InfluxDB 内存消耗分析及性能优化
Posted 钟艾伶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了InfluxDB 内存消耗分析及性能优化相关的知识,希望对你有一定的参考价值。
目录
Time Series Index (TSI) details
SERIES CARDINALITY 序列基数
什么是SERIES CARDINALITY
cardinality反应了series的维度,即不同的series的数量。
序列基数是影响内存(RAM)使用量的主要因素。
cardinality的计算
某个measuremnt的cardinality值 = distinct(tag1value) * distinct(tag2value) * ...也就说所有tag可能取值的乘积。
When influxdb counts cardinality in a Measurement, it counts the combination of all tags. For example, if my measurement has the following tags: 3 os, 200 devices, 3 browsers, then the cardinality is > 3x200x3=1800. |
查看db序列基数
SHOW SERIES CARDINALITY on db 查看某db的series维度数量
-- show estimated cardinality of the series on current database SHOW SERIES CARDINALITY -- show estimated cardinality of the series on specified database SHOW SERIES CARDINALITY ON mydb -- show exact series cardinality SHOW SERIES EXACT CARDINALITY -- show series cardinality of the series on specified database SHOW SERIES EXACT CARDINALITY ON mydb |
数据
> SHOW SERIES CARDINALITY on appMetrics cardinality estimation ---------------------- 105336 > SHOW SERIES CARDINALITY on hardWareMetrics cardinality estimation ---------------------- 10703 > SHOW SERIES EXACT CARDINALITY ON hardWareMetrics name: burrow_group count ----- 112 name: disk count ----- 14256 name: diskio count ----- 3920 name: influxdb_database count ----- 40 name: influxdb_httpd count ----- 8 name: influxdb_shard count ----- 1905 |
一个sql查询的执行过程
查询语句
select sum(pc) from advertise where publisher=‘atlasdata’ and platform = ‘baidu’ and time>='2018-08-01' and time <'2018-09-01' |
数据读取的流程
- 第一步:找出atlasdata发布在baidu的所有广告的seriesKey
- 第二步:根据seriesKey找到这些广告2018年8月份的数据,通过时间范围确定存储2018年8月份数据的shardgroup, 再根据seriesKey进行hash找到shardgroup下存储这些数据源的shard
- 第三步:找出这些数据中的pc端的数据,扫描每个shard中的TSM文件中的index block,找到符合条件的data block,再在data block中把符合条件的所查询的数据筛选出来进行聚合
提问: ??如何找到所有广告的seriesKey、?倒排索引
倒排索引
一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。
而Inverted index (倒排索引、反向索引)指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。
场景
文档——>关键词
但是这样检索关键词的时候很费力,要一个文档一个文档的遍历一遍。
于是人们发明了倒排索引~从关键词到文档的映射
关键词——>文档
这样,只要有关键词,立马就能找到关键词在哪个文档里出现过
基于内存的倒排索引
作用
提高数据源维度的查询效率:找出符合查询条件的所有数据源的seriesKey
核心数据结构及其作用
- map<tagkey, map<tagvalue, List<SeriesID>>>
保存每个tag对应的所有值对应的所有seriesID,通过条件(比如 tag1='value')获取满足条件的所有数据源的唯一标识
tagkey: 数据源属性名称
tagvalue: tagkey所指属性的值
SeriesID:满足tagkey=tagvalue的所有数据源的唯一标识,seriesID与数据源唯一标识SeriesKey一一对应
- map< SeriesID,SeriesKey>
保存seriesID和SeriesKey的映射关系,通过seriesID获取seriesKey
为什么第一个双重map中不直接用SeriesKey呢?是为了节省内存空间.
举个例子:
假如现在有3个Tag组合形成一个seriesKey:measurement=m_name,tag_1=value_1,tag_2=value_2,tag_3=value_3。那么构造形成的双重map结构:
<tag_1, <value_1, seriesKey>>
<tag_2, <value_2, seriesKey>>
<tag_3, <value_3, seriesKey>>
可以发现同一个seriesKey在内存中有多份冗余,而且seriesKey = measurement + tags,随着tag值的增加,内存消耗非常明显,因此为了节省内存消耗,采用Int对seriesKey进行编码,代替双重map中的seriesKey
优缺点
优点
- 加快数据源维度的查询效率
缺点
- 受限于内存大小
- 一旦InfluxDB进程宕掉,需要扫描解析所有TSM文件并在内存中重新构建,恢复时间很长。
基于磁盘的倒排索引-TSI文件
InfluxDB实现了基于磁盘的倒排索引,用TSI文件来存储索引信息
TSI文件的作用
提高数据源维度的查询效率:找出符合查询条件的所有数据源的seriesKey,并解决内存索引受限于内存大小、恢复时间长的问题。
TSI文件的结构
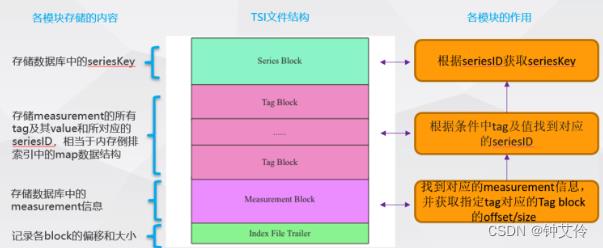
Measurement Block
找到对应的measurement信息,并获取表的tag对应的Tag block的offset/size
Measurement Block结构:
Measurement Block由三大部分组成
- Block Trailer : 记录各模块的offset和size
- HashIndex : 记录每个measurement的偏移量
- Mesurement : 记录具体表的信息,包括表的名称、所有tag对应的Tag Block的offset和size等
Measurement Block的扫描流程如下:
- 首先在TSI文件的Index File Trailer部分获取整个Mesurement Block的offset和size,
- 然后再根据Measurement Block中的Block Trailer和Hash Index确认要查询的表对应的Measurement的位置,
- 读取对应的Measurement中的Tag Block的offset和size
Influxdb中基于磁盘的倒排索引文件TSI结构解析
Influxdb中基于磁盘的倒排索引文件TSI结构解析 - 腾讯云开发者社区-腾讯云
Time Series Index (TSI) details
InfluxDB stores measurement and tag information in an index so data can be queried quickly. In earlier versions, the index was stored in-memory, requiring a lot of RAM and restricting the number of series that a machine could hold (typically, 1-4 million series, depending on the machine). Time Series Index (TSI) stores index data both in memory and on disk, removing RAM restrictions. This lets you store more series on a machine. TSI uses the operating system’s page cache to pull hot data into memory, leaving cold data on disk. |
内存消耗分析及性能优化
index-version = "inmem" inmem:基于内存 tsi1:基于磁盘 The default (inmem) index is an in-memory index that is recreated at startup. To enable the Time Series Index (TSI) disk-based index, set the value to tsi1. |
show stats 查看内存使用情况
> show stats name: runtime Alloc Frees HeapAlloc HeapIdle HeapInUse HeapObjects HeapReleased HeapSys Lookups Mallocs NumGC NumGoroutine PauseTotalNs Sys TotalAlloc ----- ----- --------- -------- --------- ----------- ------------ ------- ------- ------- ----- ------------ ------------ --- ---------- 1453852384 218795736 1453852384 1682595840 1571332096 9628928 0 3253927936 178461 228424664 96 334 784143583 3418348024 55161719256 name: queryExecutor queriesActive queriesExecuted queriesFinished queryDurationNs recoveredPanics ------------- --------------- --------------- --------------- --------------- 1 73169 73168 27803545203003 0 name: database tags: database=_internal numMeasurements numSeries --------------- --------- 12 1283 name: database tags: database=metrics numMeasurements numSeries --------------- --------- 862 105336 name: database tags: database=telegraf numMeasurements numSeries --------------- --------- 40 10703 |
HeapIdle:1.6G
HeapInUse:1.5G
HeapReleased:0g
按照go的内存分配空间布局规则,可以根据如下计算方式估计go的当前堆内存:
(HeapIdle)1.6-(HeapReleased)0+(HeapInUse) 1.5= 0.1G
提出猜想
???为什么进程RES实际占用12G, 而当前进程runtime堆占用内存仅有0.1G ???
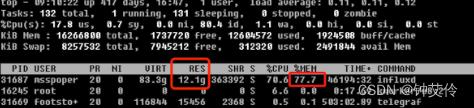
猜想:目前influxd进程持有的有效内存为 0.1G, 而系统进程RES为12G。猜想存在12-0.1=12g的内存,进程标记不再使用,系统也没有进行回收。
验证猜想
模拟一个进程,像操作系统申请占用12g内存,再top ,发现influxd占用0.1G内存,模拟程序占用12G内存
Go runtime内存释放机制:
linuxMADV_DONTNEED:释放内存效率低,但会让RSS数量下降很快(表象数据释放了,但实际还在慢慢释放,并未立即释放所有idle的内存)
MADV_FREE:释放内存更勤快,更高效。但RSS不会立刻下降,而是要等到系统有内存压力了,才会延迟下降。优化参数GODEBUG=madvdontneed=1
一直以来 go 的 runtime 在释放内存返回到内核时,在 Linux 上使用的是 MADV_DONTNEED,虽然效率比较低,但是会让 RSS(resident set size 常驻内存集)数量下降得很快。不过在 go 1.12 里专门针对这个做了优化,runtime 在释放内存时,使用了更加高效的 MADV_FREE 而不是之前的 MADV_DONTNEED。
这样带来的好处是,一次 GC 后的内存分配延迟得以改善,runtime 也会更加积极地将释放的内存归还给操作系统,以应对大块内存分配无法重用已存在的堆空间的问题。不过也会带来一个副作用:RSS 不会立刻下降,而是要等到系统有内存压力了,才会延迟下降。为了避免像这样一些靠判断 RSS 大小的自动化测试因此出问题,也提供了一个 GODEBUG=madvdontneed=1 参数可以强制 runtime 继续使用 MADV_DONTNEED。
原来是由于go内部优化而使进程内存没有立即释放,解答了内存高消耗的疑惑。
性能优化:
- influx使用 inmem 引擎时(默认),在retention policy时会消耗过高的内存
- 使用 GODEBUG=madvdontneed=1 可以让go程序尽快释放内存
因此对配置文件influxdb.conf做了如下优化:
# 详细配置说明见官方文档 # https://docs.influxdata.com/influxdb/v1.8/administration/config/#data-settings [data] #说明: wal预写日志log,用于事务一致性 #默认为0,每次写入都落盘。 #修改为1s, 根据业务场景,不保证强一致性,可采用异步刷盘 #[优化点]:用于减轻磁盘io压力 wal-fsync-delay = "1s" #说明: influx索引 #默认为inmem,创建内存型索引,在delete retention会消耗过高内存 #修改为tsi1, 注意重建tsi1索引(https://blog.csdn.net/wzy_168/article/details/107043840) #[优化点]:降低删除保留策略时的内存消耗 index-version = "tsi1" #说明: 压缩TSM数据,一次落盘的吞吐量 #默认48m #修改为64m #[优化点]:增大写入量,减轻io压力 compact-throughput = "64m" |
修改配置后,重启influx
线上验证
influxd进程重新运行一周之后,再次观察系统状态
TODO
增加influx 中间件监控,监控cpu、内存、磁盘io 等服务器资源消耗情况,将排查过成功的数据可视化,直接web观测数据情况
REF :
InfluxDb高内存占用优化(Flink监控)【干货】
InfluxDb高内存占用优化(Flink监控)【干货】 - 掘金
以上是关于InfluxDB 内存消耗分析及性能优化的主要内容,如果未能解决你的问题,请参考以下文章