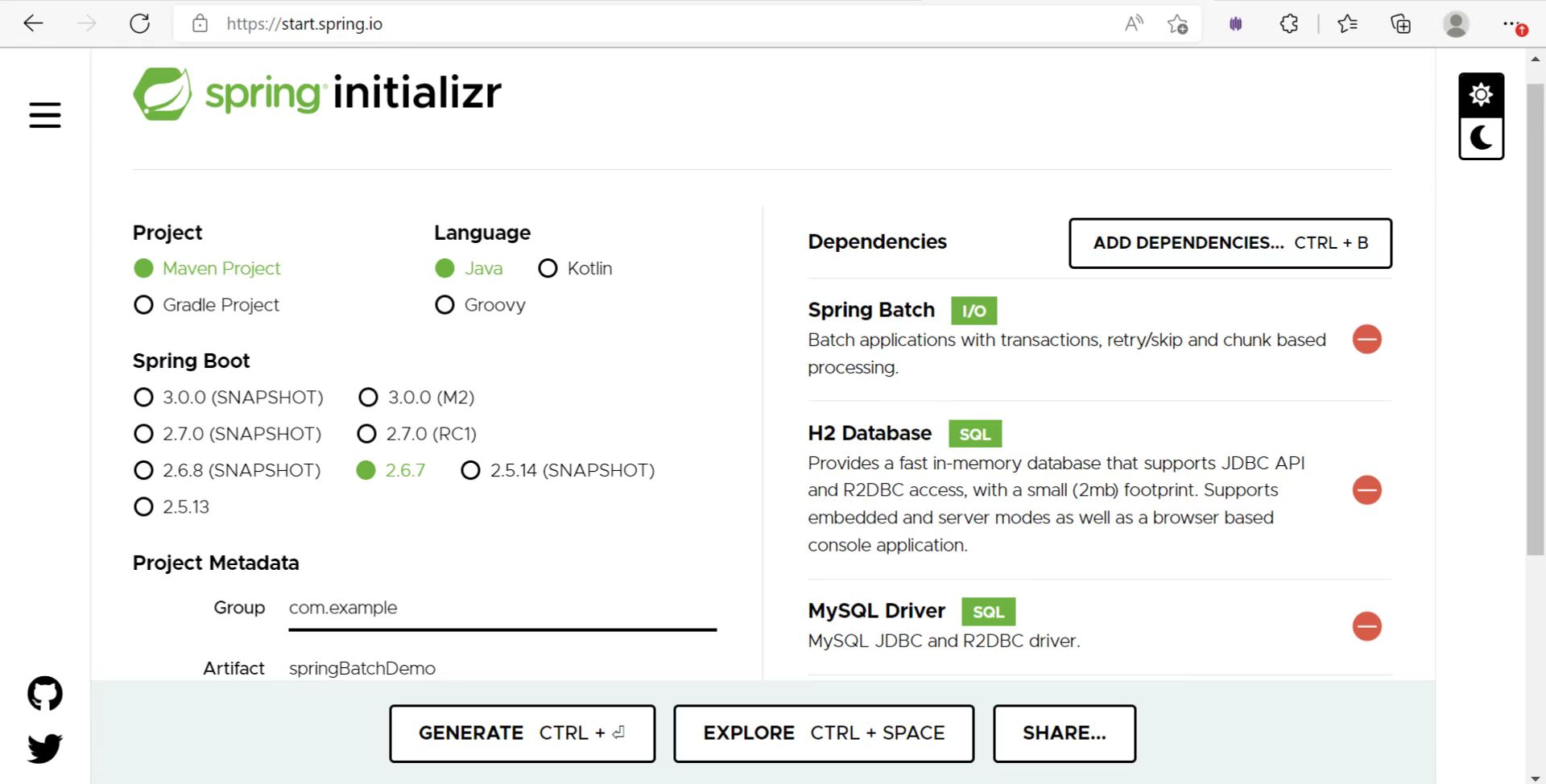
1.首先利用我们登录官网:https://start.spring.io/
选择我们需要的springboot的版本,然后选择maven构建,最后搜索我们需要的依赖,这样一个简易的springboot脚手架就搭建成功了。
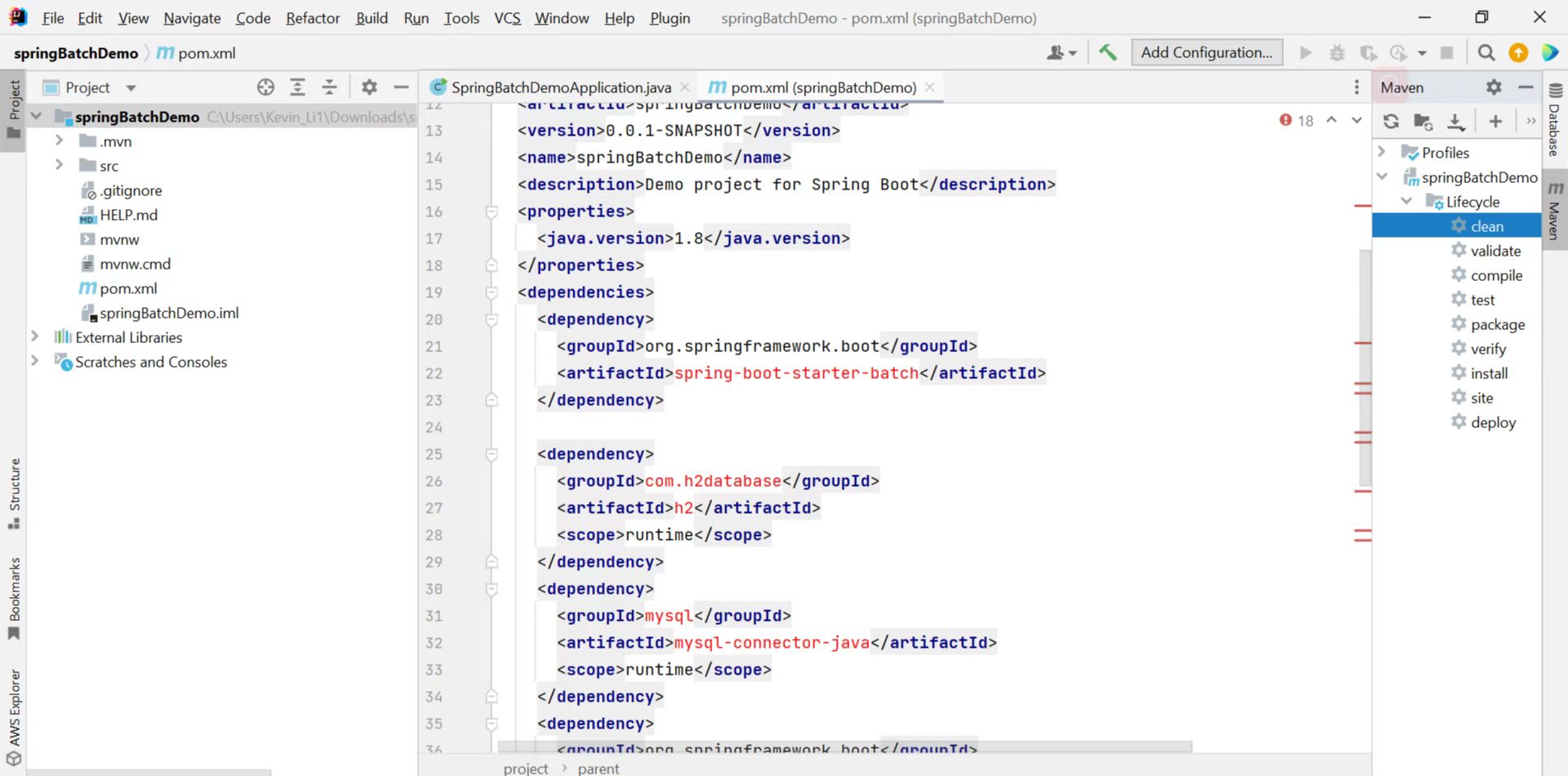
选择好后,我们可以下载一个zip包下来,里面已经包含了我们需要的依赖。项目结构如下
下一篇文章和大家分享如何一步一步的使用springBatch。感谢~
SpringBatch批处理框架+mysql仓库+web监控实录
1、概念Spring Batch 是一款轻量级地适合企业级应用的批处理框架,值得注意的是,不同于其他调度框架,Spring Batch不提供调度功能。
2、批处理过程
批处理可以分为以下几个步骤:
- 读取数据
- 按照业务处理数据
- 归档数据的过程
3、Spring Batch给我们提供了什么?
- 统一的读写接口
- 丰富的任务处理方式
- 灵活的事务管理及并发处理
- 日志、监控、任务重启与跳过等特性
4、基础组件
| 名称 | 用途 |
|---|---|
| JobRepository | 用于注册和存储Job的容器 |
| JobLauncher | 用于启动Job |
| Job | 实际要执行的作业,包含一个或多个step |
| step | 步骤,批处理的步骤一般包含ItemReader, ItemProcessor, ItemWriter |
| ItemReader | 从给定的数据源读取item |
| ItemProcessor | 在item写入数据源之前进行数据整理 |
| ItemWriter | 把Chunk中包含的item写入数据源。 |
| Chunk | 数据块,给定数量的item集合,让item进行多次读和处理,当满足一定数量的时候再一次写入。 |
| TaskLet | 子任务表, step的一个事务过程,包含重复执行,同步/异步规则等。 |
5、job, step, tasklet 和 chunk 关系
一个job对应至少一个step,一个step对应0或者1个TaskLet,一个taskLet对应0或者1个Chunk

6、实战:批处理excel插入数据库
6.1:定义数据仓库
<!-- 内存仓库 -->
<!--<bean id="jobRepository" class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean"/>-->
<!-- 数据库仓库 -->
<batch:job-repository id="jobRepository" data-source="dataRepDruidDataSource"
isolation-level-for-create="SERIALIZABLE" transaction-manager="transactionManager"
table-prefix="BATCH_" max-varchar-length="1000" />6.2:定义启动器
<!-- 作业调度器,用来启动job,引用作业仓库 -->
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository"/>
</bean>6.3:定义JOB
<batch:job id="userBatchJobName" restartable="true">
<batch:step id="userStep">
<batch:tasklet allow-start-if-complete="false"
start-limit="1" task-executor="taskExecutor" throttle-limit="5">
<batch:chunk reader="userReader" writer="userWriter"
processor="userProcessor" commit-interval="5" retry-limit="10">
<batch:retryable-exception-classes>
<batch:include class="org.springframework.dao.DuplicateKeyException"/>
<batch:include class="java.sql.BatchUpdateException"/>
<batch:include class="java.sql.SQLException"/>
</batch:retryable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="taskExecutor"
class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<!-- 线程池维护线程的最少数量 -->
<property name="corePoolSize" value="100"/>
<!-- 线程池维护线程所允许的空闲时间 -->
<property name="keepAliveSeconds" value="30000"/>
<!-- 线程池维护线程的最大数量 -->
<property name="maxPoolSize" value="300"/>
<!-- 线程池所使用的缓冲队列 -->
<property name="queueCapacity" value="100"/>
</bean>6.4:定义ItemReader
<bean id="userReader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="lineMapper" ref="lineMapper"/>
<property name="resource" value="classpath:message/batch-data-source.csv"/>
</bean> <!-- 将每行映射成对象 -->
<bean id="lineMapper" class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="delimiter" value=","/><!-- 根据某种分隔符分割 -->
<property name="names" value="id,name" />
</bean>
</property>
<property name="fieldSetMapper"><!-- 将拆分后的字段映射成对象 -->
<bean class="com.hcw.core.batch.UserFieldSetMapper" />
</property>
</bean>6.5:定义ItemWriter
<bean id="userWriter" class="com.hcw.core.batch.MyBatchItemWriter" scope="step">
<property name="statementId" value="com.hcw.core.batch.dao.UserToMapper.batchInsert"/>
<property name="sqlSessionFactory" ref="sqlSessionFactoryTo"/>
</bean>6.6:定义ItemProcessor
<bean id="userProcessor" class="com.hcw.core.batch.UserItemProcessor"/>6.7: 定义jobRepository的数据源
<bean id="dataRepDruidDataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<property name="url" value="${jdbc.mysql.rep.connection.url}" />
<property name="username" value="${jdbc.mysql.rep.connection.username}" />
<property name="password" value="${jdbc.mysql.rep.connection.password}" />
<property name="filters" value="${jdbc.mysql.rep.connection.filters}" />
<property name="maxActive" value="${jdbc.mysql.rep.connection.maxActive}" />
<property name="initialSize" value="${jdbc.mysql.rep.connection.initialSize}" />
<property name="maxWait" value="${jdbc.mysql.rep.connection.maxWait}" />
<property name="minIdle" value="${jdbc.mysql.rep.connection.minIdle}" />
<property name="timeBetweenEvictionRunsMillis"
value="${jdbc.mysql.rep.connection.timeBetweenEvictionRunsMillis}" />
<property name="minEvictableIdleTimeMillis"
value="${jdbc.mysql.rep.connection.minEvictableIdleTimeMillis}" />
<property name="validationQuery"
value="${jdbc.mysql.rep.connection.validationQuery}" />
<property name="testWhileIdle"
value="${jdbc.mysql.rep.connection.testWhileIdle}" />
<property name="testOnBorrow" value="${jdbc.mysql.rep.connection.testOnBorrow}" />
<property name="testOnReturn" value="${jdbc.mysql.rep.connection.testOnReturn}" />
<property name="poolPreparedStatements"
value="${jdbc.mysql.rep.connection.poolPreparedStatements}" />
<property name="maxPoolPreparedStatementPerConnectionSize"
value="${jdbc.mysql.rep.connection.maxPoolPreparedStatementPerConnectionSize}" />
</bean>6.8: 启动JOB
启动tomcat,打开启动页面
以上是关于SpringBatch 批处理框架的主要内容,如果未能解决你的问题,请参考以下文章