echarts-wordcloud 血泪总结使用说明 (配置项及其不足点优化)
Posted HurryUpp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了echarts-wordcloud 血泪总结使用说明 (配置项及其不足点优化)相关的知识,希望对你有一定的参考价值。
基本使用方法
echarts-wordcloud是基于echarts的一个词云库,是我常用的一个组件,业务上用的多一点,但是这个库在echarts的官网文档里面没有说明,git上的说明也很少,有些配置需要自己摸索,下面都是我的血泪总结。官方github地址
依赖
首先要安装echarts包,这是基础包,然后还需要额外引入词云的包,对应的版本可自行选择,我这不是最新的
“echarts-wordcloud”: “^2.0.0”
“echarts”: “^5.1.2”
项目中使用:
import * as echarts from 'echarts'
import 'echarts-wordcloud'
echarts-wordcloud 的基本配置项
首先基本使用:
// 这里和echarts的使用一样,先拿到容器元素
const chart = echarts.init(document.getElementById('tlrealtimewordcloud'))
// 这里是官方给出的一些基本的配置项,我做一些说明
chart.setOption(
...
series: [
type: 'wordCloud',
// shape这个属性虽然可配置,但是在词的数量不太多的时候,效果不明显,它会趋向于画一个椭圆
shape: 'circle',
// 这个功能还没用过
keepAspect: false,
// 这个是可以自定义背景图片的,词云会按照图片的形状排布,所以有形状限制的时候,最好用背景图来实现,而且,这个背景图一定要放base64的,不然词云画不出来
maskImage: maskImage,
// 下面就是位置的配置
left: 'center',
top: 'center',
width: '70%',
height: '80%',
right: null,
bottom: null,
// 词的大小,最小12px,最大60px,可以在这个范围调整词的大小
sizeRange: [12, 60],
// 每个词旋转的角度范围和旋转的步进
rotationRange: [-90, 90],
rotationStep: 45,
// 词间距,数值越小,间距越小,这里间距太小的话,会出现大词把小词套住的情况,比如一个大的口字,中间会有比较大的空隙,这时候他会把一些很小的字放在口字里面,这样的话,鼠标就无法选中里面的那个小字,这里可以用函数根据词云的数量动态返回间距
gridSize: 8,
// 允许词太大的时候,超出画布的范围
drawOutOfBound: false,
// 布局的时候是否有动画
layoutAnimation: true,
// 这是全局的文字样式,相对应的还可以对每个词设置字体样式
textStyle:
fontFamily: 'sans-serif',
fontWeight: 'bold',
// 颜色可以用一个函数来返回字符串,这里是随机色
color: function ()
// Random color
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
,
emphasis:
focus: 'self',
textStyle:
textShadowBlur: 10,
textShadowColor: '#333'
,
// 数据必须是一个数组,数组是对象,对象必须有name和value属性
data: [
name: 'Farrah Abraham',
value: 366,
// 这里就是对每个字体的样式进行设置
textStyle:
]
]
);
优化项
shape
shape也可以是一个函数,比如希望是矩形的时候(来自官方githup问答区)
shape: function shapeSquare(theta)
return Math.min(
1 / Math.abs(Math.cos(theta)),
1 / Math.abs(Math.sin(theta))
)
,
gridSize
可以用一个函数根据词云的数量动态确定词间距
color
颜色可以在外面统一配置,也可以像下文那样给每个词都配置一下,这里推荐一组好看的配色
['#86D4FF', '#FF8F6C', '#2CF263', '#9FA8F7', '#1274FF', '#E6613D', '#FFC629', '#FFAB2E', '#F78289', '#FF6C96', '#45BFD4', '#4E31FF', '#31FBFB','#86D4FF', '#BF8AFD', '#FFF500', '#DE58FF', '#72ED7C', '#0BEEB8','#931CFF', '#3D25F2', '#F995C8', '#FBE9B4', '#FF4AB6']
效果是这样的

权重问题
组件会严格按照value值的大小分配权重,权重就体现在字体大小上。所以如果数据本身分布不均匀的时候,视觉效果看起来不够好,比如一个数为10000,其他的数为100-10,那么只能体现出两种权重了,即10000和其他。但是这样往往会导致视觉上,权重的分层不够明显,所以我们这个时候需要给数据分配权重,也就是改变每个词的fontSize.
代码主要思路是:
- 数据量少于8个的时候,仅做了颜色的处理(业务需求,只有红黑两系颜色)
- 数据量大于8个的时候,二分法,把数据分成四部分,
- 对于第一梯队的数据来说,一般是最重要的,至少也有两个数据,我们只对这一部分的数据做权重处理,就可以有良好的视觉效果
- 最大的那个词,给一个最大的权重60,第二个和第三个,分别给55和40,剩下的就是(40-排名数)
- 如果还有需求的话,可以再细化一点,如果能上相关的聚类算法,那就更完美了
大体效果为:
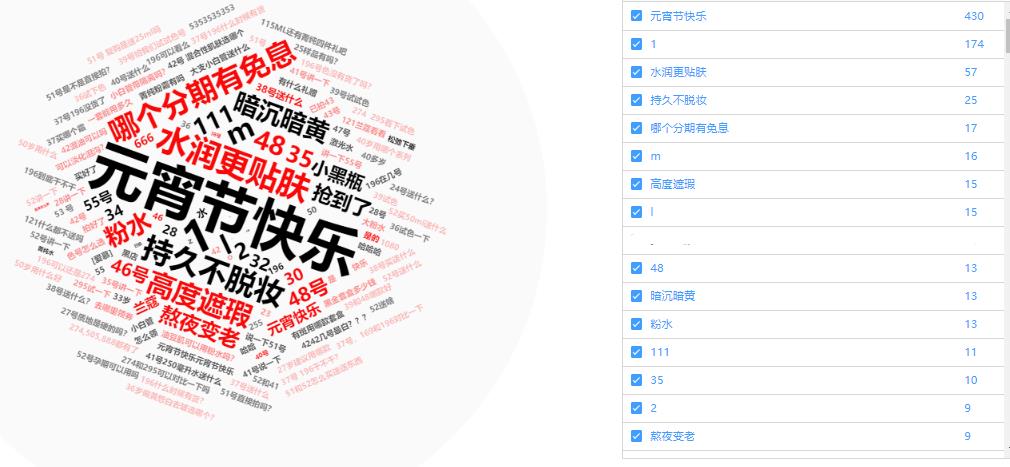
可以看见,排名靠前的都显示的比较好,直观而且有层次感
// 这里是我自己摸索的四分法,面对数据分配不均匀的时候还是挺有效果的
const blackcolor = ['#000000', '#2a2a2a', '#545454', '#7e7e7e']
const redcolor = ['rgb(249,8,8)', 'rgba(249,8,8, 0.7)', 'rgba(249,8,8, 0.5)', 'rgba(249,8,8, 0.3)']
const iterate = (arr, i, j, l) =>
if(l === 0)
for(let k = i; k <= j; k++)
if(k === 0)
arr[k].textStyle = color: blackcolor[l], fontSize: 60
else if(k < 3)
if(k % 2 === 0)
arr[k].textStyle = color: redcolor[l], fontSize: 40
else
arr[k].textStyle = color: blackcolor[l], fontSize: 55
else
if(k % 2 === 0)
arr[k].textStyle = color: redcolor[l], fontSize: 40 - k
else
arr[k].textStyle = color: blackcolor[l], fontSize: 40 - k
else
for(let k = i; k <=j ; k++)
if(k % 2 === 0)
arr[k].textStyle = color: redcolor[l]
else
arr[k].textStyle = color: blackcolor[l]
const dealworddata = (data) =>
let len = data.length
if(len <= 8 )
let i = 0,j = 0,k = 0
while(k<len)
if( k % 2 === 0)
data[k].textStyle = color: redcolor[i]
i++
else
data[k].textStyle = color: blackcolor[j]
j++
k++
else
let mid = len >> 1
let leftmid = len >> 1
let rightmid = (len - 1 + mid) >> 1
iterate(data, 0, leftmid, 0)
iterate(data, leftmid, mid, 1)
iterate(data, mid, rightmid, 2)
iterate(data, rightmid, len-1, 3)
背景图片
const maskImage = new Image()
maskImage.src = ‘’ // 这里是base64编码
...
maskImage: maskImage
大厂都是 996ICU!成功拿下阿里 P6 的 offer 后,总结出大厂面试的血泪史
前言
小编万万没想到的是:就在我们端午节休息的时候,竟然有粉丝说:自己面试阿里成功了!果然大厂都是 996ICU,端午都不放假的吗?比不过!比不过!

玩笑归玩笑,接下来我们还是看看别人是如何面试成功阿里的!并总结面试经验希望对大家有帮助,(关注的粉丝都面试成功了?)
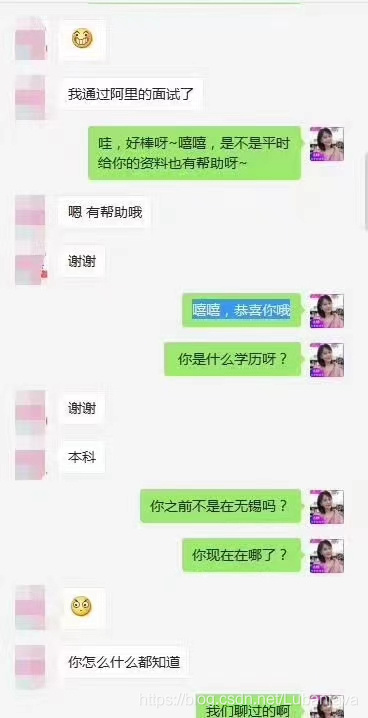
阿里一面:
1:自我介绍
2:面:谈谈你做过项目中印象较深或自认为做的比较好的地方?
答:我觉得我在 Xx 做的不错,用了 XX 需求实现 XX 功能,性能提高了 N 倍…等噼里啪啦的说了一堆。
3:面:你说使用到了 AOP,能谈谈它的实现原理嘛?
答:它是依靠动态代理实现的,动态代理又分为 JDK 自身的以及 CGLIB…
4:面:嗯,能说说他们的不同及优缺点嘛?
答:JDK 是基于接口实现,而 CGLIB 继承代理类。。。(就是这样会直问下去,如果聊的差不多了就开始问一些零散的问题)
5:JMM 内存模型,如何划分的?分别存储什么内容?线程安全与否?6:类加载机制,谈到双亲委派模型后会问到哪些违反了双亲委派模型?为什么?7:为什么要双亲委派?好处是什么?8:平时怎么使用多线程?有哪些好处?线程池的几个核心参数的意义?9:线程间通信的方式?10:HashMap 的原理:当谈到线程不安全时自然引申出 ConcurrentHashMap,它的实现原理?11:分库分表如何设计?垂直拆分、水平拆分?12:业务 ID 的生成规则,有哪些方式?13:SQL 调优?平时使用数据库有哪些注意点?14:当一个应用启动缓慢如何优化?15:对乐观锁和悲观锁的理解;
其他的想不起来了,大概是以上这些,最后还简单的聊了之前做过得项目上的问题,结束之前告诉我之后会换一个同事和我沟通,听到这样的回复一面应该就这样过了。
一面小结
首先确认对阿里的意向度(如果异地更会考虑对工作地点(杭州)的意向度!阿里很看重这个);其次面试官一般会针对您所做过的项目来做具体技术的交流,会比较关注个人对项目细节是不是掌握到位,主要考察 java 的技术基础和原理,比如 Spring 框架以及数据库和 JVM 三个方面,也会交流到分布式、线程池的实现等等,重点考察是不是有比较钻研技术和技术上的亮点【不一定每个面都很厉害但一定要有亮点】
阿里二面
1:变着法的问了一大堆线程池的知识 (主要考对应的参数)2:java 内存模型 3:lock 和 synchronized 的区别 4:B+树和 B-树的区别 5:复合索引 6:聚集索引和非聚集索引的区别?7:数据库索引 主键和唯一索引有什么区别 8:索引失效条件,什么时候该建立索引 9:innDB 和 MyISAM 的区别?10:线程安全(阻塞同步,非阻塞同步,无同步)11:说说 Java 类加载过程?12:描述一下 JVM 加载 Class 文件的原理机制?13:GC 是什么? 为什么要有 GC?14:简述 Java 垃圾回收机制。15:如何判断一个对象是否存活?(或者 GC 对象的判定方法)16:垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?17: stop() 和 suspend() 方法为何不推荐使用?18:sleep() 和 wait() 有什么区别?19:同步和异步有何异同,在什么情况下分别使用他们?20:简述 synchronized 和 java.util.concurrent.locks.Lock 的异同?21:请说出你所知道的线程同步的方法。22:什么是线程饿死,什么是活锁?23:什么是 ThreadLocal?
二面小结
根据项目深入的了解技术实力,了解您的知识面,了解您的问题解决能力以及技术灵活运用能力,也通过这一过程考察团队合作能力、学习主动性和创新性,可以挑选 2-3 个做过的有典型性的项目做一个仔细技术回顾和自己独到的理解【这会成为您的加分项】;
阿里三面
1:关于 Java 异常的续承层次结构,讲述异常的续承关系;2:java 线程如何启动?java 中加锁的方式有哪些,怎么个写法?3:对乐观锁和悲观锁的理解;4:JVM 中堆是如何管理的,JVM 的内存回收机制,介绍一下 5:redis 缓存和 memcached 缓存的区别,以及各自的优劣势 6:微服务架构:dubbo 和 springcloud 的区别,以及各自对应的使用场景。7:线程池如何做负载均衡 8:如何设计单点登录,说下单点登录的原理 9:synchronized 的实现原理?Volatile 能保证原子性吗?为什么?10:讲一下 GC?11:.TCP 三次握手,为什么三次握手?12:mysql 死锁,怎么解决,如果不要求执行顺序,死锁怎么解决 13:你觉得阿里巴巴怎么样?14:你对 996 你有什么看法呢?15:说下你的强弱点
三面小结
他们最后的高管复试会涉及到相关的技术问题,大部分是对你的整体价值观做宏观的把控(比如上进心,责任心,心态,工作激情等)
HR 确认面
基本就是从大方向了解一下您的心态、抗压能力,工作中的角色、未来大致的规划以及对阿里的意向度
【技术基础以及的问题多看看书准备下就行了,不懂的直接说不懂没关系的;在项目细节上多把关一下,根据项目有针对性的谈自己的技术亮点,能表达清楚,可以引导面试官来问你比较擅长的技术问题,个人就可以尽情发挥】
阿里比较喜欢的人才特点:对技术有热情,强硬的技术基础实力;主动,善于团队协作,善于总结思考;
面试总结
在我面试的这十几家大大小小的公司中,我发现,那些大厂的面试反而比较容易,那些小一点的面试比较苛刻的。反正就是挑你鱼里的刺。最后,我在分享一下我的面经
第一点:包装一份属于自己的独特的简历
第二点:对面试的公司做好相应的准备
第三点:在面试过程中要学会主动问问题
第四点:在技术问题上要如实的回答问题(会就会,不会就不会)
第五点:要有过硬的技术知识
第六点:在有过硬的技术知识下,要有自己的见解与看法。
最后也把阿里大佬面试成功的资料免费分享给大家,希望你也能成为下一个大佬!
Java工程师面试题分享
这套互联网 Java 工程师面试题包括了:基础 &进阶篇字符串 &集合面试题汇总、.Java 并发编程、JVM、数据结构与算法、网络协议、数据库、MySQL、52 条 SQL 性能优化策略、一千行 SQL 命令、Redis、MongoDB、Spring、MyBatis、SpringBoot、Spring & SpringBoot 常用注解、微服务、Dubbo、Nginx、Zookeeper、MQ、kafka、Elasticsearch、Linux 面试专题

由于篇幅有限下面就截取了部分内容。
需要完整 PDF 版的朋友可以三连支持一下,然后 点击此处 即可免费获取!
Java 基础篇(50 道面试题)

字符串 &&集合篇(72 道)

并发编程篇(78 道)
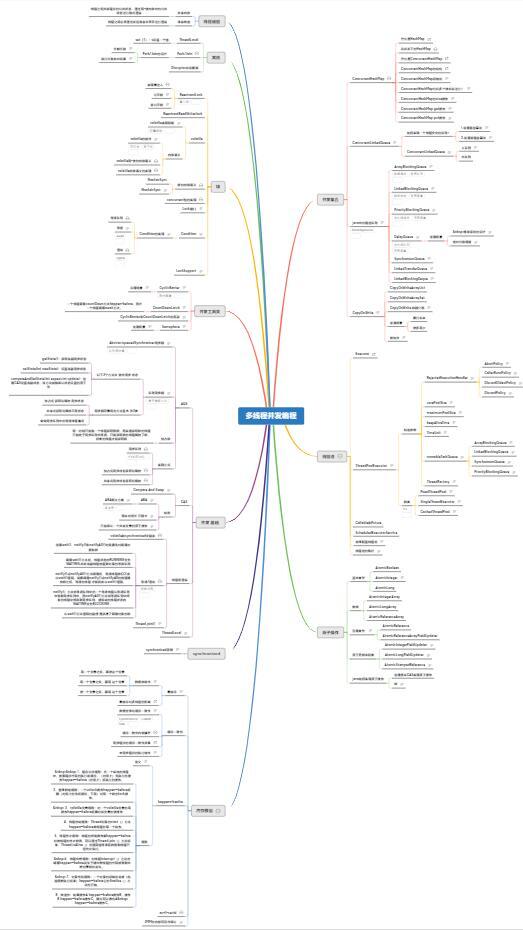
JVM 篇(51 道)

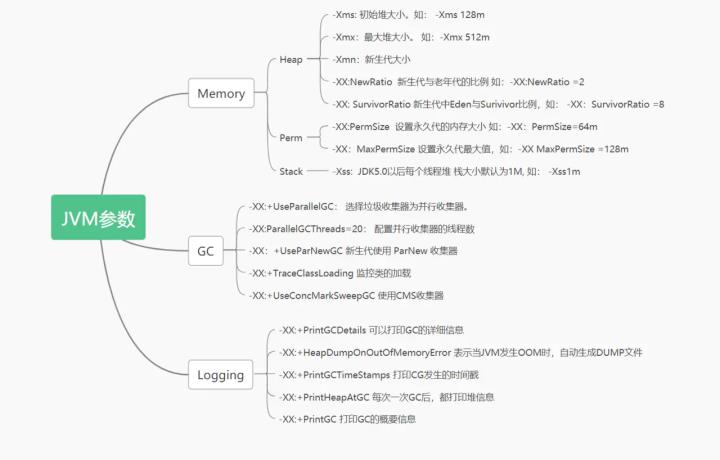
数据结构与算法(53 道)
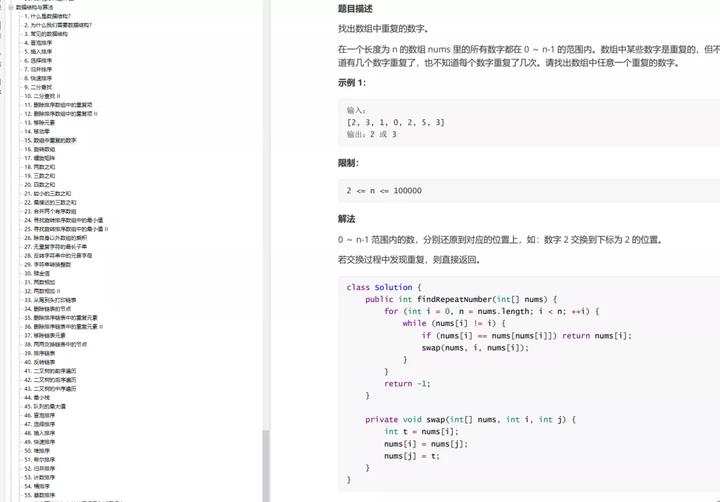
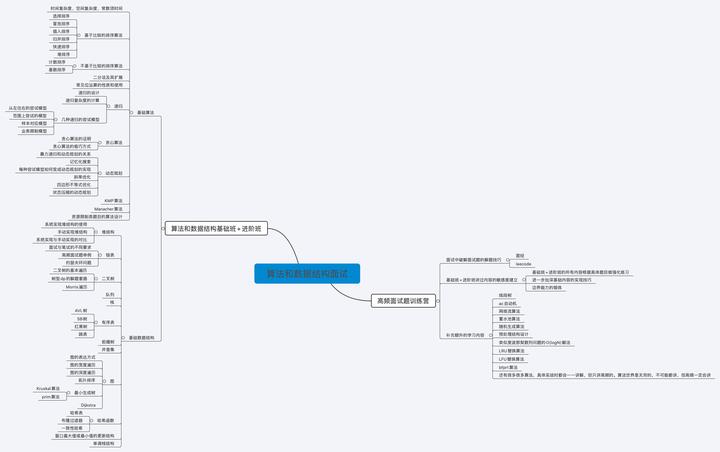
网络协议篇(53 道)


MySQL 篇(59 道)

Redis 篇(48 道)

Mongo 篇(83 道)

Spring 篇(58 道)

MyBatis 篇(47 道)

SpringBoot 篇(43 道)

常用注解篇
相信,这份资料应该是足以应对大部分的面试了;需要完整 PDF 版的朋友可以一键三连支持一下,然后 点击此处无偿下载一份!
以上是关于echarts-wordcloud 血泪总结使用说明 (配置项及其不足点优化)的主要内容,如果未能解决你的问题,请参考以下文章